Redis 的缓存策略

各位小伙伴们大家好,欢迎来到这个小扎扎的Redis 6专栏,在这个系列专栏中我对B站黑马的Redis教程进行一个总结,鉴于 看到就是学到、学到就是赚到 精神,这波依然是血赚 ┗|`O′|┛
🍖 Redis缓存中间件
🥩 缓存是什么
所谓缓存就是数据交换的缓冲区(称作Cache [ kæʃ ] ),是一个临时存贮数据的地方,一般读写性能较高。CPU的运算速度要远远大于内存的读写速度,这样会使CPU花费很长时间等待数据从内存的获取或者写入,因此缓存的出现主要就是为了解决CPU运算速度与内存读写速度不匹配的矛盾
说了半天缓存和web开发有什么必要的联系嘛?当然有,在整个web开发的各个阶段都可以使用到不同缓存,比如浏览器缓存页面等静态资源,tomcat服务器应用层缓存查询过的数据,数据库缓存索引信息等 缓存的优点
缓存的优点
- 降低后端负载
- 提高读写效率,降低响应时间
缓存的缺点
- 数据更新前后缓存区中该数据的一致性难保证
- 解决数据一致性需要复杂的业务代码,提高后续维护成本
- 集群模式下提高运维成本
🥩 Redis缓存已查询数据
在未使用缓存之前,用户的所有请求都会直接访问数据库,但是使用redis作为缓存之后就不一样了。用户的请求会是先在redis中查找,如果查到也就是命中的话就直接返回客户端,如果未命中的话就去数据库中查找,查到有结果就将查询到的结果写入redis中,然后返回给客户端;未查到结果就返回404状态码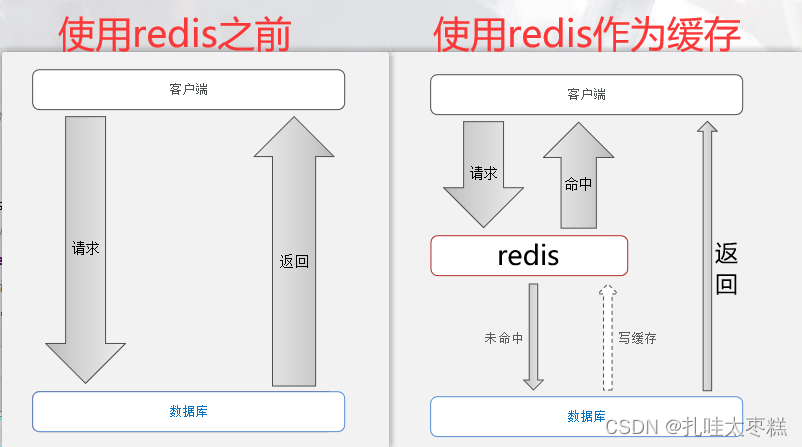
🥩 redis缓存中间件实践
黑马点评中有这么一个业务:点击商铺图片会通过id查询该商铺的相关信息,如果使用redis缓存的话,后期再访问该商铺的话就会直接到redis中查询,可以大大缩短查询所需时间
collector中定义与前端交互的方法,前端请求/shop-type/list?id=xx
@RestController
@RequestMapping("/shop")
public class ShopController {
@Resource
public IShopService shopService;
/**
* 根据id查询商铺信息
* @param id 商铺id
* @return 商铺详情数据
*/
@GetMapping("/{id}")
public Result queryShopById(@PathVariable("id") Long id) {
return shopService.queryById(id);
}
}
编写typeService里业务逻辑方法getList的接口和实现类,逻辑参考Redis缓存已查询数据的相关分析
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Override
public Result queryById(Long id) {
// 从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(RedisConstants.CACHE_SHOP_KEY + id);
// 判断该商铺是否存在
if (StrUtil.isNotBlank(shopJson)) {
// 存在直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
// 不存在查询数据库
Shop shop = getById(id);
if (shop == null) {
// 数据库中不存在直接返回错误信息
return Result.fail("店铺不存在");
}
// 数据库中存在写入redis
stringRedisTemplate.opsForValue().set(RedisConstants.CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(shop));
// 返回
return Result.ok(shop);
}
}
经实验验证得知,使用redis缓存未命中时查询耗时将近200毫秒,后续查询命中之后只需几毫秒,可见redis作为缓存中间件对数据读取的功效还是很高的
🍖 缓存更新
之前介绍redis的时候介绍过redis缓存的一些缺点,比如数据库中数据更新前后缓存区中该数据的一致性难保证,该怎么应对redis缓存的这个缺点呢?这就引出接下来的学习内容——缓存更新策略
🥩 缓存更新的三个策略
内存淘汰: redis底层的内存淘汰机制,无需我们自己维护,当内存不足时自动淘汰部分数据,下次查询时更新缓存。这种机制的优点是维护成本极低,但是缺点也很明显,由于淘汰数据的不确定性导致很难保证数据的一致性
超时剔除: 向redis中添加缓存数据的时候设置TTL时间,到期后自动删除缓存,下次查询时更新缓存。这种机制维护成本不是很高,但是数据一致性同样无法做到很高的保证,因为设置之后数据的有效期就固定了,但是更新时间不固定,若是数据在超时剔除之前发生更新然后查询,得到的仍是更新之前的数据
主动更新: 使用代码在修改数据库的同时更新缓存。这种策略能够保证很高的数据一致性,但是伴随而来的就是更高的维护成本,要在每一个更改语句后面加上redis缓存更新
具体使用哪种策略取决于该业务对数据一致性的需求:一致性需求不高的话,可以使用内存淘汰策略。一致性需求较高的话,可以使用主动更新加上超时剔除策略,保证了较高的一致性
🥩 主动更新策略的三种方案
代码(Cache Aside Pattern):最直接的一种方案,使用代码在修改数据库的同时更新缓存
服务(Read/Warite Through Pattern):将redis缓存与数据库整合为一个服务,由这个服务来维护数据的一致性,在更新数据库时只需要调用该服务即可,无需关心服务底层的业务逻辑,类似于封装。但是市面上没有现成的服务可以使用,自己封装这么一个服务也很复杂,所以说这种方案可用性很差
写回(Write Behind Caching Pattern):所有数据库的CRUD操作都在redis缓存中完成,由另外一个独立的线程异步的将缓存中的数据持久化到数据库中,以此来保证数据的最终一致。这种方案有个很大的好处,那就是极大地减少了对数据库的操作,如果主线程在另一个线程两次持久化之间对redis中的数据操作多次,数据库中只会执行最后一次操作,而不是也操作多次。但是也有坏处,那就是如果还没等到另一个线程持久化数据库,此时redis缓存发生宕机,缓存大多数在内存中,此时发生宕机就会导致缓存中的数据消失,数据库中的数据就与宕机前redis中的数据不一致
综上所述,虽然Cache Aside Pattern方案是最复杂的一个,但是他也同样是最可靠的一个,于是我们选择它来进行接下来的代码学习
主动更新策略注意项
数据库发生更新的时候直接删除缓存中的该数据,而不是跟着更新缓存,因为如果发生连续修改多次的情况,更新缓存的话更新次数等于数据库的更新次数;如果是删除缓存数据的话就只需要删除一次,下一次查询直接从数据库中查询再写入缓存。
删除缓存数据和数据库操作应该保证原子性,也就是说删除缓存数据操作和数据库操作应该同时成功或者同时失败,那么该如何实现呢?单体式系统中,可以通过将两个操作放在一个事务中来完成;分布式系统中可以利用TCC等分布式事务方案来实现
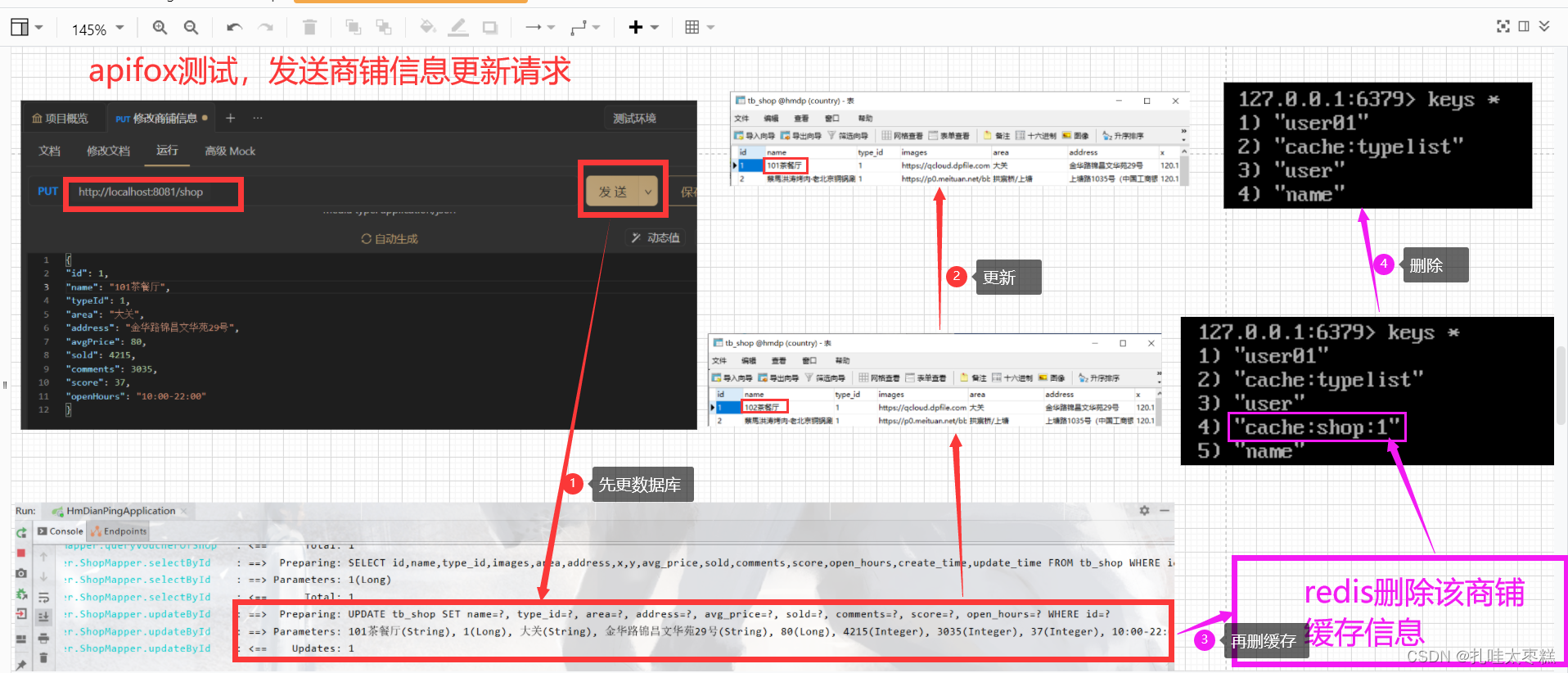
删除缓存数据操作和数据库操作的先后顺序是什么? 应该是先写数据库再删除缓存,原因是这种方式发生线程安全性问题的可能较小
🥩 主动更新的代码实现
controller层前端交互
/**
* 更新商铺信息
* @param shop 商铺数据
* @return 无
*/
@PutMapping
public Result updateShop(@RequestBody Shop shop) {
// 写入数据库
return shopService.update(shop);
}
需要server的update方法,创建接口和实现类完成业务逻辑代码编写。主动更新+超时剔除的策略就只有两步,那就是在写缓存的时候设置超时时间,更新数据库之后删除缓存
// 数据库中存在写入redis的时候设置超时时间
stringRedisTemplate.opsForValue().set(RedisConstants.CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(shop), RedisConstants.CACHE_SHOP_TTL, TimeUnit.MINUTES);
/**
* 更新商铺信息
* @param shop 商铺信息
* @return 前端返回数据
*/
@Override
@Transactional
public Result update(Shop shop) {
if (shop.getId() == null) {
return Result.fail("店铺id不能为空");
}
// 更新数据库
updateById(shop);
// 删除缓存
stringRedisTemplate.delete(RedisConstants.CACHE_SHOP_KEY + shop.getId());
// 返回
return Result.ok();
}

- 点赞
- 收藏
- 关注作者
评论(0)