Elasticsearch聚合的嵌套桶如何排序

【摘要】 在elasticsearch的聚合查询中,经常对聚合的数据再次做聚合处理,这样的聚合结果如何进行排序呢,本文将对此展开讨论和实践
关于嵌套桶
- 在elasticsearch的聚合查询中,经常对聚合的数据再次做聚合处理,例如统计每个汽车品牌下的每种颜色汽车的销售额,这时候DSL中就有了多层aggs对象的嵌套,这就是嵌套桶(此名称来自《Elasticsearch 权威指南》),如下图所示:
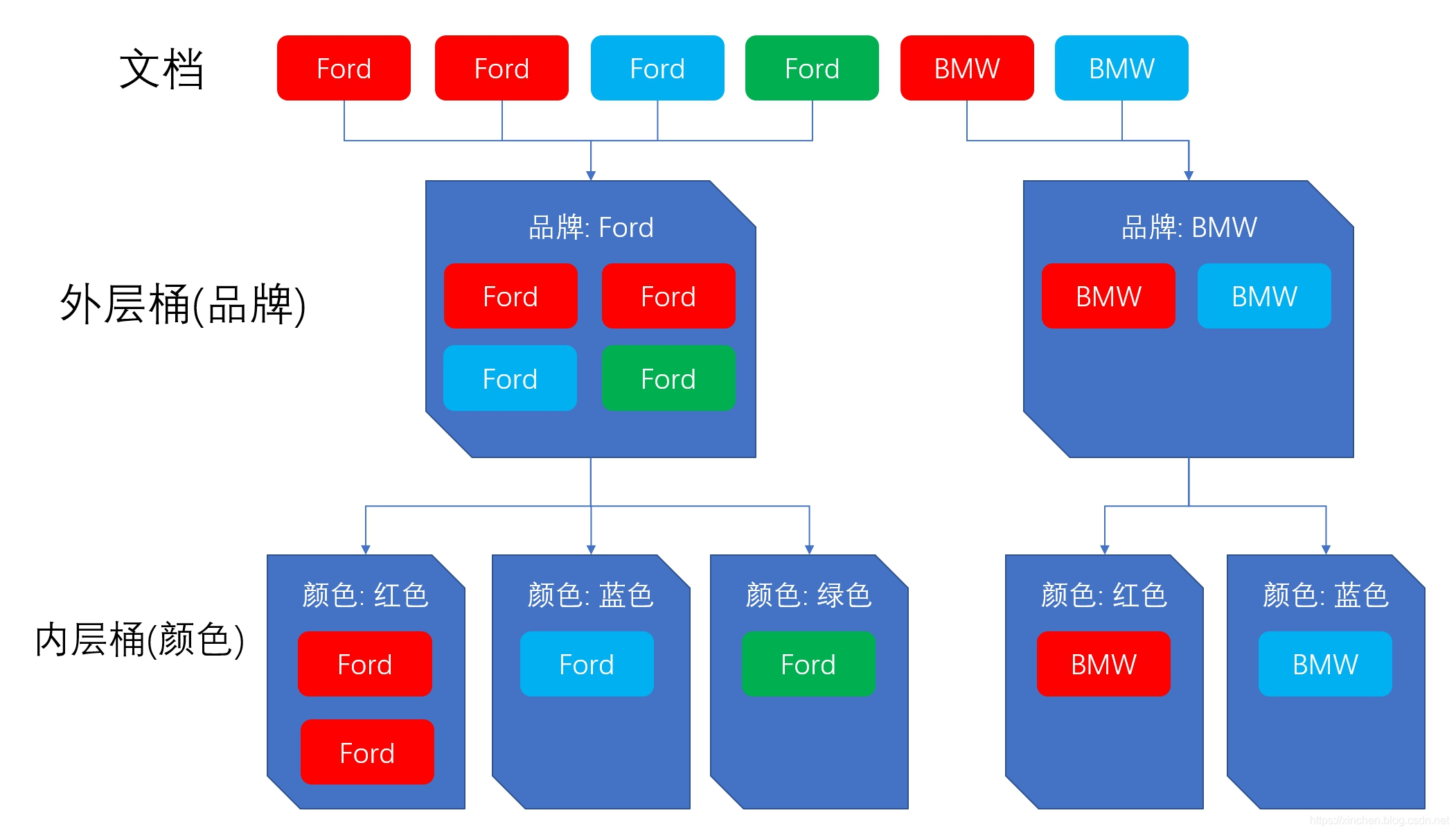
- 今天要讨论的就是在执行类似上述嵌套桶聚合时,返回的数据如何排序。首先咱们先把环境和数据准备好。
环境信息
- 以下是本次实例的环境信息,请确保您的Elasticsearch可以正常运行:
- 操作系统:Ubuntu 18.04.2 LTS
- JDK:1.8.0_191
- Elasticsearch:6.7.1
- Kibana:6.7.1
实例数据
-
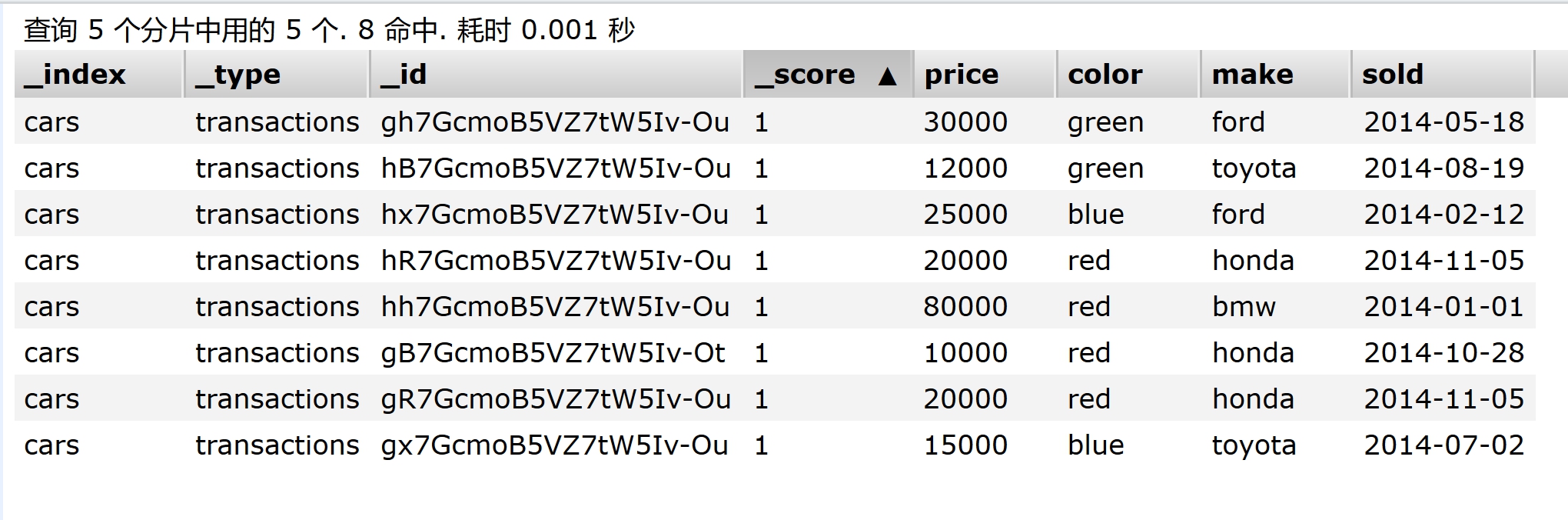
查询用到的数据是个名为cars的索引,里面保存了多条汽车销售记录,字段有品牌(make)、颜色(color)、价格(price)、售卖时间(sold)等,在elasticsearch-head查看数据如下图:

-
如果您想将上图中的数据导入到自己的es环境,请参考《Elasticsearch聚合学习之一:基本操作》,文中有详细的导入步骤;
对内层桶排序
-
针对前面提到的需求:统计每个汽车品牌下的每种颜色汽车的销售额,通常做法是:先按照品牌聚合,生成的每个桶(bucket)内有这个品牌的所有销售记录,然后将每个桶内的文档再按照颜色聚合,这样每个桶内就有多个子桶,每个子桶内就是每个品牌下每种颜色的销售记录。
-
既然每个桶内有多个子桶,那么就可以对这些子桶桶进行排序,如下图,可以对红框内的数据进行排序:
-
请求DSL如下:

GET /cars/transactions/_search
{
"size": 0,
"aggs": {
"make_agg": {
"terms": { ---外层桶,按照汽车品牌聚合
"field": "make" ---字段是make
},
"aggs": {
"color_agg": {
"terms": { ---内层桶,按照汽车颜色聚合
"field": "color", ---字段是color
"order": { ---要求内层桶排序
"make_color_sales_rank": "desc" ---排序字段是make_color_sales_rank,降序
}
},
"aggs": {
"make_color_sales_rank": { ---聚合字段是make_color_sales_rank
"sum": { ---metrics处理,类型是累加和
"field": "price" ---累加值取自price字段的值
}
}
}
}
}
}
}
}
- 响应数据如下,可见buckets内的每个对象自身也有buckets数组,里面的每个元素就是子桶,这些子桶是已经排序过了的:
......
"aggregations" : {
"make_agg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "ford",
"doc_count" : 2,
"color_agg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ ---buckets内每个元素是一个子桶,这些数据已按照make_color_sales_rank的值降序排序
{
"key" : "green",
"doc_count" : 1,
"make_color_sales_rank" : {
"value" : 30000.0
}
},
{
"key" : "blue",
"doc_count" : 1,
"make_color_sales_rank" : {
"value" : 25000.0
}
}
]
}
},
{
"key" : "toyota",
"doc_count" : 2,
"color_agg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ ---buckets内每个元素是一个子桶,这些数据已按照make_color_sales_rank的值降序排序
{
"key" : "blue",
"doc_count" : 1,
"make_color_sales_rank" : {
"value" : 15000.0
}
},
{
"key" : "green",
"doc_count" : 1,
"make_color_sales_rank" : {
"value" : 12000.0
}
}
]
}
},
......
- 此时,外层桶并没有排序。
整体排序
-
前面的示例只是对内层桶做了排序,外层桶是没有排序的,接下来看看如何做整体排序。
-
要想整体排序,一定要区分不同的内层桶的特点,才能做排序,总的来说分为以下几种情况:
-
内层桶是外层桶的数据聚合生成的,在前面的示例中,外层桶是都是某个品牌的汽车,对桶内数据按照颜色聚合,得到了内层桶,如下图:

- 对于这样的数据,无法做整体排序,因为内层桶的结果属于多值,而整体排序只能基于单值进行,以下是《Elasticsearch 权威指南》的说明,见红框内描述:

- 内层桶是外层桶的数据过滤生成的,例如统计每个汽车品牌下红色汽车的销售额,先按照品牌聚合,再对外层桶按照颜色做过滤,这样的嵌套是可以用内层桶字段的值来排序的,DSL如下:
GET /cars/transactions/_search
{
"size": 0,
"aggs": {
"makes": { ---外层桶字段名
"terms": {
"field": "make",
"order": {
"colors>sales": "asc" ---用大于号连接嵌套桶的层次
}
},
"aggs": {
"colors": { ---内层桶字段名
"filter": {
"terms": {
"color": [
"red",
"green"
]
}
},
"aggs": {
"sales": { ---metrics处理后的字段名
"sum": { ---metrics类型是求累加和
"field": "price"
}
}
}
}
}
}
}
}
- 返回数据如下所示,是按照sales字段做的排序:
......
"aggregations" : {
"makes" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "ford",
"doc_count" : 2,
"colors" : {
"doc_count" : 0,
"sales" : {
"value" : 0.0
}
}
},
{
"key" : "toyota",
"doc_count" : 2,
"colors" : {
"doc_count" : 0,
"sales" : {
"value" : 0.0
}
}
},
{
"key" : "honda",
"doc_count" : 3,
"colors" : {
"doc_count" : 3,
"sales" : {
"value" : 50000.0
}
}
},
{
"key" : "bmw",
"doc_count" : 1,
"colors" : {
"doc_count" : 1,
"sales" : {
"value" : 80000.0
}
}
}
]
}
}
}
-
对于嵌套桶,是否能进行整体排序的关键就在于整个嵌套路径中,是否有多值的桶出现,如果没有就可以用嵌套内部的字段进行排序,除了上面的filter,还有global 和reverse_nested 这两种桶类型生成的也是单值桶,因此也可以用其内部的字段进行排序;
-
至此,嵌套桶的聚合结果排序已经实践完毕了,希望您在面对类似排序问题时,此文能给您一些参考。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)