收藏,二万字讲解HiveSQL技术原理、优化与面试


来源:大数据老哥
全文共12336个字,建议收藏阅读
本文基本涵盖以下内容:

- Hive SQL 编译成MapReduce过程 -
编译 SQL 的任务是在上节中介绍的 COMPILER(编译器组件)中完成的。Hive将SQL转化为MapReduce任务,整个编译过程分为六个阶段:
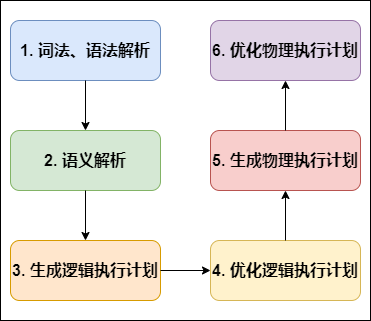
词法、语法解析: Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将 SQL 转化为抽象语法树 AST Tree;
Antlr是一种语言识别的工具,可以用来构造领域语言。使用Antlr构造特定的语言只需要编写一个语法文件,定义词法和语法替换规则即可,Antlr完成了词法分析、语法分析、语义分析、中间代码生成的过程。
语义解析: 遍历 AST Tree,抽象出查询的基本组成单元 QueryBlock;
生成逻辑执行计划: 遍历 QueryBlock,翻译为执行操作树 OperatorTree;
优化逻辑执行计划: 逻辑层优化器进行 OperatorTree 变换,合并 Operator,达到减少 MapReduce Job,减少数据传输及 shuffle 数据量;
生成物理执行计划: 遍历 OperatorTree,翻译为 MapReduce 任务;
优化物理执行计划: 物理层优化器进行 MapReduce 任务的变换,生成最终的执行计划。
下面对这六个阶段详细解析:
为便于理解,我们拿一个简单的查询语句进行展示,对5月23号的地区维表进行查询:
select * from dim.dim_region where dt = '2021-05-23';
阶段一:词法、语法解析
根据Antlr定义的sql语法规则,将相关sql进行词法、语法解析,转化为抽象语法树AST Tree:
-
ABSTRACT SYNTAX TREE:
-
TOK_QUERY
-
TOK_FROM
-
TOK_TABREF
-
TOK_TABNAME
-
dim
-
dim_region
-
TOK_INSERT
-
TOK_DESTINATION
-
TOK_DIR
-
TOK_TMP_FILE
-
TOK_SELECT
-
TOK_SELEXPR
-
TOK_ALLCOLREF
-
TOK_WHERE
-
=
-
TOK_TABLE_OR_COL
-
dt
-
'2021-05-23'

阶段二:语义解析
遍历AST Tree,抽象出查询的基本组成单元QueryBlock:
AST Tree生成后由于其复杂度依旧较高,不便于翻译为mapreduce程序,需要进行进一步抽象和结构化,形成QueryBlock。
QueryBlock是一条SQL最基本的组成单元,包括三个部分:输入源,计算过程,输出。简单来讲一个QueryBlock就是一个子查询。
QueryBlock的生成过程为一个递归过程,先序遍历 AST Tree ,遇到不同的 Token 节点(理解为特殊标记),保存到相应的属性中。
阶段三:生成逻辑执行计划
遍历QueryBlock,翻译为执行操作树OperatorTree:
Hive最终生成的MapReduce任务,Map阶段和Reduce阶段均由OperatorTree组成。
基本的操作符包括:
TableScanOperator
SelectOperator
FilterOperator
JoinOperator
GroupByOperator
ReduceSinkOperator
Operator在Map Reduce阶段之间的数据传递都是一个流式的过程。每一个Operator对一行数据完成操作后之后将数据传递给childOperator计算。
由于Join/GroupBy/OrderBy均需要在Reduce阶段完成,所以在生成相应操作的Operator之前都会先生成一个ReduceSinkOperator,将字段组合并序列化为Reduce Key/value, Partition Key。
阶段四:优化逻辑执行计划
Hive中的逻辑查询优化可以大致分为以下几类:
投影修剪
推导传递谓词
谓词下推
将Select-Select,Filter-Filter合并为单个操作
多路 Join
查询重写以适应某些列值的Join倾斜
阶段五:生成物理执行计划
生成物理执行计划即是将逻辑执行计划生成的OperatorTree转化为MapReduce Job的过程,主要分为下面几个阶段:
对输出表生成MoveTask
从OperatorTree的其中一个根节点向下深度优先遍历
ReduceSinkOperator标示Map/Reduce的界限,多个Job间的界限
遍历其他根节点,遇过碰到JoinOperator合并MapReduceTask
生成StatTask更新元数据
剪断Map与Reduce间的Operator的关系
阶段六:优化物理执行计划
Hive中的物理优化可以大致分为以下几类:
分区修剪(Partition Pruning)
基于分区和桶的扫描修剪(Scan pruning)
如果查询基于抽样,则扫描修剪
在某些情况下,在 map 端应用 Group By
在 mapper 上执行 Join
优化 Union,使Union只在 map 端执行
在多路 Join 中,根据用户提示决定最后流哪个表
删除不必要的 ReduceSinkOperators
对于带有Limit子句的查询,减少需要为该表扫描的文件数
对于带有Limit子句的查询,通过限制 ReduceSinkOperator 生成的内容来限制来自 mapper 的输出
减少用户提交的SQL查询所需的Tez作业数量
如果是简单的提取查询,避免使用MapReduce作业
对于带有聚合的简单获取查询,执行不带 MapReduce 任务的聚合
重写 Group By 查询使用索引表代替原来的表
当表扫描之上的谓词是相等谓词且谓词中的列具有索引时,使用索引扫描
经过以上六个阶段,SQL 就被解析映射成了集群上的 MapReduce 任务。
SQL编译成MapReduce具体原理
在阶段五-生成物理执行计划,即遍历 OperatorTree,翻译为 MapReduce 任务,这个过程具体是怎么转化的呢
我们接下来举几个常用 SQL 语句转化为 MapReduce 的具体步骤:
Join的实现原理
以下面这个SQL为例,讲解 join 的实现:
select u.name, o.orderid from order o join user u on o.uid = u.uid;
在map的输出value中为不同表的数据打上tag标记,在reduce阶段根据tag判断数据来源。MapReduce的过程如下:
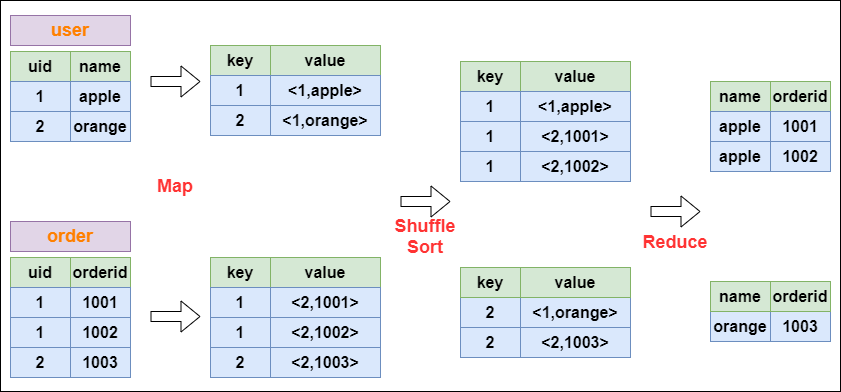
MapReduce CommonJoin的实现
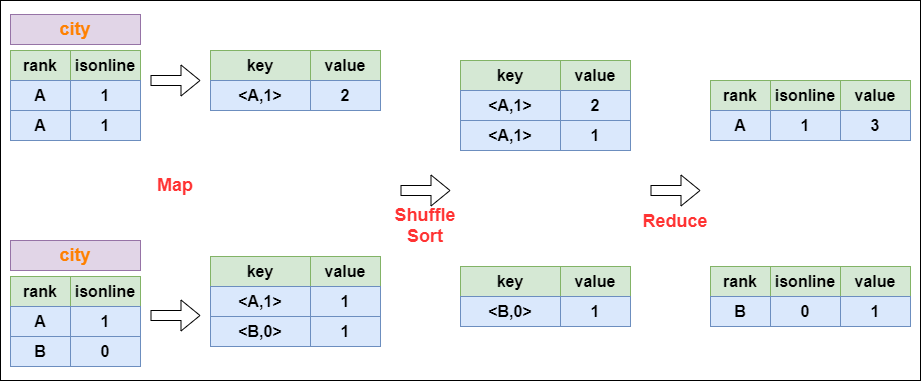
Group By的实现原理
以下面这个SQL为例,讲解 group by 的实现:
select rank, isonline, count(*) from city group by rank, isonline;
将GroupBy的字段组合为map的输出key值,利用MapReduce的排序,在reduce阶段保存LastKey区分不同的key。MapReduce的过程如下:
Distinct的实现原理
以下面这个SQL为例,讲解 distinct 的实现:
select dealid, count(distinct uid) num from order group by dealid;
当只有一个distinct字段时,如果不考虑Map阶段的Hash GroupBy,只需要将GroupBy字段和Distinct字段组合为map输出key,利用mapreduce的排序,同时将GroupBy字段作为reduce的key,在reduce阶段保存LastKey即可完成去重:
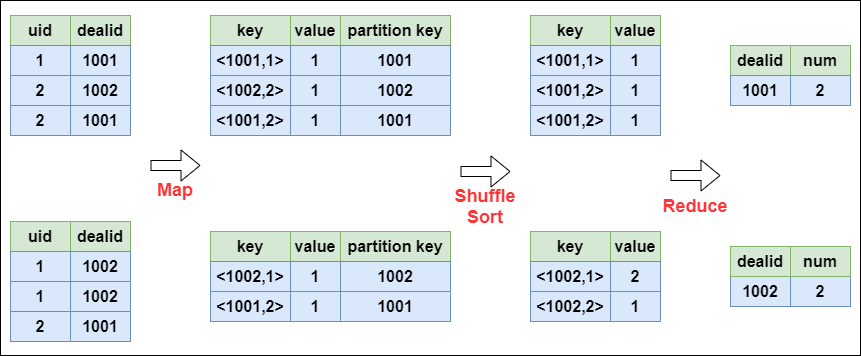

- Hive 千亿级数据倾斜 -
数据倾斜问题剖析
数据倾斜是分布式系统不可避免的问题,任何分布式系统都有几率发生数据倾斜,但有些小伙伴在平时工作中感知不是很明显,这里要注意本篇文章的标题—“千亿级数据”,为什么说千亿级,因为如果一个任务的数据量只有几百万,它即使发生了数据倾斜,所有数据都跑到一台机器去执行,对于几百万的数据量,一台机器执行起来还是毫无压力的,这时数据倾斜对我们感知不大,只有数据达到一个量级时,一台机器应付不了这么多的数据,这时如果发生数据倾斜,那么最后就很难算出结果。
所以就需要我们对数据倾斜的问题进行优化,尽量避免或减轻数据倾斜带来的影响。
在解决数据倾斜问题之前,还要再提一句:没有瓶颈时谈论优化,都是自寻烦恼。
大家想想,在map和reduce两个阶段中,最容易出现数据倾斜的就是reduce阶段,因为map到reduce会经过shuffle阶段,在shuffle中默认会按照key进行hash,如果相同的key过多,那么hash的结果就是大量相同的key进入到同一个reduce中,导致数据倾斜。
那么有没有可能在map阶段就发生数据倾斜呢,是有这种可能的。
一个任务中,数据文件在进入map阶段之前会进行切分,默认是128M一个数据块,但是如果当对文件使用GZIP压缩等不支持文件分割操作的压缩方式时,MR任务读取压缩后的文件时,是对它切分不了的,该压缩文件只会被一个任务所读取,如果有一个超大的不可切分的压缩文件被一个map读取时,就会发生map阶段的数据倾斜。
所以,从本质上来说,发生数据倾斜的原因有两种:一是任务中需要处理大量相同的key的数据。二是任务读取不可分割的大文件。
数据倾斜解决方案
MapReduce和Spark中的数据倾斜解决方案原理都是类似的,以下讨论Hive使用MapReduce引擎引发的数据倾斜,Spark数据倾斜也可以此为参照。
空值引发的数据倾斜
实际业务中有些大量的null值或者一些无意义的数据参与到计算作业中,表中有大量的null值,如果表之间进行join操作,就会有shuffle产生,这样所有的null值都会被分配到一个reduce中,必然产生数据倾斜。
之前有小伙伴问,如果A、B两表join操作,假如A表中需要join的字段为null,但是B表中需要join的字段不为null,这两个字段根本就join不上啊,为什么还会放到一个reduce中呢?
这里我们需要明确一个概念,数据放到同一个reduce中的原因不是因为字段能不能join上,而是因为shuffle阶段的hash操作,只要key的hash结果是一样的,它们就会被拉到同一个reduce中。
解决方案:
第一种:可以直接不让null值参与join操作,即不让null值有shuffle阶段
-
SELECT *
-
FROM log a
-
JOIN users b
-
ON a.user_id IS NOT NULL
-
AND a.user_id = b.user_id
-
UNION ALL
-
SELECT *
-
FROM log a
-
WHERE a.user_id IS NULL;
第二种:因为null值参与shuffle时的hash结果是一样的,那么我们可以给null值随机赋值,这样它们的hash结果就不一样,就会进到不同的reduce中:
-
SELECT *
-
FROM log a
-
LEFT JOIN users b ON CASE
-
WHEN a.user_id IS NULL THEN concat('hive_', rand())
-
ELSE a.user_id
-
END = b.user_id;
不同数据类型引发的数据倾斜
对于两个表join,表a中需要join的字段key为int,表b中key字段既有string类型也有int类型。当按照key进行两个表的join操作时,默认的Hash操作会按int型的id来进行分配,这样所有的string类型都被分配成同一个id,结果就是所有的string类型的字段进入到一个reduce中,引发数据倾斜。
解决方案:
如果key字段既有string类型也有int类型,默认的hash就都会按int类型来分配,那我们直接把int类型都转为string就好了,这样key字段都为string,hash时就按照string类型分配了:
-
SELECT *
-
FROM users a
-
LEFT JOIN logs b ON a.usr_id = CAST(b.user_id AS string);
不可拆分大文件引发的数据倾斜
当集群的数据量增长到一定规模,有些数据需要归档或者转储,这时候往往会对数据进行压缩;当对文件使用GZIP压缩等不支持文件分割操作的压缩方式,在日后有作业涉及读取压缩后的文件时,该压缩文件只会被一个任务所读取。如果该压缩文件很大,则处理该文件的Map需要花费的时间会远多于读取普通文件的Map时间,该Map任务会成为作业运行的瓶颈。这种情况也就是Map读取文件的数据倾斜。
解决方案:
这种数据倾斜问题没有什么好的解决方案,只能将使用GZIP压缩等不支持文件分割的文件转为bzip和zip等支持文件分割的压缩方式。
所以,我们在对文件进行压缩时,为避免因不可拆分大文件而引发数据读取的倾斜,在数据压缩的时候可以采用bzip2和Zip等支持文件分割的压缩算法。
数据膨胀引发的数据倾斜
在多维聚合计算时,如果进行分组聚合的字段过多,如下:
select a,b,c,count(1)from log group by a,b,c with rollup;
注:对于最后的with rollup关键字不知道大家用过没,with rollup是用来在分组统计数据的基础上再进行统计汇总,即用来得到group by的汇总信息。
如果上面的log表的数据量很大,并且Map端的聚合不能很好地起到数据压缩的情况下,会导致Map端产出的数据急速膨胀,这种情况容易导致作业内存溢出的异常。如果log表含有数据倾斜key,会加剧Shuffle过程的数据倾斜。
解决方案:
可以拆分上面的sql,将with rollup拆分成如下几个sql:
-
SELECT a, b, c, COUNT(1)
-
FROM log
-
GROUP BY a, b, c;
-
-
SELECT a, b, NULL, COUNT(1)
-
FROM log
-
GROUP BY a, b;
-
-
SELECT a, NULL, NULL, COUNT(1)
-
FROM log
-
GROUP BY a;
-
-
SELECT NULL, NULL, NULL, COUNT(1)
-
FROM log;
但是,上面这种方式不太好,因为现在是对3个字段进行分组聚合,那如果是5个或者10个字段呢,那么需要拆解的SQL语句会更多。
在Hive中可以通过参数 hive.new.job.grouping.set.cardinality 配置的方式自动控制作业的拆解,该参数默认值是30。表示针对grouping sets/rollups/cubes这类多维聚合的操作,如果最后拆解的键组合大于该值,会启用新的任务去处理大于该值之外的组合。如果在处理数据时,某个分组聚合的列有较大的倾斜,可以适当调小该值。
表连接时引发的数据倾斜
两表进行普通的repartition join时,如果表连接的键存在倾斜,那么在 Shuffle 阶段必然会引起数据倾斜。
解决方案:
通常做法是将倾斜的数据存到分布式缓存中,分发到各个 Map任务所在节点。在Map阶段完成join操作,即MapJoin,这避免了 Shuffle,从而避免了数据倾斜。
MapJoin是Hive的一种优化操作,其适用于小表JOIN大表的场景,由于表的JOIN操作是在Map端且在内存进行的,所以其并不需要启动Reduce任务也就不需要经过shuffle阶段,从而能在一定程度上节省资源提高JOIN效率。
在Hive 0.11版本之前,如果想在Map阶段完成join操作,必须使用MAPJOIN来标记显示地启动该优化操作,由于其需要将小表加载进内存所以要注意小表的大小。
如将a表放到Map端内存中执行,在Hive 0.11版本之前需要这样写:
-
select /* +mapjoin(a) */ a.id , a.name, b.age
-
from a join b
-
on a.id = b.id;
如果想将多个表放到Map端内存中,只需在mapjoin()中写多个表名称即可,用逗号分隔,如将a表和c表放到Map端内存中,则 / +mapjoin(a,c) / 。
在Hive 0.11版本及之后,Hive默认启动该优化,也就是不在需要显示的使用MAPJOIN标记,其会在必要的时候触发该优化操作将普通JOIN转换成MapJoin,可以通过以下两个属性来设置该优化的触发时机:
hive.auto.convert.join=true 默认值为true,自动开启MAPJOIN优化。
hive.mapjoin.smalltable.filesize=2500000 默认值为2500000(25M),通过配置该属性来确定使用该优化的表的大小,如果表的大小小于此值就会被加载进内存中。
注意:使用默认启动该优化的方式如果出现莫名其妙的BUG(比如MAPJOIN并不起作用),就将以下两个属性置为fase手动使用MAPJOIN标记来启动该优化:
hive.auto.convert.join=false (关闭自动MAPJOIN转换操作)
hive.ignore.mapjoin.hint=false (不忽略MAPJOIN标记)
再提一句:将表放到Map端内存时,如果节点的内存很大,但还是出现内存溢出的情况,我们可以通过这个参数 mapreduce.map.memory.mb 调节Map端内存的大小。
确实无法减少数据量引发的数据倾斜
在一些操作中,我们没有办法减少数据量,如在使用 collect_list 函数时:
-
select s_age,collect_list(s_score) list_score
-
from student
-
group by s_age
collect_list:将分组中的某列转为一个数组返回。
在上述sql中,s_age有数据倾斜,但如果数据量大到一定的数量,会导致处理倾斜的Reduce任务产生内存溢出的异常。
collect_list输出一个数组,中间结果会放到内存中,所以如果collect_list聚合太多数据,会导致内存溢出。
有小伙伴说这是 group by 分组引起的数据倾斜,可以开启hive.groupby.skewindata参数来优化。我们接下来分析下:
开启该配置会将作业拆解成两个作业,第一个作业会尽可能将Map的数据平均分配到Reduce阶段,并在这个阶段实现数据的预聚合,以减少第二个作业处理的数据量;第二个作业在第一个作业处理的数据基础上进行结果的聚合。
hive.groupby.skewindata的核心作用在于生成的第一个作业能够有效减少数量。但是对于collect_list这类要求全量操作所有数据的中间结果的函数来说,明显起不到作用,反而因为引入新的作业增加了磁盘和网络I/O的负担,而导致性能变得更为低下。
解决方案:
这类问题最直接的方式就是调整reduce所执行的内存大小。
调整reduce的内存大小使用mapreduce.reduce.memory.mb这个配置。

- Hive执行计划 -
Hive SQL的执行计划描述SQL实际执行的整体轮廓,通过执行计划能了解SQL程序在转换成相应计算引擎的执行逻辑,掌握了执行逻辑也就能更好地把握程序出现的瓶颈点,从而能够实现更有针对性的优化。此外还能帮助开发者识别看似等价的SQL其实是不等价的,看似不等价的SQL其实是等价的SQL。可以说执行计划是打开SQL优化大门的一把钥匙。
要想学SQL执行计划,就需要学习查看执行计划的命令:explain,在查询语句的SQL前面加上关键字explain是查看执行计划的基本方法。
学会explain,能够给我们工作中使用hive带来极大的便利!

- 查看SQL的执行计划 -
Hive提供的执行计划目前可以查看的信息有以下几种:
explain:查看执行计划的基本信息;
explain dependency:dependency在explain语句中使用会产生有关计划中输入的额外信息。它显示了输入的各种属性;
explain authorization:查看SQL操作相关权限的信息;
explain vectorization:查看SQL的向量化描述信息,显示为什么未对Map和Reduce进行矢量化。从 Hive 2.3.0 开始支持;
explain analyze:用实际的行数注释计划。从 Hive 2.2.0 开始支持;
explain cbo:输出由Calcite优化器生成的计划。CBO 从 Hive 4.0.0 版本开始支持;
explain locks:这对于了解系统将获得哪些锁以运行指定的查询很有用。LOCKS 从 Hive 3.2.0 开始支持;
explain ast:输出查询的抽象语法树。AST 在 Hive 2.1.0 版本删除了,存在bug,转储AST可能会导致OOM错误,将在4.0.0版本修复;
explain extended:加上 extended 可以输出有关计划的额外信息。这通常是物理信息,例如文件名,这些额外信息对我们用处不大;
1. explain 的用法
Hive提供了explain命令来展示一个查询的执行计划,这个执行计划对于我们了解底层原理,Hive 调优,排查数据倾斜等很有帮助。
使用语法如下:
explain query;
在 hive cli 中输入以下命令(hive 2.3.7):
explain select sum(id) from test1;
得到结果:
-
STAGE DEPENDENCIES:
-
Stage-1 is a root stage
-
Stage-0 depends on stages: Stage-1
-
-
STAGE PLANS:
-
Stage: Stage-1
-
Map Reduce
-
Map Operator Tree:
-
TableScan
-
alias: test1
-
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
-
Select Operator
-
expressions: id (type: int)
-
outputColumnNames: id
-
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
-
Group By Operator
-
aggregations: sum(id)
-
mode: hash
-
outputColumnNames: _col0
-
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
-
Reduce Output Operator
-
sort order:
-
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
-
value expressions: _col0 (type: bigint)
-
Reduce Operator Tree:
-
Group By Operator
-
aggregations: sum(VALUE._col0)
-
mode: mergepartial
-
outputColumnNames: _col0
-
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
-
File Output Operator
-
compressed: false
-
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
-
table:
-
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
-
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
-
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
-
-
Stage: Stage-0
-
Fetch Operator
-
limit: -1
-
Processor Tree:
-
ListSink
看完以上内容有什么感受,是不是感觉都看不懂,不要着急,下面将会详细讲解每个参数,相信你学完下面的内容之后再看 explain 的查询结果将游刃有余。
一个HIVE查询被转换为一个由一个或多个stage组成的序列(有向无环图DAG)。这些stage可以是MapReduce stage,也可以是负责元数据存储的stage,也可以是负责文件系统的操作(比如移动和重命名)的stage。
我们将上述结果拆分看,先从最外层开始,包含两个大的部分:
先看第一部分 stage dependencies ,包含两个 stage,Stage-1 是根stage,说明这是开始的stage,Stage-0 依赖 Stage-1,Stage-1执行完成后执行Stage-0。
stage dependencies:各个stage之间的依赖性
stage plan:各个stage的执行计划
再看第二部分 stage plan,里面有一个 Map Reduce,一个MR的执行计划分为两个部分:
Map Operator Tree:MAP端的执行计划树
Reduce Operator Tree:Reduce端的执行计划树
这两个执行计划树里面包含这条sql语句的 operator:
TableScan:表扫描操作,map端第一个操作肯定是加载表,所以就是表扫描操作,常见的属性:
alias:表名称
Statistics:表统计信息,包含表中数据条数,数据大小等
Select Operator:选取操作,常见的属性 :
expressions:需要的字段名称及字段类型
outputColumnNames:输出的列名称
Statistics:表统计信息,包含表中数据条数,数据大小等
Group By Operator:分组聚合操作,常见的属性:
aggregations:显示聚合函数信息
mode:聚合模式,值有 hash:随机聚合,就是hash partition;partial:局部聚合;final:最终聚合
keys:分组的字段,如果没有分组,则没有此字段
outputColumnNames:聚合之后输出列名
Statistics:表统计信息,包含分组聚合之后的数据条数,数据大小等
Reduce Output Operator:输出到reduce操作,常见属性:
sort order:值为空 不排序;值为 + 正序排序,值为 - 倒序排序;值为 +- 排序的列为两列,第一列为正序,第二列为倒序
Filter Operator:过滤操作,常见的属性:
predicate:过滤条件,如sql语句中的where id>=1,则此处显示(id >= 1)
Map Join Operator:join 操作,常见的属性:
condition map:join方式 ,如Inner Join 0 to 1 Left Outer Join0 to 2
keys: join 的条件字段
outputColumnNames:join 完成之后输出的字段
Statistics:join 完成之后生成的数据条数,大小等
File Output Operator:文件输出操作,常见的属性
compressed:是否压缩
table:表的信息,包含输入输出文件格式化方式,序列化方式等
Fetch Operator 客户端获取数据操作,常见的属性:
limit,值为 -1 表示不限制条数,其他值为限制的条数
2. explain 的使用场景
本节介绍 explain 能够为我们在生产实践中带来哪些便利及解决我们哪些迷惑
案例一:join 语句会过滤 null 的值吗?
现在,我们在hive cli 输入以下查询计划语句
select a.id,b.user_name from test1 a join test2 b on a.id=b.id;
问:上面这条 join 语句会过滤 id 为 null 的值吗
执行下面语句:
explain select a.id,b.user_name from test1 a join test2 b on a.id=b.id;
我们来看结果 (为了适应页面展示,仅截取了部分输出信息):
-
TableScan
-
alias: a
-
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
-
Filter Operator
-
predicate: id is not null (type: boolean)
-
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
-
Select Operator
-
expressions: id (type: int)
-
outputColumnNames: _col0
-
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
-
HashTable Sink Operator
-
keys:
-
0 _col0 (type: int)
-
1 _col0 (type: int)
-
...
从上述结果可以看到 predicate: id is not null 这样一行,说明 join 时会自动过滤掉关联字段为 null 值的情况,但 left join 或 full join 是不会自动过滤null值的,大家可以自行尝试下。
案例二:group by 分组语句会进行排序吗?
看下面这条sql
select id,max(user_name) from test1 group by id;
问:group by 分组语句会进行排序吗
直接来看 explain 之后结果 (为了适应页面展示,仅截取了部分输出信息)
-
TableScan
-
alias: test1
-
Statistics: Num rows: 9 Data size: 108 Basic stats: COMPLETE Column stats: NONE
-
Select Operator
-
expressions: id (type: int), user_name (type: string)
-
outputColumnNames: id, user_name
-
Statistics: Num rows: 9 Data size: 108 Basic stats: COMPLETE Column stats: NONE
-
Group By Operator
-
aggregations: max(user_name)
-
keys: id (type: int)
-
mode: hash
-
outputColumnNames: _col0, _col1
-
Statistics: Num rows: 9 Data size: 108 Basic stats: COMPLETE Column stats: NONE
-
Reduce Output Operator
-
key expressions: _col0 (type: int)
-
sort order: +
-
Map-reduce partition columns: _col0 (type: int)
-
Statistics: Num rows: 9 Data size: 108 Basic stats: COMPLETE Column stats: NONE
-
value expressions: _col1 (type: string)
-
...
我们看 Group By Operator,里面有 keys: id (type: int) 说明按照 id 进行分组的,再往下看还有 sort order: + ,说明是按照 id 字段进行正序排序的。
案例三:哪条sql执行效率高呢?
观察两条sql语句
-
SELECT
-
a.id,
-
b.user_name
-
FROM
-
test1 a
-
JOIN test2 b ON a.id = b.id
-
WHERE
-
a.id > 2;
-
SELECT
-
a.id,
-
b.user_name
-
FROM
-
(SELECT * FROM test1 WHERE id > 2) a
-
JOIN test2 b ON a.id = b.id;
这两条sql语句输出的结果是一样的,但是哪条sql执行效率高呢?
有人说第一条sql执行效率高,因为第二条sql有子查询,子查询会影响性能;
有人说第二条sql执行效率高,因为先过滤之后,在进行join时的条数减少了,所以执行效率就高了。
到底哪条sql效率高呢,我们直接在sql语句前面加上 explain,看下执行计划不就知道了嘛!
在第一条sql语句前加上 explain,得到如下结果
-
hive (default)> explain select a.id,b.user_name from test1 a join test2 b on a.id=b.id where a.id >2;
-
OK
-
Explain
-
STAGE DEPENDENCIES:
-
Stage-4 is a root stage
-
Stage-3 depends on stages: Stage-4
-
Stage-0 depends on stages: Stage-3
-
-
STAGE PLANS:
-
Stage: Stage-4
-
Map Reduce Local Work
-
Alias -> Map Local Tables:
-
$hdt$_0:a
-
Fetch Operator
-
limit: -1
-
Alias -> Map Local Operator Tree:
-
$hdt$_0:a
-
TableScan
-
alias: a
-
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
-
Filter Operator
-
predicate: (id > 2) (type: boolean)
-
Statistics: Num rows: 2 Data size: 25 Basic stats: COMPLETE Column stats: NONE
-
Select Operator
-
expressions: id (type: int)
-
outputColumnNames: _col0
-
Statistics: Num rows: 2 Data size: 25 Basic stats: COMPLETE Column stats: NONE
-
HashTable Sink Operator
-
keys:
-
0 _col0 (type: int)
-
1 _col0 (type: int)
-
-
Stage: Stage-3
-
Map Reduce
-
Map Operator Tree:
-
TableScan
-
alias: b
-
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
-
Filter Operator
-
predicate: (id > 2) (type: boolean)
-
Statistics: Num rows: 2 Data size: 25 Basic stats: COMPLETE Column stats: NONE
-
Select Operator
-
expressions: id (type: int), user_name (type: string)
-
outputColumnNames: _col0, _col1
-
Statistics: Num rows: 2 Data size: 25 Basic stats: COMPLETE Column stats: NONE
-
Map Join Operator
-
condition map:
-
Inner Join 0 to 1
-
keys:
-
0 _col0 (type: int)
-
1 _col0 (type: int)
-
outputColumnNames: _col0, _col2
-
Statistics: Num rows: 2 Data size: 27 Basic stats: COMPLETE Column stats: NONE
-
Select Operator
-
expressions: _col0 (type: int), _col2 (type: string)
-
outputColumnNames: _col0, _col1
-
Statistics: Num rows: 2 Data size: 27 Basic stats: COMPLETE Column stats: NONE
-
File Output Operator
-
compressed: false
-
Statistics: Num rows: 2 Data size: 27 Basic stats: COMPLETE Column stats: NONE
-
table:
-
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
-
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
-
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
-
Local Work:
-
Map Reduce Local Work
-
-
Stage: Stage-0
-
Fetch Operator
-
limit: -1
-
Processor Tree:
-
ListSink
在第二条sql语句前加上 explain,得到如下结果
-
hive (default)> explain select a.id,b.user_name from(select * from test1 where id>2 ) a join test2 b on a.id=b.id;
-
OK
-
Explain
-
STAGE DEPENDENCIES:
-
Stage-4 is a root stage
-
Stage-3 depends on stages: Stage-4
-
Stage-0 depends on stages: Stage-3
-
-
STAGE PLANS:
-
Stage: Stage-4
-
Map Reduce Local Work
-
Alias -> Map Local Tables:
-
$hdt$_0:test1
-
Fetch Operator
-
limit: -1
-
Alias -> Map Local Operator Tree:
-
$hdt$_0:test1
-
TableScan
-
alias: test1
-
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
-
Filter Operator
-
predicate: (id > 2) (type: boolean)
-
Statistics: Num rows: 2 Data size: 25 Basic stats: COMPLETE Column stats: NONE
-
Select Operator
-
expressions: id (type: int)
-
outputColumnNames: _col0
-
Statistics: Num rows: 2 Data size: 25 Basic stats: COMPLETE Column stats: NONE
-
HashTable Sink Operator
-
keys:
-
0 _col0 (type: int)
-
1 _col0 (type: int)
-
-
Stage: Stage-3
-
Map Reduce
-
Map Operator Tree:
-
TableScan
-
alias: b
-
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
-
Filter Operator
-
predicate: (id > 2) (type: boolean)
-
Statistics: Num rows: 2 Data size: 25 Basic stats: COMPLETE Column stats: NONE
-
Select Operator
-
expressions: id (type: int), user_name (type: string)
-
outputColumnNames: _col0, _col1
-
Statistics: Num rows: 2 Data size: 25 Basic stats: COMPLETE Column stats: NONE
-
Map Join Operator
-
condition map:
-
Inner Join 0 to 1
-
keys:
-
0 _col0 (type: int)
-
1 _col0 (type: int)
-
outputColumnNames: _col0, _col2
-
Statistics: Num rows: 2 Data size: 27 Basic stats: COMPLETE Column stats: NONE
-
Select Operator
-
expressions: _col0 (type: int), _col2 (type: string)
-
outputColumnNames: _col0, _col1
-
Statistics: Num rows: 2 Data size: 27 Basic stats: COMPLETE Column stats: NONE
-
File Output Operator
-
compressed: false
-
Statistics: Num rows: 2 Data size: 27 Basic stats: COMPLETE Column stats: NONE
-
table:
-
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
-
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
-
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
-
Local Work:
-
Map Reduce Local Work
-
-
Stage: Stage-0
-
Fetch Operator
-
limit: -1
-
Processor Tree:
-
ListSink
大家有什么发现,除了表别名不一样,其他的执行计划完全一样,都是先进行 where 条件过滤,在进行 join 条件关联。说明 hive 底层会自动帮我们进行优化,所以这两条sql语句执行效率是一样的。
以上仅列举了3个我们生产中既熟悉又有点迷糊的例子,explain 还有很多其他的用途,如查看stage的依赖情况、排查数据倾斜、hive 调优等,小伙伴们可以自行尝试。
2. explain dependency的用法
explain dependency用于描述一段SQL需要的数据来源,输出是一个json格式的数据,里面包含以下两个部分的内容:
input_partitions:描述一段SQL依赖的数据来源表分区,里面存储的是分区名的列表,如果整段SQL包含的所有表都是非分区表,则显示为空。
input_tables:描述一段SQL依赖的数据来源表,里面存储的是Hive表名的列表。
使用explain dependency查看SQL查询非分区普通表,在 hive cli 中输入以下命令:
explain dependency select s_age,count(1) num from student_orc;
得到结果:
{"input_partitions":[],"input_tables":[{"tablename":"default@student_tb _orc","tabletype":"MANAGED_TABLE"}]}
使用explain dependency查看SQL查询分区表,在 hive cli 中输入以下命令:
explain dependency select s_age,count(1) num from student_orc_partition;
得到结果:
-
{"input_partitions":[{"partitionName":"default@student_orc_partition@ part=0"},
-
{"partitionName":"default@student_orc_partition@part=1"},
-
{"partitionName":"default@student_orc_partition@part=2"},
-
{"partitionName":"default@student_orc_partition@part=3"},
-
{"partitionName":"default@student_orc_partition@part=4"},
-
{"partitionName":"default@student_orc_partition@part=5"},
-
{"partitionName":"default@student_orc_partition@part=6"},
-
{"partitionName":"default@student_orc_partition@part=7"},
-
{"partitionName":"default@student_orc_partition@part=8"},
-
{"partitionName":"default@student_orc_partition@part=9"}],
-
"input_tables":[{"tablename":"default@student_orc_partition", "tabletype":"MANAGED_TABLE"}]
explain dependency的使用场景有两个:
场景一:快速排除。快速排除因为读取不到相应分区的数据而导致任务数据输出异常。例如,在一个以天分区的任务中,上游任务因为生产过程不可控因素出现异常或者空跑,导致下游任务引发异常。通过这种方式,可以快速查看SQL读取的分区是否出现异常。
场景二:理清表的输入,帮助理解程序的运行,特别是有助于理解有多重子查询,多表连接的依赖输入。
下面通过两个案例来看explain dependency的实际运用:
案例一:识别看似等价的代码
对于刚接触SQL的程序员,很容易将
select * from a inner join b on a.no=b.no and a.f>1 and a.f<3;
等价于
select * from a inner join b on a.no=b.no where a.f>1 and a.f<3;
我们可以通过案例来查看下它们的区别:
代码1:
-
select
-
a.s_no
-
from student_orc_partition a
-
inner join
-
student_orc_partition_only b
-
on a.s_no=b.s_no and a.part=b.part and a.part>=1 and a.part<=2;
代码2:
-
select
-
a.s_no
-
from student_orc_partition a
-
inner join
-
student_orc_partition_only b
-
on a.s_no=b.s_no and a.part=b.part
-
where a.part>=1 and a.part<=2;
我们看下上述两段代码explain dependency的输出结果:
代码1的explain dependency结果:
-
{"input_partitions":
-
[{"partitionName":"default@student_orc_partition@part=0"},
-
{"partitionName":"default@student_orc_partition@part=1"},
-
{"partitionName":"default@student_orc_partition@part=2"},
-
{"partitionName":"default@student_orc_partition_only@part=1"},
-
{"partitionName":"default@student_orc_partition_only@part=2"}],
-
"input_tables": [{"tablename":"default@student_orc_partition","tabletype":"MANAGED_TABLE"}, {"tablename":"default@student_orc_partition_only","tabletype":"MANAGED_TABLE"}]}
代码2的explain dependency结果:
-
{"input_partitions":
-
[{"partitionName":"default@student_orc_partition@part=1"},
-
{"partitionName" : "default@student_orc_partition@part=2"},
-
{"partitionName" :"default@student_orc_partition_only@part=1"},
-
{"partitionName":"default@student_orc_partition_only@part=2"}],
-
"input_tables": [{"tablename":"default@student_orc_partition","tabletype":"MANAGED_TABLE"}, {"tablename":"default@student_orc_partition_only","tabletype":"MANAGED_TABLE"}]}
通过上面的输出结果可以看到,其实上述的两个SQL并不等价,代码1在内连接(inner join)中的连接条件(on)中加入非等值的过滤条件后,并没有将内连接的左右两个表按照过滤条件进行过滤,内连接在执行时会多读取part=0的分区数据。而在代码2中,会过滤掉不符合条件的分区。
案例二:识别SQL读取数据范围的差别
代码1:
-
explain dependency
-
select
-
a.s_no
-
from student_orc_partition a
-
left join
-
student_orc_partition_only b
-
on a.s_no=b.s_no and a.part=b.part and b.part>=1 and b.part<=2;
代码2:
-
explain dependency
-
select
-
a.s_no
-
from student_orc_partition a
-
left join
-
student_orc_partition_only b
-
on a.s_no=b.s_no and a.part=b.part and a.part>=1 and a.part<=2;
以上两个代码的数据读取范围是一样的吗?答案是不一样,我们通过explain dependency来看下:
代码1的explain dependency结果:
-
{"input_partitions":
-
[{"partitionName": "default@student_orc_partition@part=0"},
-
{"partitionName":"default@student_orc_partition@part=1"}, …中间省略7个分区
-
{"partitionName":"default@student_orc_partition@part=9"},
-
{"partitionName":"default@student_orc_partition_only@part=1"},
-
{"partitionName":"default@student_orc_partition_only@part=2"}],
-
"input_tables": [{"tablename":"default@student_orc_partition","tabletype":"MANAGED_TABLE"}, {"tablename":"default@student_orc_partition_only","tabletype":"MANAGED_TABLE"}]}
代码2的explain dependency结果:
-
{"input_partitions":
-
[{"partitionName":"default@student_orc_partition@part=0"},
-
{"partitionName":"default@student_orc_partition@part=1"}, …中间省略7个分区
-
{"partitionName":"default@student_orc_partition@part=9"},
-
{"partitionName":"default@student_orc_partition_only@part=0"},
-
{"partitionName":"default@student_orc_partition_only@part=1"}, …中间省略7个分区
-
{"partitionName":"default@student_orc_partition_only@part=9"}],
-
"input_tables": [{"tablename":"default@student_orc_partition","tabletype":"MANAGED_TABLE"}, {"tablename":"default@student_orc_partition_only","tabletype":"MANAGED_TABLE"}]}
可以看到,对左外连接在连接条件中加入非等值过滤的条件,如果过滤条件是作用于右表(b表)有起到过滤的效果,则右表只要扫描两个分区即可,但是左表(a表)会进行全表扫描。如果过滤条件是针对左表,则完全没有起到过滤的作用,那么两个表将进行全表扫描。这时的情况就如同全外连接一样都需要对两个数据进行全表扫描。
在使用过程中,容易认为代码片段2可以像代码片段1一样进行数据过滤,通过查看explain dependency的输出结果,可以知道不是如此。
3. explain authorization 的用法
通过explain authorization可以知道当前SQL访问的数据来源(INPUTS) 和数据输出(OUTPUTS),以及当前Hive的访问用户 (CURRENT_USER)和操作(OPERATION)。
在 hive cli 中输入以下命令:
-
explain authorization
-
select variance(s_score) from student_tb_orc;
结果如下:
-
INPUTS:
-
default@student_tb_orc
-
OUTPUTS:
-
hdfs://node01:8020/tmp/hive/hdfs/cbf182a5-8258-4157-9194- 90f1475a3ed5/-mr-10000
-
CURRENT_USER:
-
hdfs
-
OPERATION:
-
QUERY
-
AUTHORIZATION_FAILURES:
-
No privilege 'Select' found for inputs { database:default, table:student_ tb_orc, columnName:s_score}
从上面的信息可知:
上面案例的数据来源是defalut数据库中的 student_tb_orc表;
数据的输出路径是hdfs://node01:8020/tmp/hive/hdfs/cbf182a5-8258-4157-9194-90f1475a3ed5/-mr-10000;
当前的操作用户是hdfs,操作是查询;
观察上面的信息我们还会看到AUTHORIZATION_FAILURES信息,提示对当前的输入没有查询权限,但如果运行上面的SQL的话也能够正常运行。为什么会出现这种情况?Hive在默认不配置权限管理的情况下不进行权限验证,所有的用户在Hive里面都是超级管理员,即使不对特定的用户进行赋权,也能够正常查询。
通过上面对explain的介绍,可以发现explain中有很多值得我们去研究的内容,读懂 explain 的执行计划有利于我们优化Hive SQL,同时也能提升我们对SQL的掌控力。

- Hive SQL底层执行原理 -
本节结构采用宏观着眼,微观入手,从整体到细节的方式剖析 Hive SQL 底层原理。第一节先介绍 Hive 底层的整体执行流程,然后第二节介绍执行流程中的 SQL 编译成 MapReduce 的过程,第三节剖析 SQL 编译成 MapReduce 的具体实现原理。

- Hive 底层执行架构 -
我们先来看下 Hive 的底层执行架构图, Hive 的主要组件与 Hadoop 交互的过程:
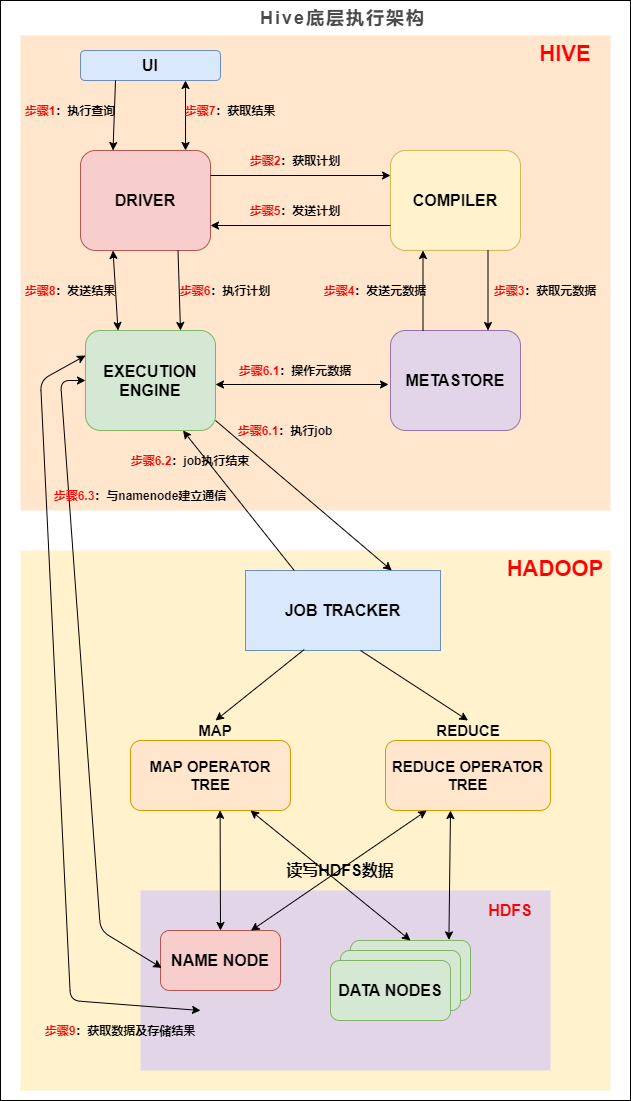
在 Hive 这一侧,总共有五个组件:
UI:用户界面。可看作我们提交SQL语句的命令行界面。
DRIVER:驱动程序。接收查询的组件。该组件实现了会话句柄的概念。
COMPILER:编译器。负责将 SQL 转化为平台可执行的执行计划。对不同的查询块和查询表达式进行语义分析,并最终借助表和从 metastore 查找的分区元数据来生成执行计划.
METASTORE:元数据库。存储 Hive 中各种表和分区的所有结构信息。
EXECUTION ENGINE:执行引擎。负责提交 COMPILER 阶段编译好的执行计划到不同的平台上。
上图的基本流程是:
步骤1:UI 调用 DRIVER 的接口;
步骤2:DRIVER 为查询创建会话句柄,并将查询发送到 COMPILER(编译器)生成执行计划;
步骤3和4:编译器从元数据存储中获取本次查询所需要的元数据,该元数据用于对查询树中的表达式进行类型检查,以及基于查询谓词修建分区;
步骤5:编译器生成的计划是分阶段的DAG,每个阶段要么是 map/reduce 作业,要么是一个元数据或者HDFS上的操作。将生成的计划发给 DRIVER。
如果是 map/reduce 作业,该计划包括 map operator trees 和一个 reduce operator tree,执行引擎将会把这些作业发送给 MapReduce :
步骤6、6.1、6.2和6.3:执行引擎将这些阶段提交给适当的组件。在每个 task(mapper/reducer) 中,从HDFS文件中读取与表或中间输出相关联的数据,并通过相关算子树传递这些数据。最终这些数据通过序列化器写入到一个临时HDFS文件中(如果不需要 reduce 阶段,则在 map 中操作)。临时文件用于向计划中后面的 map/reduce 阶段提供数据。
步骤7、8和9:最终的临时文件将移动到表的位置,确保不读取脏数据(文件重命名在HDFS中是原子操作)。对于用户的查询,临时文件的内容由执行引擎直接从HDFS读取,然后通过Driver发送到UI。

- 总结 -
通过上面的内容我们发现,shuffle阶段堪称性能的杀手,为什么这么说,一方面shuffle阶段是最容易引起数据倾斜的;另一方面shuffle的过程中会产生大量的磁盘I/O、网络I/O 以及压缩、解压缩、序列化和反序列化等。这些操作都是严重影响性能的。
所以围绕shuffle和数据倾斜有很多的调优点:
Mapper 端的Buffer 设置为多大?Buffer 设置得大,可提升性能,减少磁盘I/O ,但 是对内存有要求,对GC 有压力;Buffer 设置得小,可能不占用那么多内存, 但是可能频繁的磁盘I/O 、频繁的网络I/O 。
公众号推送规则变了
点击上方公众号名片,收藏公众号,不错过精彩内容推送!



文章来源: dataclub.blog.csdn.net,作者:数据社,版权归原作者所有,如需转载,请联系作者。
原文链接:dataclub.blog.csdn.net/article/details/123343553

- 点赞
- 收藏
- 关注作者
评论(0)