Elasticsearch聚合学习之一:基本操作

【摘要】 Elasticsearch的聚合是常用的功能,此三部曲系列通过实战来熟悉和了解常用的聚合命令和参数
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
本篇概览
- 聚合是我们在使用elasticsearch服务时常用的功能,从本篇起,一起通过实战来学习和掌握聚合的有关知识;
系列文章列表
- 《Elasticsearch聚合学习之一:基本操作》;
- 《Elasticsearch聚合学习之二:区间聚合》;
- 《Elasticsearch聚合学习之三:范围限定》;
- 《Elasticsearch聚合学习之四:结果排序》;
关于聚合
- 通过搜索,我们可找到匹配查询条件的文档集;
- 通过聚合,我们会得到一个数据的概念,以汽车销售信息为例,以下都是聚合数据:
- 有多少中颜色;
- 每辆车的平均价格是多少;
- 按照汽车的颜色来划分,每个颜色的销售量是多少;
- 学习Elasticsearch聚合的第一步就是理解两个概念:桶(Buckets)和指标(Metrics)
桶(Buckets)
- 桶是指满足特定条件的文档的集合,例如按照汽车颜色分类,如下图,每个颜色都有一个桶,里面放的是所有这个颜色的文档:

指标(Metrics)
-
指标是对桶内的文档进行统计计算,如统计红色汽车的数量、最低价、最高价、平均售价、总销售额等,这些都是根据桶中的文档的值来计算的;
-
基本概念有所了解后一起通过实战来学习和掌握聚合的知识;
环境信息
- 以下是本次实战的环境信息,请确保您的Elasticsearch可以正常运行:
- 操作系统:Ubuntu 18.04.2 LTS
- JDK:1.8.0_191
- Elasticsearch:6.7.1
- Kibana:6.7.1
导入实战数据
- 本次实战用到的数据来自《Elasticsearch权威指南》的示例;
- 实战会用到名为cars的索引,里面的每个文档是一条汽车销售记录,具体字段定义如下:
| 字段 | 类型 | 作用 |
|---|---|---|
| price | long | 汽车售价 |
| color | text | 汽车颜色 |
| make | text | 汽车品牌 |
| sold | date | 销售日期 |
- 通过静态映射的方式来创建索引,在Kibana的Dev Tools页面执行以下命令,就会创建cars索引和transactions类型,并且指定了每个字段的定义:
PUT /cars
{
"mappings" : {
"transactions" : {
"properties" : {
"color" : {
"type" : "keyword"
},
"make" : {
"type" : "keyword"
},
"price" : {
"type" : "long"
},
"sold" : {
"type" : "date"
}
}
}
}
}
- 导入数据:
POST /cars/transactions/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }
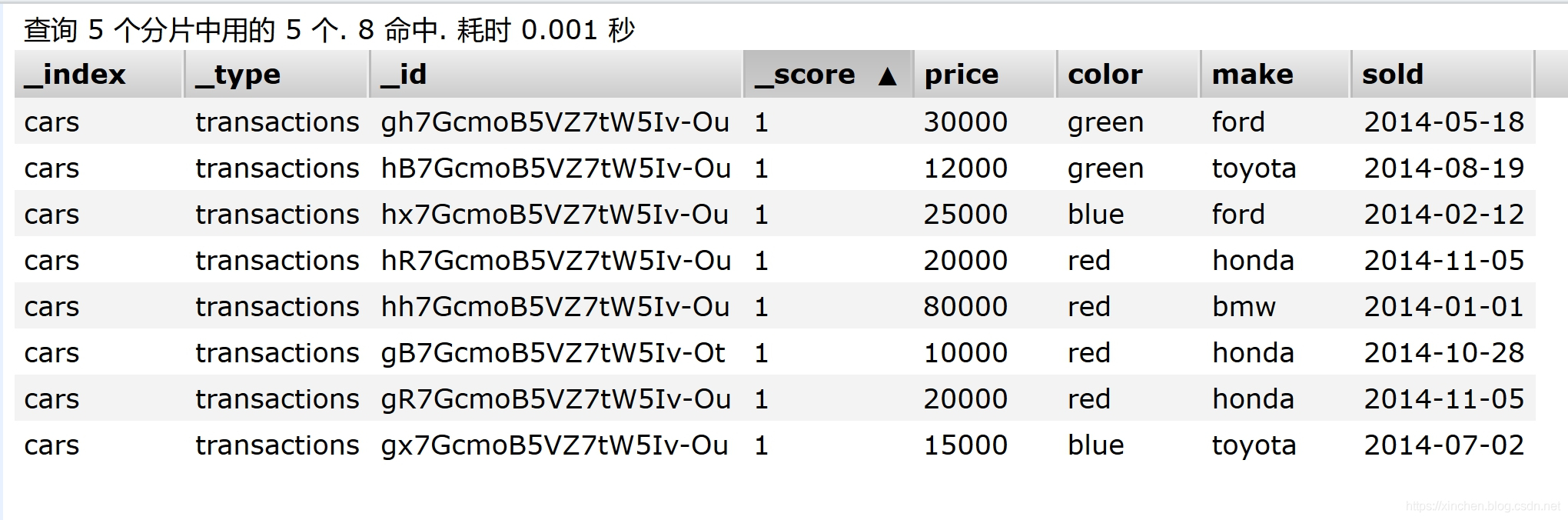
- 通过head插件看到新建的索引cars的所有数据如下图,例如第一条记录,表示售价30000,汽车颜色是绿色,品牌是ford,销售时间是2014年5月8日:

最简单的聚合:terms桶
- 第一个聚合命令是terms桶,相当于SQL中的group by,将所有记录按照颜色聚合,执行以下查询命令:
GET /cars/transactions/_search
{
"size":0,
"aggs":{
"popular_colors":{
"terms": {
"field": "color"
}
}
}
}
- 收到响应如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 8,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"popular_colors" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "red",
"doc_count" : 4
},
{
"key" : "blue",
"doc_count" : 2
},
{
"key" : "green",
"doc_count" : 2
}
]
}
}
}
- 现在对查询命令中的参数做出解释:
- size设置为0,这样返回的hits字段为空(hits不是我们本次查询关心的内容),这样可以提高查询速度;
- aggs:聚合操作都被至于aggs之下,注意aggs是顶层参数,另外使用aggregations替代aggs也可以;
- popular_colors:为聚合的类型指定名称,本次是按照颜色来聚合的,所以起名为popular_colors,响应内容中可以看到该字段的聚合结果如下:
aggregations" : {
"popular_colors" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "red",
"doc_count" : 4
},
{
"key" : "blue",
"doc_count" : 2
},
...
-
terms:在聚合的时候,桶的类型有很多种,terms是常用的一种,作用是按照指定字段来聚合,例如本例指定了color字段,所以所有color为red的文档聚合到一个桶,green的文档聚合到另一个桶,实际上桶类型是有很多种的,常见的类型在后面的实战中会用到,更多详细内容请参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.0/search-aggregations-bucket.html
-
field的值就是terms桶指定的聚合字段,这里是color字段;
-
接下来看看返回的信息,aggregations就是聚合结果,popular_colors是我们指定的别名,buckets是个json数组,里面的每个json对象都是一个桶,里面的doc_count就是记录数;例如结果中的第一条记录就是红色汽车的销售记录;
添加度量指标
- 上面的示例返回的是每个桶中的文档数量,接下es支持丰富的指标,例如平均值(Avg)、最大值(Max)、最小值(Min)、累加和(Sum)等,接下来试试累加和的用法;
- 下面请求的作用是统计每种颜色汽车的销售总额:
GET /cars/transactions/_search
{
"size":0,
"aggs":{
"colors":{
"terms": {
"field": "color"
},
"aggs":{
"sales":{
"sum":{
"field":"price"
}
}
}
}
}
}
- 收到响应如下:
{
"took" : 17,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 8,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"colors" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "red",
"doc_count" : 4,
"sales" : {
"value" : 130000.0
}
},
{
"key" : "blue",
"doc_count" : 2,
"sales" : {
"value" : 40000.0
}
},
{
"key" : "green",
"doc_count" : 2,
"sales" : {
"value" : 42000.0
}
}
]
}
}
}
- 请求参数和第一次的请求相比,按颜色聚合的参数不变,但是内部多了个aggs对象,详细的说明如下:
GET /cars/transactions/_search
{
"size":0,
"aggs":{ ------和前面一样,指定聚合操作
"colors":{ ------别名
"terms": { ------桶类型是按指定字段聚合
"field": "color" ------按照color字段聚合
},
"aggs":{ ------新增的aggs对象,用于处理聚合在每个桶内的文档
"sales":{ ------别名
"sum":{ ------度量指标是指定字段求和
"field":"price" ---求和的字段是price
}
}
}
}
}
}
- 对响应的数据说明如下:
"aggregations" : { ------聚合结果
"colors" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ ------这个json数组的每个对象代表一个桶
{
"key" : "red", ------该桶将所有color等于red的文档聚合进来
"doc_count" : 4, ------有4个color等于red的文档
"sales" : { ------这里面是sum计算后的结果
"value" : 130000.0 ------所有color等于red的汽车销售总额
}
},
{
"key" : "blue",
"doc_count" : 2,
"sales" : {
"value" : 40000.0 ------所有color等于blue的汽车销售总额
}
},
-
对于其他度量类型和sum也是相似的,您可以参考官方文档了解更多信息:https://www.elastic.co/guide/en/elasticsearch/reference/7.0/search-aggregations.html
-
至此,Elasticsearch6的基本聚合操作就完成了,接下来的文章我们会接触到更复杂的聚合操作;
欢迎关注华为云博客:程序员欣宸

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)