

🤵♂️ 个人主页: @计算机魔术师
👨💻 作者简介:CSDN内容合伙人,全栈领域优质创作者。
🌐 推荐一款找工作神器网站: 牛客网🎉🎉|笔试题库|面试经验|实习招聘内推
还没账户的小伙伴 速速点击链接跳转牛客网登录注册 开始刷爆题库,速速通关面试吧🙋♂️
该文章收录专栏
✨—【Django | 项目开发】从入门到上线 专栏—✨
@[toc]
一、实现excel表格导入数据(命令行工具)
- HR需要人肉输入应聘者数据,非常枯燥和耗时,所以我们进行产品的第二次迭代 – 实现候选人数据的导入
在应用interview创建managment文件以及该目录下command文件,创建import_candidate.py进行脚本操作、
需要存入的数据
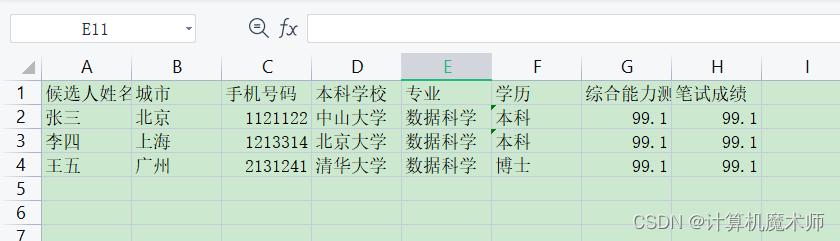
import_candidates.py(这里选择使用pandas读取数据)
import pandas as pd
from django.core.management import BaseCommand
from interview.models import Candidate
# python manage.py import_candidates --path file.csv
class Command(BaseCommand):
help = '从一个csv导入数据,并存贮到数据库'
# 添加一个长命令 Linux中 -- 表示长命令
def add_arguments(self, parser):
parser.add_argument('--path', type=str) # 所接受参数为一个字符串
# 处理逻辑
def handle(self, *args, **options):
path = options['path'] # 从命令行参数读取 path 存贮的路径
# with open(path, 'r', encoding='gbk') as f:
# reader = csv.reader(f, dialect='excel')
# for row in reader:
# print(row[0])
candidate_data = pd.read_csv(path, encoding='gbk', )
for row in range(len(candidate_data)):
data = list(candidate_data.iloc[row, :])
print()
# 创建对象不能Candidate()这是一个类实例,需要通过objects 对象来与数据库交互
candidate = Candidate.objects.create(
user_name=data[0],
city=data[1],
phone=data[2],
bachelor_school=data[3],
major=data[4],
degree=data[5],
test_score_of_general_ability=data[6],
page_score=data[7]
)
candidate.save()
- 命令行输入
python manage.py import_candidates --path ~/应聘者数据.csv
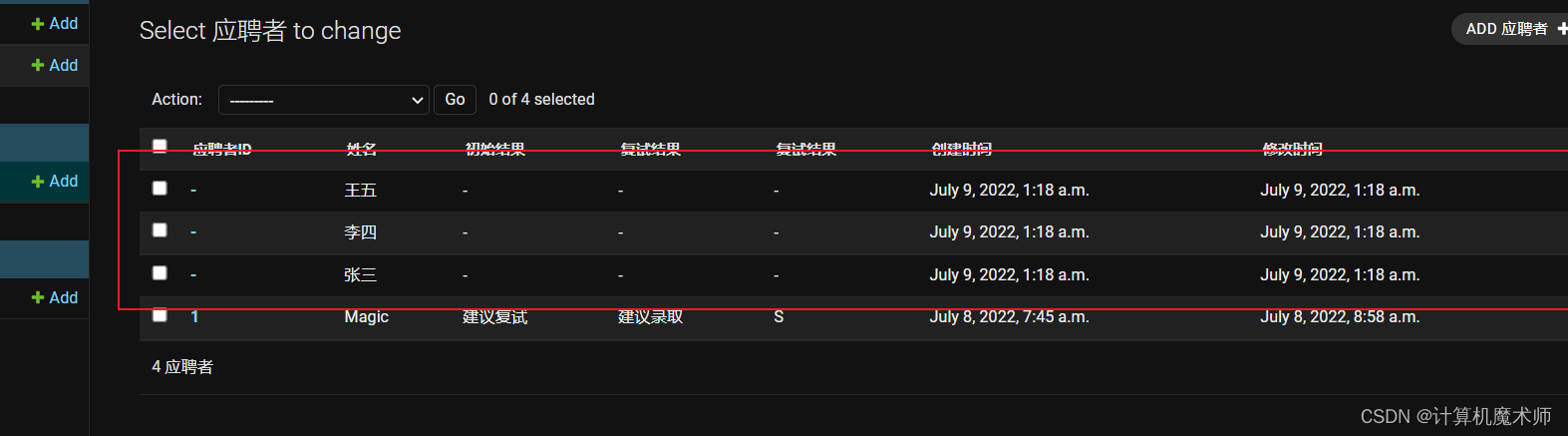
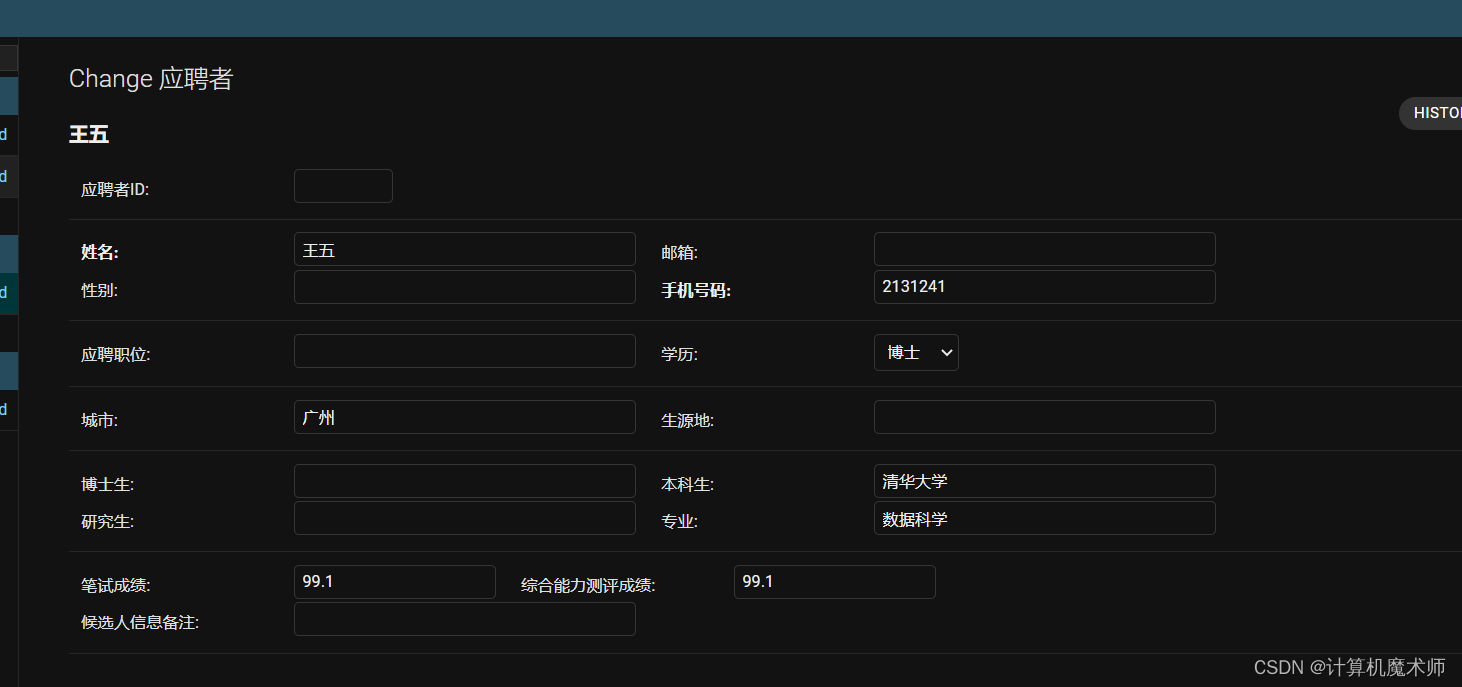
此时HR非常开心,不用一个一个录入候选人,我们的第二轮开发实现,接下来我们实现 列表查询和筛选
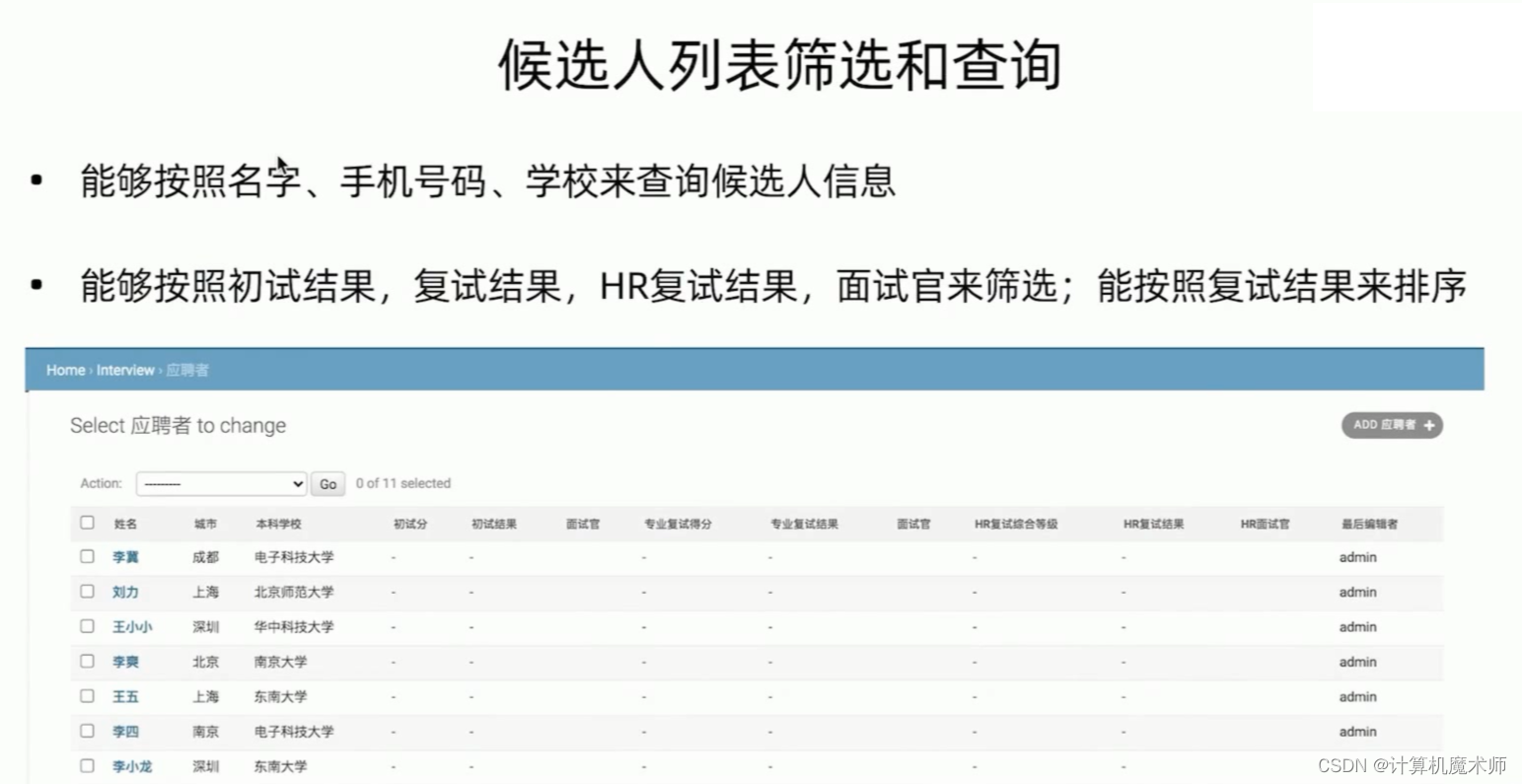
二、列表查询和筛选&页面再优化
希望能通过快速筛选得到数据,要求如下
Django官方文档 关于AdminModel 的选项
强烈建议看官方文档,比任何教程都要强
admin.py文件
from django.contrib import admin
from interview.models import Candidate
# Register your models here.
@admin.register(Candidate)
class CandidateAdmin(admin.ModelAdmin):
list_display = ('user_id', 'user_name', 'first_result', 'second_result', 'hr_result', 'create_time', 'modify_time')
# 定义集合的字段列表
fieldsets = (
# 第一个元素表示分组展现的名字,第二元素是一个map
(None, {'fields': ("user_id", ("user_name", "email", "gender", "phone",),
("apply_position", "degree"),
("city", "born_address"),
("doctor_school", "bachelor_school", "master_school", "major",), ("page_score",
"test_score_of_general_ability",
"candidate_remark",),
), }),
('第一轮面试', {'fields': ("first_score", "first_result", "second_interviewer",
), 'classes': ('collapse',), "description": '请由面试官输入该信息'}),
('第二轮面试', {'fields': ("second_score", "second_result", "first_interviewer",
), 'classes': ('collapse',), "description": '请由面试官输入该信息'}),
('第三轮面试', {'fields': ("hr_score", "hr_result", "hr_interviewer",
), 'classes': ('collapse',), "description": '请由面试官输入该信息'})
)
list_editable = ('user_id',) # 可直接在页面修改的数据
list_display_links = ('user_name',) # 默认为第一个columns 不想要设置为None 超链接跳转到form表单
list_per_page = 10 # 每个页面显示多少条数据
# list_max_show_all = 5 每个页面点击show_all最多显示数据
list_filter = ('first_result', 'second_result', 'hr_result') # 按照成绩筛选名字
# list_select_related = ('user_name', 'first_result')
# readonly_fields = ( 'modify_time',) # in_list_page non-editable and readonly
# save_as = True # 将 save_and_add_another replace to save_as
search_fields = ('user_name', 'first_result', 'second_result', 'hr_result',) # 设置可搜索内容
ordering = ('hr_result', 'second_result','first_result' ,) # 默认按照成绩排序好
- 效果:

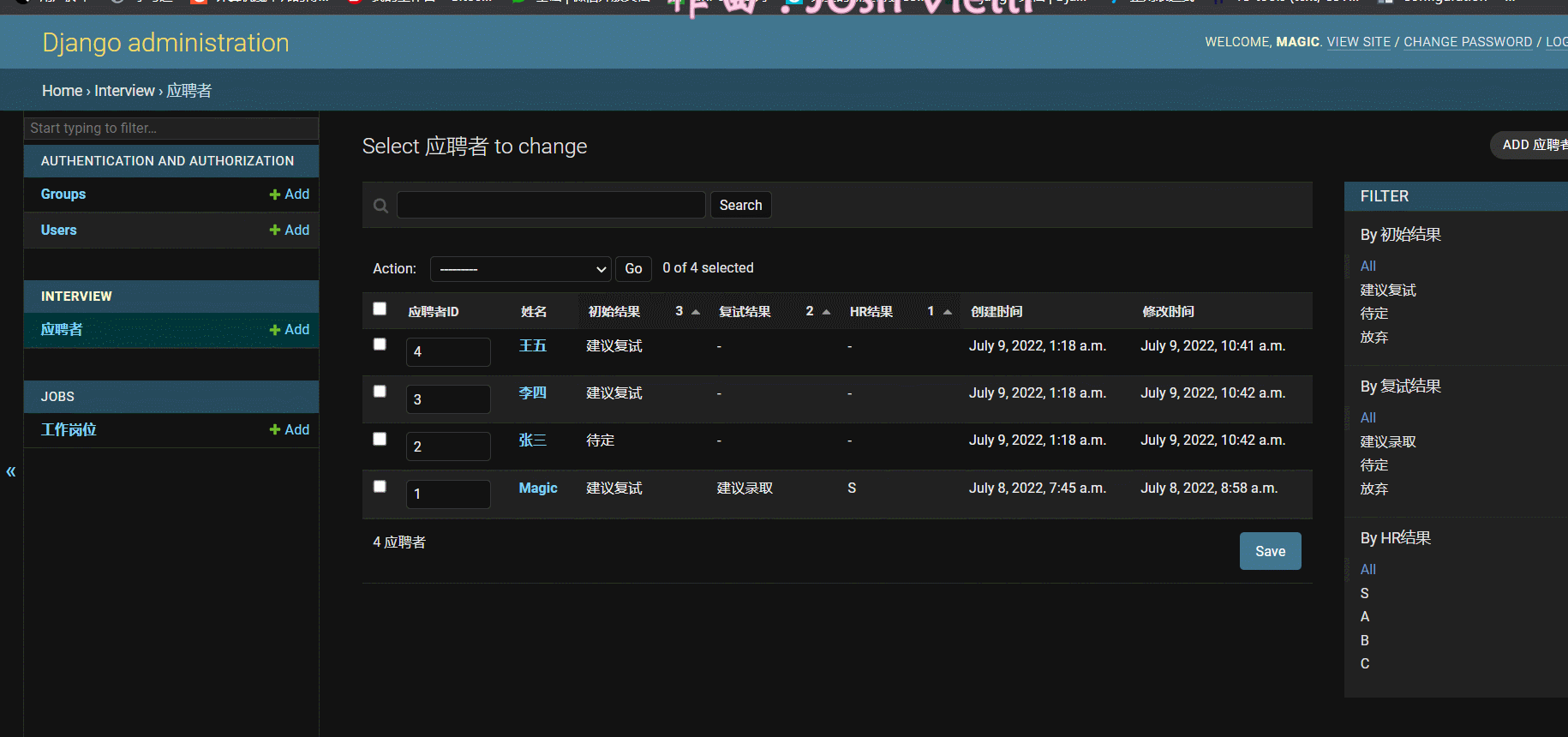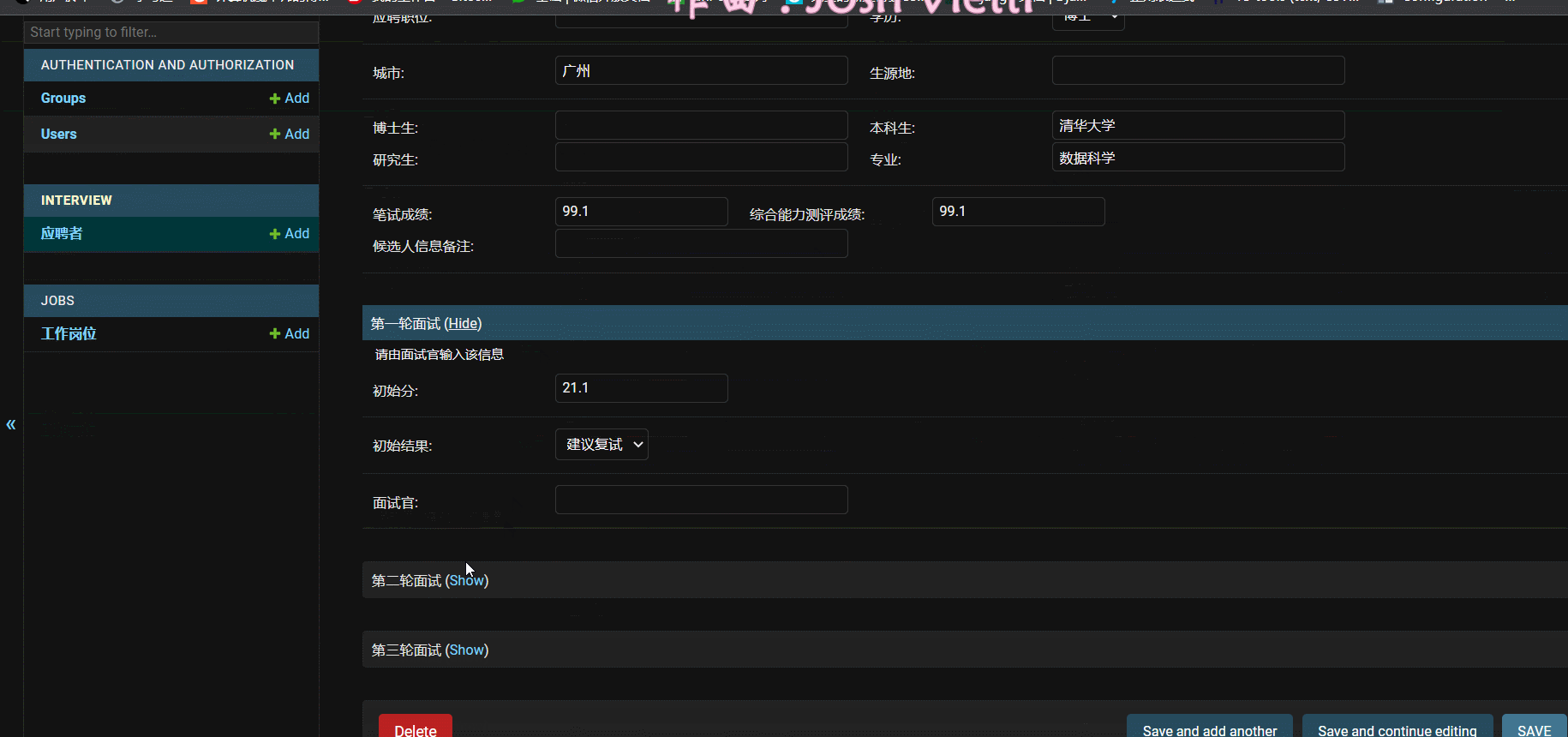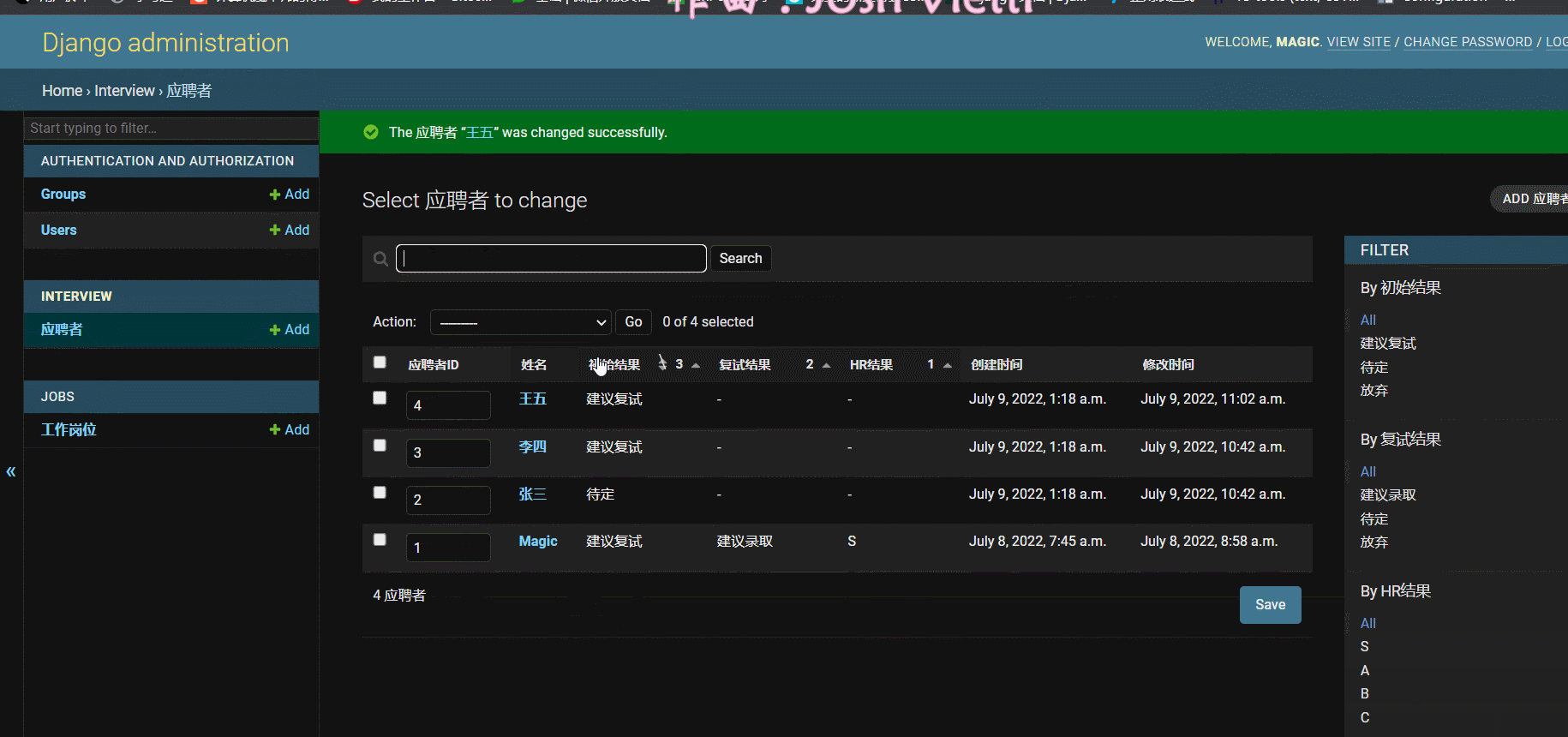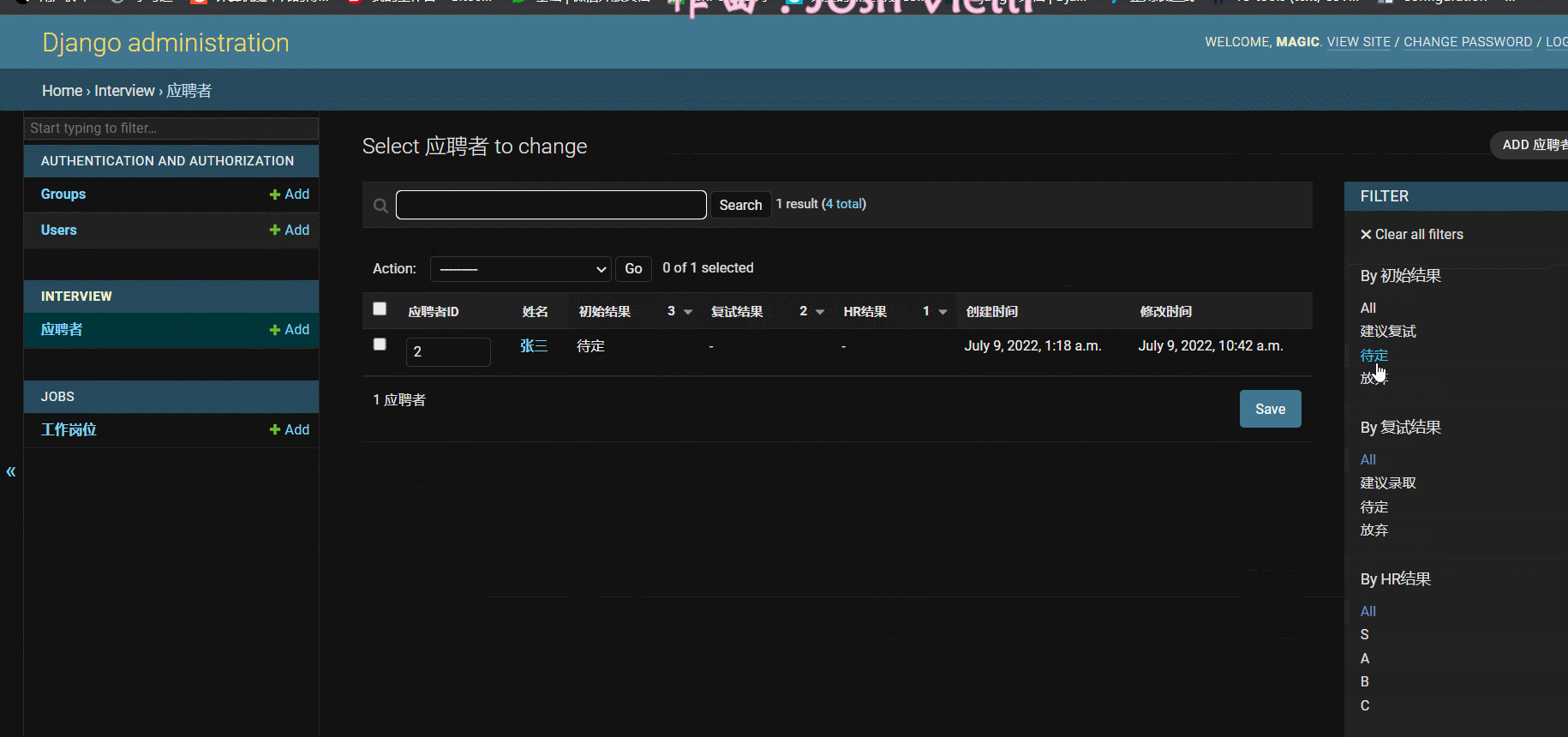
三、企业域账号集成
目的:省去多余的账号管理(每个人都要注册一个账号,过于麻烦)

- LDAP 成员页面
- 在服务器的服务



1) 安装应用
pip install django-python3-ldap
- 在
setting.py应用将app加进来
OpenLDAP设置



这样用户可以有两个账号,一个是使用LDAP账号,一个是admin账号,每个员工登陆一下时会需要在每次登录自动录入账号到user群,但却由于显示非员工无法登录,需要在admin后台修改其为员工然后登录,但是这样需要一个一个登录,效率低下
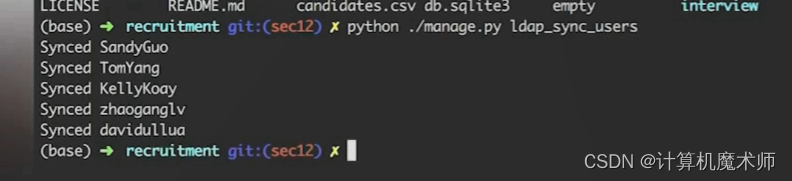
- 解决:通过
manage脚本导入用户信息
python manage.py ldap_sync_users
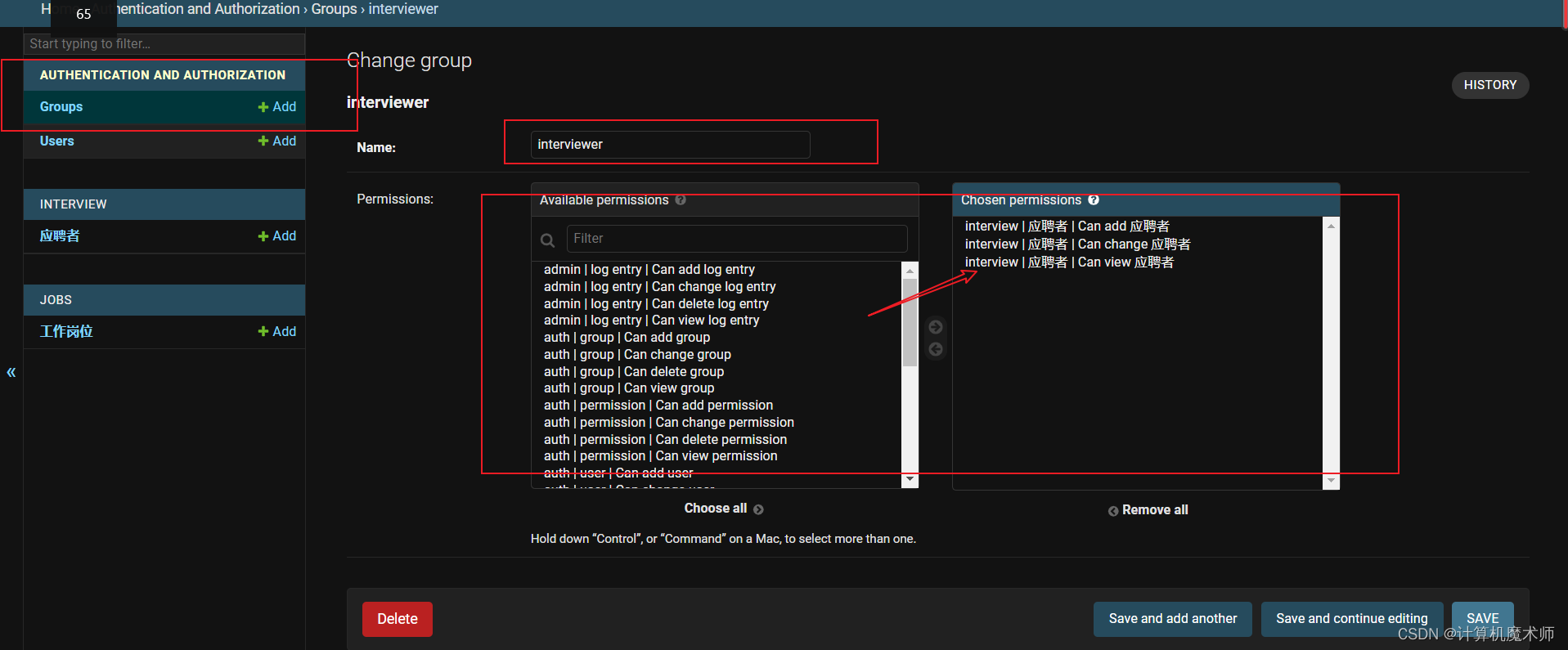
2) 设置面试官和HR权限(群组)
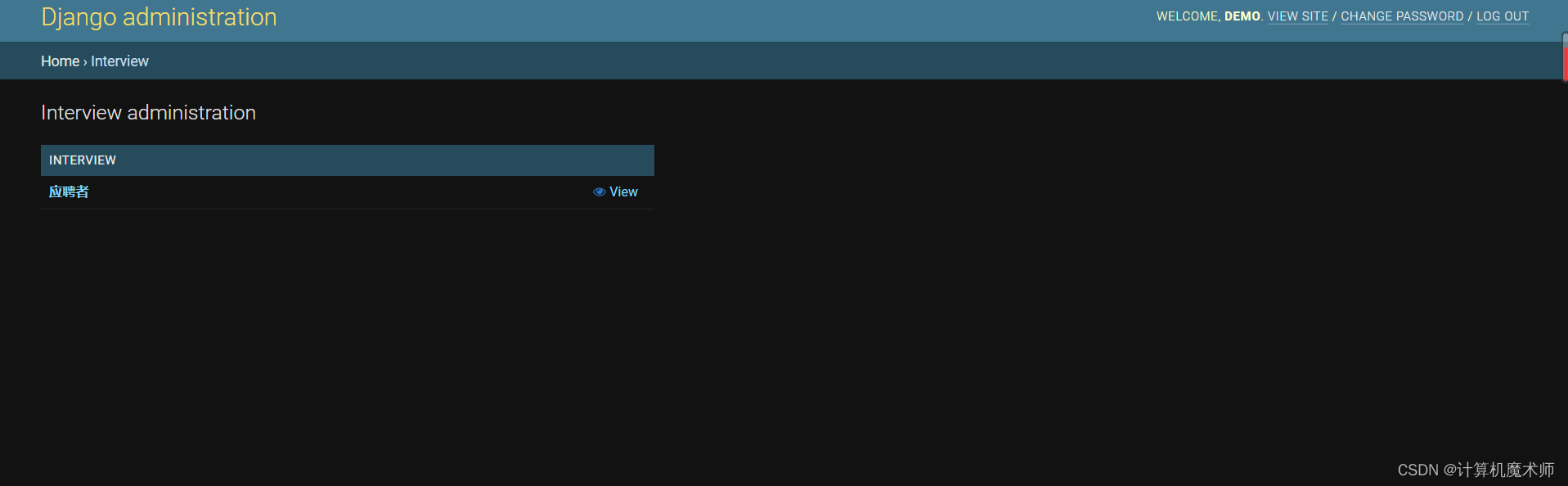
- HR的管理页面
四、添加导出为csv功能
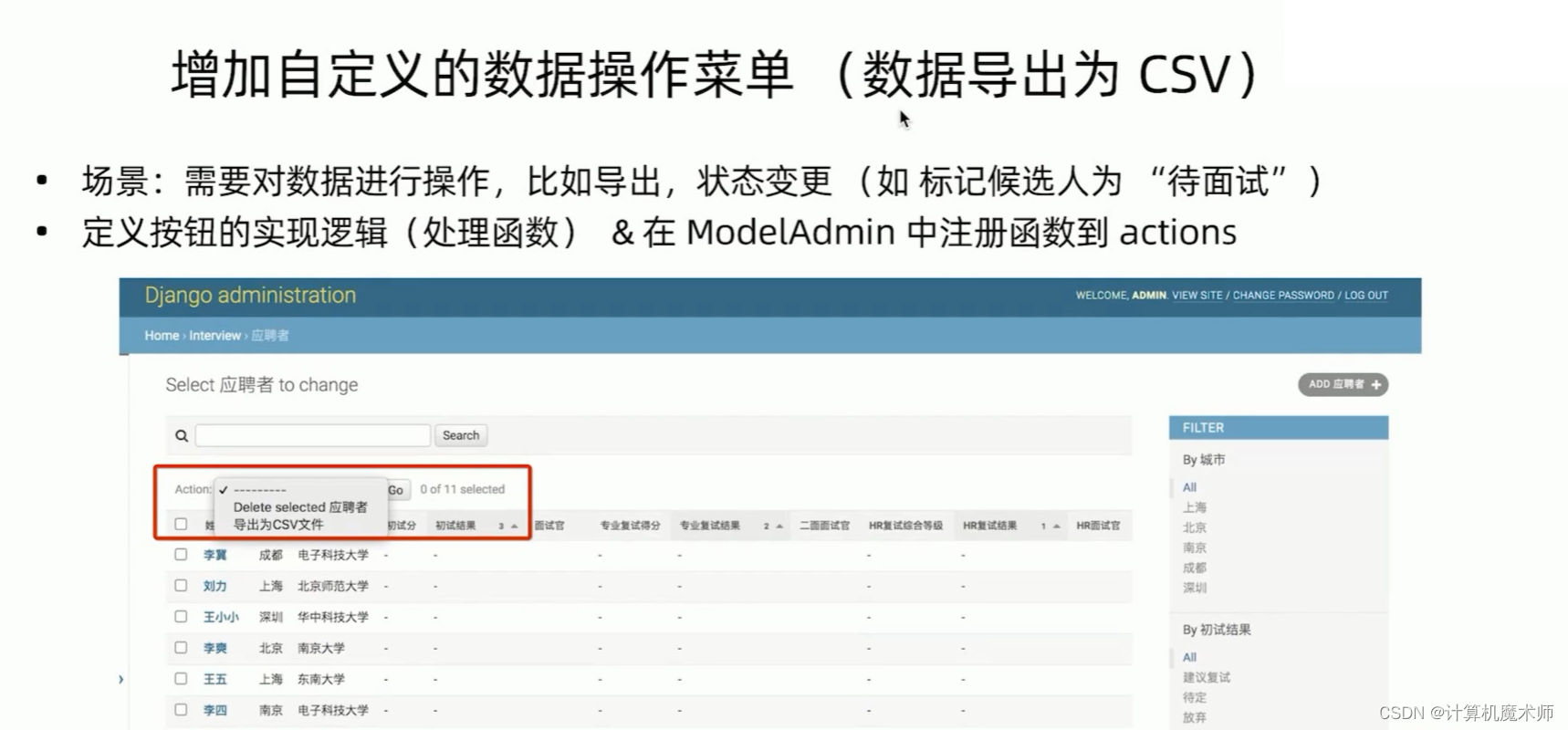
- 添加action,指向不同函数进行处理
操作函数
import csv
from datetime import datetime
# 注册为 action
@admin.action(description='导出为csv文件')
def export_model_as_csv(modeladmin, request, queryset):
# 告诉浏览器以附件处理
response = HttpResponse(content_type="text/csv")
field_list = ['user_name', 'first_result', "first_interviewer", 'second_result', "second_interviewer",
'hr_result', "hr_interviewer", 'modify_time']
# attachment 类型是附件 名字为 ""(为字符串,需要单双引号)
response['Content-Disposition'] = 'attachment; filename= "recruitment_candidate_list_%s.csv"' % (
datetime.now().strftime('%Y-%m-%d,%H-%M-%S')
)
# candidate_list = pd.DataFrame(columns=columns)
# _meta 是一个Options对象 有get_filed and get_fields 两个方法,得到对象关键字的大写
writer = csv.writer(response)
writer.writerow([queryset.model._meta.get_field(f).verbose_name.title() for f in field_list])
# columns_name = [queryset.model._meta.get_field(f).verbose_name.title() for f in columns]
for obj in queryset:
## 单行记录
csv_line_values = []
for field in field_list:
field_object = queryset.model._meta.get_field(field)
field_values = field_object.value_from_object(obj)
csv_line_values.append(field_values)
writer.writerow(csv_line_values)
return response
在adminmodel类中引入action
@admin.register(Candidate)
class CandidateAdmin(admin.ModelAdmin):
list_display = (
'user_id', 'user_name', 'first_result', "first_interviewer", 'second_result', "second_interviewer", 'hr_result',
"hr_interviewer", 'modify_time')
# import actions to use
actions = [export_model_as_csv, ]
···
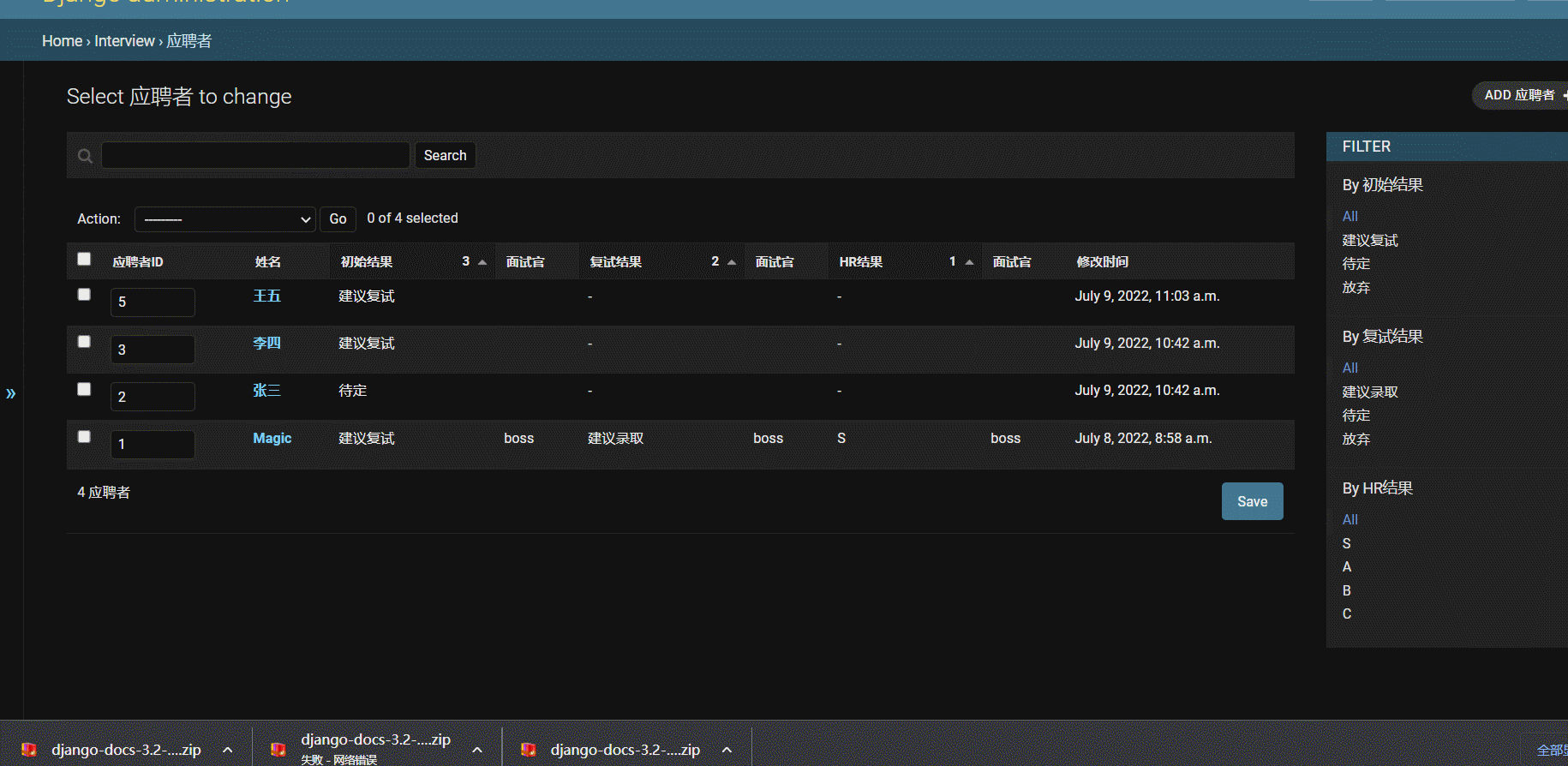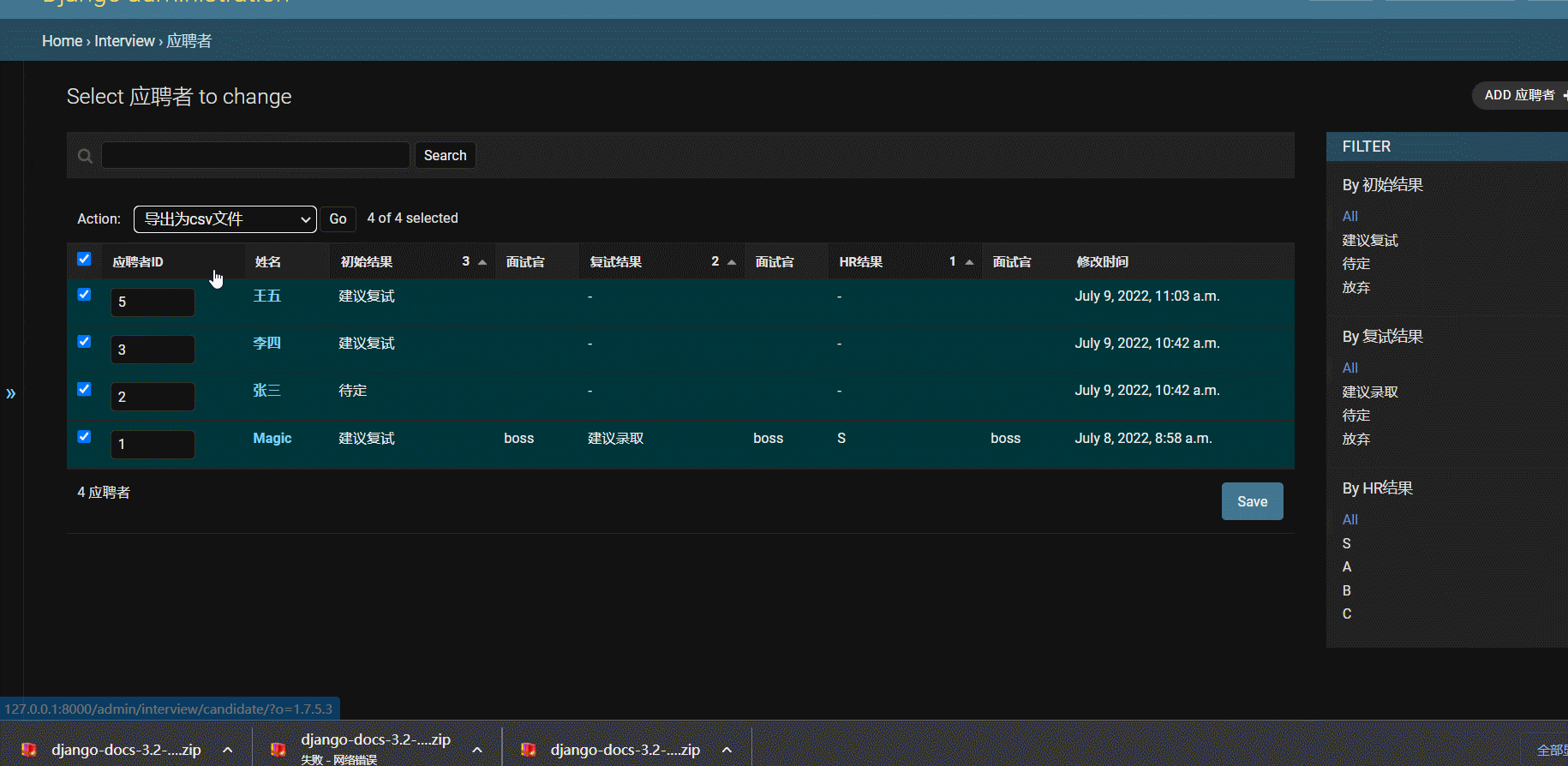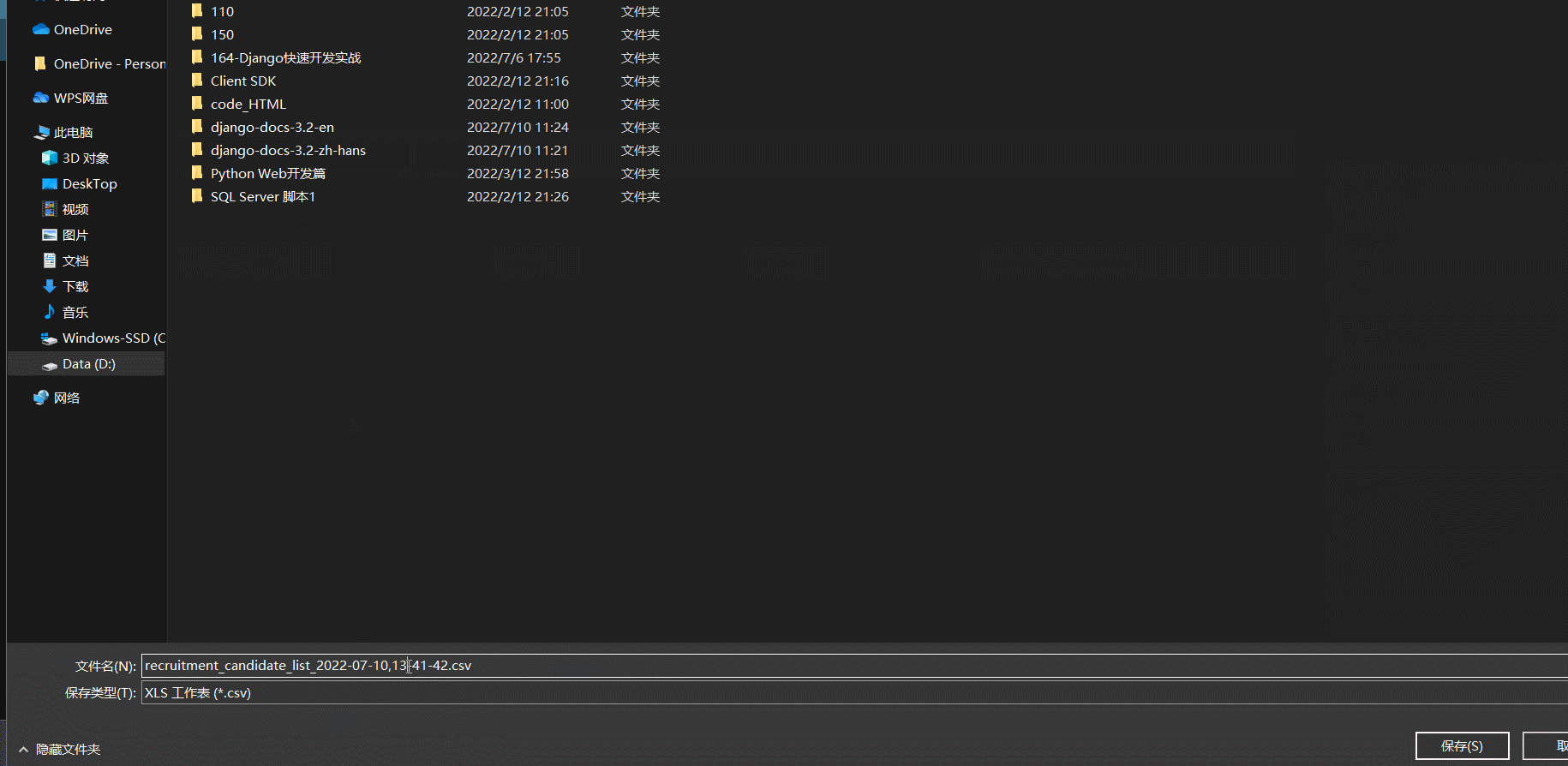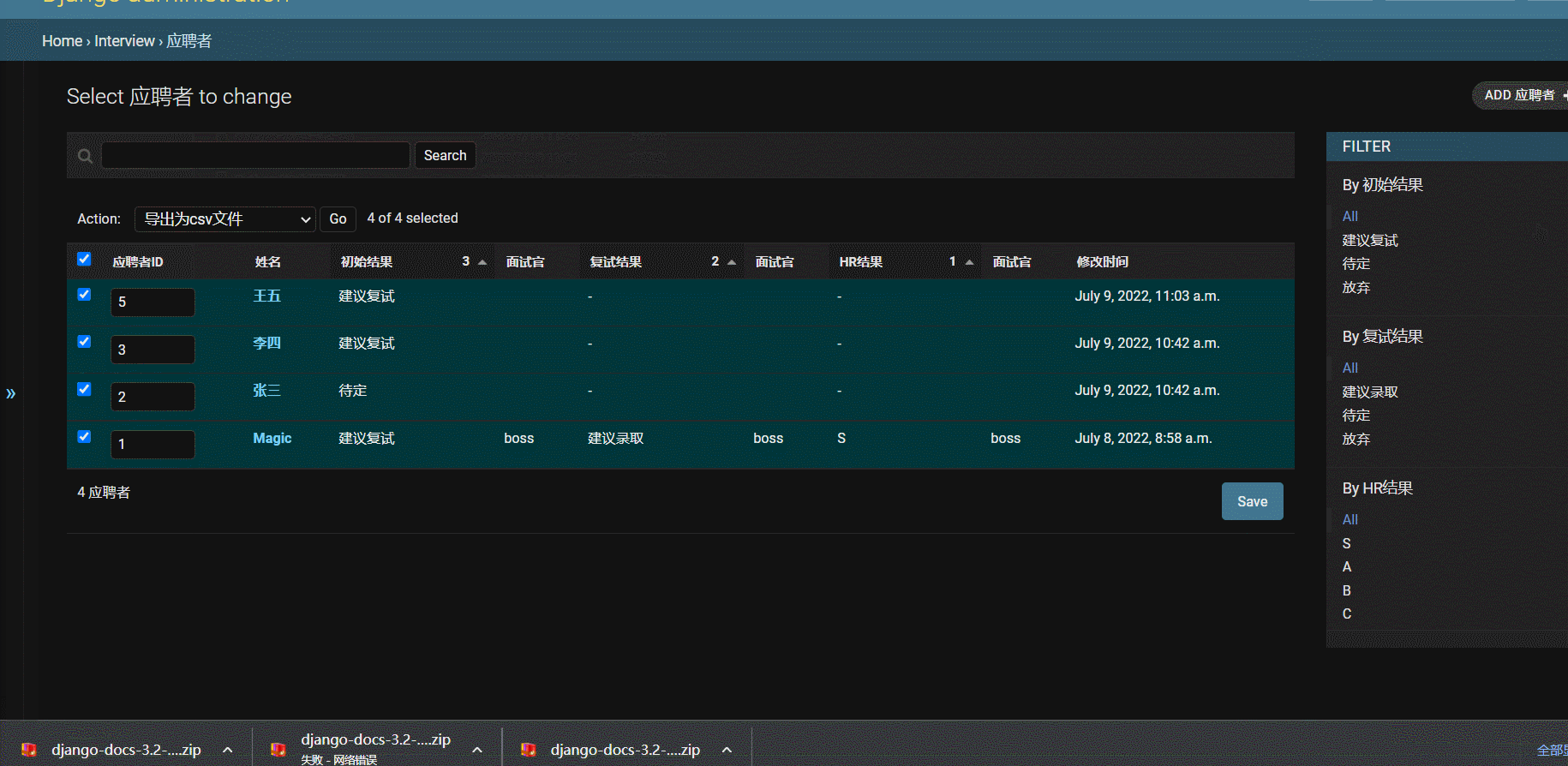
- 效果
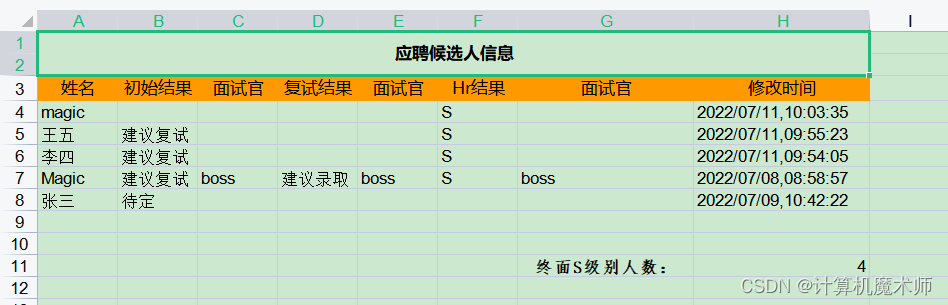
六、添加excel导出功能(样式)
此时HR需要能够导出一个具有好看样式的表格,可以统计S分数的候选人,此时我们使用python中处理excel表格文件的三板斧
xlrd-xlwt-xlutils
- 在需要导入excel文件,我们可以用
xlrd-xlutils-xlwt,通过xlutils将book转换为workbook,进行读写操作
这里现在只需要用到xlrt
def setStyle(name, height=200, font_color=256, background_color=0x40, background=False, bold=False, align=True,
border=False, border_size=1):
"""
xlwt样式写入设置
"""
style = xlwt.XFStyle() # 初始化样式
if background:
# 创建背景模式对像
pattern = xlwt.Pattern()
# 固定样式
pattern.pattern = xlwt.Pattern.SOLID_PATTERN # May be: NO_PATTERN, SOLID_PATTERN, or 0x00 through 0x12
pattern.pattern_fore_colour = background_color # 设置模式颜色 May be: 8 through 63. 0 = Black, 1 = White, 2 = Red, 3 = Green, 4 = Blue, 5 = Yellow, 6 = Magenta, 7 = Cyan, 16 =
# Maroon, 17 = Dark Green, 18 = Dark Blue, 19 = Dark Yellow , almost brown), 20 = Dark Magenta, 21 = Teal, 22 = Light Gray, 23 = Dark Gray, the list goes on...
style.pattern = pattern
font = xlwt.Font() # 为样式创建字体
# 字体类型:比如宋体、仿宋也可以是汉仪瘦金书繁
font.name = name
# 设置字体颜色
font.colour_index = font_color
# 字体大小
font.height = height
# 字体加粗
font.bold = bold
# 定义格式
style.font = font
if border:
# 框线
borders = xlwt.Borders()
borders.left = border_size
borders.right = border_size
borders.top = border_size
borders.bottom = border_size
style.borders = borders
# 细实线:1,小粗实线:2,细虚线:3,中细虚线:4,大粗实线:5,双线:6,细点虚线:7
# 大粗虚线:8,细点划线:9,粗点划线:10,细双点划线:11,粗双点划线:12,斜点划线:13
if align:
# 设置单元格对齐方式
al = xlwt.Alignment()
# 0x01(左端对齐)、0x02(水平方向上居中对齐)、0x03(右端对齐)
al.horz = 0x02
# 0x00(上端对齐)、 0x01(垂直方向上居中对齐)、0x02(底端对齐)
al.vert = 0x01
style.alignment = al
return style
# 注册为 action
@admin.action(description='导出为excel文件')
def export_model_as_excel(modeladmin, request, queryset):
# 告诉浏览器以附件处理
response = HttpResponse(content_type='application/vnd.ms-excel')
field_list = ['user_name', 'first_result', "first_interviewer", 'second_result', "second_interviewer",
'hr_result', "hr_interviewer", "modify_time"]
# attachment 类型是附件 名字为 ""(为字符串,需要单双引号)
response['Content-Disposition'] = 'attachment; filename= "recruitment_candidate_list_%s.xlsx"' % (
datetime.now().strftime('%Y-%m-%d,%H-%M-%S')
)
# 使用 xlwt 生成表格
title = ['应聘候选人信息']
wb = xlwt.Workbook(encoding='utf-8') # 创建一个excel #ascii'可视为'utf-8'的一部分,so用'utf-8'更好
ws = wb.add_sheet('候选人') # 新建一个工作表
ws.write_merge(0, 1, 0, len(field_list) - 1, title, style=setStyle('微软雅黑', height=200, font_color=256, bold=True, border=True, border_size=1))
for col, name in enumerate(field_list): # 变为枚举类型,默认从0开始,
ws.write(2, col, queryset.model._meta.get_field(name).verbose_name.title(), style=setStyle('微软雅黑', height=200, font_color=0x40, background=True, background_color=0x4682B4))
row = 3 # 从第三行开始
# style_date = xlwt.XFStyle()
# style_date.num_format_str = 'M/D/YY h:mm'
S_sum = 0
for obj in queryset:
columns = 0
# # 单行记录
for field in field_list:
field_object = queryset.model._meta.get_field(field)
field_values = field_object.value_from_object(obj)
logger.warning(type(field_values))
if type(field_values) == type(datetime.today()): # 判断是否为datetime数据类型,并指定数据为时间格式
field_values = field_values.strftime('%Y/%m/%d,%H:%M:%S')
ws.write(row, columns, field_values)
else:
# 累加S级别人数
if field_values == 'S':
S_sum += 1
ws.write(row, columns, field_values)
columns += 1
# 时间行宽增大
row += 1
ws.col(columns - 1).width = 5000
ws.col(columns - 2).width = 5000
ws.write(row + 2, len(field_list) - 2, '终面S级别人数:', setStyle(name='仿宋', bold=True))
ws.write(row + 2, len(field_list) - 1, S_sum)
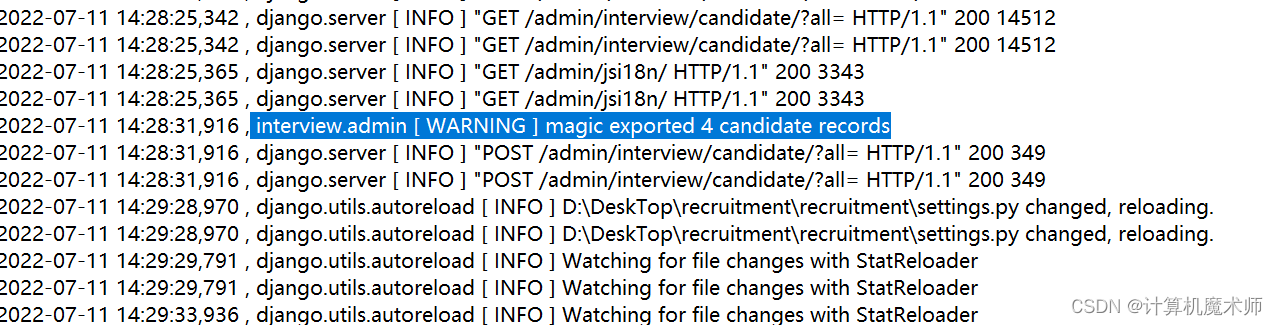
logger.warning('{} exported {} candidate records'.format(request.user, len(queryset)))
wb.save(response) # 保存到文件类对象
return response
- 导出样式
五、记录日志以方便排查问题
1) 项目配置
- 记录详细的日志信息可以快速排查问题

和
python格式一样,使用dictConfig格式来定义日志信息,在处理级别时是按照过滤原则,handler处理其级别信息上传到记录器 记录器再根据自身级别过滤上传到 root再过滤
- 优化配置(django logging 文档,强烈建议看文档)
在项目的setting.py文件中进行如下配置
# log record
LOGGING = {
'version': 1, # 必须
"disable_existing_loggers": False, # 设置其他日志同时记录
'handlers': {
'console': { # handler 名称(表示控制台输出)
"class": "logging.StreamHandler", # 在控制台流 类
'formatter': 'simple',
'level': 'INFO'
},
'file': { # handler 名称 (表示文件输出)
'level': 'INFO',
'class': 'logging.FileHandler', # 文件流类
'formatter': 'simple',
# 得到完整路径并拼接
'filename': os.path.join(BASE_DIR, 'logs/debug.log'),
},
},
'formatters': {
# simple 类
'simple': {
'format': '%(asctime)s , %(name)s [ %(levelname)s ] %(message)s',
}
},
# 根日志记录器(父记录器)
'root': {
'handlers': ['console', 'file'], # 记录到文件和控制台中
'level': 'INFO',
},
'loggers': {
'django': {
'handlers': ['file'],
'level': 'DEBUG',
'propagate': True,
}
}
}
- 运行服务器查看
python manage.py runserver 0.0.0.0:8000
2)在admin中配置python的logging模块
# 得到 当前日志记录对象
# logging.basicConfig(level=logging.DEBUG,format="'%(asctime) %(name) %(levelname) %(message)")
logger = logging.getLogger(__name__)
def ·······
·······
# 输出 导出对象以及条数(只有warning以上才会被打印,可以自己配置)
logger.warning('{} exported {} candidate records'.format(request.user, len(queryset)))
return response

参考文献:
Python 常用模块大全(整理)
python的xlwt模块使用
🤞到这里,如果还有什么疑问🤞
🎩欢迎私信博主问题哦,博主会尽自己能力为你解答疑惑的!🎩
🥳如果对你有帮助,你的赞是对博主最大的支持!!🥳
- 点赞
- 收藏
- 关注作者
评论(0)