【Dive into Deep Learning / 动手学深度学习】第十章 - 第一节:注意力提示

【摘要】
目录
前言10.1. 注意力提示10.1.1. 生物学中的注意力提示10.1.2. 查询、键和值10.1.3. 注意力的可视化10.1.4. 小结
结语
前言
Hello! ...

前言
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
自我介绍 ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研。
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力💪
知其然 知其所以然!
本文仅记录自己感兴趣的内容
10.1. 注意力提示
10.1.1. 生物学中的注意力提示
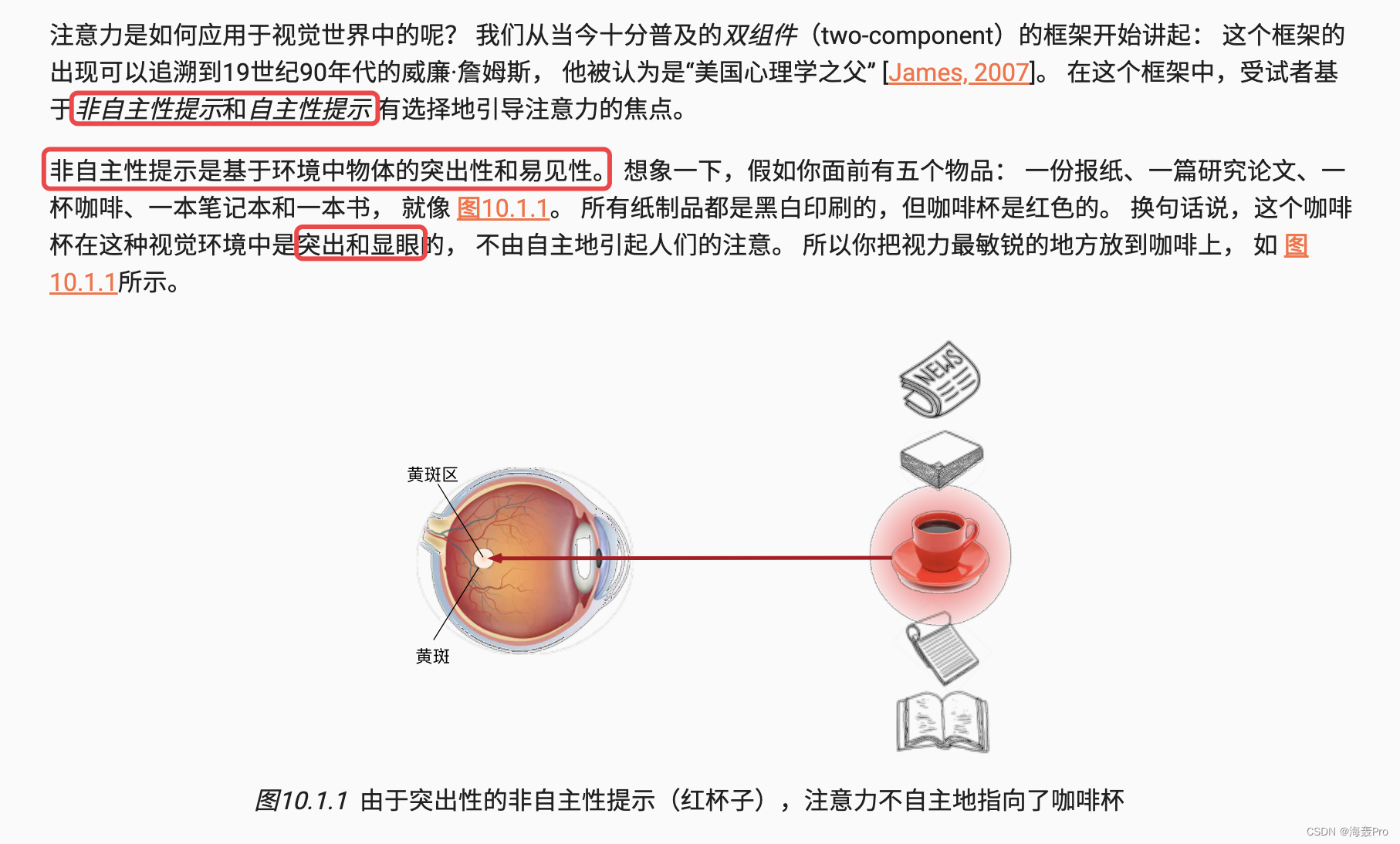
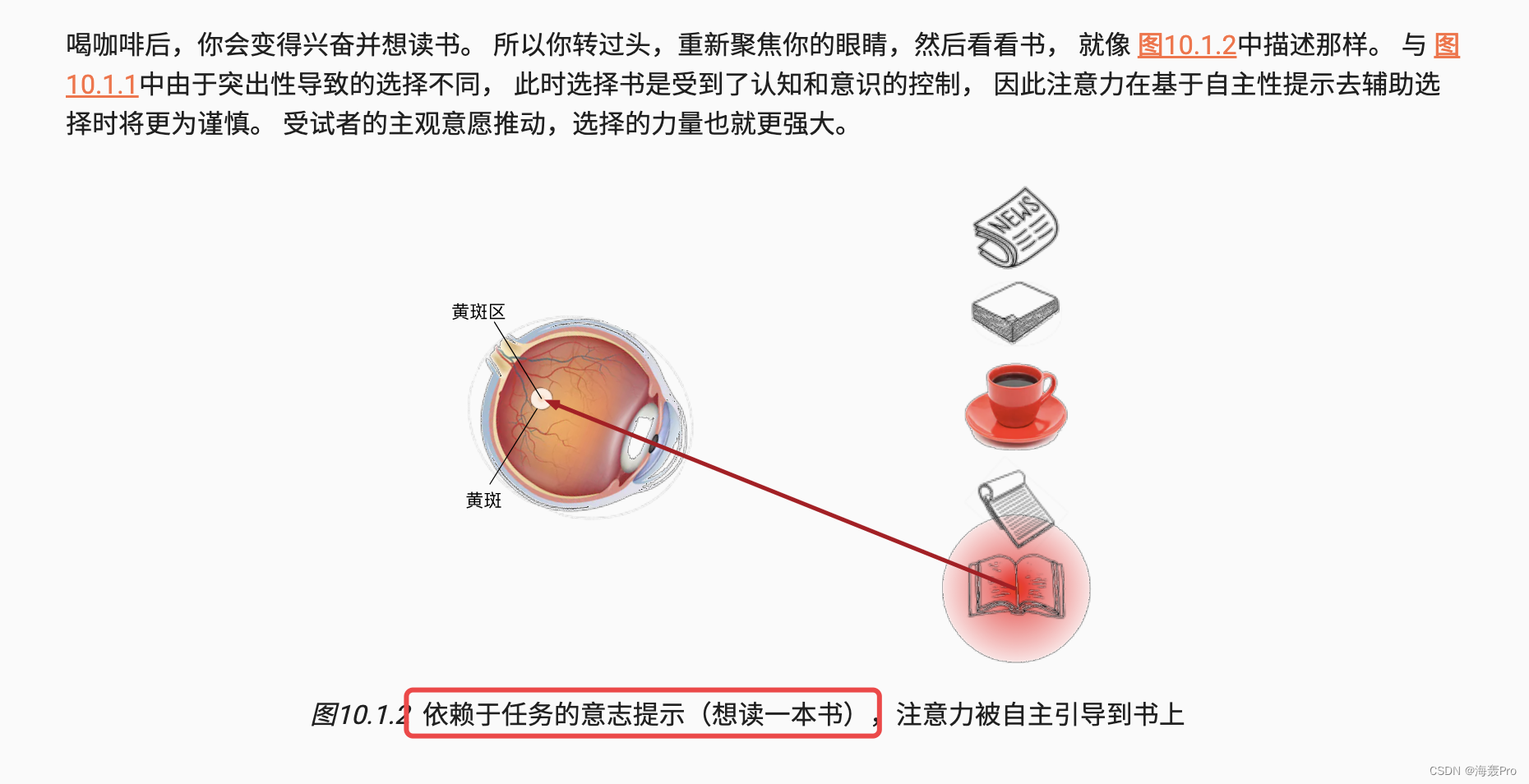
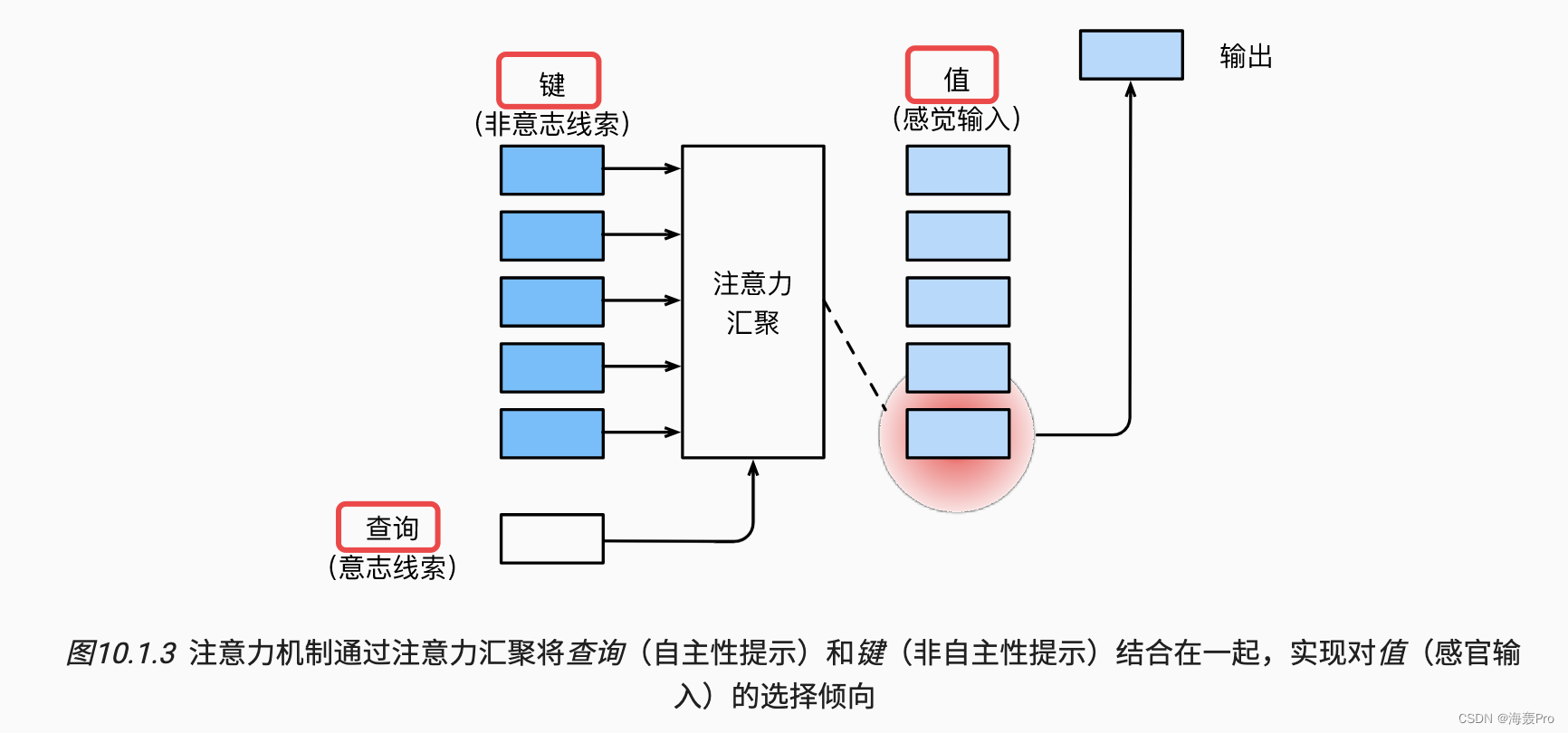
10.1.2. 查询、键和值
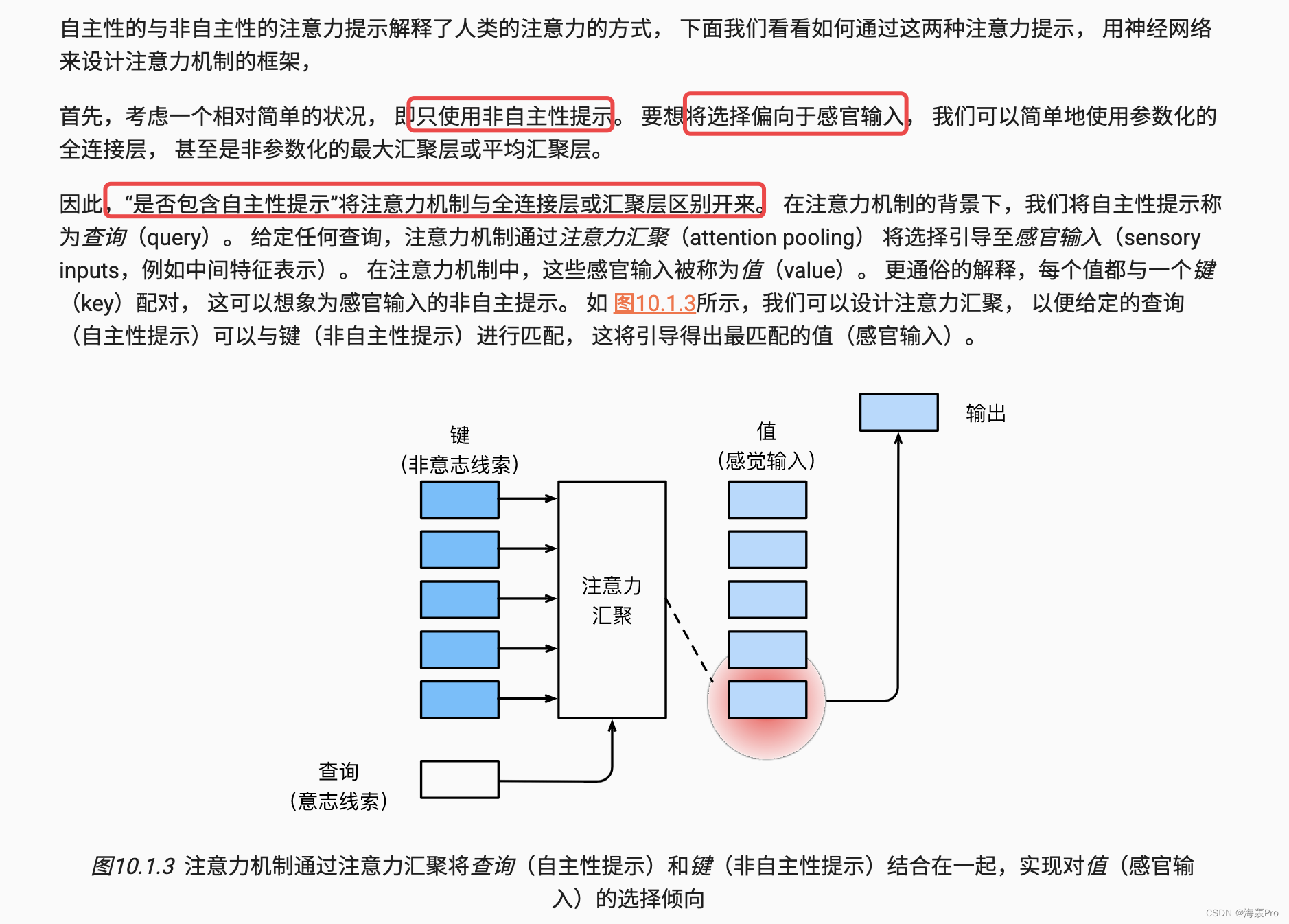

note:
- 下图比较重要
- 主要讲的是query、key、value的一个关系
- 之前不太懂这三者的关系
- 看完沐神的讲解,懂了一点点
- 大概意思是:查询就是,人的大脑喝完咖啡后,
想看书(那么就需要去找书,就是查询) - 然后就去寻找有没有书,书的外表、大小等(标志它是书的因素,就是key)
- 通过这个key找到书,然后进行
看书 - 看书里的内容,则就是我们需要的内容(也就是
输入value:书里的内容)
10.1.3. 注意力的可视化
平均汇聚层可以被视为输入的加权平均值, 其中各输入的权重是一样的
实际上,注意力汇聚得到的是加权平均的总和值, 其中权重是在给定的查询和不同的键之间计算得出的
import torch
from d2l import torch as d2l
- 1
- 2
为了可视化注意力权重,我们定义了show_heatmaps函数
其输入matrices的形状是 (要显示的行数,要显示的列数,查询的数目,键的数目)
#@save
def show_heatmaps(matrices, xlabel, ylabel, titles=None, figsize=(2.5, 2.5),
cmap='Reds'):
"""显示矩阵热图"""
d2l.use_svg_display()
num_rows, num_cols = matrices.shape[0], matrices.shape[1]
fig, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize,
sharex=True, sharey=True, squeeze=False)
for i, (row_axes, row_matrices) in enumerate(zip(axes, matrices)):
for j, (ax, matrix) in enumerate(zip(row_axes, row_matrices)):
pcm = ax.imshow(matrix.detach().numpy(), cmap=cmap)
if i == num_rows - 1:
ax.set_xlabel(xlabel)
if j == 0:
ax.set_ylabel(ylabel)
if titles:
ax.set_title(titles[j])
fig.colorbar(pcm, ax=axes, shrink=0.6);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
note:

axes:可以理解为,一个图代表有一个axe
fig, axes = d2l.plt.subplots(1, 1, figsize=(2.5, 2.5),
sharex=True, sharey=True, squeeze=False)
- 1
- 2
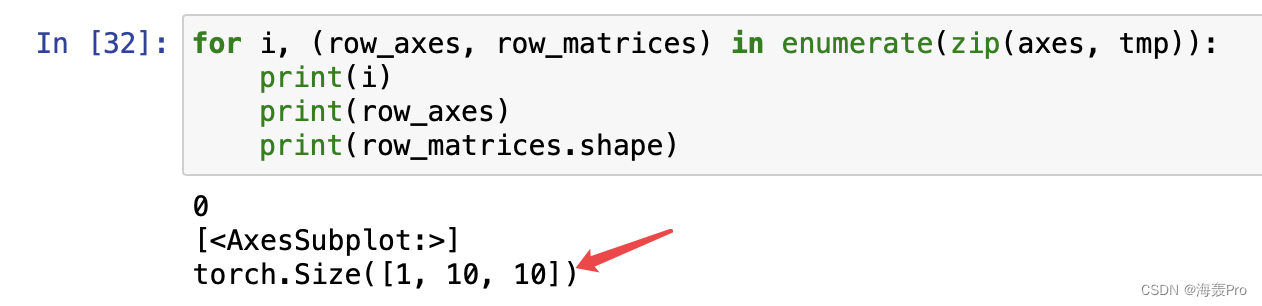
matrices就是多个图的数据总和,每个图的大小规格是一样的,比如都为(10,10)
下面我们使用一个简单的例子进行演示
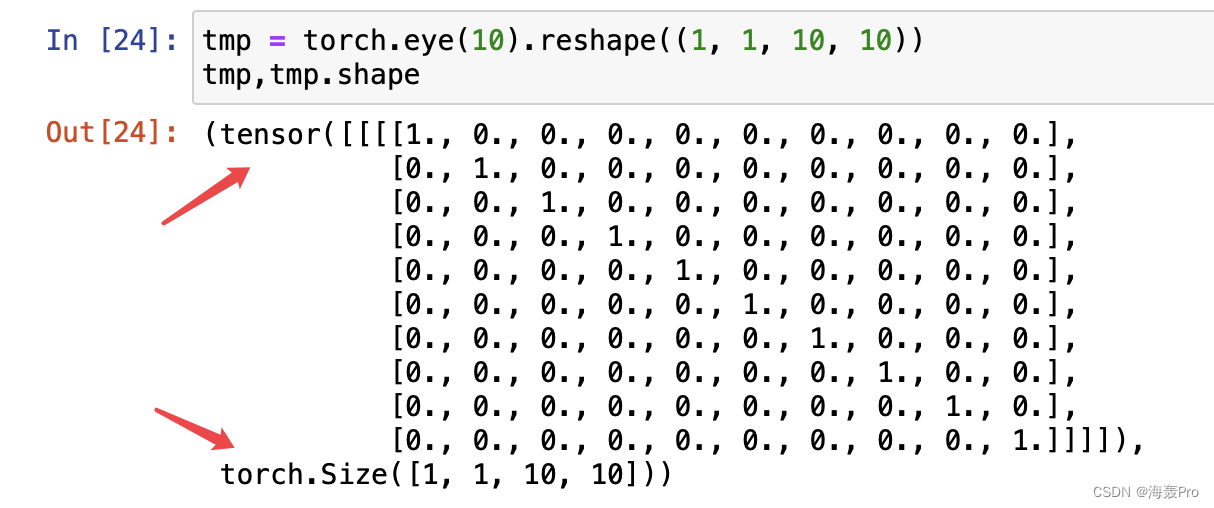
在本例子中,仅当查询和键相同时,注意力权重为1,否则为0。
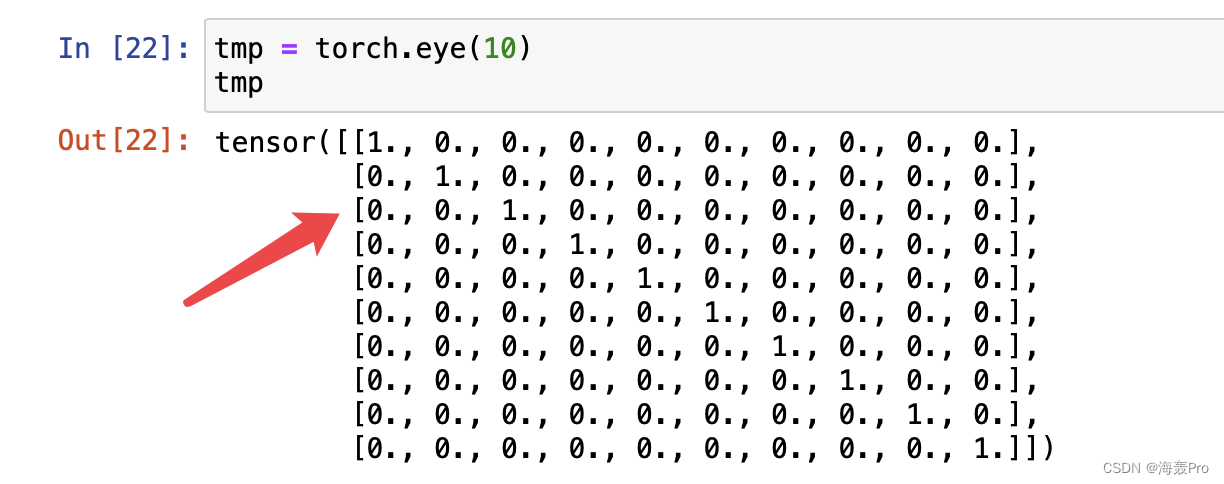
attention_weights = torch.eye(10).reshape((1, 1, 10, 10))
show_heatmaps(attention_weights, xlabel='Keys', ylabel='Queries')
- 1
- 2
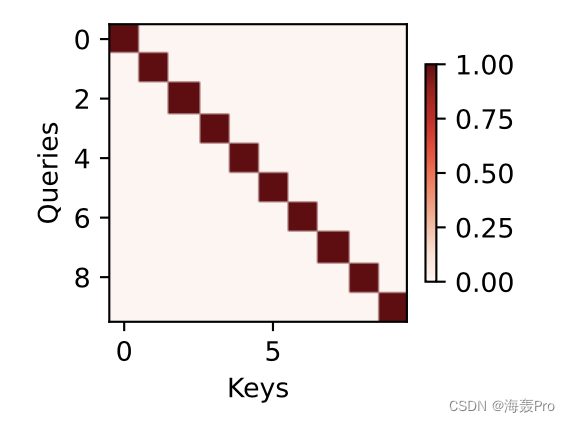
在后面的章节中,我们将经常调用show_heatmaps函数来显示注意力权重。
10.1.4. 小结

结语
学习资料:http://zh.d2l.ai/
文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正

文章来源: haihong.blog.csdn.net,作者:海轰Pro,版权归原作者所有,如需转载,请联系作者。
原文链接:haihong.blog.csdn.net/article/details/126452059

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)