【源码阅读】结构特征提取算法:ReFex

@TOC

简介
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力💪
本文仅记录自己感兴趣的内容
论文简介
原文链接:It’s Who You Know: Graph Mining Using Recursive Structural Features
会议:Acm Sigkdd International Conference on Knowledge Discovery & Data Mining (CCF-A)
年度:2012
方法简述
refex特征提取步骤:
- 提取节点基础特征(例如:度…)
- 递归融合邻域特征
- 每一次递归,融合其节点的邻域特征
- 首先,对邻域特征进行聚合操作(比如,求和sum,求均值mean…)
- 然后,与原特征进行对比,选择有用的特征并入原特征(如果把节点邻域特征全加入到旧特征,那么特征维度则会特别大,我们只需要选择加入特征会提高原特征效果的特征)
- 最后,完成多次递归后,对特征进行二值化(binarize)处理
- 得到节点结构特征
源码阅读
主体框架
def create_features(self):
# 基本节点级特征提取和诱导子图创建开始。
state_printer("Basic node level feature extraction and induced subgraph creation started.")
self.basic_stat_extractor()
# 递归开始。
state_printer("Recursion started.")
self.do_recursions()
# 二进制特征量化开始。
state_printer("Binary feature quantization started.")
self.binarize()
state_printer("Saving the raw features.")
self.dump_to_disk()
state_printer("The number of extracted features is: " + str(self.new_features.shape[1]) + ".")
refex主要分为四步
- 提取节点基本特征 basic_stat_extractor()
- 递归融合邻域特征 do_recursions()
- 二值化 binarize()
- 存储结果 dump_to_disk()
提取节点基本特征:basic_stat_extractor()
# 提取节点的基本节点特征 & 创建诱导子图
def basic_stat_extractor(self):
self.base_features = []
self.sub_graph_container = {} # dict key:节点 value:邻域节点集
for node in tqdm(range(0,len(self.nodes))):
sub_g, overall_counts, nebs = inducer(self.graph, node)
in_counts = len(nx.edges(sub_g))
self.sub_graph_container[node] = nebs
deg = nx.degree(sub_g, node)
trans = nx.clustering(sub_g, node) # 计算节点对应子图中三角形的数量
self.base_features.append([in_counts, overall_counts, float(in_counts)/float(overall_counts), float(overall_counts - in_counts)/float(overall_counts),deg, trans])
self.features = {}
# note: 这里features是一个dict key=0 对应value为节点的基础特征
self.features[0] = np.array(self.base_features)
print("")
del self.base_features
遍历每个节点,得到每个节点的基础特征,同时记录下每个节点的邻域节点
最后返回一个features,类型dict,使用key = 0标记为原特征(基础特征),便于后面与得到的邻域特征进行选择、聚合
- base_features, list类型,用于存储每个节点的基础特征
- sub_graph_container,dict类型,存储每个节点的邻域节点
- 文中记录了6种基础特征(使用networkx库进行的一系列图特征的提取)
递归融合邻域特征:do_recursions()
# 递归
def do_recursions(self):
for recursion in range(0,self.args.recursive_iterations):
state_printer("Recursion round: " + str(recursion+1) + ".")
new_features = self.single_recursion(recursion)
# pruning_cutoff 默认 0.5
new_features = sub_selector(self.features[recursion], new_features, self.args.pruning_cutoff)
self.features[recursion+1] = new_features
# 拼接所有特征矩阵
self.features = np.concatenate(self.features.values(), axis = 1)
# 归一化
self.features = self.features / (np.max(self.features)-np.min(self.features))
每一次递归
- 先运行single_recursion(), 得到邻域节点的聚合特征
- 再运行sub_selector(), 对比上一特征,在此次所有特征中进行选择需要的特征
- 因为features为dict,features[0]表示基础特征,features[1]表示第一次递归得到的特征,features[2]表示第二次递归得到的特征…, 所以最后再使用np.concatenate进行所有特征的拼接,得到一个特征矩阵(相当于就是把所有特征拼接在一起了)
- 最后再进行归一化处理
单次递归聚合:single_recursion()
def single_recursion(self, i):
features_from_previous_round = self.features[i].shape[1] # 上一层特征的特征维度
# new_features [N, features_from_previous_round * multiplier]
# 新特征的特征维度
new_features = np.zeros((len(self.nodes), features_from_previous_round * self.multiplier))
for k in tqdm(range(0,len(self.nodes))):
selected_nodes = self.sub_graph_container[k] # 节点k的邻域集
main_features = self.features[i][selected_nodes,:] # 节点k的邻域集对应的特征(上一层特征)
# 对邻域节点集的特征进行聚合操作 aggregator()
# 得到新一层的特征
new_features[k,:]= reduce(lambda x,y: x+y,[self.aggregator(main_features[:,j]) for j in range(0,features_from_previous_round)])
return new_features
注意这里新特征的维度为:(len(self.nodes), features_from_previous_round * self.multiplier)
那么对于一个node来说,new_feature的大小为 features_from_previous_round * self.multiplier
self.multiplier为聚合操作的操作数量
比如:def aggregator(x):
return [np.sum(x),np.mean(x)]
那么self.multiplier = 2, 因为有sum、mean两种操作
以一个节点的特征聚合为例:
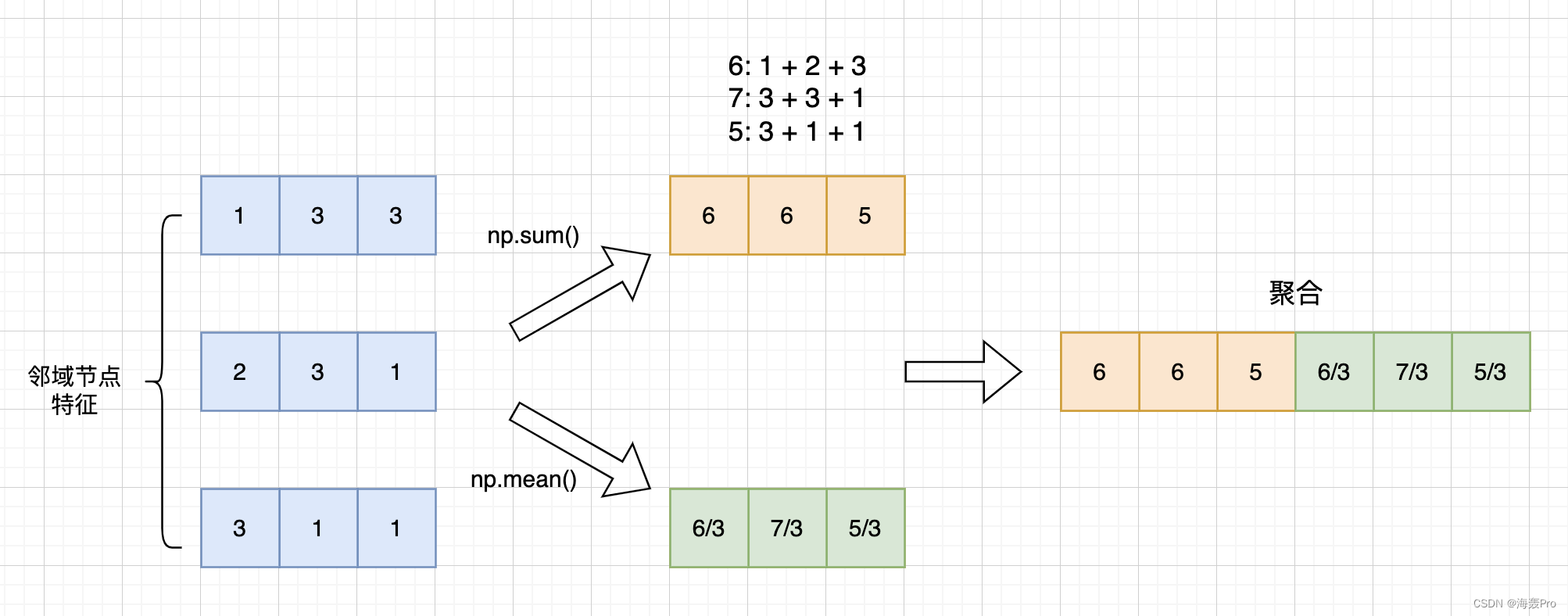
上图为一个特例,当j = features_from_previous_round - 1时(便于一点理解)
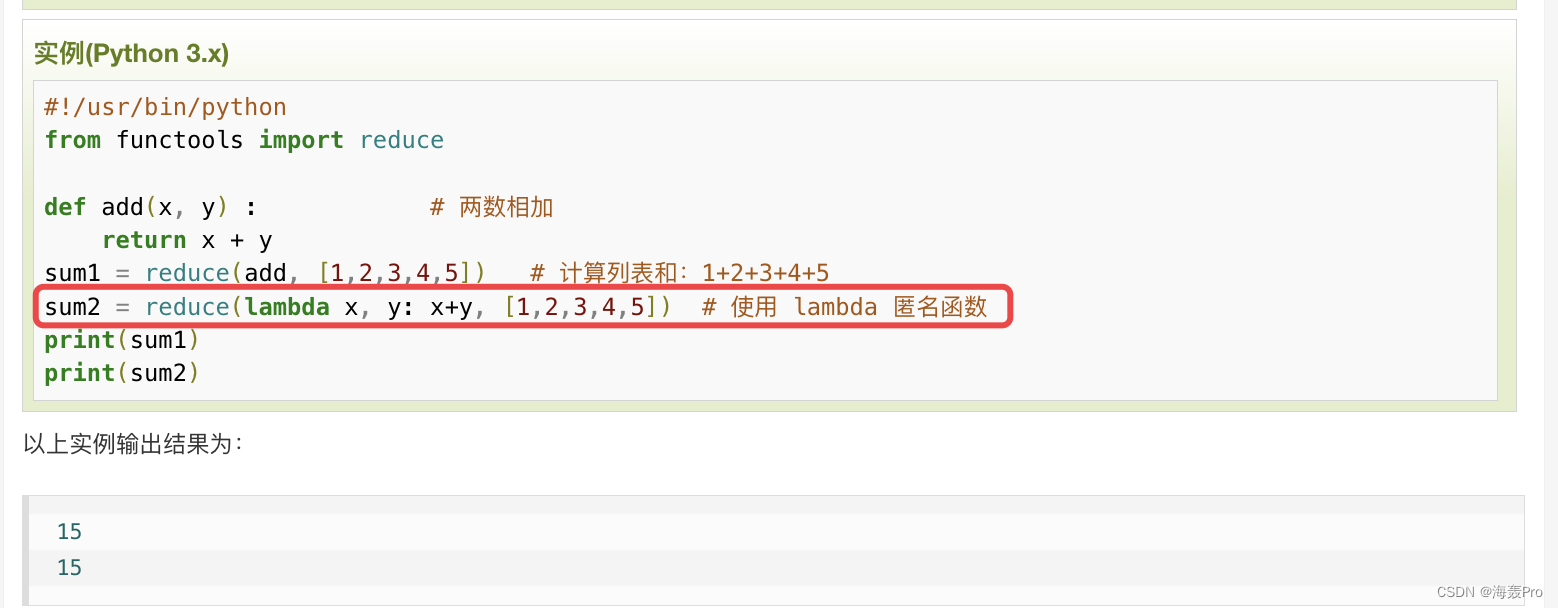
我们需要注意这句代码:reduce(lambda x,y: x+y,[self.aggregator(main_features[:,j]) for j in range(0,features_from_previous_round)])
先看reduce的举例
也就是可以理解为进行一个累积的操作(对参数序列中元素进行累积)
参考:https://www.runoob.com/python/python-func-reduce.html
所以,其实完整的聚合应是:
- main_features[:0]先进行aggregator()
- main_features[:1]再进行aggregator()
- …
- main_features[: features_from_previous_round - 1]再进行aggregator()【上面的示例图】

特征选择:sub_selector()
# 新特征 对比 旧特征 选择新特征中一些特需的特征点加入旧特征
def sub_selector(old_features, new_features, pruning_threshold):
print("Cross-temporal feature pruning started.")
indices = set()
for i in tqdm(range(0,old_features.shape[1])):
for j in range(0, new_features.shape[1]):
c = np.corrcoef(old_features[:,i], new_features[:,j])
if abs(c[0,1]) > pruning_threshold:
indices = indices.union(set([j]))
keep = list(set(range(0,new_features.shape[1])).difference(indices))
new_features = new_features[:,keep]
indices = set()
return new_features
这里的思路就是
- 双重遍历原、新特征,进行两两比较
- 若两特征之间相似度(暂且称为相似度)大于我们设置的一个阈值
- 则将这个新特征加入原特征中
- 本质就是:新特征中的单个特征(每一列)与原特征进行相似分析,大于阈值,说明此特征可以保留,就可以存入原特征中
np.corrcoef就是计算两组数据的皮尔逊积矩相关系数
暂且将old_features[:,i]记为a,new_features[:,j]记为b
np.corrcoef(a, b)的结果就是
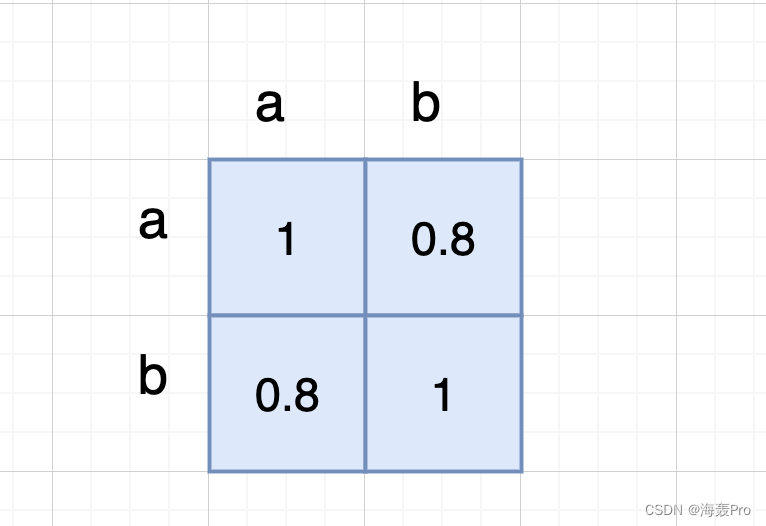
1表示a与a的皮尔逊积矩相关系数(暂且理解为相似性)
0.8表示a与b的皮尔逊积矩相关系数(暂且理解为相似性)
所以这里返回c[0,1],也就是返回两个特征的相似性(大于设定的阈值,则可以保留)
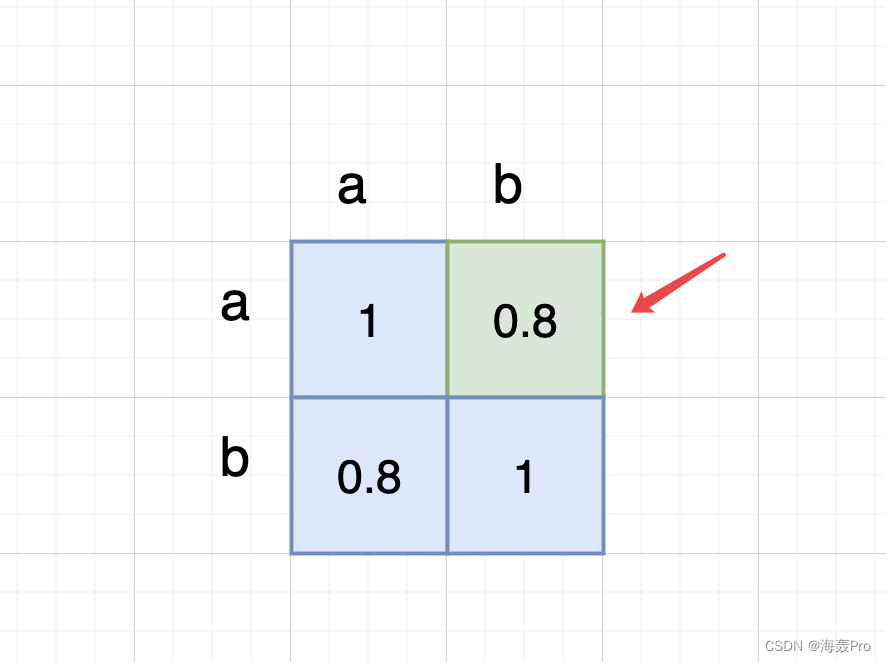
代码中的实现则是,记录下j的坐标,放入set中,最后再统一提取其特征至new_features
二值化:binarize()
# 二值化
def binarize(self):
self.new_features = []
for x in tqdm(range(0,self.features.shape[1])):
try:
self.new_features = self.new_features + [pd.get_dummies(pd.qcut(self.features[:,x],self.args.bins, labels = range(0,self.args.bins), duplicates = "drop"))]
except:
pass
self.new_features = pd.concat(self.new_features, axis = 1)
这里就是将features中的值映射到0到
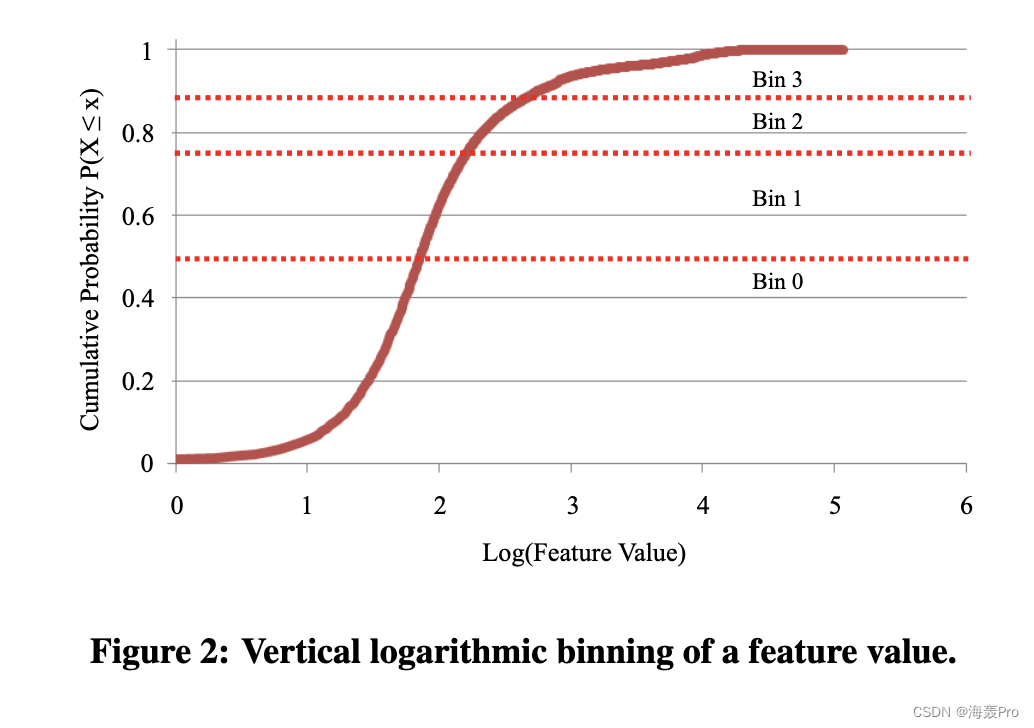
结合pd.qcut()函数进行理解
其实就是对特征数据进行一个按箱分配,前百分之多少标记为0,后面一次标记为1,2,…,self.args.bins


参考:https://zhuanlan.zhihu.com/p/144234097?from_voters_page=true
最后再使用one-hot编码即可
使其变为0、1
存储结果:dump_to_disk()
这里就是存储features至csv文件
def dump_to_disk(self):
self.new_features.columns = map(lambda x: "x_" + str(x), range(0,self.new_features.shape[1]))
self.new_features.to_csv(self.args.recursive_features_output, index = None)
结语
文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正


- 点赞
- 收藏
- 关注作者
评论(0)