金鱼哥RHCA回忆录:DO280安装和配置Metric系统

🎹 个人简介:大家好,我是 金鱼哥,CSDN运维领域新星创作者,华为云·云享专家,阿里云社区·专家博主
📚个人资质:CCNA、HCNP、CSNA(网络分析师),软考初级、中级网络工程师、RHCSA、RHCE、RHCA、RHCI、ITIL😜
💬格言:努力不一定成功,但要想成功就必须努力🔥🎈支持我:可点赞👍、可收藏⭐️、可留言📝
📜METRICS子系统组件
📑metric架构介绍
OpenShift metric子系统支持捕获和长期存储OpenShift集群的性能度量,收集节点以及节点中运行的所有容器的指标。

metric子系统被由以下开源项目的容器组件构成:
Heapster
从Kubernetes集群中的所有节点收集指标,并将其转发给存储引擎进行长期存储。OCP使用Hawkular作为Heapster的存储引擎。
Heapster项目是由Kubernetes社区孵化的,目的是为第三方应用程序提供一种从Kubernetes集群捕获性能数据的方法。
Hawkular Metrics
提供用于存储和查询时间序列数据的REST API。Hawkular Metrics组件是更大的Hawkular项目的一部分。Hawkular Metrics使用Cassandra作为其数据存储。
Hawkular是作为RHQ项目(Red Hat JBoss Operations Network product)的继承者创建的,是Red Hat CloudForms产品中间件管理功能的一个关键部分。
Hawkular Agent
从应用程序收集自定义性能指标,并将其转发到Hawkular Metrics进行存储。应用程序为Hawkular agent提供度量标准。
Hawkular OpenShift Agent (HOSA)目前是一个技术预览功能,默认情况下没有安装,Red Hat不支持技术预览功能,也不建议将其用于生产。
Cassandra
将时间序列数据存储在非关系分布式数据库中。
OpenShift Metrics子系统独立于其他OpenShift组件工作。OpenShift只有三个部分需要metrics子系统来提供一些可选特性:
- web控制台调用Hawkular Metrics API来获取数据,以呈现项目中pod的性能图形。如果没有部署度量子系统,则不显示图表。
注意,这些调用是从用户web浏览器发出的,而不是从OpenShift主节点发出的。
- oc adm top命令使用Heapster API来获取关于集群中所有pod和节点的当前状态的数据。
- Kubernetes的autoscaler控制器调用Heapster API来从部署中获取关于所有pod当前状态的数据,以便决定如何伸缩部署控制器。
OCP并不强制一定部署完整的度量子系统,如果已经有一个监视系统,并且希望使用它来管理OpenShift集群,那么可以选择只部署Heapster组件,并将度量的长期存储委托给外部监视系统。
如果现有的监视系统只提供警报和健康功能,那么监视系统可以使用Hawkular API捕获指标来生成警报。
Heapster收集节点及其容器的指标,然后聚合pod、namespace和整个集群的指标。
Heapster为一个节点收集的指标包括:
-
working set:节点中运行的所有进程有效使用的内存,以bytes为单位度量。
-
CPU usage:节点中运行的所有进程使用的CPU数量,以millicores单位度量,十个millicores相当于一个CPU繁忙时间的1%。
Heapster还支持对内存中保留的指标进行简单查询,这些查询允许获取在特定时间范围内收集和聚合的度量。
📑访问Heapster和Hawkular
OpenShift用户需要区分声明的资源请求(和限制)与实际的资源使用情况。pod声明的资源请求用于调度,声明的资源请求从节点容量中减去,其差值是节点的剩余可用容量。
节点的可用容量不反映在节点内运行的容器和其他应用程序使用的实际内存和CPU。
oc describe node命令,在OCP 3.9中,只显示与pods声明的资源请求相关的信息。如果pod没有声明任何资源请求,则不会考虑pod的实际资源使用情况,节点的可用容量可能看起来比实际容量大。
web控制台显示的信息与oc describe node命令相同,还可以显示Hawkular Metrics的实际资源使用情况。但是,OCP 3.9的web控制台只显示pod和项目的指标,web控制台不显示节点指标。
要获得节点的实际资源使用情况,并确定节点是否接近其全部硬件或虚拟容量,系统管理员需要使用oc adm top命令。如果需要更详细的信息,系统管理员可以使用标准的Linux命令,比如vmstat和ps。
OpenShift不向集群外部公开Heapster组件。外部应用程序需要访问Heapster必须使用OpenShift master API代理。master API代理确保对内部组件API的访问遵从OpenShift集群身份验证和访问控制策略。
将Hawkular暴露给外部访问涉及到一些安全方面的考虑。如果系统管理员认为使用Heapster和Hawkular api过于复杂,那么Origin和Kubernetes开源项目的上游社区还提供了与Nagios和Zabbix等流行的开源监控工具的集成,或者当前最火热的Prometheus。
📑Metrics subsystem大小
OpenShift度量子系统的每个组件都使用自己的dc进行部署,并且独立于其他组件进行伸缩。它们可以计划在OpenShift集群的任何地方运行,但是建议为生产环境中的metrics子系统pod特定保留一些node。
Cassandra和Hawkular是Java应用程序。Hawkular运行在JBoss EAP 7应用服务器中。Hawkular和Cassandra都利用了大规模的优势,默认值是为中小型OpenShift集群设置的大小。测试环境可能需要更改默认值,以减少内存和CPU资源。
Heapster和Hawkular部署使用标准的OpenShift工具部署size、比例和调度。少量Heapster和Hawkular pods可以管理数百个OpenShift节点和数千个项目的指标。
可以使用oc命令配置Heapster和Hawkular部署。例如增加每个pod请求的副本数量或资源数量,但是推荐的配置参数的方法是修改为安装Metrics的Ansible剧本中的变量。
Cassandra不能使用标准oc命令进行伸缩和配置,因为Cassandra(大多数数据库都是这样)不是无状态云应用程序。Cassandra有严格的存储要求,每个Cassandra pod都有不同的部署配置。必须使用Metrics安装playbook来伸缩和配置Cassandra部署。
📑CASSANDRA配置持久存储
Cassandra可以部署为单个pod,使用一个持久卷。但至少需要三个Cassandra pod才能为度量子系统实现高可用性(HA)。每个pod都需要一个独占卷:Cassandra使用“无共享”存储架构。
尽管Cassandra可以使用enptyDir存储进行部署,但这意味着存在永久数据丢失的风险。通常生产环境不推荐使用临时存储(即emptyDir卷类型)。
每个Cassandra卷使用的存储量不仅取决于预期的集群大小(节点和pod的数量),还取决于度量的时间序列的粒度和持续时间。
Metrics安装剧本支持使用静态供应的持久卷或动态卷。无论选择哪种方法,playbook都基于前缀创建持久卷声明,前缀后面附加一个序列号。对于静态供应的持久卷,请确保使用相同的命名约定。
📜METRICS子系统
📑部署metrics子系统
OpenShift Metrics子系统由Ansible playbook部署,可以选择使用基本playbook或单独用于Metrics的playbook进行部署。
大多数Metrics子系统配置是使用用于高级安装方法的Inventory文件中的Ansible变量执行的。尽管可以使用-e选项覆盖或自定义某些变量的值,更建议在Inventory中定义metrics变量。如果需要更改度量Metrics配置,可更新Inventory中的变量并重新运行安装剧本。
metrics子系统在许多生产环境中不需要认定配置,可直接通过运行metrics安装剧本使用默认设置安装。
示例:Ansible结合主配置文件和Metrics子系统playbook安装。
Ansible主配置文件如下:
[defaults]
remote_user = student
inventory = ./inventory
log_path = ./ansible.log
[privilege_escalation]
become = yes
become_user = root
become_method = sudo
Metrics子系统剧本:
# ansible-playbook \
/usr/share/ansible/openshift-ansible/playbooks/openshift-metrics/config.yml \
-e openshift_metrics_install_metrics=True
提示:OpenShift metrics剧本由openshift-ansibl-playbooks包提供,该包是作为atomic-openshift-utils包的依赖项安装的。
openshift_metrics_install_metrics Ansible变量配置剧本用来部署metrics子系统,playbook为metrics子系统创建dc、service和其他支撑metrics的Kubernetes资源,还可以在用于部署集群的Inventory文件中定义该变量。
metrics子系统安装playbook会在openshift-infra项目中创建所需Kubernetes资源。安装playbook不配置任何节点选择器来限制pod所运行的node。
📑卸载metrics子系统
卸载OpenShift metrics子系统的一种方法是手动删除OpenShift-infra项目中的所有Kubernetes资源。通常需要多个oc命令,且容易出错,因为其他OpenShift子系统也被部署到这个项目。
卸载metrics子系统的推荐方法是运行安装剧本,但是将openshift_metrics_install_metrics Ansible变量设置为False,如下面的示例所示,-e选项覆盖库存文件中定义的值。
# ansible-playbook \
/usr/share/ansible/openshift-ansible/playbooks/openshift-metrics/config.yml \
-e openshift_metrics_install_metrics=False
📑验证metrics子系统
OpenShift metrics子系统playbook完成后,应该创建所有Cassandra、Hawkular和Heapster pod,并可能需要一些时间进行初始化。可能由于Cassandra pod初始化时间过长,会重新启动Hawkular和Heapster pod。
除非另外配置,否则安装程序剧本应该为每个组件创建一个dc,其中包含一个pod,并且openshift-infra项目的oc get pod能显示相应pod。
📑部署metrics子系统常见错误
造成部署错误的常见原因通常有:
- image缺失;
- metrics所需资源过高,节点无法满足;
- Cassandra pod所需的持久卷无法满足。
📑其他配置
在所有pod准备好并运行之后,需要执行一个特定配置以便于和web对接。如果跳过此步骤,OpenShift web控制台将无法显示项目的metrics图形,尽管底层metrics子系统正在正常工作。
OpenShift web控制台是一个JavaScript应用程序,它直接访问Hawkular API,而不需要经过OpenShift master service。
但由于内部使用TLS访问API,默认情况下,TLS证书不是由受信任的认证机构签署的。因此web浏览器拒绝连接到Hawkular API endpoint。
在OpenShift安装之后,web控制台本身也会出现类似证书不信任的问题。与metrics同样的方式解决,配置浏览器接受TLS证书。为此,在web浏览器中打开Hawkular API欢迎页面,并接受不受信任的TLS证书。
https://hawkular-metrics.<master-wildcard-domain>
主通配符域DNS后缀应该与OpenShift主服务中配置的后缀相同,并用作新路由的默认域。
playbook从Ansible hosts文件中获取主通配符域值,由openshift_master_default_subdomain变量定义。如果更改了OpenShift master service配置,则它们将不匹配。在本例中,为metrics剧本中的openshift_metrics_hawkular_hostname变量提供新值。
📑metrics涉及变量
OCP安装和配置文档提供了metrics安装剧本使用的所有可能变量的列表,它们控制着各种配置参数。常见有:
每个组件的pod比例:
- openshift_metrics_cassandra_replicas
- openshift_metrics_hawkular_replicas
每个组件对pod的资源请求和限制:
- openshift_metrics_cassandra_requests_memory
- openshift_metrics_cassandra_limits_memory
- openshift_metrics_cassandra_requests_cpu
- openshift_metrics_cassandra_limits_cpu
对于Hawkular和Heapster,有类似配置:
- openshift_metrics_hawkular_requests_memory
- openshift_metrics_heapster_requests_memory
用于duration和resolution参数:
- openshift_metrics_duration
- openshift_metrics_resolution
Cassandra pods的持久卷声明属性:
- openshift_metrics_cassandra_storage_type
- openshift_metrics_cassandra_pvc_prefix
- openshift_metrics_cassandra_pvc_size
用于pull metrics子系统容器image的仓库:
- openshift_metrics_image_prefix
- openshift_metrics_image_version
其他配置参考:
- openshift_metrics_heapster_standalone
- openshift_metrics_hawkular_hostname
示例1:使用自定义配置安装metrics子系统,用于覆盖Inventory中定义的Cassandra配置。
[OSEv3:vars]
...output omitted...
openshift_metrics_cassandra_replicas=2
openshift_metrics_cassandra_requests_memory=2Gi
openshift_metrics_cassandra_pvc_size=50Gi
示例2:使用自定义配置,用于覆盖Cassandra定义的属性。
# ansible-playbook \
/usr/share/ansible/openshift-ansible/playbooks/openshift-metrics/config.yml \
-e openshift_metrics_cassandra_replicas=3 \
-e openshift_metrics_cassandra_requests_memory=4Gi \
-e openshift_metrics_cassandra_pvc_size=25Gi
提示:大多数配置参数都可以使用OpenShift oc命令进行更改,但是推荐的方法是使用更新Inventory中变量值运行metrics安装剧本进行修改。
📜课本练习
📑环境准备
[student@workstation ~]$ lab install-prepare setup
[student@workstation ~]$ cd /home/student/do280-ansible
[student@workstation do280-ansible]$ ./install.sh
提示:若已经拥有一个完整环境,可不执行。
📑本练习准备
[student@workstation ~]$ lab install-metrics setup
📑验证image
[student@workstation ~]$ docker-registry-cli registry.lab.example.com \
search metrics-cassandra ssl
[student@workstation ~]$ docker-registry-cli registry.lab.example.com \
search ose-recycler ssl
📑验证NFS
[root@services ~]# ls -alZ /exports/metrics/
drwxrwxrwx. nfsnobody nfsnobody unconfined_u:object_r:default_t:s0 .
drwxr-xr-x. root root unconfined_u:object_r:default_t:s0 ..
[root@services ~]# cat /etc/exports.d/openshift-ansible.exports
"/exports/registry" *(rw,root_squash)
"/exports/metrics" *(rw,root_squash)
"/exports/logging-es" *(rw,root_squash)
"/exports/logging-es-ops" *(rw,root_squash)
"/exports/etcd-vol2" *(rw,root_squash,sync,no_wdelay)
"/exports/prometheus" *(rw,root_squash)
"/exports/prometheus-alertmanager" *(rw,root_squash)
"/exports/prometheus-alertbuffer" *(rw,root_squash)
📑创建PV
[student@workstation ~]$ cat /home/student/DO280/labs/install-metrics/metrics-pv.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: metrics
spec:
capacity:
storage: 5Gi #定义capacity.storage容量为5G
accessModes:
- ReadWriteOnce #定义访问模式
nfs:
path: /exports/metrics #定义nfs.path
server: services.lab.example.com #定义nfs.services
persistentVolumeReclaimPolicy: Recycl #定义回收策略
[student@workstation ~]$ oc login -u admin -p redhat https://master.lab.example.com
Login successful.
[student@workstation ~]$ oc create -f /home/student/DO280/labs/install-metrics/metrics-pv.yml
persistentvolume "metrics" created
[student@workstation ~]$ oc get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
etcd-vol2-volume 1G RWO Retain Bound openshift-ansible-service-broker/etcd 18d
metrics 5Gi RWO Recycle Available 12s
registry-volume 40Gi RWX Retain Bound default/registry-claim
📑规划安装变量
[student@workstation ~]$ cd DO280/labs/install-metrics/
[student@workstation install-metrics]$ ll
total 32
-rw-r--r--. 1 student student 159 Aug 17 2018 ansible.cfg
-rwxr-xr-x. 1 student student 803 Aug 17 2018 install-metrics.sh
-rw-r--r--. 1 student student 2952 Aug 14 2018 inventory
-rw-r--r--. 1 student student 244 Aug 17 2018 metrics-pv.yml
-rw-r--r--. 1 student student 494 Aug 14 2018 metrics-vars.txt
-rwxr-xr-x. 1 student student 511 Aug 14 2018 node-metrics.sh
-rwxr-xr-x. 1 student student 587 Aug 14 2018 project-metrics.sh
-rwxr-xr-x. 1 student student 378 Aug 17 2018 uninstall-metrics.sh
[student@workstation install-metrics]$ cat metrics-vars.txt
# Metrics Variables
# Append the variables to the [OSEv3:vars] group
openshift_metrics_install_metrics=True
openshift_metrics_image_prefix=registry.lab.example.com/openshift3/ose-
openshift_metrics_image_version=v3.9
openshift_metrics_heapster_requests_memory=300M
openshift_metrics_hawkular_requests_memory=750M
openshift_metrics_cassandra_requests_memory=750M
openshift_metrics_cassandra_storage_type=pv
openshift_metrics_cassandra_pvc_size=5Gi
openshift_metrics_cassandra_pvc_prefix=metrics
openshift_metrics_image_prefix:指向服务VM上的私有仓库,并添加openshift3/ose-作为映像名称前缀。
openshift_metrics_image_version:要使用的容器image标记,私有仓库为image添加一个v3.9标记。
openshift_metrics_heapster_requests_memory:本环境配置300mb内存。
openshift_metrics_hawkular_requests_memory:本环境配置750mb内存。
openshift_metrics_cassandra_requests_memory:本环境配置750mb内存。
openshift_metrics_cassandra_storage_type:使用pv选择一个持久卷作为存储类型。
openshift_metrics_cassandra_pvc_size:本环境配置5gib容量。
openshift_metrics_cassandra_pvc_prefix:使用metrics作为pvc名称的前缀.
提示:生产环境中建议根据实际规划进行配置,可适当调大配置规格。
📑配置安装变量
[student@workstation install-metrics]$ cat metrics-vars.txt
[student@workstation install-metrics]$ cat metrics-vars.txt >> inventory
[student@workstation install-metrics]$ lab install-metrics grade #本环境使用脚本判断配置
📑执行安装
[student@workstation install-metrics]$ ansible-playbook /usr/share/ansible/openshift-ansible/playbooks/openshift-metrics/config.yml
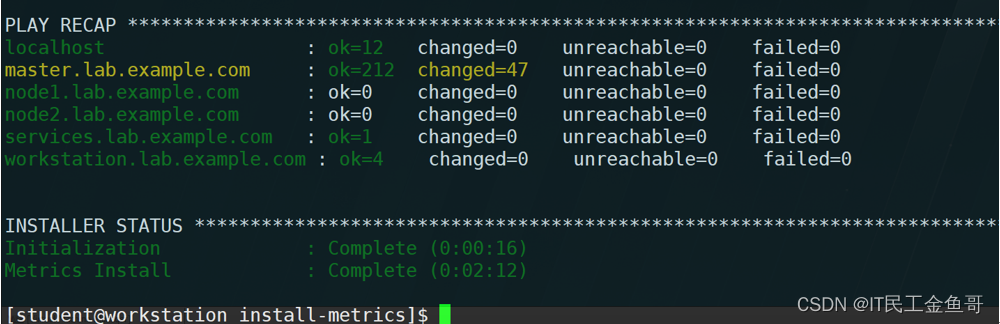
📑验证安装
[student@workstation install-metrics]$ oc get pvc -n openshift-infra #验证持久卷是否成功挂载
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
metrics-1 Bound metrics 5Gi RWO 2m
[student@workstation install-metrics]$ oc get pod -n openshift-infra #验证metric相关pod
NAME READY STATUS RESTARTS AGE
hawkular-cassandra-1-8bclg 1/1 Running 0 7m
hawkular-metrics-srh26 1/1 Running 0 7m
heapster-h5tnt 1/1 Running 0 7m
[student@workstation install-metrics]$ oc get route -n openshift-infra #查看metric route地址
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
hawkular-metrics hawkular-metrics.apps.lab.example.com hawkular-metrics <all> reencrypt None
浏览器访问:
https://hawkular-metrics.apps.lab.example.com
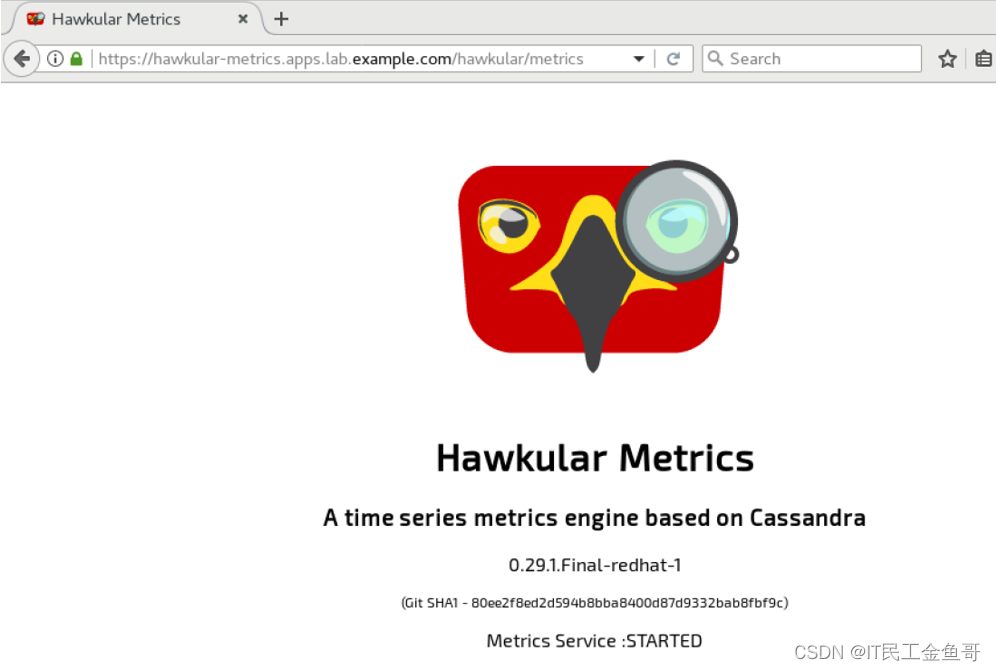
提示:浏览器信任SSL证书。
📑部署测试应用
[student@workstation ~]$ oc login -u developer -p redhat https://master.lab.example.com
[student@workstation ~]$ oc new-project load #创建project
[student@workstation ~]$ oc new-app --name=hello \
--docker-image=registry.lab.example.com/openshift/hello-openshift #部署应用
[student@workstation ~]$ oc scale --replicas=9 dc/hello #扩展应用
[student@workstation ~]$ oc get pod -o wide #查看pod
[student@workstation ~]$ oc get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
hello-1-b6vhk 1/1 Running 0 4s 10.128.0.224 node1.lab.example.com
hello-1-gs8wm 1/1 Running 0 3s 10.128.0.225 node1.lab.example.com
hello-1-h9bfc 1/1 Running 0 3s 10.128.0.226 node1.lab.example.com
hello-1-hx2mz 1/1 Running 0 1m 10.129.1.35 node2.lab.example.com
hello-1-kgfwh 1/1 Running 0 3s 10.129.1.39 node2.lab.example.com
hello-1-p4ql4 1/1 Running 0 3s 10.129.1.38 node2.lab.example.com
hello-1-q7h9s 1/1 Running 0 3s 10.128.0.223 node1.lab.example.com
hello-1-tp5w8 1/1 Running 0 3s 10.129.1.37 node2.lab.example.com
hello-1-v6k6t 1/1 Running 0 3s 10.129.1.36 node2.lab.example.com
[student@workstation ~]$ oc expose svc hello
📑压力测试
[student@workstation ~]$ sudo yum -y install httpd-tools
[student@workstation ~]$ ab -n 300000 -c 20 http://hello-load.apps.lab.example.com/
📑查看资源使用情况
[student@workstation ~]$ oc login -u admin -p redhat
[student@workstation ~]$ oc adm top node \
--heapster-namespace=openshift-infra \
--heapster-scheme=https
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master.lab.example.com 249m 12% 1382Mi 79%
node1.lab.example.com 111m 5% 461Mi 5%
node2.lab.example.com 411m 20% 3024Mi 39%
提示:保持3.11的压测程序,重开终端进行查看。
[student@workstation ~]$ oc adm top node --heapster-namespace=openshift-infra --heapster-scheme=https
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master.lab.example.com 246m 12% 1372Mi 78%
node1.lab.example.com 1051m 52% 477Mi 6%
node2.lab.example.com 925m 46% 3043Mi 39%
📑获取指标
[student@workstation ~]$ cat ~/DO280/labs/install-metrics/node-metrics.sh #使用此脚本获取指标
#!/bin/bash
oc login -u admin -p redhat >/dev/null
TOKEN=$(oc whoami -t)
APIPROXY=https://master.lab.example.com:/api/v1/proxy/namespaces/openshift-infra/services
HEAPSTER=https:heapster:/api/v1/model
NODE=nodes/node1.lab.example.com
START=$(date -d '1 minute ago' -u '+%FT%TZ')
curl -kH "Authorization: Bearer $TOKEN" \
-X GET $APIPROXY/$HEAPSTER/$NODE/metrics/memory/working_set?start=$START
curl -kH "Authorization: Bearer $TOKEN" \
-X GET $APIPROXY/$HEAPSTER/$NODE/metrics/cpu/usage_rate?start=$START
[student@workstation ~]$ ./DO280/labs/install-metrics/node-metrics.sh
{
"metrics": [
{
"timestamp": "2021-03-16T09:46:30Z",
"value": 504520704
},
{
"timestamp": "2021-03-16T09:47:00Z",
"value": 509423616
}
],
"latestTimestamp": "2021-03-16T09:47:00Z"
}{
"metrics": [
{
"timestamp": "2021-03-16T09:46:30Z",
"value": 836
},
{
"timestamp": "2021-03-16T09:47:00Z",
"value": 1324
}
],
"latestTimestamp": "2021-03-16T09:47:00Z"
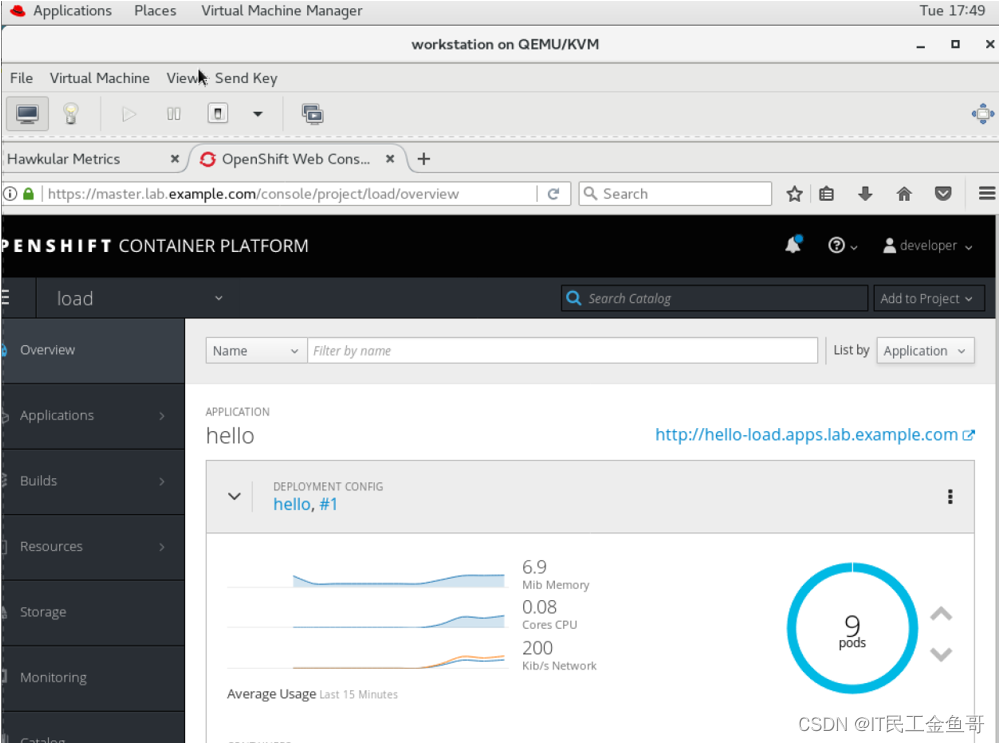
浏览器访问:https://master.lab.example.com
查看相关性能监控
📑清除项目
[student@workstation ~]$ oc delete project load
project "load" deleted
💡总结
RHCA认证需要经历5门的学习与考试,还是需要花不少时间去学习与备考的,好好加油,可以噶🤪。

以上就是【金鱼哥】对 第八章 安装和配置Metric系统 的简述和讲解。希望能对看到此文章的小伙伴有所帮助。
💾红帽认证专栏系列:
RHCSA专栏:戏说 RHCSA 认证
RHCE专栏:戏说 RHCE 认证
此文章收录在RHCA专栏:RHCA 回忆录
如果这篇【文章】有帮助到你,希望可以给【金鱼哥】点个赞👍,创作不易,相比官方的陈述,我更喜欢用【通俗易懂】的文笔去讲解每一个知识点。
如果有对【运维技术】感兴趣,也欢迎关注❤️❤️❤️ 【金鱼哥】❤️❤️❤️,我将会给你带来巨大的【收获与惊喜】💕💕!


- 点赞
- 收藏
- 关注作者
评论(0)