Linux安装Hive并测试

【摘要】
一、Node2节点配置
二、Master节点配置
三、Node1节点配置
四、启动Hive并测试
下载Hive包:https://cloud.189.cn/t/zqaieevYNrau (访问...
一、Node2节点配置
二、Master节点配置
三、Node1节点配置
四、启动Hive并测试
下载Hive包:https://cloud.189.cn/t/zqaieevYNrau (访问码:c10p)
下载mysql-jar包:https://cloud.189.cn/t/2IzYzuARVzQ3 (访问码:nc8j)
下载result.json文件:https://cloud.189.cn/t/FjmUJ3NbiMza (访问码:3ev9)
下载moivescsv.csv文件:https://cloud.189.cn/t/UvUBFzb2q6ba (访问码:8pk4)
一、Node2节点配置
Node2节点执行:
首先在windows中传输mysql-connector-java-5.1.5-bin.jar到node2
1、安装mysqld/mariadb服务(建议使用离线源)
[root@node2 ~]# yum -y install mariadb-server
- 1
2、启动mysql服务,并设置开机自启
[root@node2 ~]# systemctl start mariadb
[root@node2 ~]# systemctl enable mariadb
- 1
- 2
3、初始化mysql并设置密码并测试登陆mysql
[root@node2 ~]# mysql_secure_installation
- 1
4、Node2将jar包发给node1
[root@node2 ~]# scp mysql-connector-java-5.1.5-bin.jar node1:/root
- 1

二、Master节点配置
Master节点执行操作
1、传输tar包到master节点
使用SecureFX进行传输
2、Master创建文件夹并解压hive压缩包,并将tar包传输给node1
[root@master ~]# mkdir -p /usr/hive
[root@master ~]# tar -zxf apache-hive-2.3.7-bin.tar.gz -c /usr/hive
[root@master ~]# scp apache-hive-2.3.7-bin.tar.gz node1:/root
- 1
- 2
- 3

3、Master修改环境变量并验证
[root@master ~]# vi /etc/profile
- 1

[root@master ~]# source /etc/profile
- 1
master配置客户端
4、更换jar包
[root@master ~]# cp /usr/hive/apache-hive-2.3.7-bin/lib/jline-2.12.jar /opt/bigdata/hadoop-3.0.0/lib
- 1

5、添加hive-site.xml
[root@master ~]# cd /usr/hive/apache-hive-2.3.7-bin/conf
[root@master conf]# vi hive-site.xml
- 1
- 2
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
三、Node1节点配置
Node1节点操作
1、Node1将jar包复制到lib中
[root@node1 ~]# cp mysql-connector-java-5.1.5-bin.jar /usr/hive/apache-hive-2.3.7-bin/lib
- 1

2、Node1复制配置文件
[root@node1 ~]# cd /usr/hive/apache-hive-2.3.7-bin/conf
[root@node1 conf]# cp hive-env.sh.template hive-env.sh
- 1
- 2

3、Node1添加环境变量
在hive-env.sh中添加hadoop的目录
[root@node1 conf]# vi hive-env.sh
在首行添加
HADOOP_HOME=/opt/bigdata/hadoop-3.0.0
- 1
- 2
- 3

4、Node1创建hive-site.xml文件
[root@node1 ~]# cd /usr/hive/apache-hive-2.3.7-bin/conf
[root@node1 conf]# vi hive-site.xml
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node2:3306/hivecreateDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
</configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
四、启动Hive并导入json/csv格式文件进行测试
[root@node1 ~]cd /usr/hive/apache-hive-2.3.7-bin/
[root@node1 apache-hive-2.3.7-bin]bin/hive
- 1
- 2
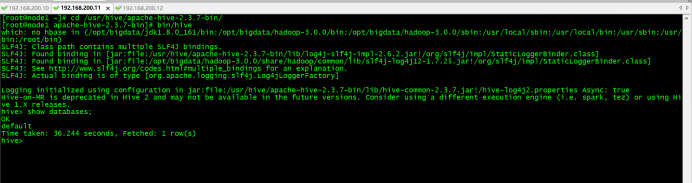
创建result表,并导入数据
hive>create table result(json string);
hive>load data local inpath ‘/root/result.json’ into table result;
hive>select * from result;
- 1
- 2
- 3
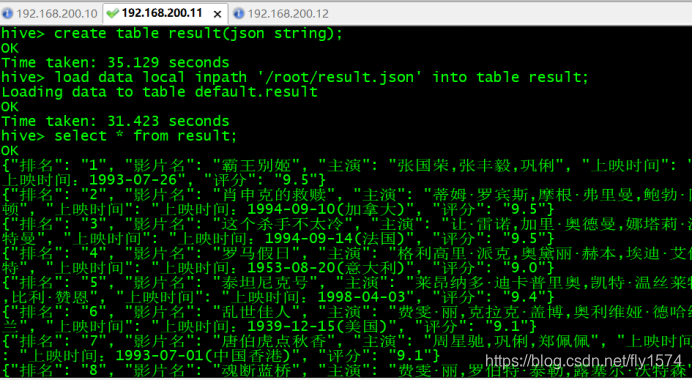
创建moives表,并导入数据,查询
hive> create table movies(a string,b string,c string,d string,e int)
> row format serde
> 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
> with
> SERDEPROPERTIES
> ("separatorChar"=",")
> STORED AS TEXTFILE;
hive> load data local inpath '/root/moviescsv.csv' into table movies;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
文章来源: blog.csdn.net,作者:指剑,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/fly1574/article/details/105695376

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)