【Django | 开发】面试招聘信息网站(快速搭建核心需求)


🤵♂️ 个人主页: @计算机魔术师
👨💻 作者简介:CSDN内容合伙人,全栈领域优质创作者。
🌐 推荐一款找工作神器网站: 牛客网🎉🎉|笔试题库|面试经验|实习招聘内推
还没账户的小伙伴 速速点击链接跳转牛客网登录注册 开始刷爆题库,速速通关面试吧🙋♂️
该文章收录专栏
✨—【Django | 项目开发】从入门到上线 专栏—✨
@[toc]
✨ 本文主要讲解核心思想,省略了一些细枝末节(如setting中简单配置等)✨
一、创建职位管理后台
1.1 定义用户模型
创建recruitment(招聘) 项目和 jobs应用
我们在对项目开发时,需要提前设计好整个数据表的字段(不能想到什么再加,后面修改和数据迁移操作会麻烦的多)

- 在
jobs.models.py应用中创建如下模型:
from datetime import datetime
from django.contrib.auth.models import User
from django.db import models
# Create your models here.
JobType = [
(0, '产品类'),
(1, '技术类'),
(2, '运营类'),
(3, '设计类')
]
JobPlace = [
(0, '上海市'),
(1, '北京市'),
(2, '惠州市'),
(3, '广州市')
]
class Jobs(models.Model):
job_type = models.SmallIntegerField(choices=JobType, blank=False, verbose_name='职位类别')
job_name = models.CharField(max_length=200, blank=False, verbose_name='职位名称')
job_place = models.SmallIntegerField(choices=JobPlace, blank=False, verbose_name='工作地点')
job_responsibility = models.TextField(verbose_name='工作职责', blank=False, max_length=1024)
job_require = models.TextField(max_length=2048, verbose_name='工作要求')
# on_delete 默认为忽略这条数据, 可以设置为级联删除或者NULL, 引用函数不用()
# 默认值为当前用户, 与用户多对一
job_creator = models.ForeignKey(User, on_delete=models.SET_NULL, null=True, default=User,
verbose_name='创建人') # 不能添加default=User 这里的是User 对象(不是特定的user,需要request.user
# 不要date 要的是 datetime, 引用函数
create_time = models.DateTimeField(verbose_name='创建日期', default=datetime.now)
modify_time = models.DateTimeField(verbose_name='修改日期', default=datetime.now)
def __str__(self):
return self.job_name
1.2 在admin优化管理
from django.contrib import admin
from jobs.models import Jobs
# 方法一
@admin.register(Jobs)
class JobAdmin(admin.ModelAdmin):
# exclude 不包括列表.隐藏字段(系统自定生成默认值为其值)
exclude = ('create_time', 'modify_time', 'job_creator')
# 展示列表
list_display = ('job_name', 'job_type', 'job_place', 'job_creator', 'create_time', 'modify_time')
# ModelAdmin父类所定义的方法 会被自动调用
def save_model(self, request, obj, form, change):
# object对象 由于隐藏了job_creator字段,且没有默认值,所以需要手动加上
obj.job_creator = request.user
# obj.save() # super 实例的 save_model 方法的源码是 obj.save()
super().save_model(request, obj, form, change)
# 方法二,绑定二者
# admin.site.register(Jobs,JobAdmin)
1.3 效果
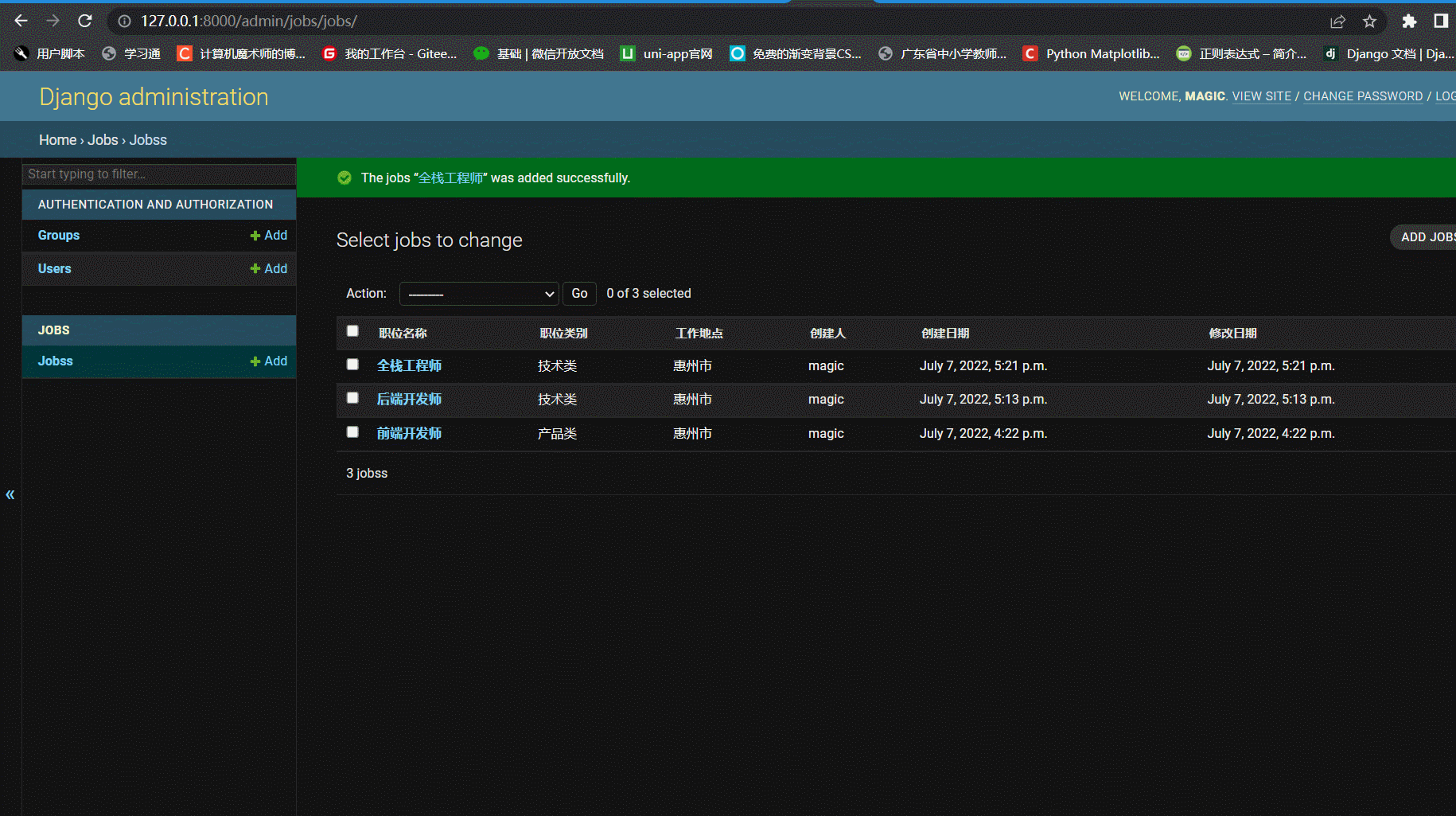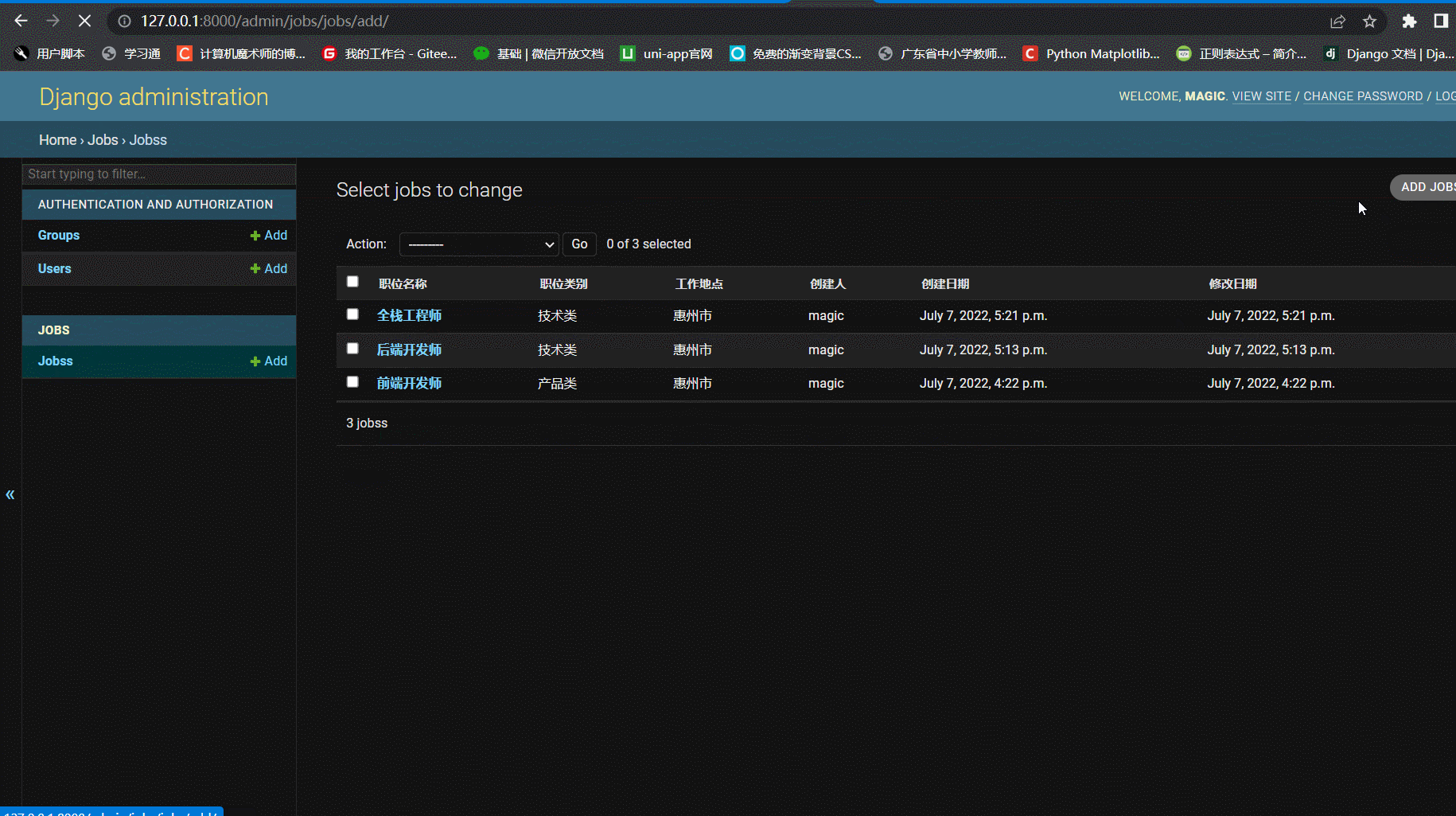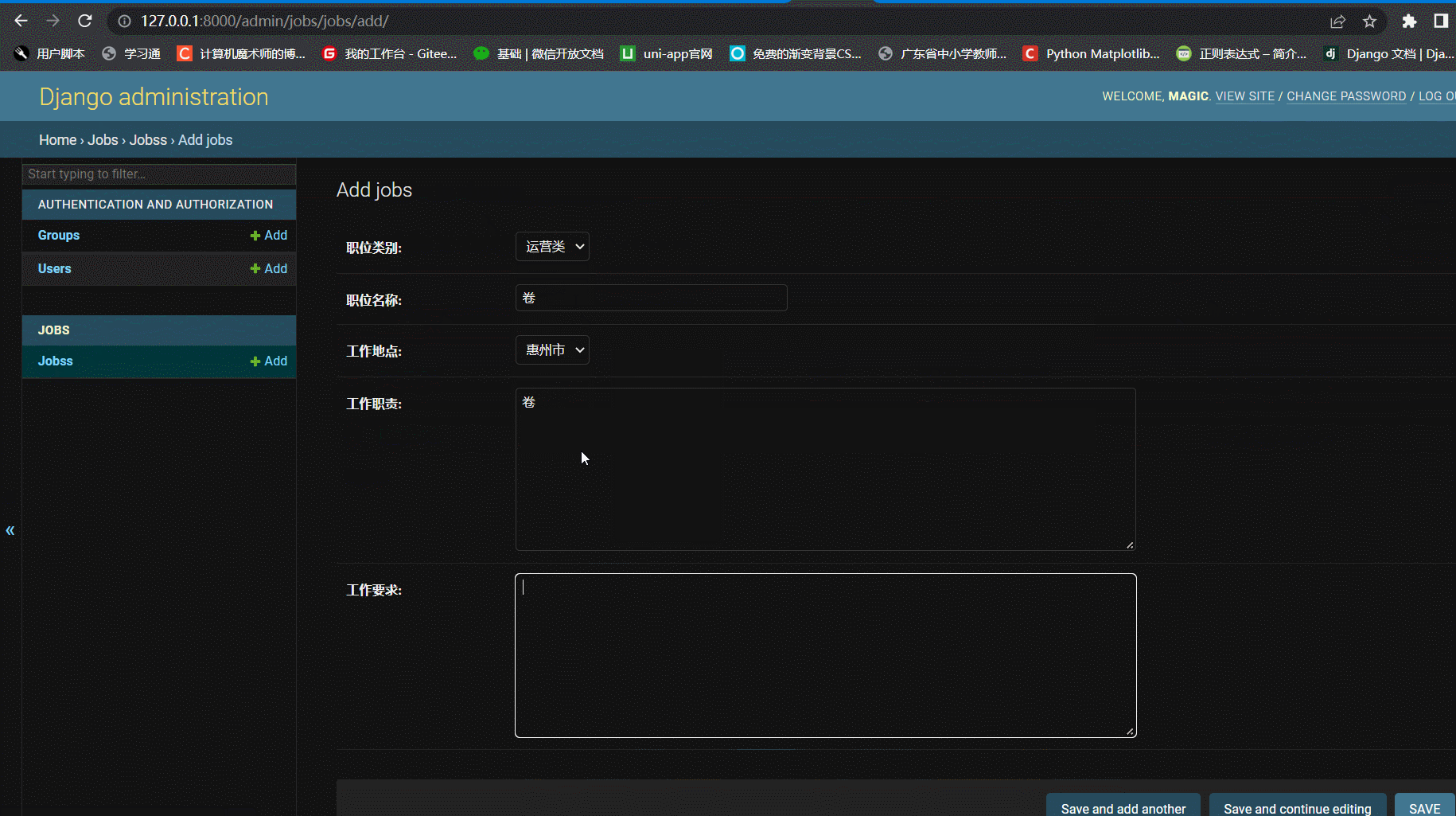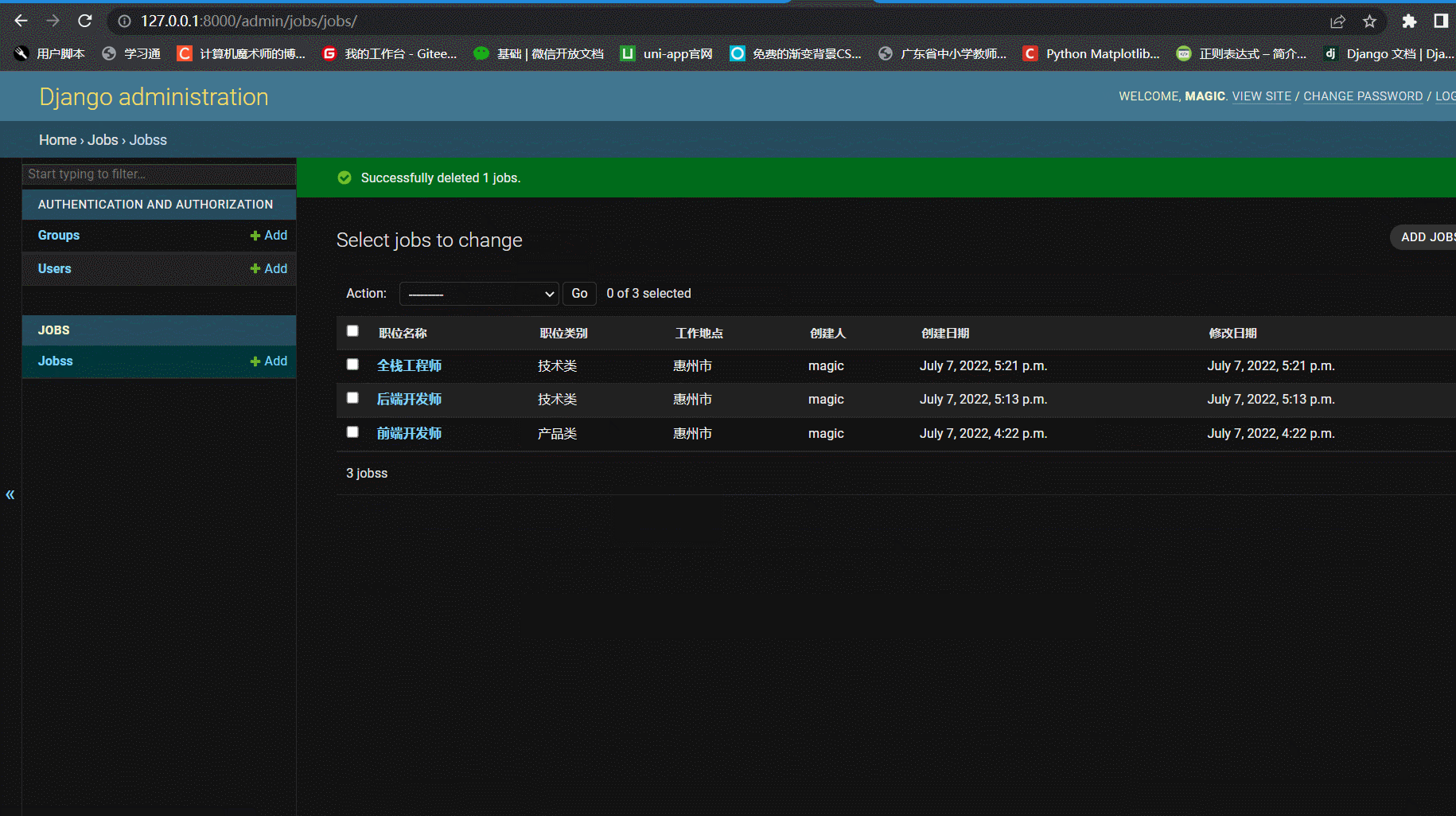
二、匿名用户可查看职位列表和职位详情
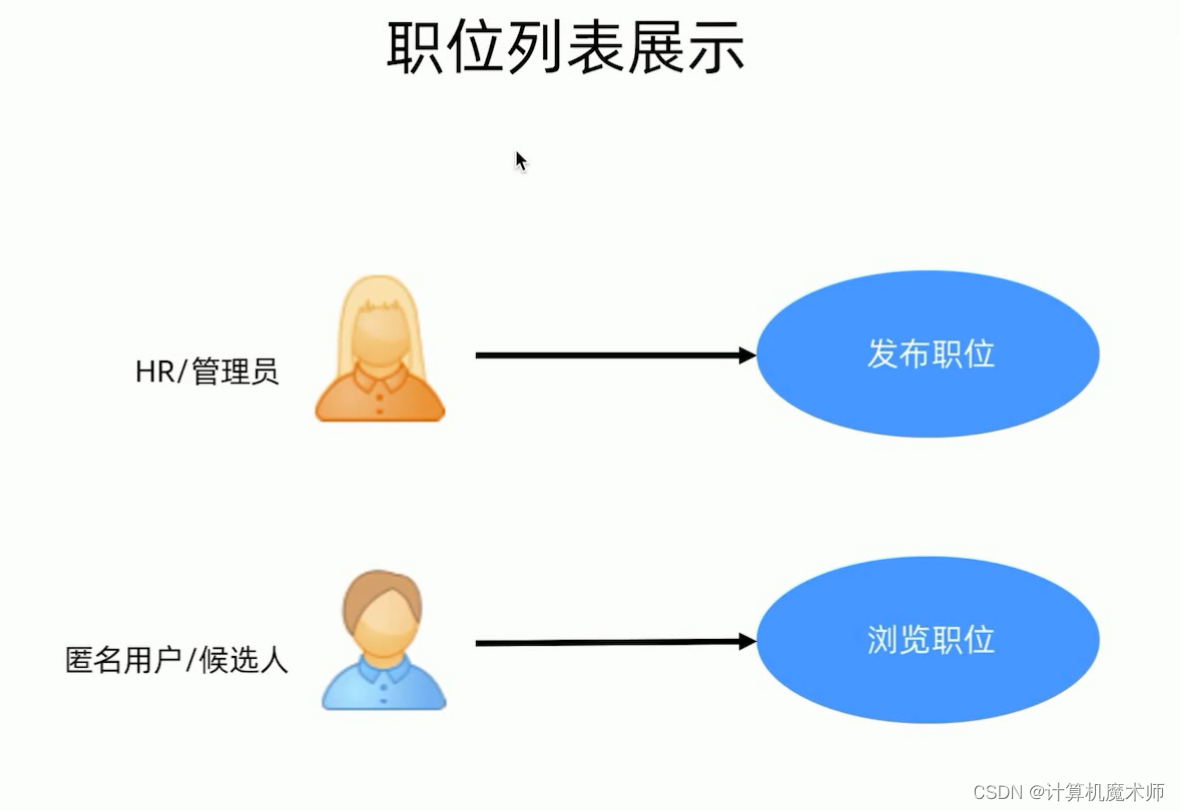
- 创建模板目录
templates和配置模板目录
创建基础模板base.html
<!-- base.html -->
<h2 style="margin:auto;width:50%;">霍格沃兹</h2>
{% block_content %}
{% endblock %}
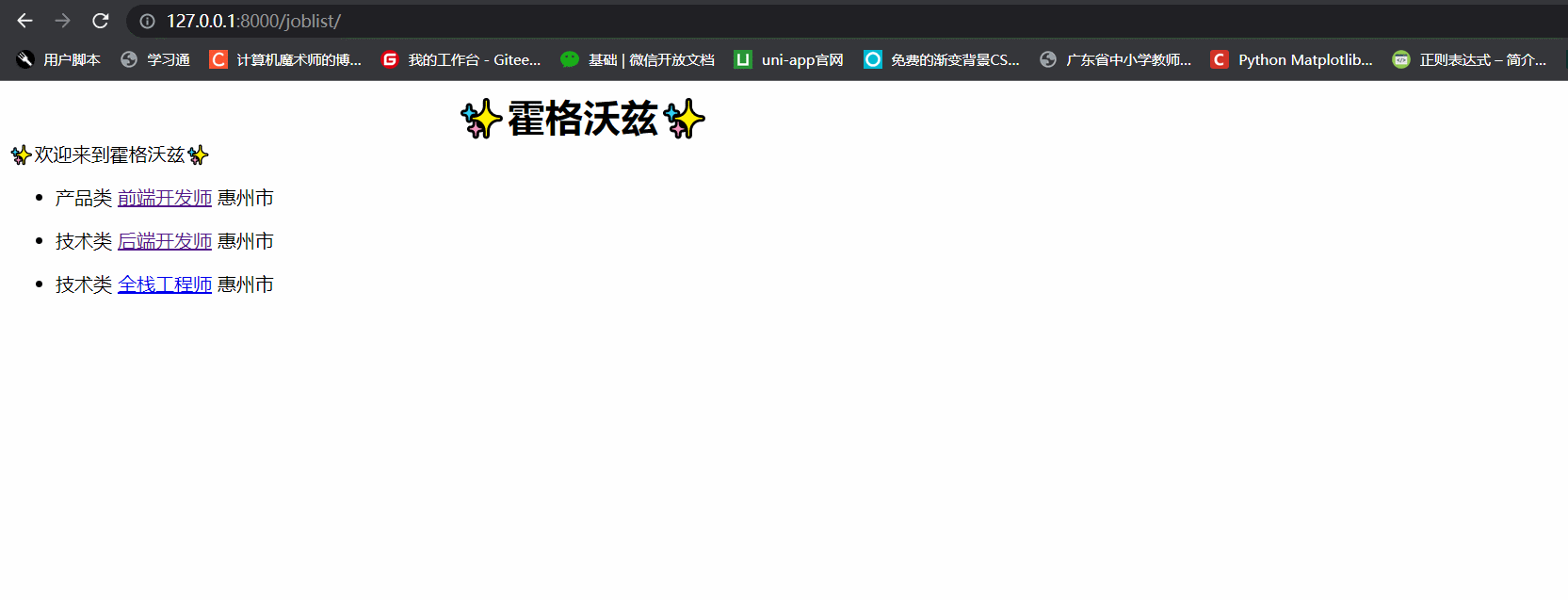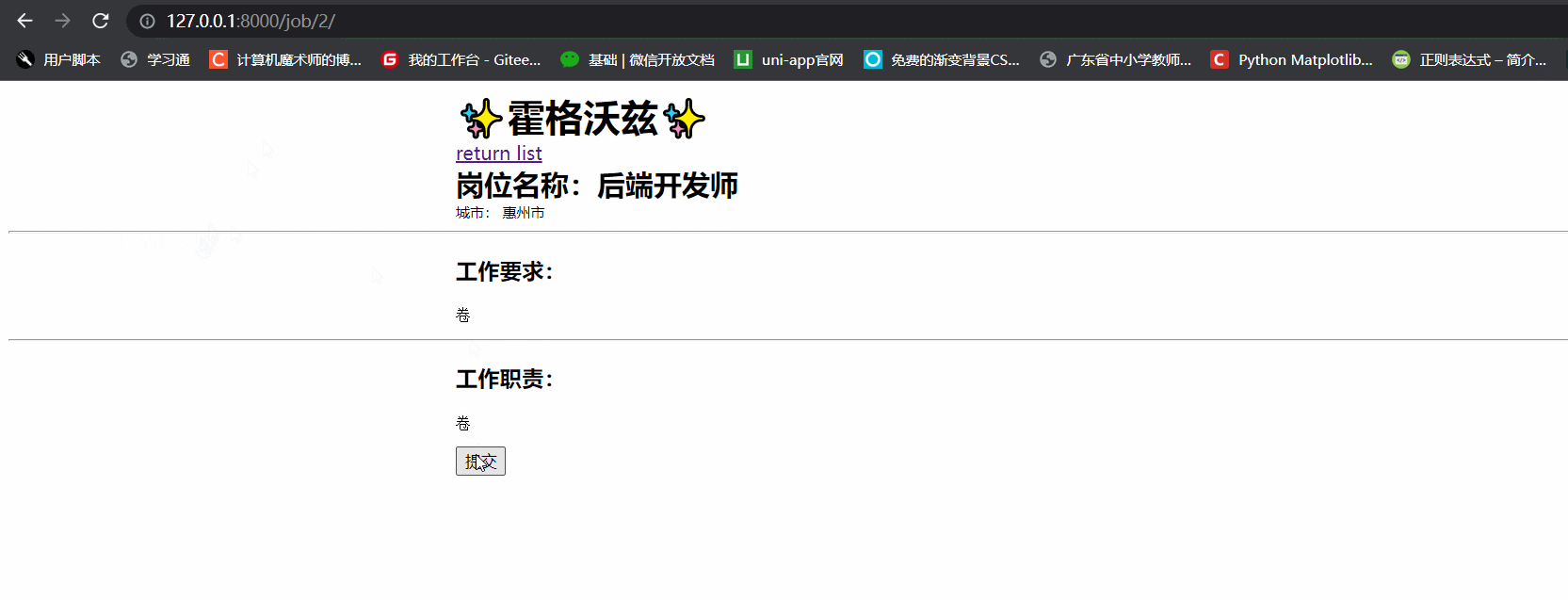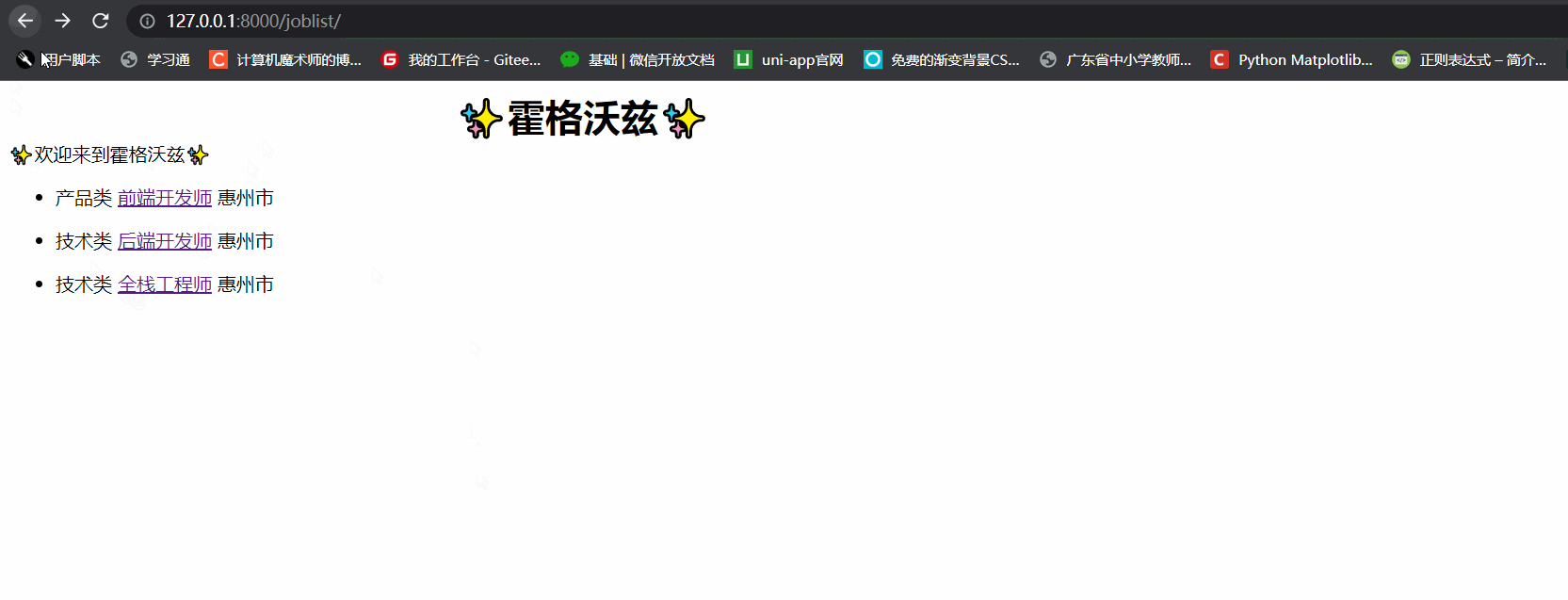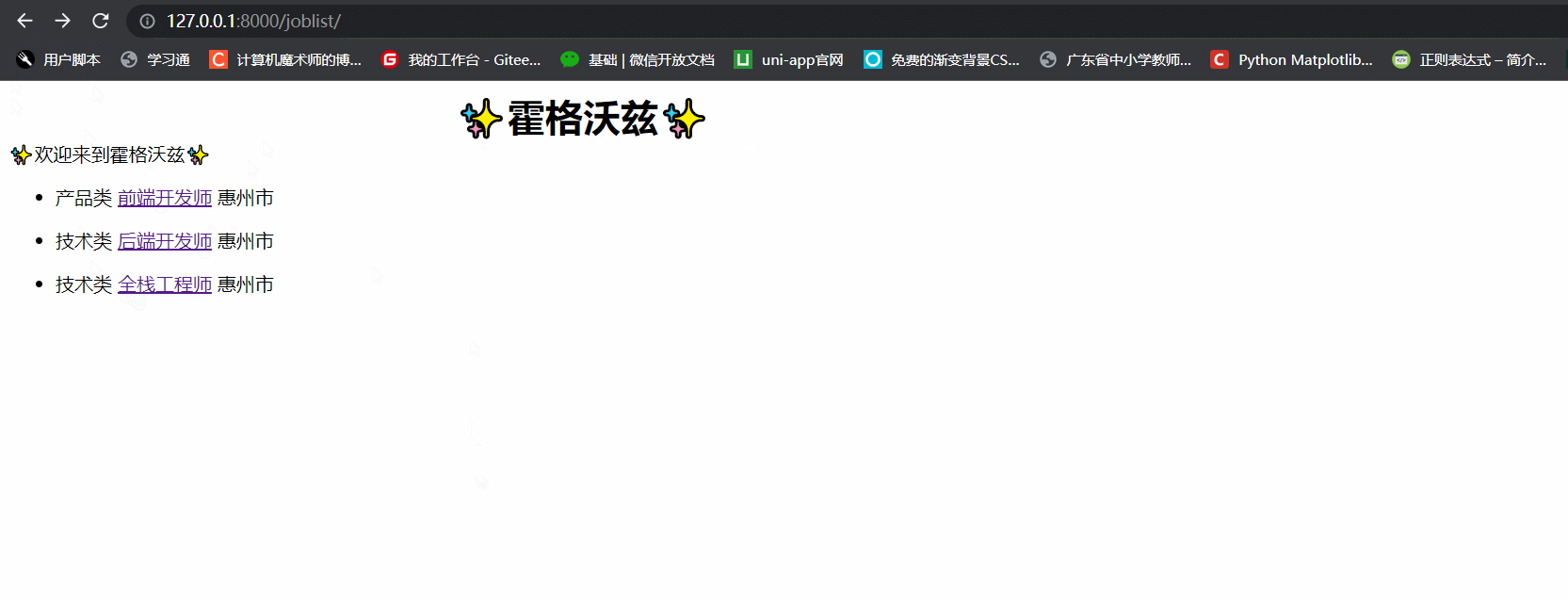
jobs_list.html代码
{% extend 'base.html' %}
{% block_content %}
欢迎来到霍格沃兹
{% if jobList %}
{% for job in jobList %}
<ul>
<li>{{ job.job_type }} <a href="/job/{{ job.id }}"></a>{{ job.job_name }} {{ job.job_place }}</li>
</ul>
{% endfor %}
{% else %}
<p> 没有可用的职位✨</p>
{% endif %}
{% endblock %}
job-item.html页面(有点简陋)
{% extends 'base.html' %}
{% block content %}
<div style="margin:auto;width:50%;" class="">
<a href="{% url 'jobList' %}" style="margin:auto;width:50%;">return list</a>
</div>
{% if job %} <!-- 如果职位为显示无职位-->
<h2 style="margin:auto;width:50%;">岗位名称:{{ job.job_name }}</h2>
<div style="margin:auto;width:50%;">
</div>
<div style="margin:auto;width:50%;font-size: 10px;">
城市: {{ job.job_place }}
</div>
<hr>
<div style="margin:auto;width:50%;">
<h3>工作要求:</h3>
<pre>{{ job.job_responsibility }}</pre>
</div>
<hr>
<div style="margin:auto;width:50%;">
<h3>工作职责:</h3>
<pre>{{ job.job_require }}</pre>
</div>
<div style="margin:auto;width:50%;"><input type="submit" value="提交"></div>
{% else %}
<p> 职位不存在 </p>
{% endif %}
{% endblock %}
<style>
</style>
- 效果

三、产品背景迭代思维
3.1 产品背景

- 表格

- 如何在一天之内交付面试管理系统呢,
3.2唯快不破:迭代思维

- 我们可以看看微信1.0版本开发迭代思想

善于利用MVP迭代思维(抓住最核心的部分实现,再通过用户的需求迭代更新)

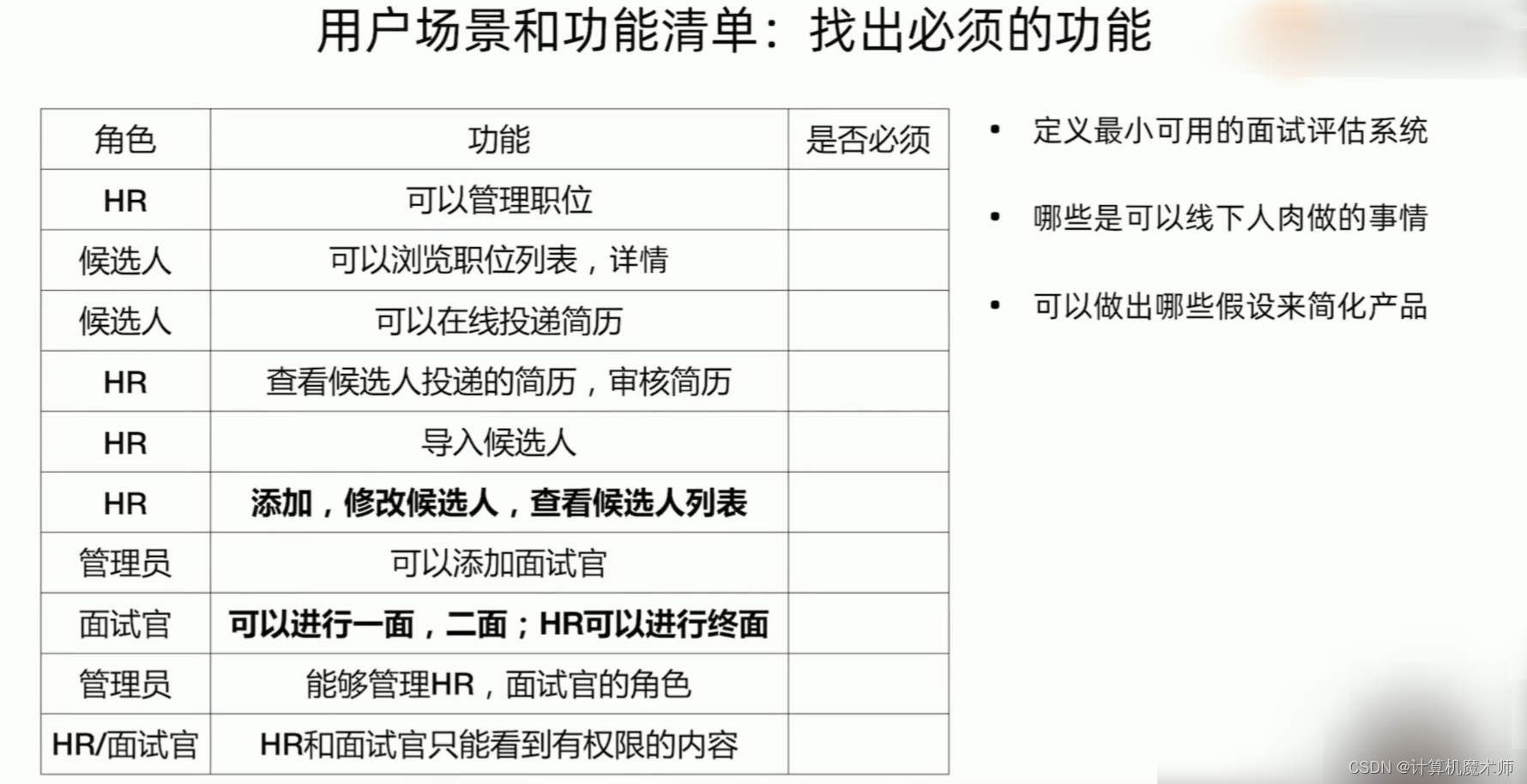
3.3 如何使用迭代思想
找出必须功能
四、数据建模&企业级数据库设计原则
4.1 数据建模

4.2 数据库设计原则



五、创建应用和模型
- 需求一:HR 可以维护候选人信息
- 需求二:面试官可以录入面试反馈
这里按照产品迭代思维用一个功能实现即可,候选人的信息以及面试反馈信息都放在一张表中。(在admin中完成实现
- 创建
interview应用,在model.py创建模型
这里为了快速搭建核心需求,忽略了一个问题,由于一面面试官二面面试官和HR信息都直接放在了一个表里,所以这里一面二面hr面试官的
foreignkey键对于得是用户,而用户处理面试官们还包括了普通用户,所以会出现在下拉选项出现可以选择应聘者得选项bug,这个读者们可以加多一个额外应聘者信息模型,外键对应面试官
from django.db import models
# Create your models here.
# 学历
DEGREE_TYPE = [
('本科', '本科'),
('硕士', '硕士'),
('博士', '博士')
]
# 一面
FIRST_INTERVIEW_SCORE_TYPE = [
('建议复试', '建议复试'),
('待定', '待定'),
('放弃', '放弃'),
]
# 复试
INTERVIEW_RESULT_TYPE = [
('建议录取', '建议录取'),
('待定', '待定'),
('放弃', '放弃'),
]
# HR
HR_SCORE = [
('S', 'S'),
('A', 'A'),
('B', 'B'),
('C', 'C'),
]
# 关于blank = true 放区别应聘者信息就好了(方便填表)
class Candidate(models.Model):
# 基础信息
user_id = models.IntegerField(verbose_name='应聘者ID', blank=True, null=True)
user_name = models.CharField(max_length=135, verbose_name='姓名')
city = models.CharField(max_length=135, verbose_name='城市', blank=True)
phone = models.CharField(max_length=135, verbose_name='手机号码')
email = models.EmailField(max_length=135, verbose_name='城市', blank=True)
gender = models.CharField(max_length=135, verbose_name='性别', blank=True)
apply_position = models.CharField(max_length=135, verbose_name='应聘职位', blank=True)
born_address = models.CharField(max_length=135, verbose_name='生源地', blank=True)
candidate_remark = models.CharField(max_length=135, blank=True, verbose_name='候选人信息备注')
# 学校与学历信息
bachelor_school = models.CharField(max_length=135, blank=True, verbose_name='本科生')
master_school = models.CharField(max_length=135, blank=True, verbose_name='研究生')
doctor_school = models.CharField(max_length=135, blank=True, verbose_name='博士生')
major = models.CharField(max_length=135, blank=True, verbose_name='专业')
degree = models.CharField(max_length=135, choices=DEGREE_TYPE, blank=True, verbose_name='学历')
# 综合能力测评成绩,
test_score_of_general_ability = models.DecimalField(max_digits=3, decimal_places=1, blank=True,
verbose_name='综合能力测评成绩', null=True)
page_score = models.DecimalField(max_digits=3, decimal_places=1, blank=True,
verbose_name='笔试成绩', null=True)
# 第一轮面试结果
first_score = models.DecimalField(max_digits=3, decimal_places=1, blank=True, verbose_name='初始分', null=True)
first_result = models.CharField(choices=FIRST_INTERVIEW_SCORE_TYPE, blank=True, verbose_name='初始结果', max_length=135)
second_interviewer = models.CharField(max_length=135, blank=True, verbose_name='面试官')
# 第二轮面试结果
second_score = models.DecimalField(max_digits=3, decimal_places=1, blank=True, verbose_name='初始分')
second_result = models.CharField(choices=INTERVIEW_RESULT_TYPE, blank=True, verbose_name='复试结果', max_length=135)
first_interviewer = models.CharField(max_length=135, blank=True, verbose_name='面试官')
# HR
hr_score = models.DecimalField(max_digits=3, decimal_places=1, blank=True, verbose_name='hr复试得分')
hr_result = models.CharField(choices=HR_SCORE, blank=True, verbose_name='复试结果', max_length=135)
hr_interviewer = models.CharField(max_length=135, blank=True, verbose_name='面试官')
# 每张表都需要的原则
create_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
modify_time = models.DateTimeField(auto_now=True, verbose_name='修改时间')
class Mate:
db_table = 'candidate'
verbose_name = '应聘者'
verbose_name_plural = '应聘者' # 复数形式
# python 3方法,2是 unicode 把对象转换为字符串(当遇到数据类型转换时返回该字符串,与c++转换构造函数一样。遇到其他类型指定转换值)
def __str__(self):
return self.user_name
- 在
admin.py中
from django.contrib import admin
from interview.models import Candidate
# Register your models here.
@admin.register(Candidate)
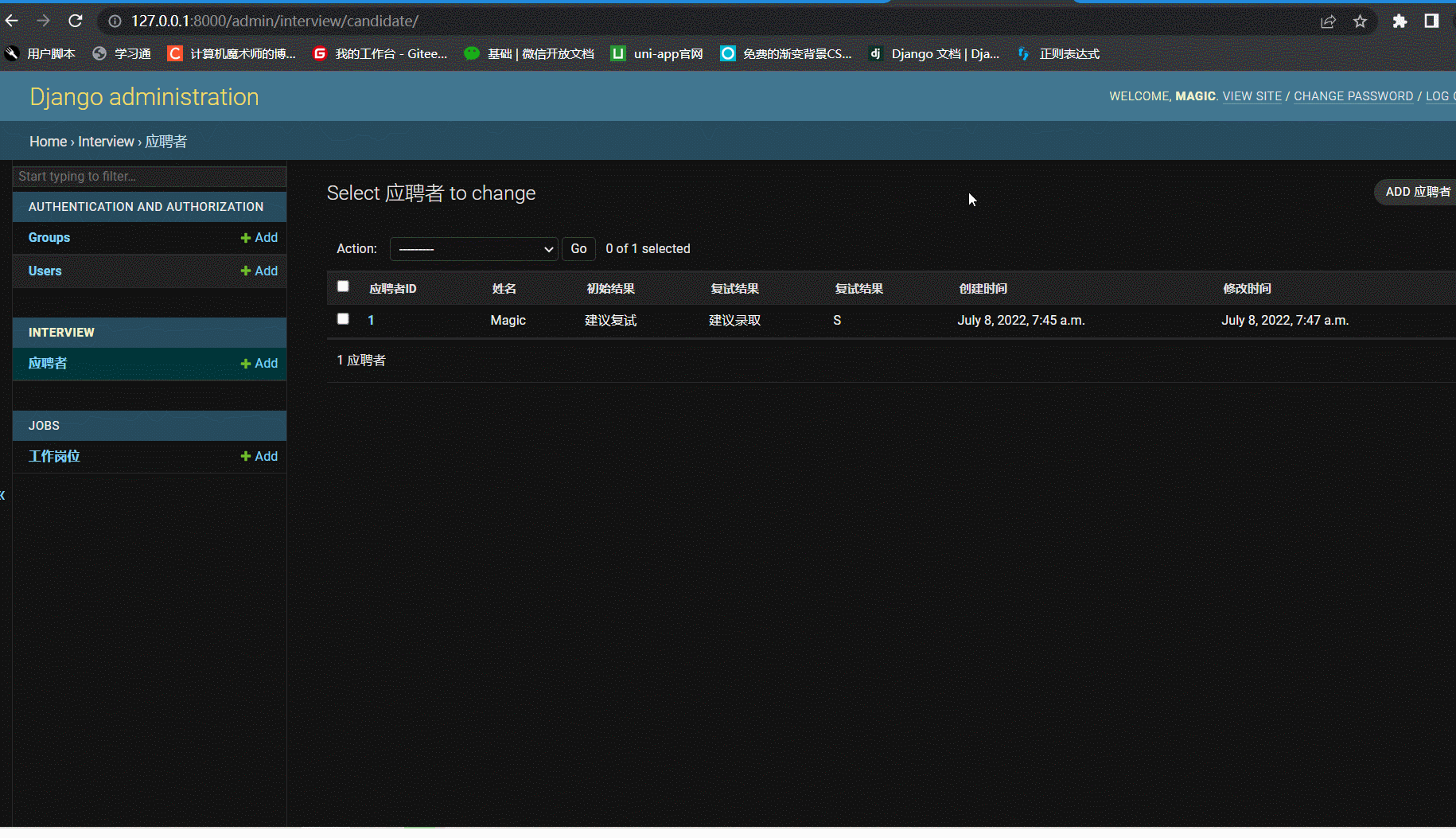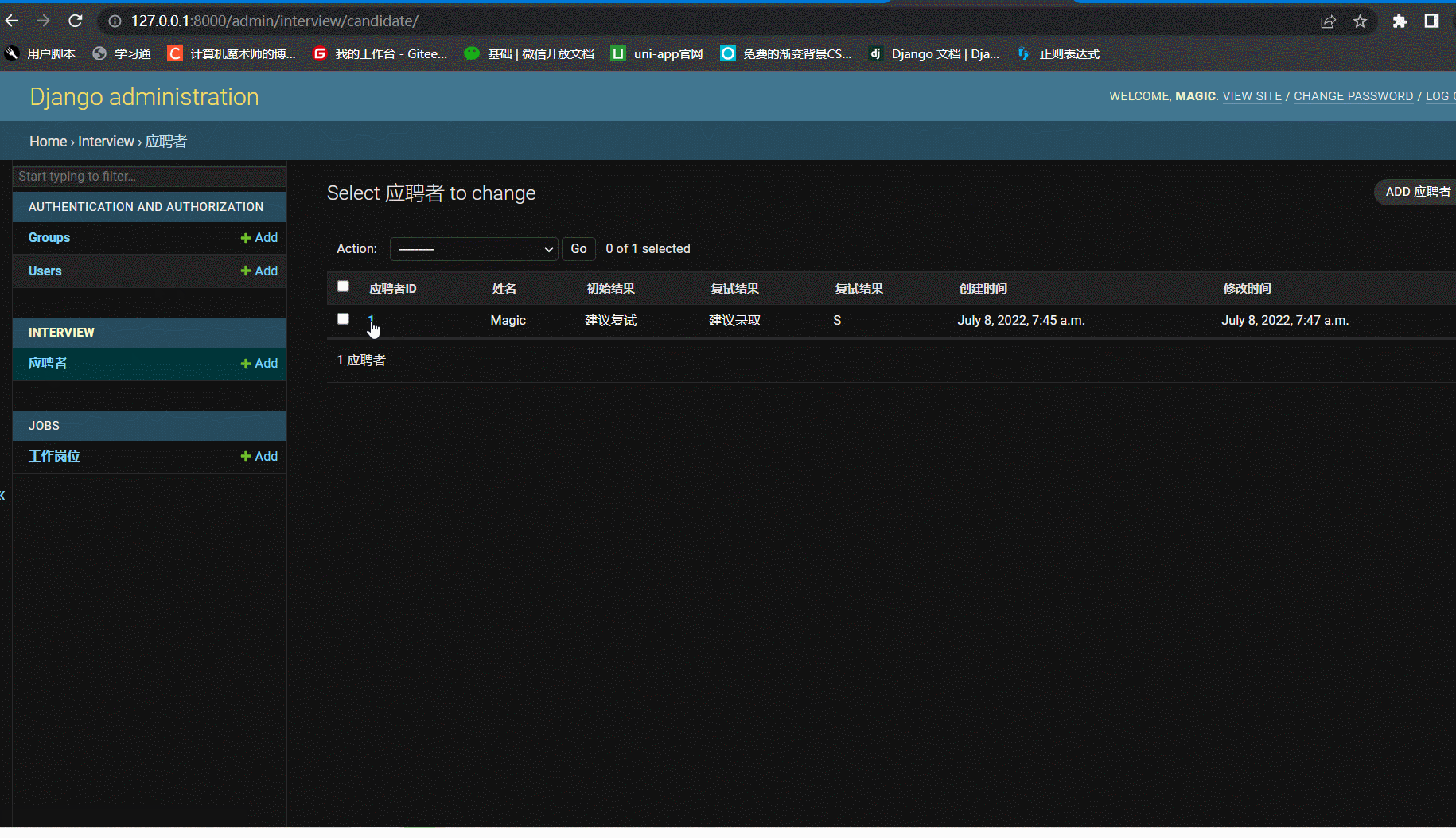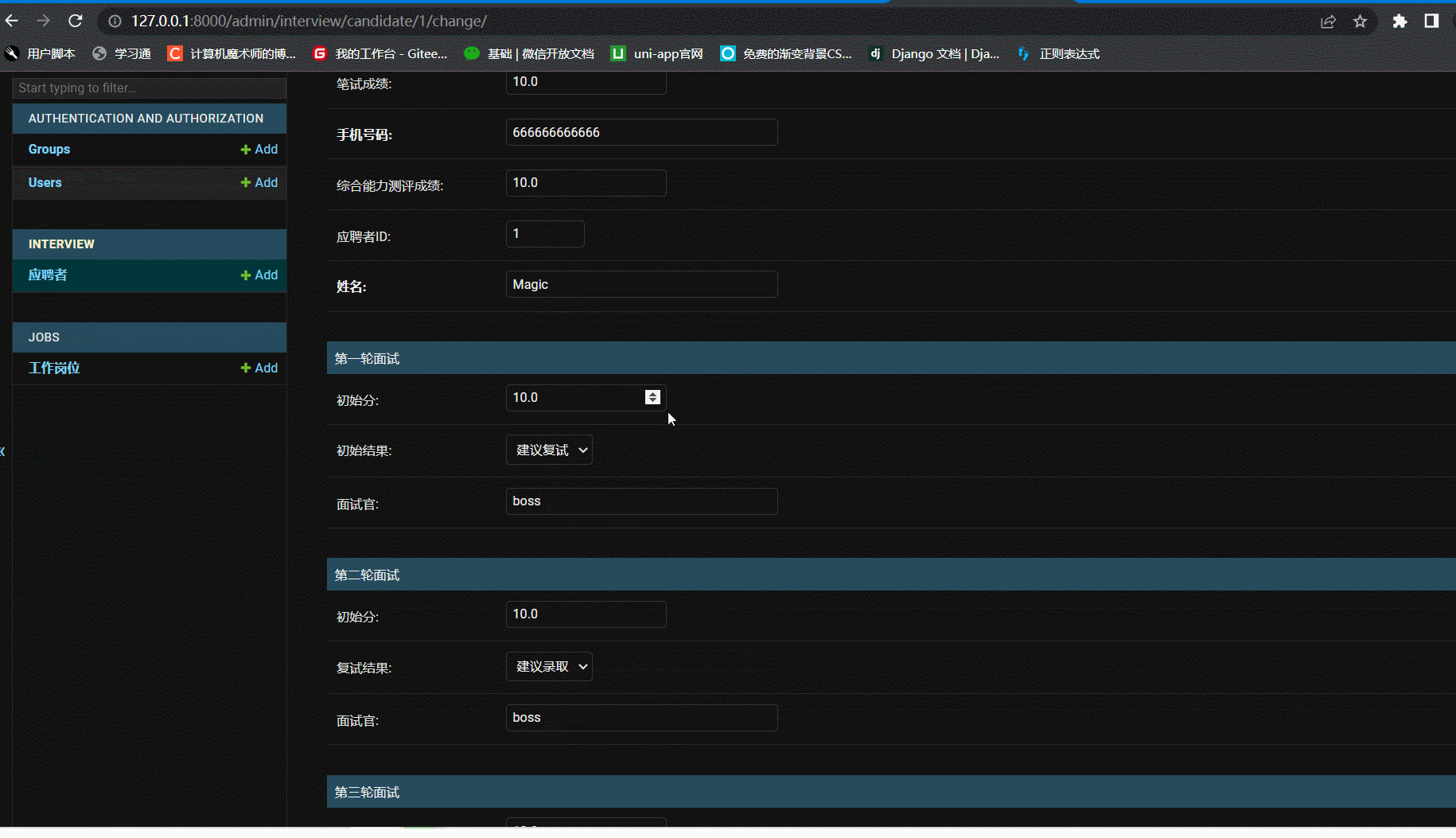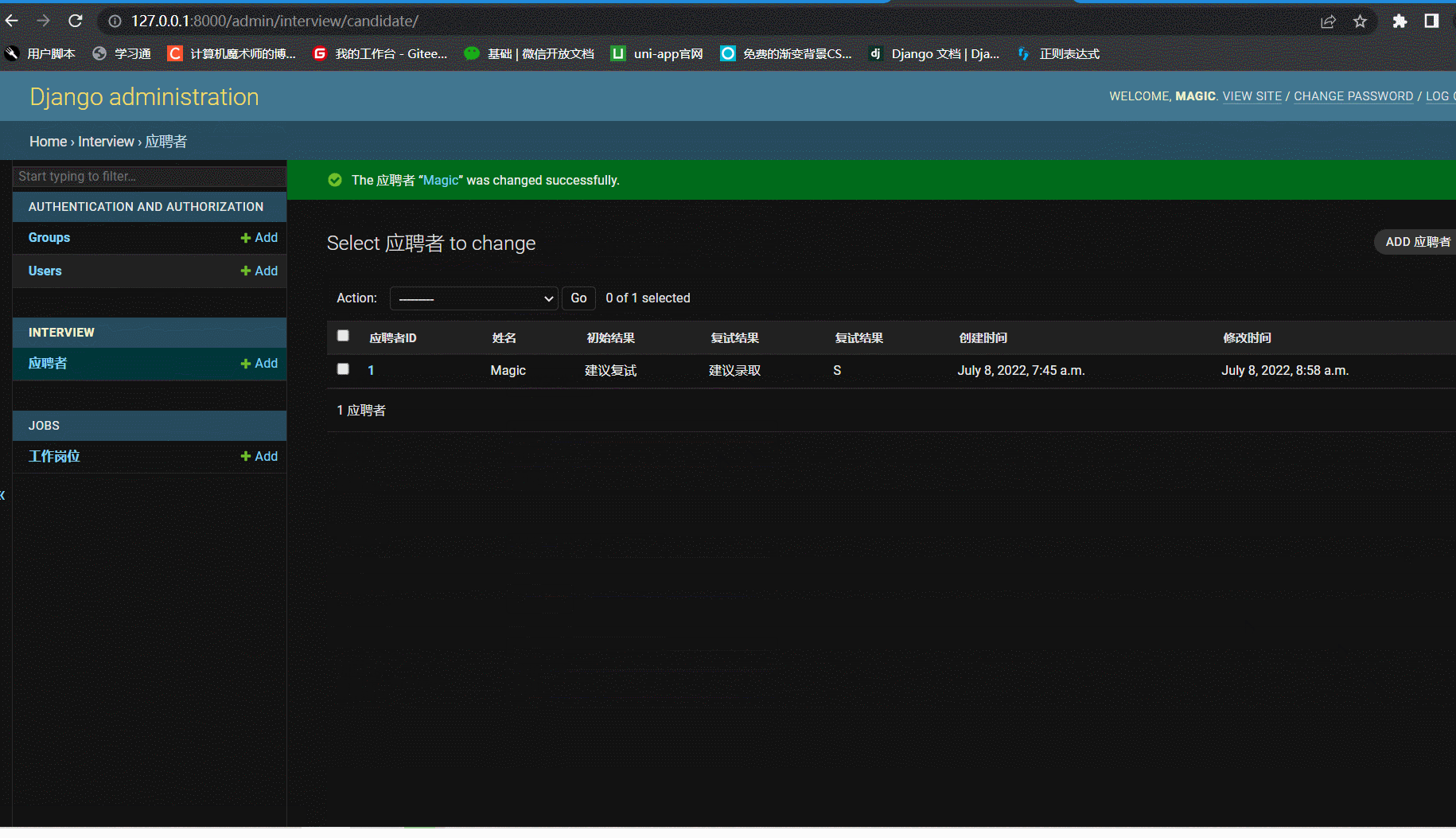
class CandidateAdmin(admin.ModelAdmin):
list_display = ('user_id', 'user_name', 'phone', 'city')
- 三板斧运行服务器
六、优化admin
6.1 分组填写
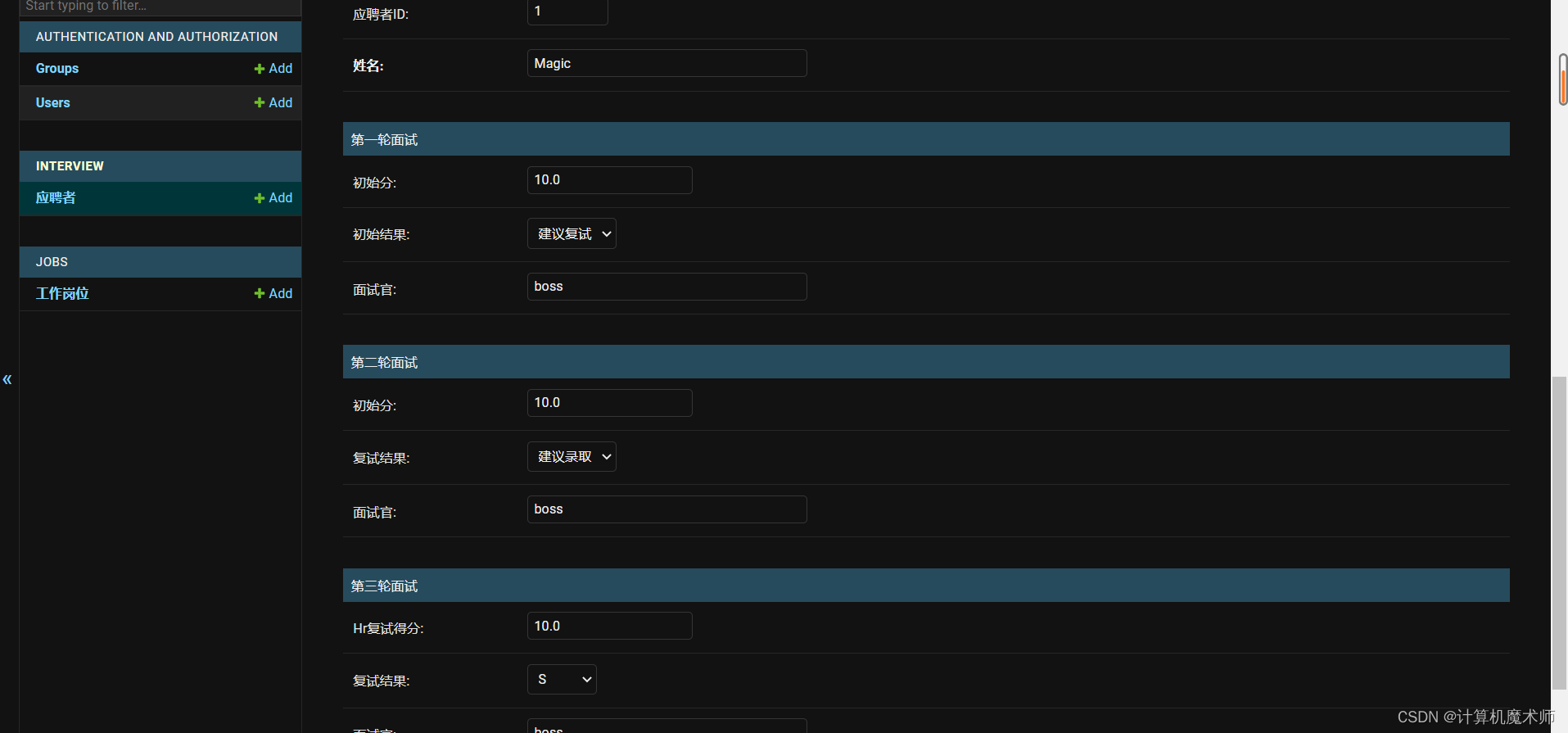
- 很显然,表的结构太复杂,因为字段太多,所以我们需要优化admin,实现分组填写
from django.contrib import admin
from interview.models import Candidate
# Register your models here.
@admin.register(Candidate)
class CandidateAdmin(admin.ModelAdmin):
list_display = ('user_id', 'user_name', 'first_result', 'second_result', 'hr_result', 'create_time', 'modify_time')
# 定义集合的字段列表
fieldsets = (
# 第一个元素表示分组展现的名字,第二元素是一个map
(None, {'fields': (
"apply_position", "bachelor_school", "born_address", "candidate_remark", "city", "degree",
"doctor_school", "email", "gender", "major", "master_school", "page_score", "phone",
"test_score_of_general_ability", "user_id", "user_name",
)}),
('第一轮面试', {'fields': ("first_score", "first_result", "second_interviewer",
)}),
('第二轮面试', {'fields': ("second_score", "second_result", "first_interviewer",
)}),
('第三轮面试', {'fields': ("hr_score", "hr_result", "hr_interviewer",
)})
)
- 分组实现成功
6.2 将类别一样的信息放在同一行
from django.contrib import admin
from interview.models import Candidate
# Register your models here.
@admin.register(Candidate)
class CandidateAdmin(admin.ModelAdmin):
list_display = ('user_id', 'user_name', 'first_result', 'second_result', 'hr_result', 'create_time', 'modify_time')
# 定义集合的字段列表
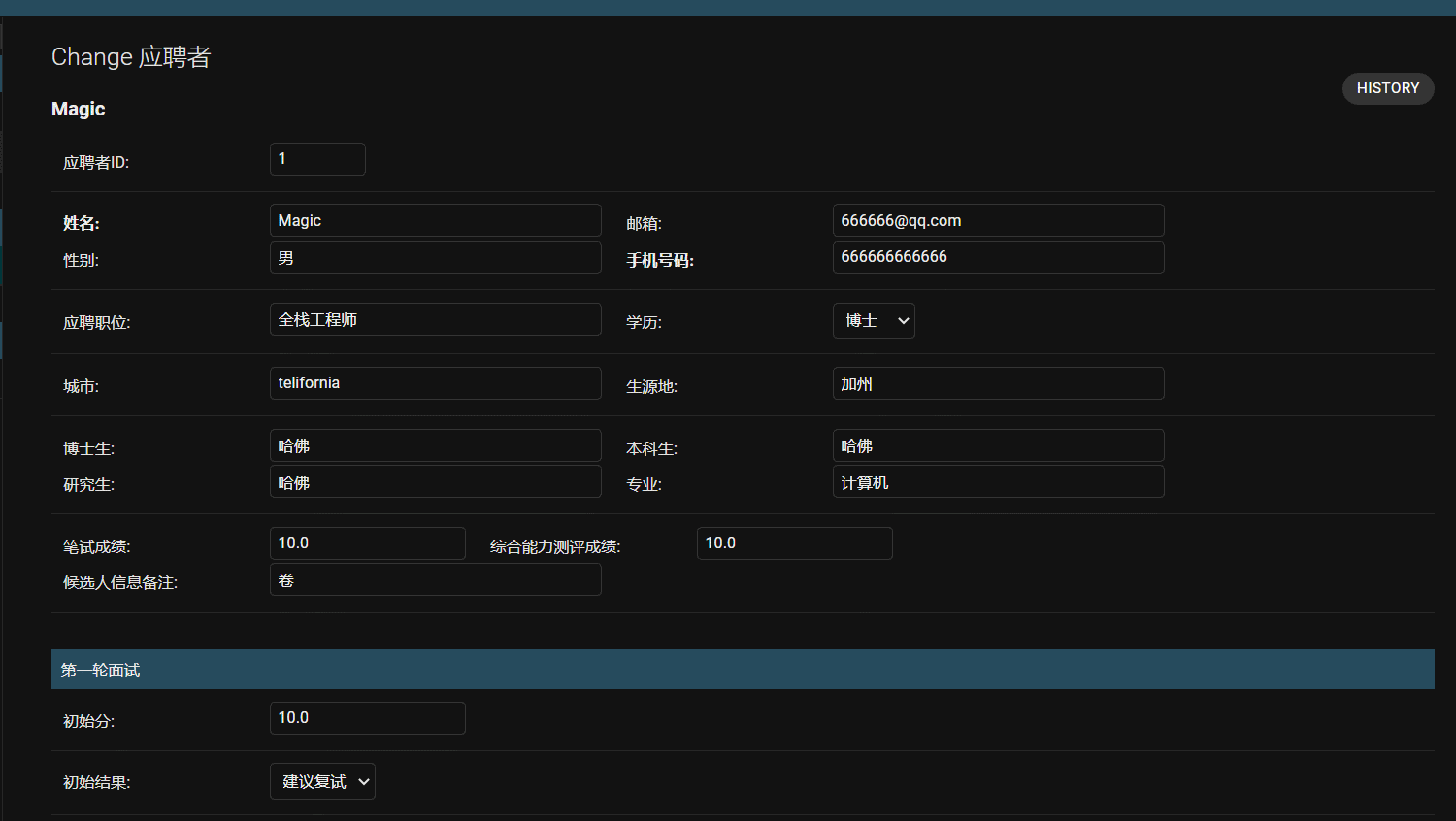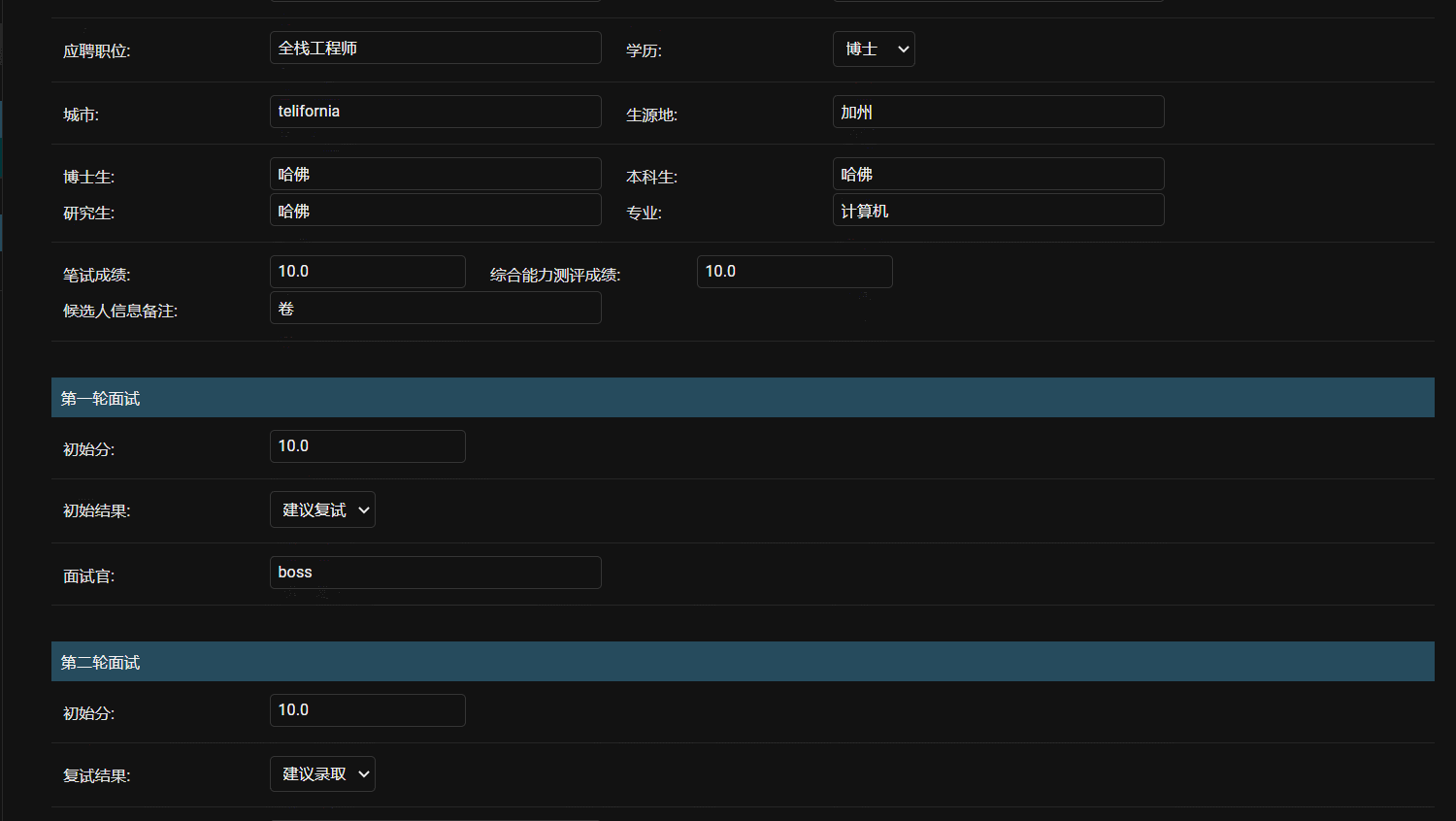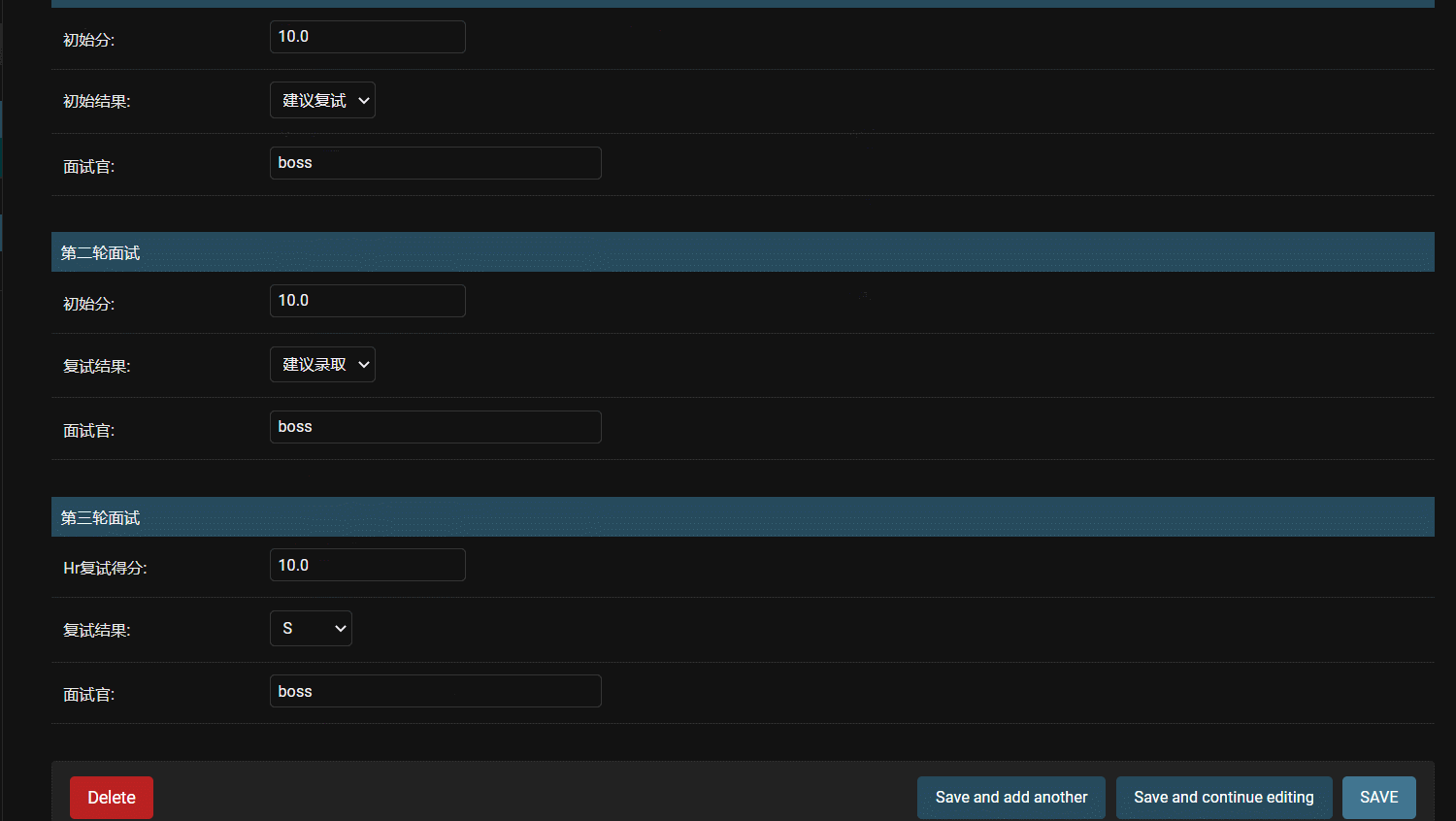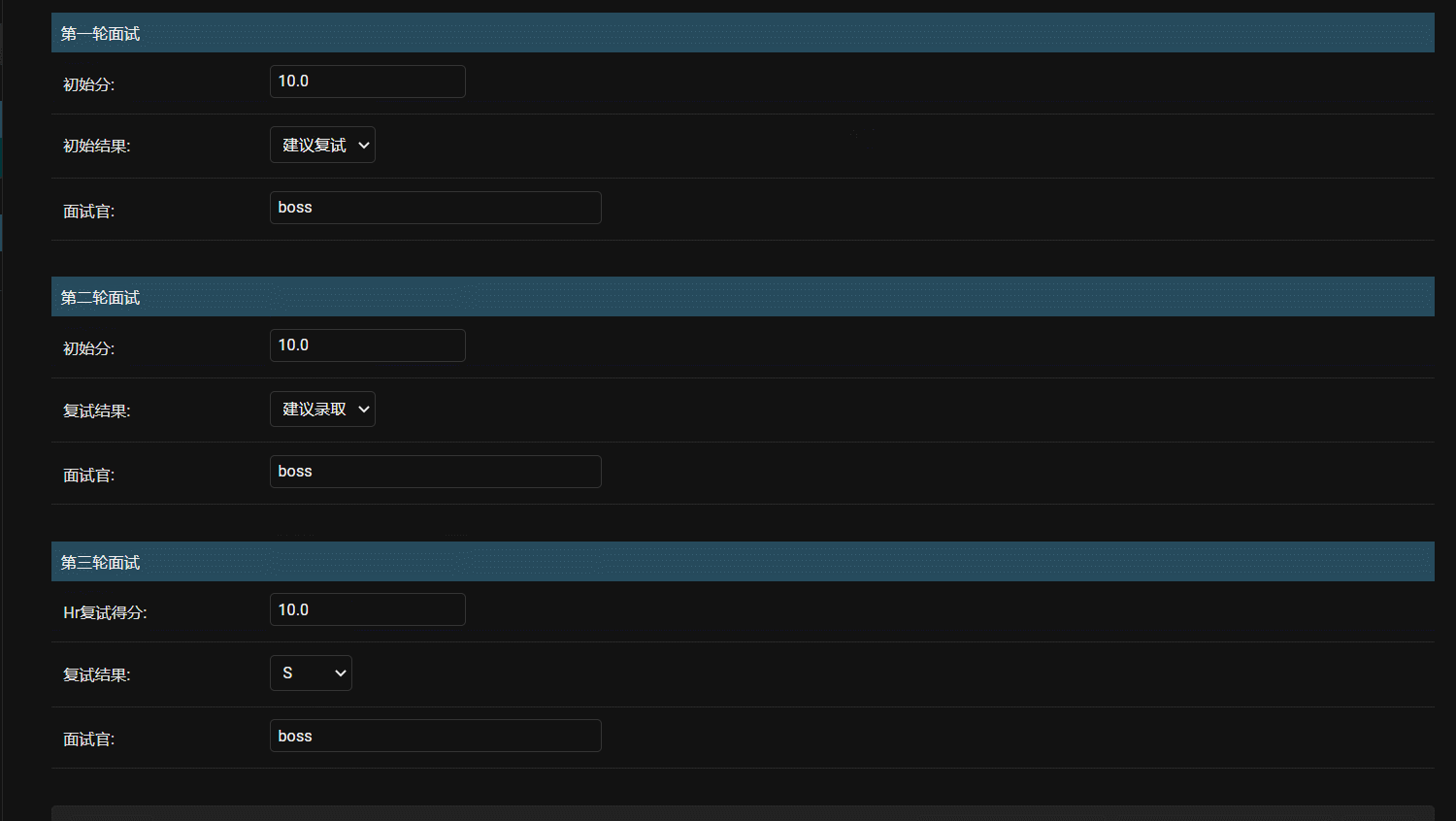
fieldsets = (
# 第一个元素表示分组展现的名字,第二元素是一个map
(None, {'fields': ("user_id", ("user_name", "email", "gender", "phone",),
("apply_position", "degree"),
("city", "born_address"),
("doctor_school", "bachelor_school", "master_school", "major",), ("page_score",
"test_score_of_general_ability",
"candidate_remark",),
)}),
('第一轮面试', {'fields': ("first_score", "first_result", "second_interviewer",
)}),
('第二轮面试', {'fields': ("second_score", "second_result", "first_interviewer",
)}),
('第三轮面试', {'fields': ("hr_score", "hr_result", "hr_interviewer",
)})
)
- 效果
如果对django model,admin有更多用法,可以去官方看看
https://docs.djangoproject.com/en/3.2/ref/models/querysets/#only
参考文献:
Django中max_length限制长度注意事项
auto_now & auto_now_add
函数引用和调用
Python中文编码问题(字符串前面加’u’)
网络编码那些事
Django model 字段类型——models.DecimalField
✨谢谢你的阅读,你的点赞和收藏是我创作的最大动力✨

- 点赞
- 收藏
- 关注作者
评论(0)