
在前一期的“应用开发向导”中,我们知道,使用AscendCL接口开发应用时,典型场景包括网络模型推理、单算子执行等,本期我们来深入讲解网络模型推理场景下,具体怎么做。
首先,我们得先了解下,使用AscendCL时,经常会提到的“数据类型的操作接口” ,这是什么呢?为啥会存在?
在C/C++中,对用户开放的数据类型通常以Struct结构体方式定义、以声明变量的方式使用,但这种方式一旦结构体要增加成员参数,用户的代码就涉及兼容性问题,不便于维护,因此AscendCL对用户开放的数据类型,均以接口的方式操作该数据类型,例如,调用某个数据类型的Create接口创建该数据类型、调用Get接口获取数据类型内参数值、调用Set接口设置数据类型内的参数值、调用Destroy接口销毁该数据类型,用户无需关注定义数据类型的结构体长什么样,这样即使后续数据类型需扩展,只需增加该数据类型的操作接口即可,也不会引起兼容性问题。
所以,总结下,“数据类型的操作接口”就是创建数据类型、Get/Set数据类型中的参数值、销毁数据类型的一系列接口,存在的最大好处就是减少兼容性问题。
接下来,进入我们今天的主题,怎么用AscendCL的接口开发网络模型推理场景下的应用。
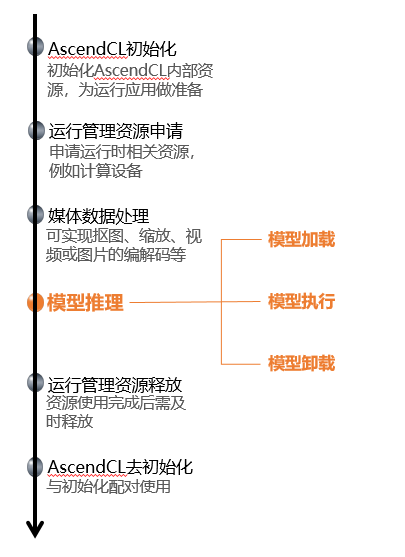
01 AscendCL初始化与去初始化
使用AscendCL接口开发应用时,必须先初始化AscendCL ,否则可能会导致后续系统内部资源初始化出错,进而导致其它业务异常。在初始化时,还支持以下跟推理相关的可配置项(例如,性能相关的采集信息配置),以json格式的配置文件传入AscendCL初始化接口。如果当前的默认配置已满足需求(例如,默认不开启性能相关的采集信息配置),无需修改,可向AscendCL初始化接口中传入NULL,或者可将配置文件配置为空json串(即配置文件中只有{})。
有初始化就有去初始化,在确定完成了AscendCL的所有调用之后,或者进程退出之前,需调用AscendCL接口实现AscendCL去初始化。

02 运行管理资源申请与释放
运行管理资源包括Device、Context、Stream、Event等,此处重点介绍Device、Context、Stream,其基本概念如下图所示 。
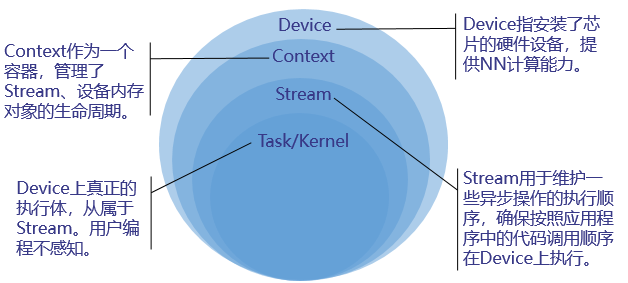
您需要按顺序依次申请如下运行管理资源:Device、Context、Stream,确保可以使用这些资源执行运算、管理任务。所有数据处理都结束后,需要按顺序依次释放运行管理资源:Stream、Context、Device。
在申请运行管理资源时,Context、Stream支持隐式创建和显式创建两种申请方式。


03 媒体数据处理
如果模型对输入图片的宽高要求与用户提供的源图不一致,AscendCL提供了媒体数据处理的接口,可实现抠图、缩放、格式转换、视频或图片的编解码等,将源图裁剪成符合模型的要求。后续期刊中会展开说明这个功能,本期着重介绍模型推理的部分,以输入图片满足模型的要求为例。
04 模型加载
模型推理场景下,必须要有适配昇腾AI处理器的离线模型(*.om文件),我们可以使用ATC(Ascend Tensor Compiler)来构建模型。如果模型推理涉及动态Batch、动态分辨率等特性,需在构建模型增加相关配置。怎么使用ATC来构建模型,在往期文档速递中有介绍,可拖动到文末查阅。
有了模型,就可以开始加载了,当前AscendCL支持以下几种方式加载模型:
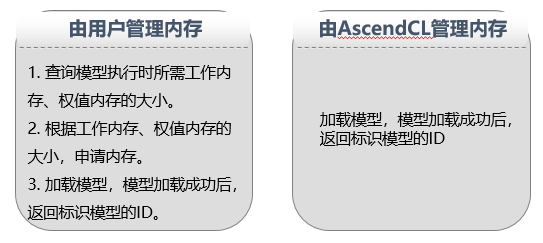
• 从*.om文件中加载模型数据,由AscendCL管理内存
• 从*.om文件中加载模型数据,由用户自行管理内存
• 从内存中加载模型数据,由AscendCL管理内存
• 从内存中加载模型数据,由用户自行管理内存
由用户自行管理内存时,需关注工作内存、权值内存。工作内存用于存放模型执行过程中的临时数据,权值内存用于存放权值数据。这个时候,是不是有疑问了,我怎么知道工作内存、权值内存需要多大?不用担心,AscendCL不仅提供了加载模型的接口,同时也提供了“根据模型文件获取模型执行时所需的工作内存和权值内存大小”的接口,方便用户使用 。

05 模型执行
在调用AscendCL接口进行模型推理时,模型推理有输入、输出数据,输入、输出数据需要按照AscendCL规定的数据类型存放。相关数据类型如下:
• 使用aclmdlDesc类型的数据描述模型基本信息(例如输入/输出的个数、名称、数据类型、Format、维度信息等)。
模型加载成功后,用户可根据模型的ID,调用该数据类型下的操作接口获取该模型的描述信息,进而从模型的描述信息中获取模型输入/输出的个数、内存大小、维度信息、Format、数据类型等信息。
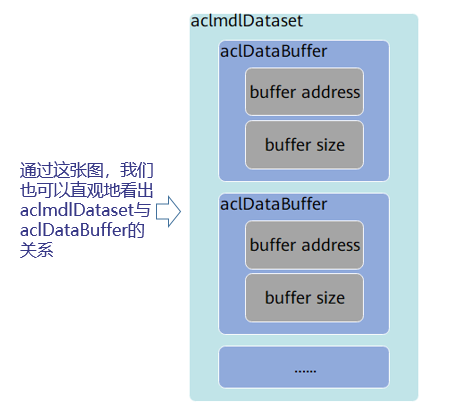
• 使用aclDataBuffer类型的数据来描述每个输入/输出的内存地址、内存大小。
调用aclDataBuffer类型下的操作接口获取内存地址、内存大小等,便于向内存中存放输入数据、获取输出数据。
• 使用aclmdlDataset类型的数据描述模型的输入/输出数据。
模型可能存在多个输入、多个输出,调用aclmdlDataset类型的操作接口添加多个aclDataBuffer类型的数据。

准备好模型执行所需的输入、输出数据类型后,存放好模型执行的输入数据后,可以执行模型推理了,如果模型的输入涉及动态Batch、动态分辨率等特性,则在模型执行前,还需要调用AscendCL接口告诉模型本次执行时需要用的Batch数、分辨率等。
当前AscendCL支持同步模型执行、异步模型执行两种方式,这里说的同步、异步是站在调用者和执行者的角度。
• 若调用模型执行的接口后需等待推理完成再返回,则表示同步的。当用户调用同步模型执行接口后,可直接从该接口的输出参数中获取模型执行的结果数据,如果需要推理的输入数据量很大,同步模型执行时,需要等所有数据都处理完成后,才能获取推理的结果数据。
• 若调用模型执行的接口后不等待推理完成完成再返回,则表示异步的。当用户调用异步模型执行接口时,需指定Stream( Stream用于维护一些异步操作的执行顺序,确保按照应用程序中的代码调用顺序在Device上执行),另外,还需调用aclrtSynchronizeStream接口阻塞程序运行,直到指定Stream中的所有任务都完成,才可以获取推理的结果数据。如果需要推理的输入数据量很大,异步模型执行时,AscendCL提供了Callback机制,触发回调函数,在指定时间内一旦有推理的结果数据,就获取出来,达到分批获取推理结果数据的目的,提高效率。

推理结束后,如果需要获取并进一步处理推理结果数据,则由用户自行编码实现。最后,别忘了,我们还要销毁aclmdlDataset、aclDataBuffer等数据类型,释放相关内存,防止内存泄露。
06 模型卸载
在模型推理结束后,还需要通过aclmdlUnload接口卸载模型,并销毁aclmdlDesc类型的模型描述信息、释放模型运行的工作内存和权值内存。

07 更多介绍
了解更详细的内容,登录昇腾社区,在开发者文档中心(https://www.hiascend.com/document)阅读相关文档:
昇腾CANN文档中心致力于为开发者提供更优质的内容和更便捷的开发体验,助力CANN开发者共建AI生态。任何意见和建议都可以在昇腾社区反馈,您的每一份关注都是我们前进的动力。

评论(0)