为什么要做数仓分层,不做行吗?


来源:数据社 作者:数据一哥 编辑:数据一哥
全文共1404个字,建议阅读4分钟
大家好,我是一哥。
今天跟大家聊一聊数仓为什么分层?
01
经典的数仓分层
首先跟大家聊一个经典的数仓分层结构,主要包括ODS、DWS、DW、APP四层。
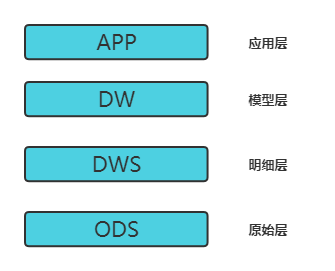
ODS:抽取的原始业务数据,结构一般和原始业务数据库表结构或者抽取的业务日志数据结构保持一致。一句话:从业务系统增量抽取,数据不做清洗转换,与业务系统数据模型保持一致。
DWS:根据ODS层,增加一些维度信息,过滤一些异常数据。为DW层提供来源明细数据,提供业务系统细节数据的长期沉淀,为未来分析类需求的扩展提供历史数据支撑。
DW:模型层,根据DWS层数据,按各个业务需求,以某个维度ID进行粗粒度汇总聚合。此层一般会根据数仓涉及的业务发展或者主数据的建立等,抽象出一些公用的聚合汇总模型
APP:应用层/指标层/报表层,每个公司的叫法不一样,一般指根据特定的某个应用或者报表进行的数据指标开发汇总。
02
数仓为什么分层
那么为什么数据仓库会有分层呢?
每多一层不就会多一些开发工作吗?还会经常有多层数据重复?不分层可不可以?
也许上面这些问题会困扰你,可能还会有人说,我来公司的时候已经有开发规范了,不分层不行!
其实数据仓库分层原因可以概括为以下4个方面:
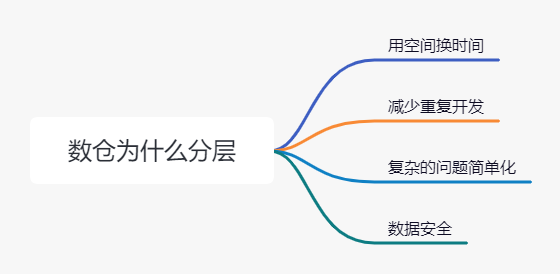
用空间换时间:数仓的发展已经几十年了,在大数据技术出现之前,我们一般采用Oracle等一些关系型数据库来做数仓,但随着数据量的发展,特别是电信和银行业务的快速发展(那时候互联网企业还没起来),在进行一个数仓应用开发过程中,我们需要分很多步骤来进行,所以会考虑用空间来换时间,包括现在市面上也会有一些用空间换时间这样的OLAP产品。
减少重复开发:可以把一些指标用到的汇总数据进行抽象,建立一个或者多个模型,这些模型可以支撑我们建立多个数仓报表,这一步需要对业务非常了解,不然就会出现上面问题说的“ 还会经常有多层数据重复?”
复杂的问题简单化:做过传统数仓的都知道,以前Oracle的存储过程会写几千行,所以现在我们一般很少写几千行的业务ETL逻辑了,而是分为多个ETL过程,从明细层到应用层进行逻辑拆解,中间也会进行一些逻辑合并,形成模型层。
数据安全:通过分层,可以更方便地对不同层,不同的数据模型进行权限管理,特定业务场景下,对不同的开发人员和业务人员屏蔽一些敏感的数据。
03
数仓分层的模板
我们可以看到现在网上有很多数仓建模的规范,那么到底有没有一套万能的规范模板,直接拿来就能用呢?
每个公司的业务发展都不尽相同,不能完全套搬一些规范,在建立数仓之前是要对自己公司的业务进行梳理,包括业务种类、数据量、需求量等,也许公司的数据量本来就不大,而且业务比较单一,那么明细层(DWS)可以不要呀,直接通过原始数据层来建立模型汇总层。
规范是给大家拓展思路参考的,数仓的开发建设本来就是和业务强关联的。开发效率提升了,分析人员用着模型说好了,业务应用人员用着说好了,那就可以了。



公众号推送规则变了
点击上方公众号名片,收藏公众号,不错过精彩内容推送!

文章来源: dataclub.blog.csdn.net,作者:数据社,版权归原作者所有,如需转载,请联系作者。
原文链接:dataclub.blog.csdn.net/article/details/123038984

- 点赞
- 收藏
- 关注作者
评论(0)