Nat. Methods | scBasset:基于DNA序列的单细胞ATAC-seq卷积神经网络建模

本文介绍由美国生物科技公司Calico Life Sciences的Han Yuan 和 David R. Kelley共同通讯发表在 Nature methods 的研究成果:单细胞ATAC-seq(scATAC)在研究表观遗传景观中的细胞异质性方面具有巨大前景,但由于数据高维性和稀疏性的特点,scATAC的分析仍然面临重大挑战。为此,作者提出了一种基于DNA序列的卷积神经网络方法(scBasset)来对scATAC数据进行建模。实验表明,通过利用可及性峰值下的DNA序列信息和神经网络模型的表达能力,scBasset在scATAC和单细胞多组数据集的各种任务中展现了最先进的性能,包括细胞类型识别、scATAC去噪、数据集成和转录因子活性推断。

1.简介
scATAC可以在单细胞水平上揭示表观遗传景观。该技术已成功应用于识别细胞类型,揭示细胞异质性的调控机制,绘制与疾病相关的调控元件,以及重建分化轨迹。
然而,由于可及性峰值固有的高维性和每个细胞测序读长的稀疏性,使得scATAC数据分析仍面临重大挑战。已有的scATAC分析方法大致可以分为两类:不依赖DNA序列的方法和依赖DNA序列的方法。从聚合读长和可及性染色质中的峰值调用生成的稀疏peak-by-cell矩阵开始,大多数方法将这些带注释的峰值表示为基因组坐标并忽略了潜在的DNA序列。主成分分析(PCA)和潜在语义索引(LSI)对peak-by-cell矩阵进行线性变换,以将细胞投影到低维空间。SCALE和cisTopic使用潜在dirichlet分配或变分自动编码器对数据分布的生成过程进行建模。这些不依赖DNA序列的方法利用peak-by-cell矩阵中具有生物学意义的协方差来对细胞进行有效的表示。然而,它们忽略了DNA序列信息,并依赖于额外的工具才能建立染色质开放区域与转录因子(TF)之间的联系。另一方面,依赖DNA序列的方法(例如chromVAR和BROCKMAN)通过其TF基序或k-mer含量表示峰值,并将这些特征聚合到峰值或其他感兴趣区域以学习细胞表示。虽然chromVAR直接将峰值与TF相关联,具有更好的可解释性,但由于其模型相对简单,在学习细胞表示方面往往表现较差。
作者提出了一种基于深度卷积神经网络(CNN)的更具表达性的DNA序列模型。CNN模型可以比k-mer或TF基序模型更有效地预测来自大量染色质分析的峰值,例如DeepSEA和Basset。这些模型通过卷积层计算潜在峰值序列的显式嵌入,并在最终线性变换的参数中计算多个“任务”(即测序实验)的隐式嵌入。作者扩展了Basset架构,从DNA序列中预测单细胞染色质可及性,使用瓶颈层学习单细胞的低维表示。实验结果表明,通过在深度学习框架中利用DNA序列信息,scBasset在细胞表示学习、单细胞可及性去噪、scATAC与scRNA的整合以及转录因子活性推断方面优于最先进的方法。
2.结果
scBasset预测单细胞染色质在突出峰值上的可及性
scBasset是一种深度CNN模型,用于从DNA序列预测染色质可及性。CNN在预测bulk数据中的表观遗传图谱方面表现出了最先进的性能,并已成功用于遗传变异效应预测和TF语法推断。在这里,作者将将模型视为一个特征学习机器。scBasset模型通过一系列的卷基层学习到了一个低维的嵌入序列,模型的最后一层是一个将这个嵌入序列用于预测每个单细胞可及性的线性变换。这个线性变换矩阵包含每个细胞的向量表示,它指定如何利用每个嵌入序列来预测细胞特定的可及性。我们可以把向量的每个潜在特征理解为代表着基于DNA序列的各种调控因素,例如TF结合点位或核苷酸组成,而线性变换的权重决定了每个细胞在多大程度上依赖于这些因素。作者将这些单细胞向量作为用于下游任务(如可视化和聚类)的细胞表示。
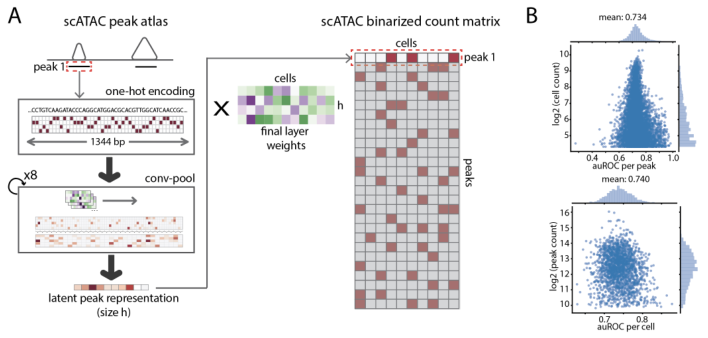 图1 scBasset架构
图1 scBasset架构
scBasset从每个峰的中心提取1344bp的DNA序列作为输入,通过one-hot将其编码为4×1344矩阵。输入的DNA序列经过八个卷积块,其中每个块由1D卷积、批量归一化、最大池化和GELU激活层组成。与以前的大多数架构不同,作者在这些架构之后创建了一个大小为h的瓶颈层,旨在通过层输出和下一层的参数来学习峰值的低维表示。最后,密集线性变换连接瓶颈序列嵌入以预测每个细胞中的二进制可及性(图1a)。作者应用标准的二元交叉熵损失函数,并使用随机梯度下降优化模型参数。
为了对scBasset进行基准测试,作者将scBasset应用于三个公共数据集:具有2k个细胞的scATAC-seq FACS分类的造血分化数据集(称为 Buenrostro2018),具有3k个细胞的10x Multiome RNA+ATAC PBMC数据集和包含5k个细胞的10x Multiome RNA+ATAC小鼠大脑数据集。
首先,作者研究了scBasset可以在多大程度上预测跨细胞的可及性,以确保模型使用稀疏噪声标签能够学习DNA序列和可及性之间有意义的关系。对于保留的峰值,作者计算了每个细胞峰值之间的接收器操作特征曲线下面积(auROC)。为了评估细胞类型特异性,作者还计算了每个峰值细胞间的auROC。实验结果表明,scBasset达到了很高的准确度水平,这表明模型学习的成功(图1b)。鉴于已知存在的可及性峰值,这些峰值很可能在所有细胞中都是可以真正访问的,并代表了可实现精度的粗略上限。
scBasset最后一层学习细胞表示
作者连接瓶颈层和预测的h×cell权重矩阵用作单个细胞的低维表示。有效细胞表示的一个要求是消除测序深度的影响。因此,作者首先验证了模型最后一层中的截距向量与所有数据集的细胞测序深度几乎完全相关,这表明测序深度已经从表示中标准化。接下来,作者将scBasset学习到的细胞表征与其他方法进行了定性和定量比较。对于Buenrostro2018数据集,作者使用t-SNE(图 2a)在2D中可视化细胞嵌入,并观察t-SNE空间中的分化轨迹。与其他流行的scATAC嵌入方法相比,chromVAR和PCA难以区分CLP和LMPP,而Cicero、SCALE、cisTopic和scBasset可以区分。作者还通过使用ARI指标将Louvain聚类结果与真实细胞类型标签进行比较,量化了细胞嵌入的正确性。根据该指标可以发现scBasset优于其他方法(图 2b,顶部)。由于ARI对Louvain算法中的超参数选择和随机性敏感,作者提出了一种评估细胞嵌入的替代方法。通过基于细胞嵌入构建最近邻图来计算“标签分数”,并分析每个细胞的邻居中有多少百分比共享相同的标签。对于每种嵌入方法,计算了一系列邻域的标签分数。实验表明,scBasset在学习细胞表示时始终优于其他方法,这些细胞相互嵌入了相同类型的其他细胞(图 2b,底部)。对于每种细胞类型的标签分数,作者进一步分析并观察到单核细胞学习得最好,而MPP细胞最难区分。
对于多组PBMC和小鼠大脑数据集,作者计算了模拟的细胞嵌入标签分数。由于多组数据集的真实细胞类型未知,作者使用来自scRNA-seq Leiden聚类的聚类标识符作为细胞类型标签。同样的,通过这一指标可知scBasset的表现优于其他方法。对于这些多组数据集,作者还计算了“邻居分数”,从scRNA和scATAC构建独立的最近邻图,并分析每个细胞的邻居在两个图之间共享的百分比。结果表明,scBasset在多组PBMC和多组小鼠大脑数据集上都优于其他方法(图2c,d)。
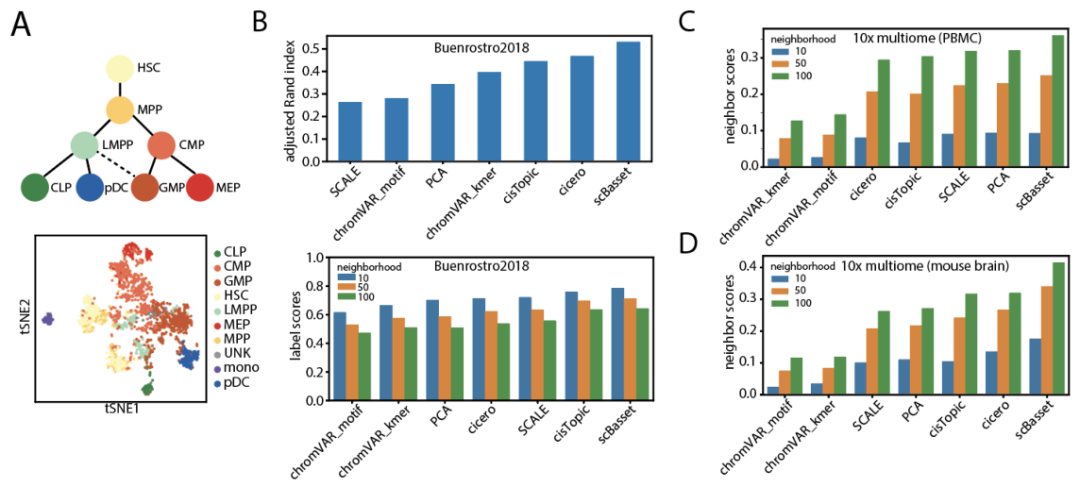 图2 scBasset在学习细胞表示时的性能
图2 scBasset在学习细胞表示时的性能
在批次条件下scBasset可消除批次效应
在Buenrostro2018数据集中,无论采用哪种细胞嵌入方法,HSC都聚集成两个群体。正如之前的研究中所指出的,这是由不同供体的批次效应引起的(图3 a)。为了解决这一问题,以及更普遍的批次效应,作者对scBasset架构进行了修改。
具体来说,在瓶颈层之后,作者添加了第二个全连接层来预测批次效应对可及性的贡献。即在计算最终的sigmoid之前添加了批次层和细胞特异性层的输出。直观地说,与批次效应相关的可及性信息会被新的全连接层学习,而原始的h×cell权重矩阵仅会学习到有生物学意义的信息。
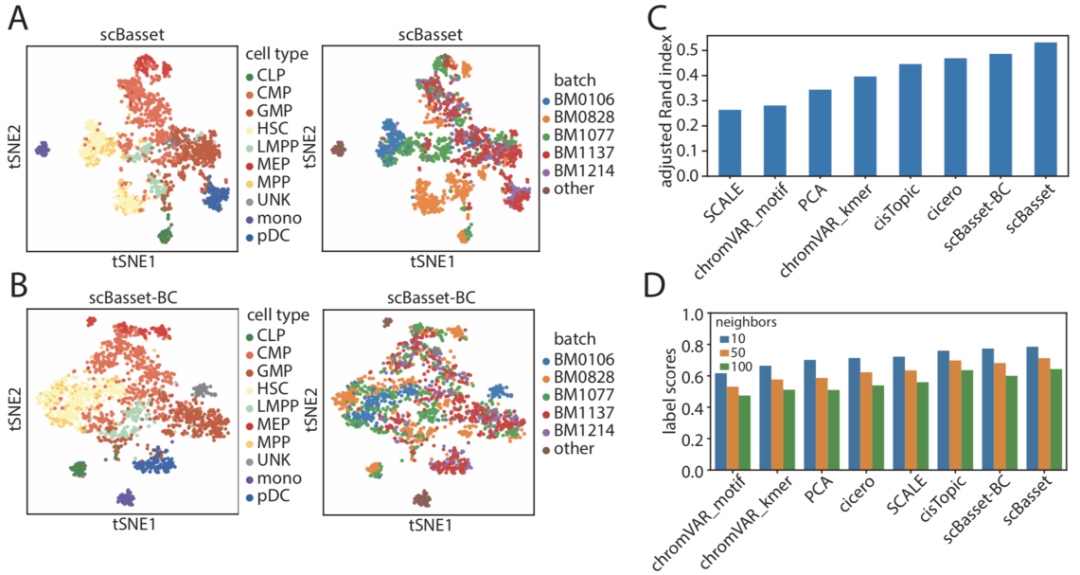 图3 scBasset可适用于执行批次校正
图3 scBasset可适用于执行批次校正
作者比较了批次校正前后的scBasset细胞嵌入结果。结果表明,批次校正后t-SNE空间中不同的批次整体混合(图 3a、b)。然而,批次校正后集群评估指标略有下降。这是由来自不同供体的细胞类型分布不平衡和批次层学习引起的,这与最近一项研究所观察到的结果一致。尽管如此,scBasset-BC在通过ARI评估时仍然优于其他方法,并且在通过标签分数评估时表现最好(图 3c、d)。
scBasset对单细胞可及性图谱进行去噪
由于scATAC的稀疏性,任何给定细胞和峰值的二进制可及性指标都包含大量假阴性,因此无法在单细胞水平上研究数据和跨细胞聚合。目前许多方法提供去噪(或插补)数值来表示每个细胞/峰值组合的可及性状态。scBasset可在其基于序列的预测中计算这些值。
在Buenrostro2018数据集中,作者采样了500个峰值和200个细胞,并直接可视化了原始cell-by-peak矩阵与去噪矩阵(图 4a)。在原始计数矩阵中,细胞和峰值按测序深度聚集,没有显示出生物学相关的模式。然而,在scBasset去噪后,相同细胞类型的细胞具有相似的可及性图谱,并且细胞的层次聚类与真实标签能够很好的匹配。
几种已发表的方法汇总了基因转录起始位点周围区域的scATAC计数,用以估计其转录。作者提出的去噪方法将改善基因可及性估计与多组实验中基因测量的RNA表达之间的相关性。作者还通过平均去噪前后所有启动子峰值的预测可及性值来计算每个基因的可及性分数(图 4b)。
基于协方差的方法也可用于对scATAC进行去噪,作者将scBasset与SCALE进行了比较,SCALE是一种不依赖DNA序列的方法,其使用变分自动编码器进行可及性去噪。研究表明,可及性和表达变化之间的相关性比它们的绝对值更好,因此这将是验证可及性去噪方法的更有用的衡量指标。作者评估了scBasset和SCALE可及性去噪,以确保差异表达和差异可及性之间的一致性。作者还假设SCALE对细胞间协方差的依赖会促使细胞彼此之间比实际更相似并且更平滑。scBasset不太容易过度平滑,因为每个峰值仅通过其序列来考虑。SCALE在去噪基线可及性方面表现更好,而scBasset在去噪差异可及性方面表现更好。实验结果表明,结合scBasset和SCALE比单独使用任何一种方法产生的性能更好(图 4c)。
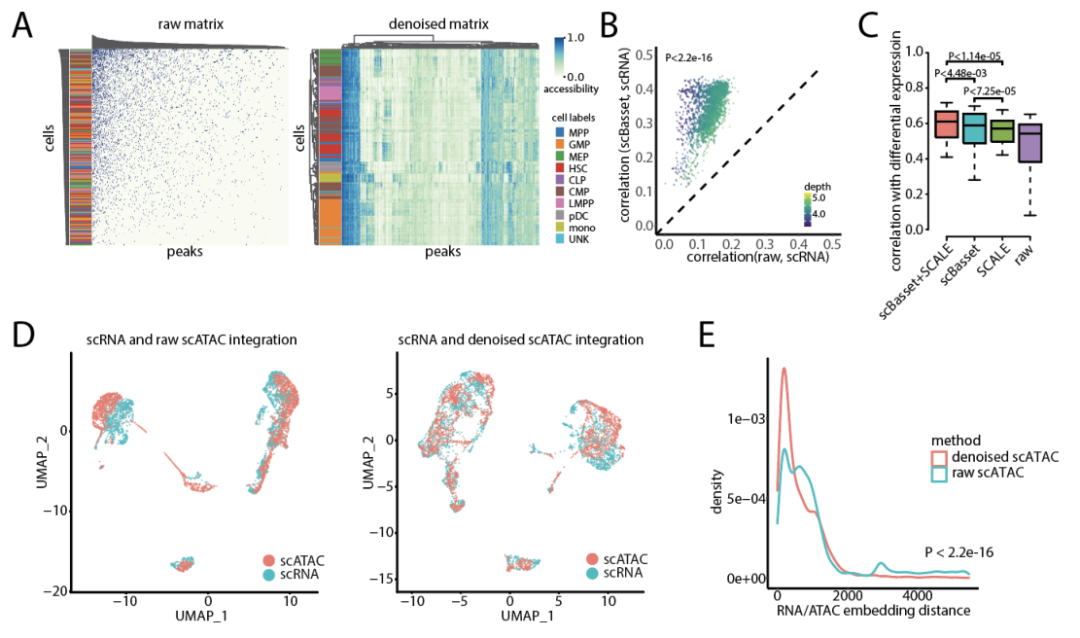 图4 scBasset具有良好的去噪性能
图4 scBasset具有良好的去噪性能
将scRNA和scATAC独立分析的细胞整合到共享的潜在空间中是许多scATAC注释和分析方法的关键步骤。作者假设scATAC去噪会提高scRNA和scATAC整合性能。为了评估整合性能,作者将10x多组scRNA和scATAC图谱视为两个独立实验。实验结果表明,将scRNA图谱与去噪后的scATAC图谱整合时,与将scRNA与原始scATAC图谱整合时相比,细胞实现了更好的混合(图 4d)。作者还测量了每个匹配细胞的RNA和ATAC嵌入之间的多组秩距离(图4e)。
scBasset在单细胞分辨率下推断转录因子活性
转录因子活性是染色质可及性的主要驱动因素。由于scBasset可以从DNA序列预测染色质可及性,作者期望模型能够捕获预测TF结合的序列信息。为了预测单细胞TF活性,作者利用scBasset模型的灵活性来预测任意序列。更具体地说,作者将一对具有和不具有特定TF基序的合成DNA序列输入到经过训练的scBasset模型,并根据预测的可及性差值估计对应的转录因子在每个细胞当中的活性。如果TF在特定细胞中发挥激活作用,那么在插入TF基序后可及性会增加。
作者使用Buenrostro2018训练的模型对733个人类CIS-BP基序进行了基序注入,并重现了已知的基序活动轨迹。以前基于DNA序列的方法也能量化TF基序活性。为了在这项任务中全面比较scBasset和chromVAR,作者分析了10x PBMC多组数据集,其中在RNA中测量的TF表达可以作为其基序活性的代表。作者使用scBasset和chromVAR推断了733个人类CIS-BP基序的基序活性。对于在细胞类型簇之间显著差异表达的203个TF,作者分析推断了每个细胞的TF活性与其表达的相关性。实验表明, scBasset 的总体TF活性与表达的相关性显著高于chromVAR 的TF活性(图 5b)。这种单方面的测试低估了scBasset相对于chromVAR的性能优势,因为可能抑制因子的TF表达和推断活性呈负相关。因此,作者还分别评估了scBasset和chromVAR对激活和抑制TF的影响。对于74个TF,两种方法都表明TF活性与表达正相关,scBasset预测的TF活性与表达的相关性明显高于chromVAR预测的活性。对于41个TF,两种方法都表明TF活性与表达负相关,scBasset预测的TF活性与表达的相关性明显低于chromVAR预测的活性。
通过检测PBMC细胞类型的一些关键调控因子,作者发现scBasset TF活性比chromVAR具有更好的细胞类型特异性,并且与TF表达的相关性更好(图 5c)。
与chromVAR不同,scBasset使用准确的定量模型来预测DNA核苷酸的细胞类型特异性可及性。它不仅能够在每个细胞水平上预测scBasset的TF活性,还可以在每个细胞每个核苷酸的分辨率下推断TF活性。作者检测了调控红细胞特异性β-珠蛋白表达的β-珠蛋白基因的已知增强子。对该100bp序列计算了ISM,其中预测了在将每个位置突变为其它三个替代核苷酸后每个细胞中可及性的变化。通过对每个参考核苷酸进行表征化的ISM评分来汇总每个位置的单个评分。图5d显示了红细胞系中每种细胞类型的平均ISM评分。该实验表明,scBasset可以在单细胞分辨率下学习可及性调控语法,并用于识别调控单个细胞和谱系中特定增强子的TF。
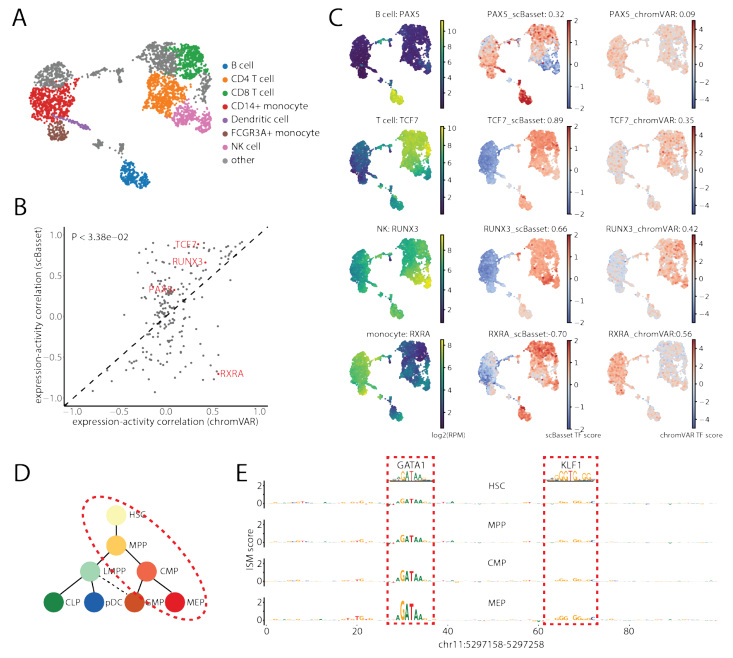 图5 scBasset推断单细胞TF活性
图5 scBasset推断单细胞TF活性
3.总结
在这项研究中,作者介绍了scBasset,这是一种基于DNA序列的深度学习框架,用于对scATAC数据进行建模。scBasset经过训练,可以从ATAC峰值下的DNA序列预测单个细胞的可及性,学习嵌入向量以表示该过程中的单个细胞。经过训练的scBasset模型可以加强对scATAC的多条分析,并在多项任务上展示最先进的性能。对模型的细胞嵌入进行聚类可以更好地与真实细胞类型标签对齐。模型的输出可用作可及性图谱去噪,从而提高与RNA测量的一致性。该模型可以学习识别TF基序及其对可及性的影响,作者通过将基序注入背景序列中,以预测单细胞中的TF基序活性。该模型还可用于预测突变的影响,从而能够在单细胞分辨率下对感兴趣的调控序列计算ISM。与之前基于DNA序列的scATAC分析方法相比,scBasset在学习细胞嵌入和推断TF活性方面取得了更好的性能,因为scBasset受益于更具表现力的CNN模型,该模型可以学习更复杂的序列特征,包括非线性关系。与以前的不依赖DNA序列的方法相比,scBasset在基准测试任务中取得了更好的性能,并提供了一个更具解释性的模型,可以直接预测TF活性或识别调控序列。
基于DNA序列的方法有几个限制。首先,在利用参考基因组时,许多样本会有变异版本,包括可能导致模型误入歧途的拷贝数变异。其次,假设调控基序及其相互作用在整个基因组中普遍存在。这种假设在某些基因组位点可能并不完全正确,因为这些基因组位点的进化导致了特殊的调控方式。由于scBasset与基于协方差的方法采用的是完全独立的方法,因此可以将这两种方法结合起来以作进一步改进。
此外,作者预见了进一步改进该模型的几种途径。为了提高scBasset内存效率以便扩展到非常大的数据集,可以同时对序列和细胞进行小批量采样,而不是只对当前实现中的序列进行抽样。scATAC分析的所有方法都取决于准确的峰值调用,并且已经提出了预测性建模框架,以帮助识别高度特异性的调控元素。作者期望神经网络模型将通过考虑序列信息进一步改善scATAC峰值调用。最后,作者计划探索迁移学习方法,使得在对特定的单细胞数据集进行微调训练之前,能先在大数据集上对模型进行预训练。
参考资料
Yuan, H. & Kelley, DR. scBasset: sequence-based modeling of single-cell ATAC-seq using convolutional neural networks. Nature methods, 2022.
https://www.nature.com/articles/s41592-022-01562-8.
数据
https://support.10xgenomics.com/single-cell-multiome-atac-gex/datasets/2.0.0/pbmc_granulocyte_sorted_3k https://support.10xgenomics.com/single-cell-multiome-atac-gex/datasets/2.0.0/e18_mouse_ brain_fresh_5k
代码
https://github.com/calico/scBasset
文章来源: drugai.blog.csdn.net,作者:DrugAI,版权归原作者所有,如需转载,请联系作者。
原文链接:drugai.blog.csdn.net/article/details/126495960

- 点赞
- 收藏
- 关注作者
评论(0)