【RF分类】基于matlab随机森林算法数据分类【含Matlab源码 2048期】

一、随机森林算法预测简介
随机森林 (random forest) 是一种基于分类树 (classification tree) 的算法 (Breiman, 2001) 。这个算法需要模拟和迭代, 被归类为机器学习中的一种方法。经典的机器学习模型是神经网络 (Hopfield, 1982) , 有半个多世纪的历史了。神经网络预测精确, 但是计算量很大。20世纪80年代Breiman等人 (1984) 发明了分类和回归树 (Classification And Regression Tree, 简称CART) 的算法, 通过反复二分数据进行分类或回归, 计算量大大降低。
RF是由一系列树型分类器{h (x, Θ) }k, 其中k=1, …, 组合成的分类器, 其中Θk是独立同分布随机向量, 且每棵树对输入向量x所属的最受欢迎类投一票[6]。RF生成步骤如图1所示: (1) 从总训练样本集D中用Bootstrap采样选取k个子训练样本集D1, D2, …, Dk, 并预建k棵分类树; (2) 在分类树的每个节点上随机地从n个指标中选取m个, 选取最优分割指标进行分割; (3) 重复步骤 (2) 遍历预建的k棵分类树; (4) 由k棵分类树形成随机森林。
Bootstrap随机抽样得到输入训练集和节点随机选取指标进行分割, 使得RF对噪声有很好的容忍性, 且降低了分类树之间的相关性。单棵树不剪枝任意生长的特点可获得低偏差分类树, 且能够保证对新测试数据分类的正确率。
RF的生成和单棵风险分类树如图1和图2所示。
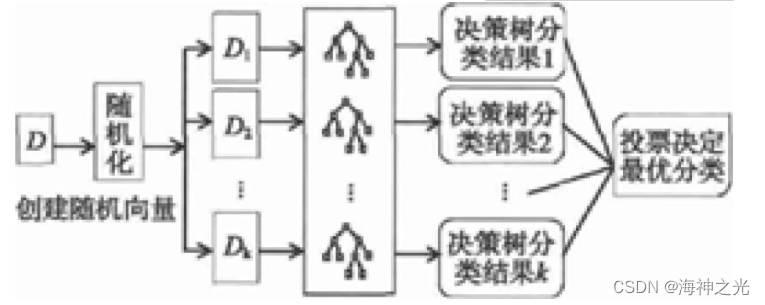
图1 RF生成步骤
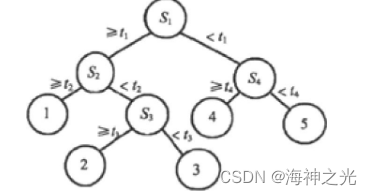
图2 单棵风险分类树
二、部分源代码
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 导入数据
res = xlsread(‘数据集.xlsx’);
%% 划分训练集和测试集
temp = randperm(357);
P_train = res(temp(1: 240), 1: 12)‘;
T_train = res(temp(1: 240), 13)’;
M = size(P_train, 2);
P_test = res(temp(241: end), 1: 12)‘;
T_test = res(temp(241: end), 13)’;
N = size(P_test, 2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax(‘apply’, P_test, ps_input );
t_train = T_train;
t_test = T_test ;
%% 转置以适应模型
p_train = p_train’; p_test = p_test’;
t_train = t_train’; t_test = t_test’;
%% 训练模型
trees = 50; % 决策树数目
leaf = 1; % 最小叶子数
OOBPrediction = ‘on’; % 打开误差图
OOBPredictorImportance = ‘on’; % 计算特征重要性
Method = ‘classification’; % 分类还是回归
net = TreeBagger(trees, p_train, t_train, ‘OOBPredictorImportance’, OOBPredictorImportance, …
‘Method’, Method, ‘OOBPrediction’, OOBPrediction, ‘minleaf’, leaf);
importance = net.OOBPermutedPredictorDeltaError; % 重要性
三、运行结果





四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1] 杨森彬.线性回归和随机森林算法融合在餐饮客流量的预测[J].软件工程. 2018,21(07)
3 备注
简介此部分摘自互联网,仅供参考,若侵权,联系删除
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/126512027

- 点赞
- 收藏
- 关注作者
评论(0)