双向带头循环链表的(增删查改)的实现

【摘要】 👩💻博客主页:风起 风落的博客主页✨欢迎关注🖱点赞🎀收藏⭐留言✒👕参考网站:牛客网🎨你的收入跟你的不可替代成正比🀄如果觉得博主的文章还不错的话,请三连支持一下博主哦💬给大家介绍一个求职刷题收割offer的地方👉点击网站@TOC 一、双向带头循环链表 构成 二、双向带头循环链表的实现 1.函数的定义和结构体的创建——list.h#include<stdio.h>#inclu...
👩💻博客主页:风起 风落的博客主页
✨欢迎关注🖱点赞🎀收藏⭐留言✒
👕参考网站:牛客网
🎨你的收入跟你的不可替代成正比
🀄如果觉得博主的文章还不错的话,请三连支持一下博主哦
💬给大家介绍一个求职刷题收割offer的地方👉点击网站
@TOC
一、双向带头循环链表
构成

二、双向带头循环链表的实现
1.函数的定义和结构体的创建——list.h
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int datatype;
struct listNode
{
datatype val;
struct listNode* prev;
struct listNode* next;
};
struct listNode* stackinit();
void stackpushback(struct listNode* phead, datatype x);
void stackprint(struct listNode* phead);
void stackpopback(struct listNode* phead);
void stackpushfront(struct listNode* phead, datatype x);
void stackpopfront(struct listNode* phead);
struct listNode*stackfind (struct listNode* phead,datatype x);
void stackinsert(struct listNode* pos, datatype x);
void stackdestroy(struct listNode* phead);
2.函数的调用——list.c
#include"list.h"
int main()
{
struct listNode* phead= stackinit();//这里为了不使用二级指针,将结构体指针返回
stackpushback(phead, 1);
stackpushback(phead, 2);
stackpushback(phead, 3);
stackpushback(phead, 4);
stackpopback(phead);
stackpushfront(phead,5);
stackpopfront(phead);
stackprint(phead);
struct listNode*pos=stackfind(phead, 2);
stackinsert(pos, 4);
stackprint(phead);
struct listNode* pos2 = stackfind(phead, 2);
stackerase(pos2);
stackprint(phead);
stackdestroy(phead);
phead = NULL;
return 0;
}
3. 双向带头循环链表与单链表的传递参数区别
1.单链表:
单链表因为没有头节点的存在,导致在尾插时会改变链表的头节点
所以需要传递二级指针的地址即二级指针。
2.双向带头循环链表:
初始化头指针时,是需要传递二级指针,只不过用函数传回结构体指针的方式代替了,
而在后续接口则不需要传递二级指针,因为后来都是在头指针的基础上进行的,而头节点本身不会存储有效数据,并不会改变头节点本身。
4.双向带头循环链表的接口
1.初始化
struct listNode* stackinit()//初始化头节点
{
struct listNode* phead = (struct listNode*)malloc(sizeof(struct listNode));
phead->next = phead;//带哨兵位的头节点
phead->prev = phead;
}
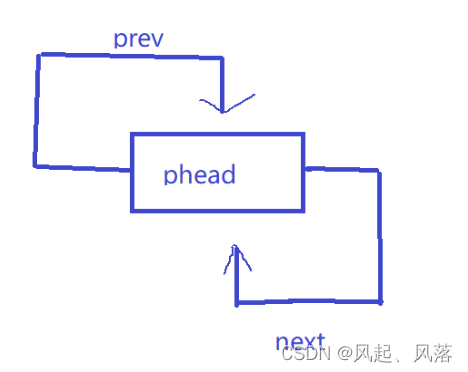
2.尾插
void stackpushback(struct listNode* phead, datatype x)//尾插
{
struct listNode* tail = phead->prev;//tail为最后一个节点
struct listNode* newnode = (struct listNode*)malloc(sizeof(struct listNode));
newnode->val = x;
tail->next = newnode;
newnode->prev=tail;
newnode->next = phead;
phead->prev = newnode;
}
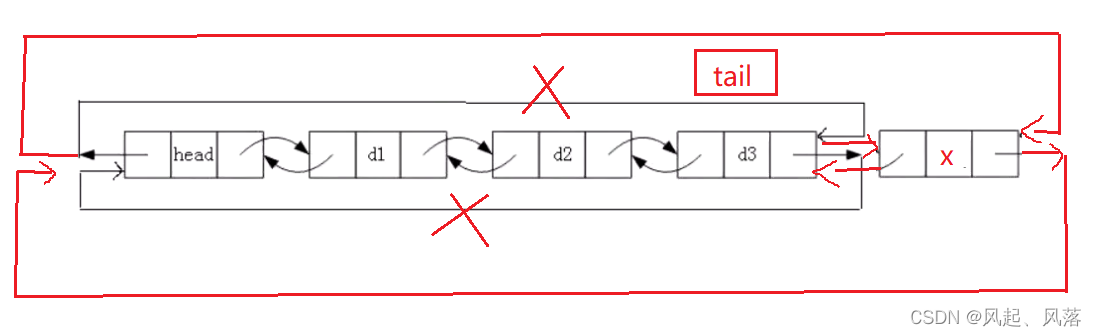
3.尾删
void stackpopback(struct listNode* phead)//尾删
{
assert(phead);
assert(phead->next != phead);//当只剩下头节点时 phead->next才会指向phead
struct listNode* tail = phead->prev;
struct listNode* cur = tail->prev;//rur为最后一个节点的前一个节点
cur->next = phead;
phead->prev = cur;
free(tail);
tail = NULL;
}
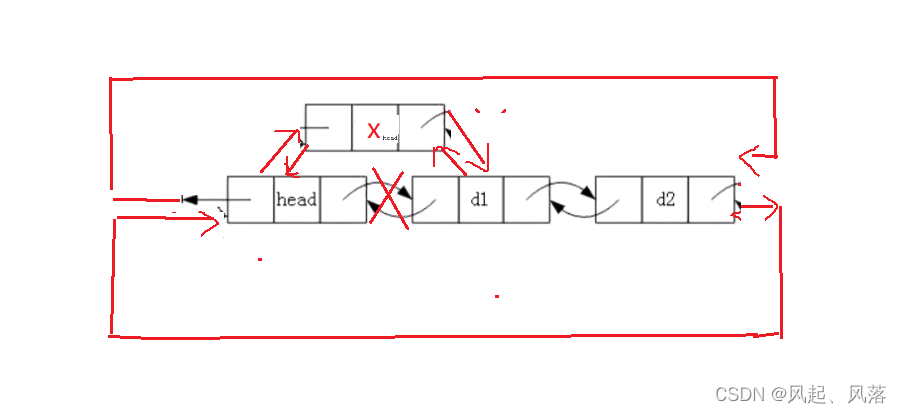
4.头插
void stackpushfront(struct listNode* phead, datatype x)//头插
{
struct listNode* newnode = (struct listNode*)malloc(sizeof(struct listNode));
newnode->val = x;
struct listNode* cur = phead->next;
phead->next = newnode;
newnode->prev = phead;
newnode->next = cur;
cur->prev = newnode;
}
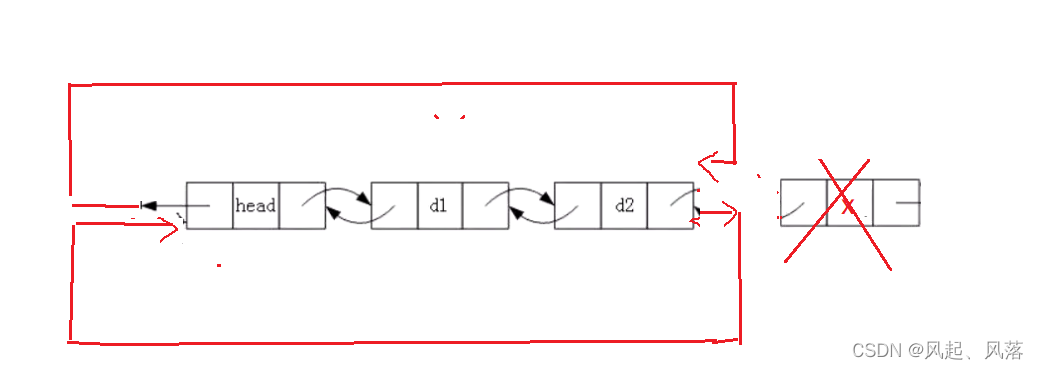
5.头删
void stackpopfront(struct listNode* phead)//头删
{
assert(phead);
assert(phead->next != phead);//链表为空时
struct listNode* prev = phead->next;
struct listNode* next = phead->next->next;//找到第一个节点后的一个节点
phead->next = next;
next->prev = phead;
free(prev);
prev = NULL;
}
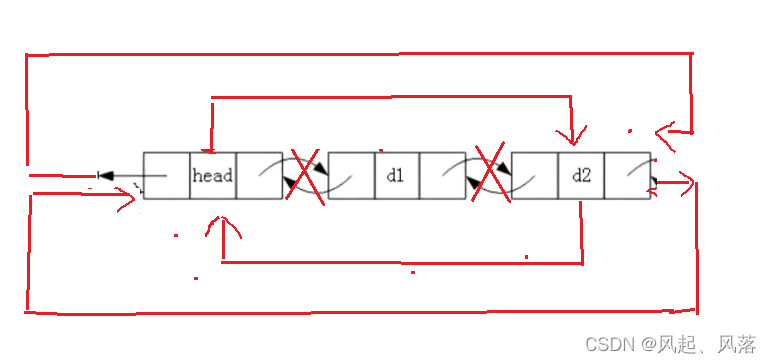
6.查找位置
struct listNode* stackfind(struct listNode* phead, datatype x)//查找位置
{
struct listNode* cur = phead->next;
while (cur != phead)
{
if (cur->val == x)
{
return cur;//如果找到了返回结构体
}
cur = cur->next;
}
return NULL;//如果找不到就返回NULL
}
7.指定 在pos之前插入
void stackinsert(struct listNode* pos, datatype x)//指定插 在pos之前插入
{
assert(pos);
struct listNode* prev = pos->prev;
struct listNode* newnode = (struct listNode*)malloc(sizeof(struct listNode));
newnode->val = x;
prev->next = newnode;
newnode->prev = prev;
newnode->next = pos;
pos->prev = newnode;
}
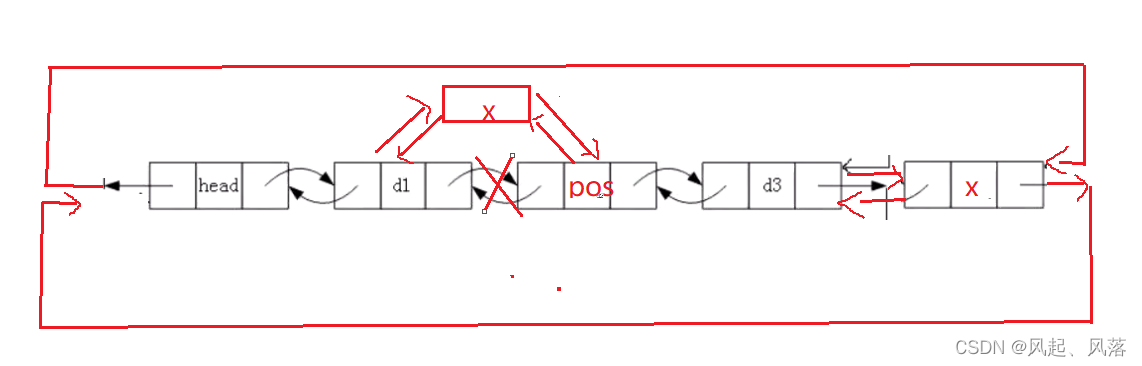
8.指定删
void stackerase(struct listNode* pos)//指定删
{
assert(pos);
struct listNode* prev = pos->prev;
struct listNode* next = pos->next;
prev->next = next;
next->prev = prev;
free(pos);
pos = NULL;
}
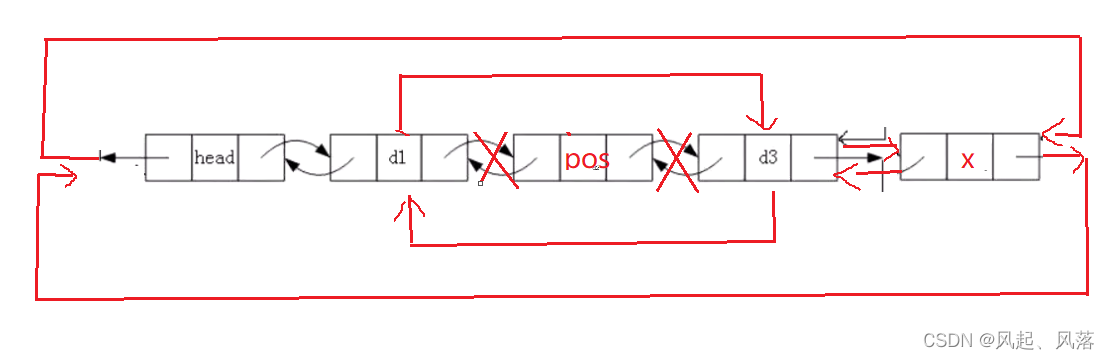
9.内存销毁
void stackdestroy(struct listNode* phead)//内存销毁
{
struct listNode* cur = phead->next;
while (cur != phead)
{
struct listNode* next = cur->next;
free(cur);
cur = next;
}
free(phead);
phead = NULL;//因为此时传过来是一级指针不能影响会传回去的phead 所以可以手动在外面置NULL
}
10.打印
void stackprint(struct listNode* phead)//打印
{
struct listNode* cur = phead->next;
while (cur != phead)//此时因为是循环链表 ,所以不要写成NULL
{
printf("%d ", cur->val);
cur = cur->next;
}
printf("\n");
}
三、链表与顺序表的不同点
1.顺序表:
在物理上是连续的
优点: 支持随机访问。
缺点:(1)任意位置插入或者删除时,可能需要挪动元素,效率低。
(2)在动态开辟空间时,会造成一定的浪费。
2.链表:
逻辑上是来连续的,物理上的不连续。
优点:(1)任意位置插入或者删除,不会挪动元素,只会改变指针指向,(2)没有容量的概念,不会造成空间浪费。
缺点:不支持随机访问

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)