金鱼哥RHCA回忆录:DO280管理和监控OpenShift平台--使用probes监视应用

🎹 个人简介:大家好,我是 金鱼哥,CSDN运维领域新星创作者,华为云·云享专家,阿里云社区·专家博主
📚个人资质:CCNA、HCNP、CSNA(网络分析师),软考初级、中级网络工程师、RHCSA、RHCE、RHCA、RHCI、ITIL😜
💬格言:努力不一定成功,但要想成功就必须努力🔥🎈支持我:可点赞👍、可收藏⭐️、可留言📝
📜使用probes监视应用
📑OPENSHIFT探针介绍
OpenShift应用程序可能会因为临时连接丢失、配置错误或应用程序错误等问题而异常。开发人员可以使用探针来监视他们的应用程序。探针是一种Kubernetes操作,它定期对正在运行的容器执行诊断。可以使用oc客户端命令或OpenShift web控制台配置探针。
目前,可以使用两种类型的探测:
- Liveness探针
Liveness探针确定在容器中运行的应用程序是否处于健康状态。如果Liveness探针返回检测到一个不健康的状态,OpenShift将杀死pod并试图重新部署它。开发人员可以通过配置template.spec.container.livenessprobe来设置Liveness探针。
- Readiness探针
Readiness探针确定容器是否准备好为请求服务,如果Readiness探针返回失败状态,OpenShift将从所有服务的端点删除容器的IP地址。开发人员可以使用Readiness探针向OpenShift发出信号,即使容器正在运行,它也不应该从代理接收任何流量。开发人员可以通过配置template.spec.containers.readinessprobe来设置Readiness探针。
OpenShift为探测提供了许多超时选项,有五个选项控制支持如上两个探针:
-
initialDelaySeconds:强制性的。确定容器启动后,在开始探测之前要等待多长时间。
-
timeoutSeconds:强制性的确定等待探测完成所需的时间。如果超过这个时间,OpenShift容器平台会认为探测失败。
-
periodSeconds:可选的,指定检查的频率。
-
successThreshold:可选的,指定探测失败后被认为成功的最小连续成功数。
-
failureThreshold:可选的,指定探测器成功后被认为失败的最小连续故障。
📑检查应用程序健康
Readiness和liveness probes可以通过三种方式检查应用程序的健康状况:
HTTP检查:当使用HTTP检查时,OpenShift使用一个webhook来确定容器的健康状况。如果HTTP响应代码在200到399之间,则认为检查成功。
示例:演示如何使用HTTP检查方法实现readiness probe 。
...
readinessProbe:
httpGet:
path: /health #检测的URL
port: 8080 #端口
initialDelaySeconds: 15 #在容器启动后多久才能检查其健康状况
timeoutSeconds: 1 #要等多久探测器才能完成
...
📑容器执行检查
当使用容器执行检查时,kubelet agent在容器内执行命令。退出状态为0的检查被认为是成功的。
示例:实现容器检查。
...
livenessProbe:
exec:
command:
- cat
- /tmp/health
initialDelaySeconds: 15
timeoutSeconds: 1
...
📑TCP Socket检查
当使用TCP Socket检查时,kubelet agent尝试打开容器的socket。如果检查能够建立连接,则认为容器是健康的。
示例:使用TCP套接字检查方法实现活动探测。
...
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
timeoutSeconds: 1
...
📑使用Web管理probes
开发人员可以使用OpenShift web控制台管理readiness和liveness探针。对于每个部署,探针管理都可以从Actions下拉列表中获得。
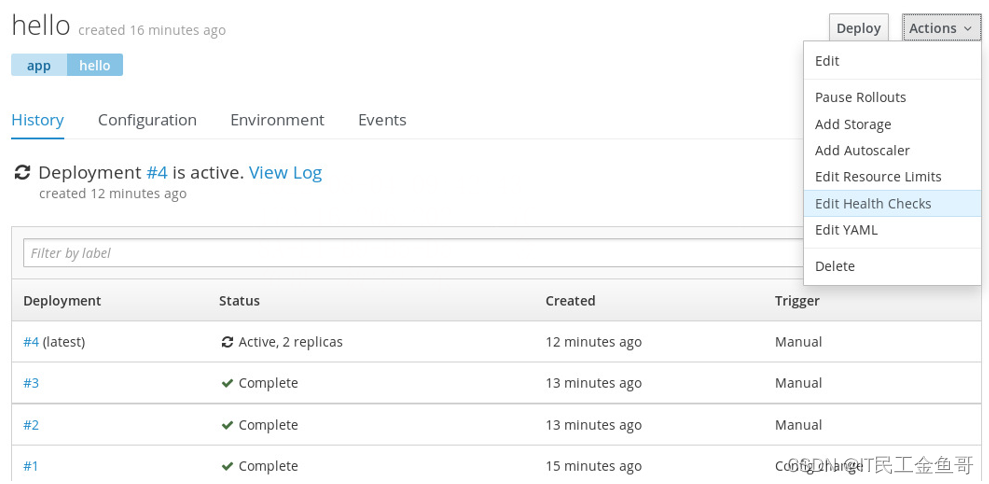
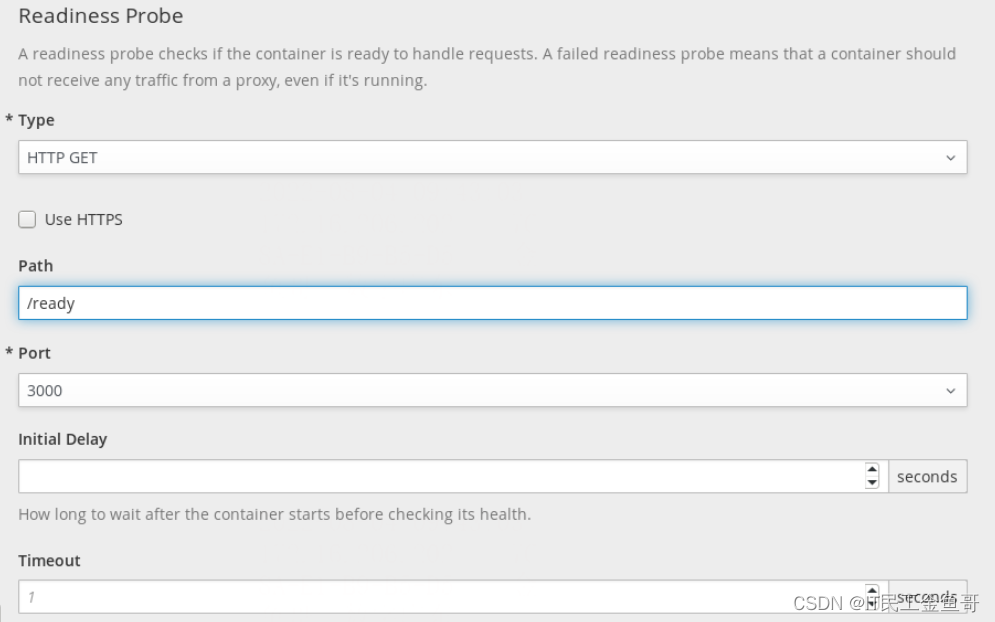
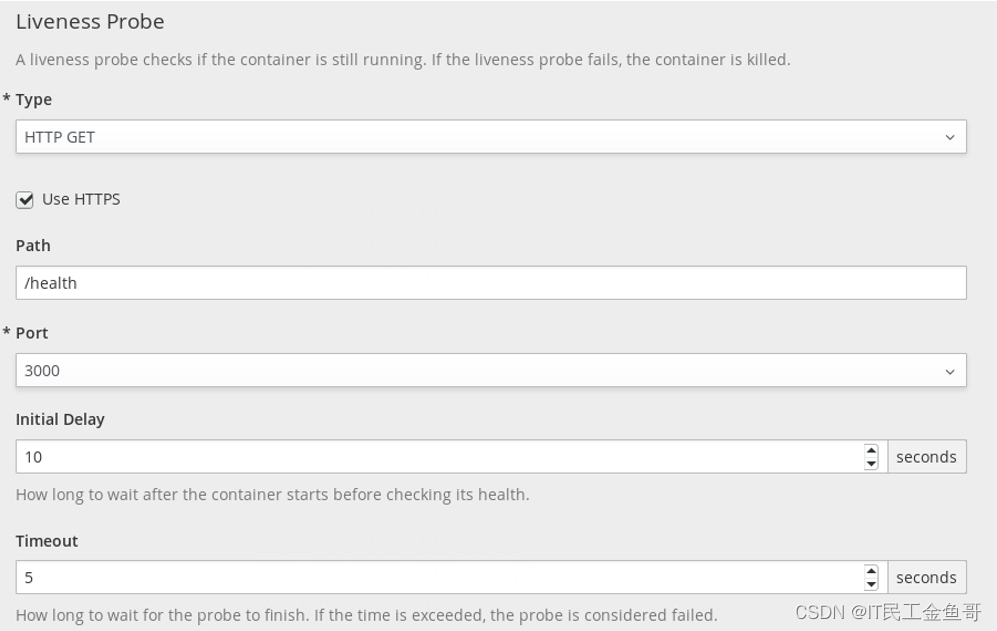
对于每种探针类型,开发人员可以选择该类型,例如HTTP GET、TCP套接字或命令,并为每种类型指定参数。web控制台还提供了删除探针的选项。
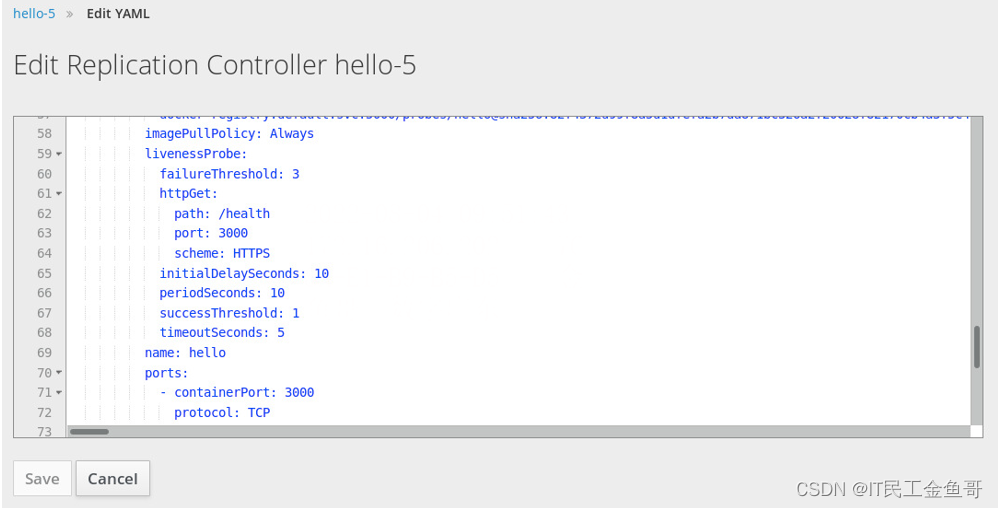
web控制台还可以用于编辑定义部署配置的YAML文件。在创建探针之后,将一个新条目添加到DC的配置文件中。使用DC编辑器来检查或编辑探针。实时编辑器允许编辑周期秒、成功阈值和失败阈值选项。
📜使用探针监视应用程序实验
📑前置准备
[student@workstation ~]$ lab install-prepare setup
[student@workstation ~]$ cd /home/student/do280-ansible
[student@workstation do280-ansible]$ ./install.sh
提示:若已经拥有一个完整环境,可不执行。
📑本练习准备
[student@workstation ~]$ lab probes setup
📑创建应用
[student@workstation ~]$ oc login -u developer -p redhat \
https://master.lab.example.com
[student@workstation ~]$ oc new-project probes
[student@workstation ~]$ oc new-app --name=probes \
http://services.lab.example.com/node-hello
[student@workstation ~]$ oc status
In project probes on server https://master.lab.example.com:443
svc/probes - 172.30.4.233:3000
dc/probes deploys istag/probes:latest <-
bc/probes docker builds http://services.lab.example.com/node-hello on istag/nodejs-6-rhel7:latest
build #1 running for 15 seconds - aaf02db: Establish remote repository (root <root@services.lab.example.com>)
deployment #1 waiting on image or update
2 infos identified, use 'oc status -v' to see details.
[student@workstation ~]$ oc get pods -w
NAME READY STATUS RESTARTS AGE
probes-1-2qf8f 0/1 ContainerCreating 0 1s
probes-1-build 0/1 Completed 0 42s
probes-1-deploy 1/1 Running 0 3s
probes-1-2qf8f 1/1 Running 0 3s
probes-1-deploy 0/1 Completed 0 6s
probes-1-deploy 0/1 Terminating 0 6s
probes-1-deploy 0/1 Terminating 0 6s
[student@workstation ~]$ oc get pods -w
NAME READY STATUS RESTARTS AGE
probes-1-2qf8f 1/1 Running 0 21s
probes-1-build 0/1 Completed 0 1m
📑暴露服务
[student@workstation ~]$ oc expose svc probes --hostname=probe.apps.lab.example.com
route "probes" exposed
[student@workstation ~]$ curl http://probe.apps.lab.example.com
Hi! I am running on host -> probes-1-2qf8f
📑检查服务
[student@workstation ~]$ curl http://probe.apps.lab.example.com/health
OK
[student@workstation ~]$ curl http://probe.apps.lab.example.com/ready
READY
📑创建readiness探针
使用Web控制台登录。并创建readiness探针。
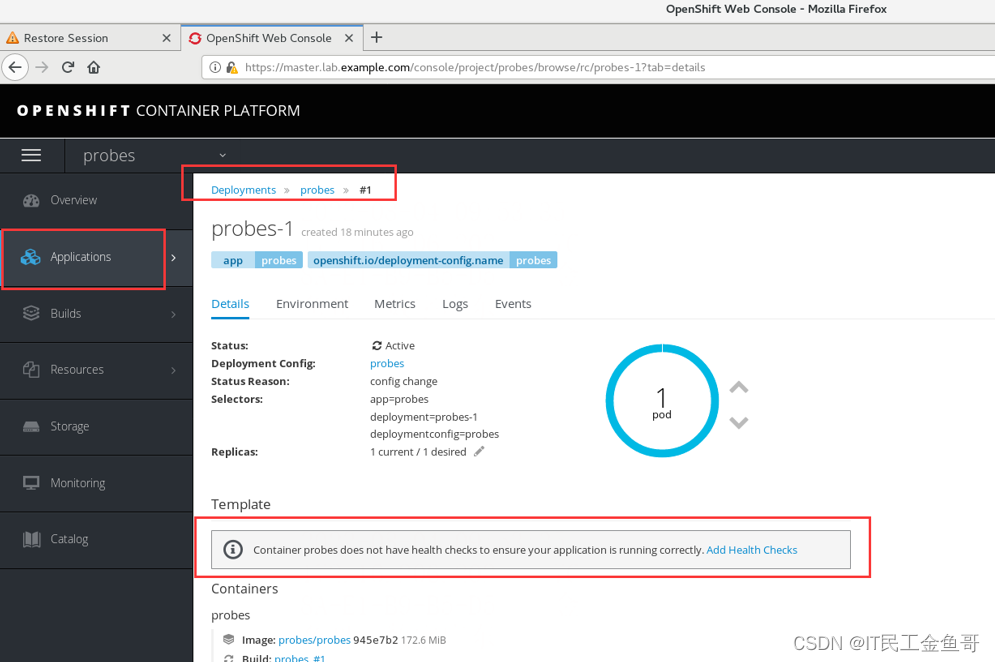
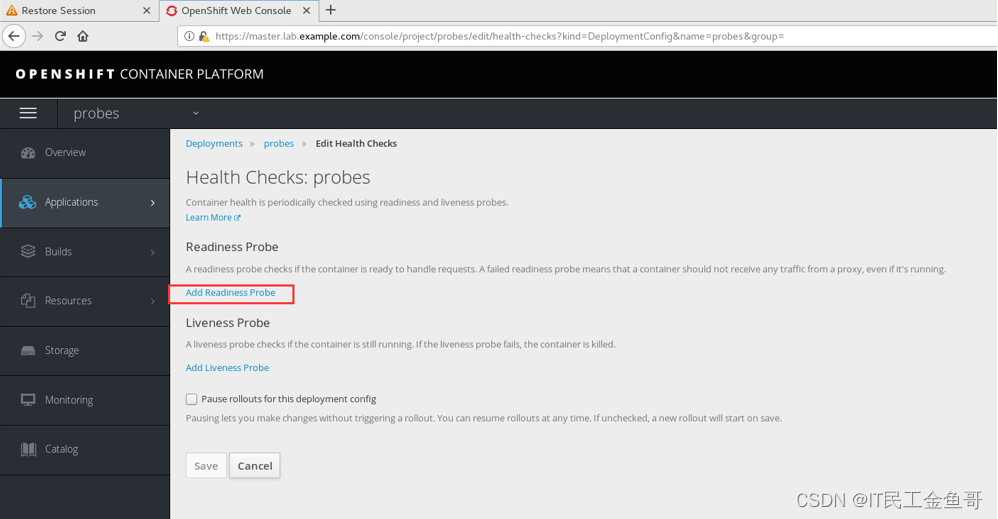
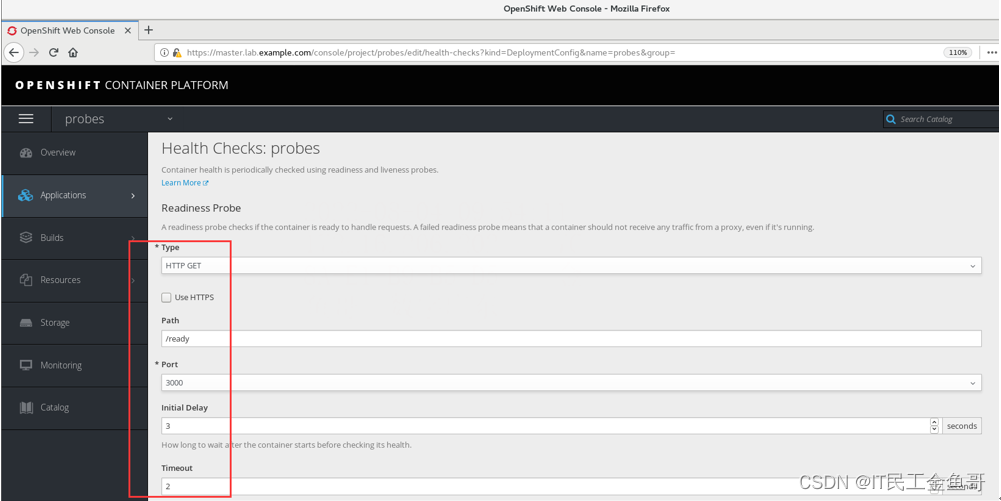
📑创建Liveness探针
使用Web控制台登录。并创建Liveness探针。
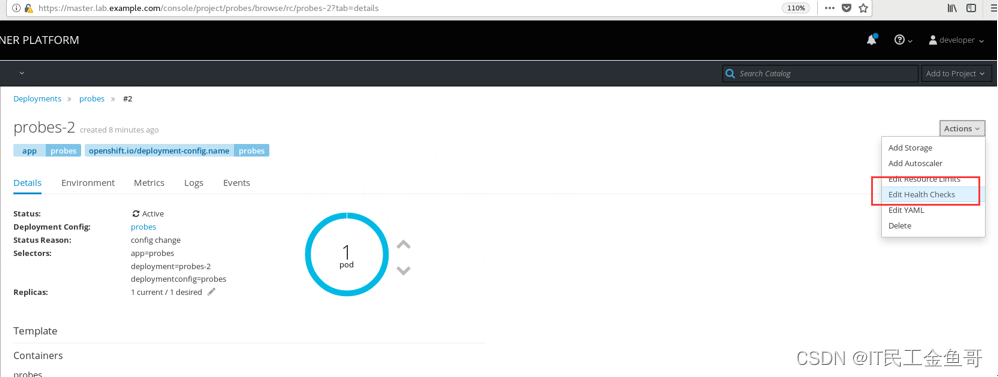
参考5.5存在的用于检查健康,特意使用healtz错误的值而不是health创建,从而测试相关报错。这个错误将导致OpenShift认为pod不健康,这将触发pod的重新部署。
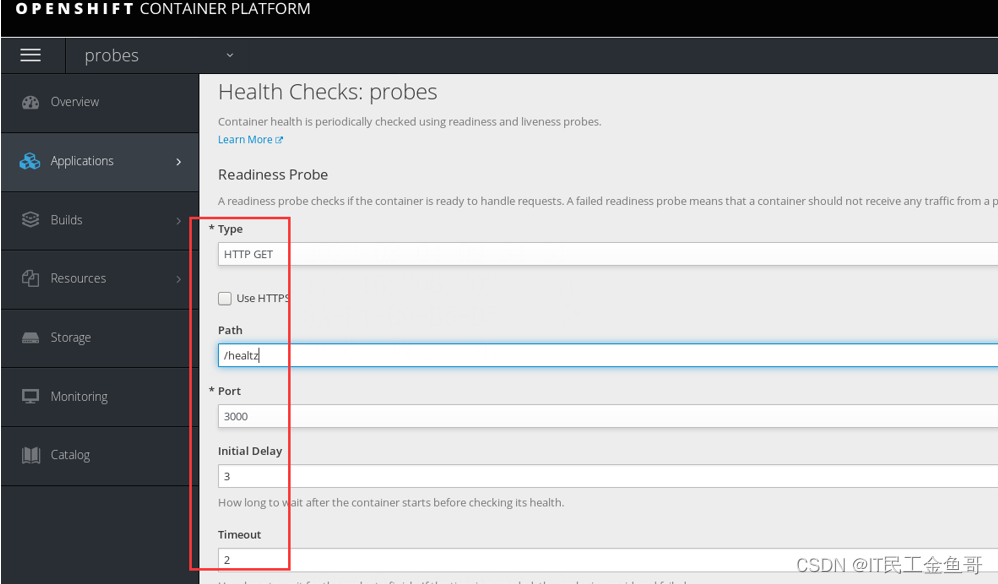
提示:由于探针更新了部署配置,因此更改将触发一个新的部署。
📑确认探测
通过单击侧栏上的Monitoring查看探测的实现。观察事件面板的实时更新。此时将标记为不健康的条
目,这表明liveness探针无法访问/healtz资源。
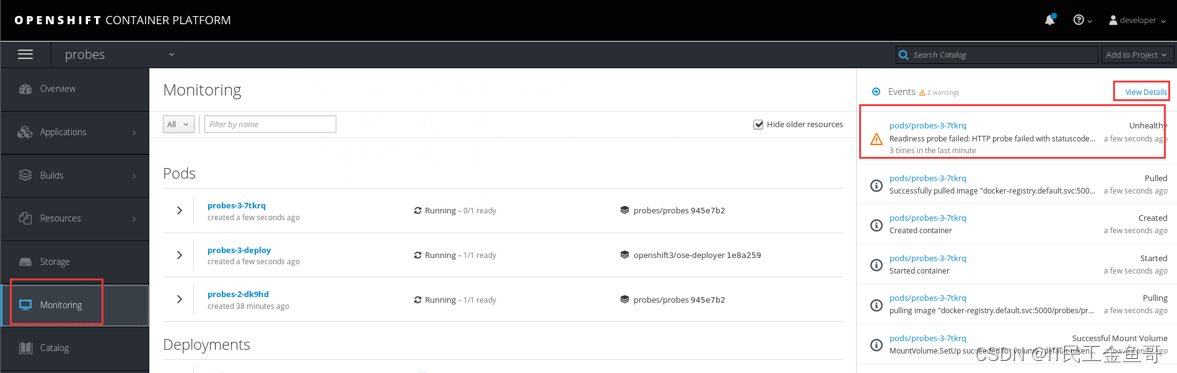
view details查看详情
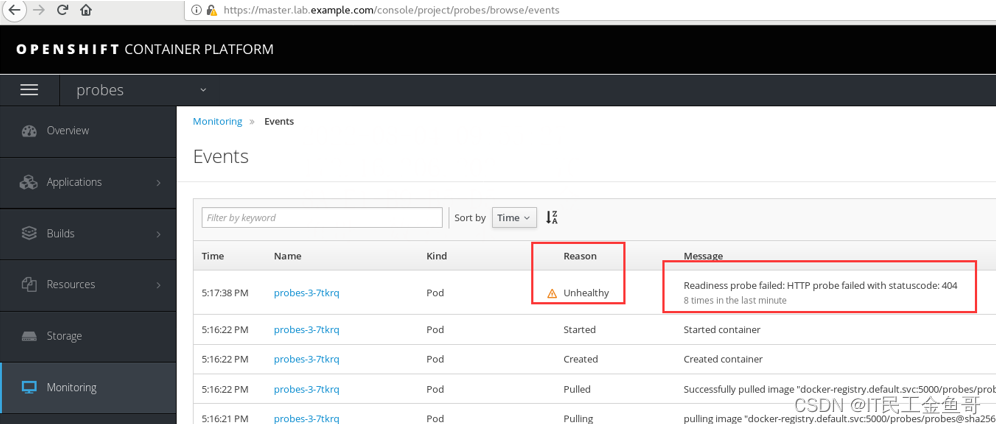
student@workstation ~]$ oc get events --sort-by='.metadata.creationTimestamp' | grep 'probe failed'
27s 3m 20 probes-3-7tkrq.166d65168057d4a0 Pod spec.containers{probes} Warning Unhealthy kubelet, node2.lab.example.com Readiness probe failed: HTTP probe failed with statuscode: 404
[student@workstation ~]$ oc get events | grep 'probe failed'
29s 3m 20 probes-3-7tkrq.166d65168057d4a0 Pod spec.containers{probes} Warning Unhealthy kubelet, node2.lab.example.com Readiness probe failed: HTTP probe failed with statuscode: 404
📑修正probe
修正healtz为health
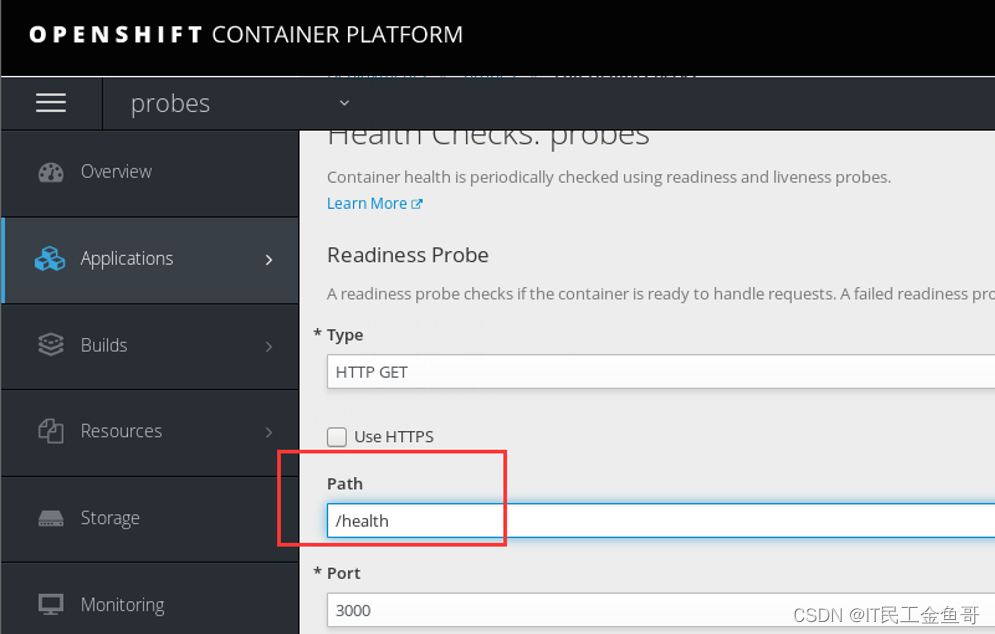
📑确认情况
[student@workstation ~]$ oc get events --sort-by='.metadata.creationTimestamp'
#从终端重新运行oc get events命令,此时OpenShift在重新部署DC新版本,以及杀死旧pod。同时将不会有任何关于pod不健康的信息。
📑清除项目
[student@workstation ~]$ oc delete project probes
💡总结
RHCA认证需要经历5门的学习与考试,还是需要花不少时间去学习与备考的,好好加油,可以噶🤪。

以上就是【金鱼哥】对 第九章 管理和监控OpenShift平台–使用probes监视应用 的简述和讲解。希望能对看到此文章的小伙伴有所帮助。
💾红帽认证专栏系列:
RHCSA专栏:戏说 RHCSA 认证
RHCE专栏:戏说 RHCE 认证
此文章收录在RHCA专栏:RHCA 回忆录
如果这篇【文章】有帮助到你,希望可以给【金鱼哥】点个赞👍,创作不易,相比官方的陈述,我更喜欢用【通俗易懂】的文笔去讲解每一个知识点。
如果有对【运维技术】感兴趣,也欢迎关注❤️❤️❤️ 【金鱼哥】❤️❤️❤️,我将会给你带来巨大的【收获与惊喜】💕💕!


- 点赞
- 收藏
- 关注作者
评论(0)