python学习(一)

@TOC
----------------------------------基础----------------------------------
1.变量

-
元组类型
b = () -
列表类型
b = [] -
字典类型
b = {} -
简单类型
b = 123 a = ’123‘ c = True d = 5.0 -
命名规则
1、开头必须以字母或下划线_开头
2、区分大小写
3、除了开头,其余字母、数字、下划线均可
4、python关键字不能用作变量名 -
命名规范


2.运算符
- 算术运算符
- 比较运算符
- 逻辑运算符
优先级:() > not > and > or - 赋值运算符
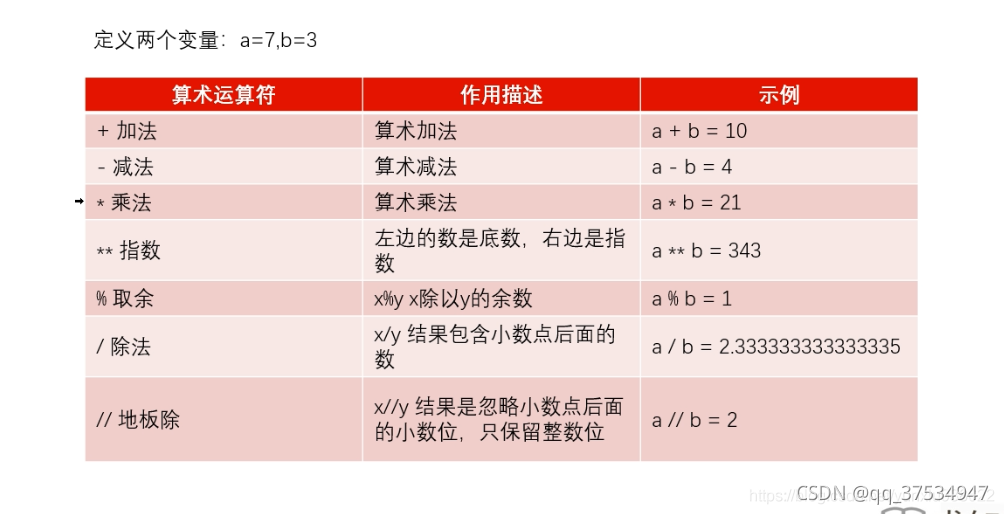
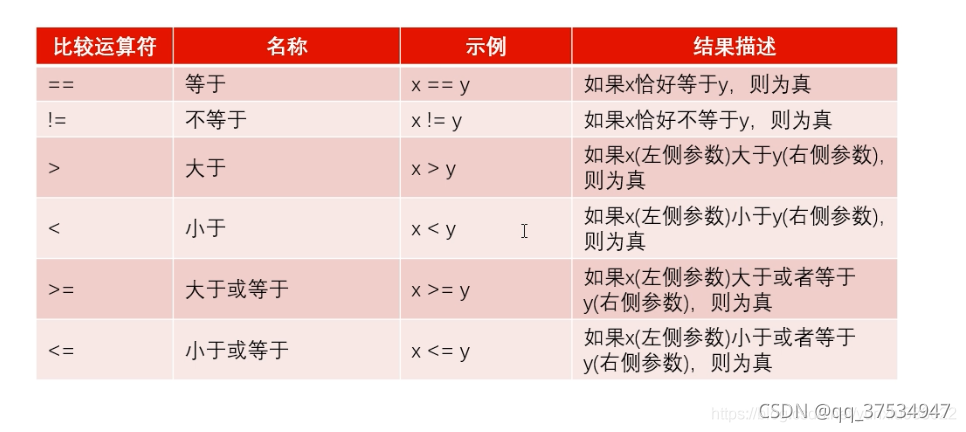
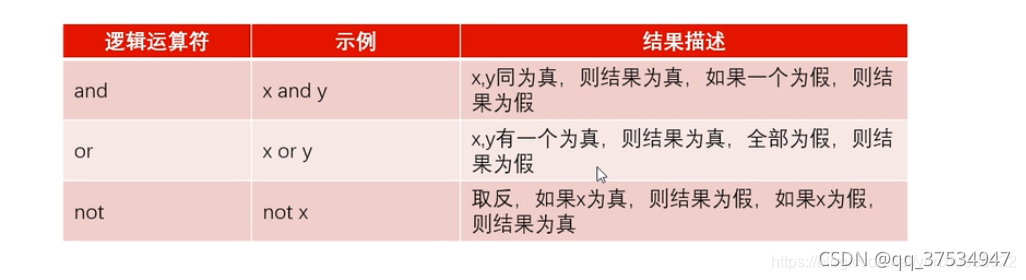
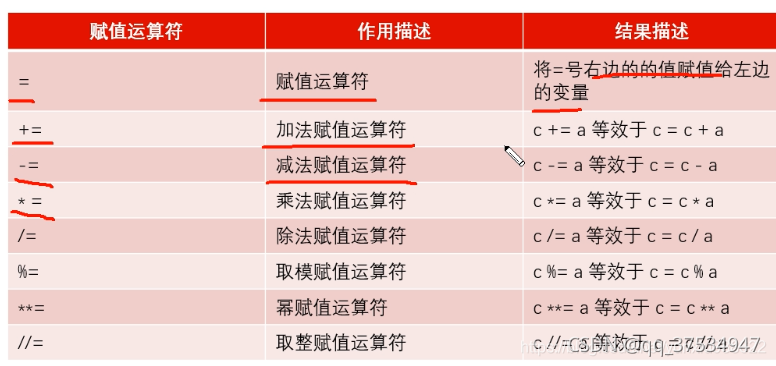
3.输入和输出
-
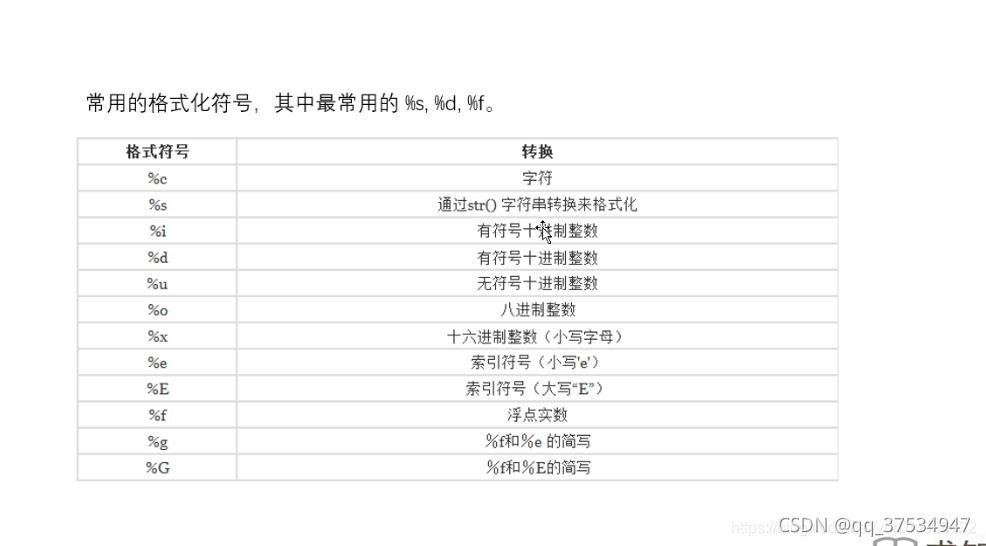
输出
- %占位符
#输出 %占位符 name = '张扬' classPro = '清华附中3班' age = 7 #整数为%d print('我的名字是%s:来自[%s],今年%d岁了'%(name,classPro,age))- .format()
name = '张扬' classPro = '清华附中3班' age = 7 #整数为%d print('我的名字是{}:来自[{}],今年{}岁了'.format(name,classPro ,age))- \n换行符
-
输入
# input输入的一定是字符串形式 如果必须要求输入其他类型的数 # 比如%d要求整数 就用int(input())转换 name = input("请输入你的姓名:")
总结

4.流程控制结构
-
选择控制 if-elif-else
score = int(input('请输入成绩:')) if score > 70: print('成绩可以') elif score >60: print('及格了') else: print('没及格,延毕!') -
循环控制
- for循环
for i in range(1,101): print(i , end = " ") - while循环
row = 1 while row<9: print(row) row += 1 - break 跳出当前循环
- continue 执行当前循环的下一次
注:许多案例,如九九乘法表、直角三角形等等
- for循环
5.高级数据类型
-
序列:一组按照顺序排列的值(数据集合)
-
索引/下表(默认从0开始)
-
切片:截取字符串中的其中一段内容,[start : end :step] (step默认为1,end默认为不包含)
-
1:字符串(不可变)
Test='python' # print(type(Test)) # print('获取第一个字符%s'%Test[0]) # print('获取第二个字符%s'%Test[1]) # for item in Test: # print(item,end=' ') name='peter' # print('姓名首字母转换大写%s'%name.capitalize()) capitalize 首字母变大写 a=' hello ' # b=a.strip() #去除字符串中两边的空格 # print(a) # print(a.lstrip()) #删除左边的空格 # print(a.rstrip()) #删除右边的空格 # 复制字符串 # print('a的内存地址%d'%id(a)) #id函数 可以查看一个对象的内存地址 # b=a #在此只是把a对象的内存地址赋给了b # print('a的内存地址%d'%id(a)) # print(b) # dataStr='I love Python' # print(dataStr.find('M')) #find函数可以查找目标对象在序列对象中的为值,如果没找到就返回-1 # print(dataStr.index('W')) #检测字符串中是否包含子字符串 返回的是下标值 # index如果没有找到对象的数据 便会报异常,而find函数不会,找不到返回-1 # print(dataStr.startswith('I')) #判断开头 # print(dataStr.endswith('n'))#判断结尾 # # print(dataStr.lower()) #转换成小写 # print(dataStr.upper())#转换成大写 strMsg='hello world' # slice [start:end:step] 左闭右开 start<=value<end 范围 # print(strMsg) #输出完整的数据 # print(strMsg[0]) print(strMsg[2:5]) #2-5下标之间的数据 print(strMsg[2:]) #第三个字符到最后 print(strMsg[:3]) #1-3 strMsg[0:3]=strMsg[:3] print(strMsg[::-1]) #倒叙输出 负号表示方向 从右边往左去遍历 # 共有方法 + * in # 字符串合并 strA='人生苦短' strB='我用Python' # list 合并 listA=list(range(10)) listB=list(range(11,20)) print(listA+listB) # print(strA+strB) # 复制 * # print(strA*3) # print(listA*3) # in 对象是否存在 结果是一个bool值 print('我' in strA) #False print(9 in listA) #False dictA={"name":"peter"} print("name" in dictA)
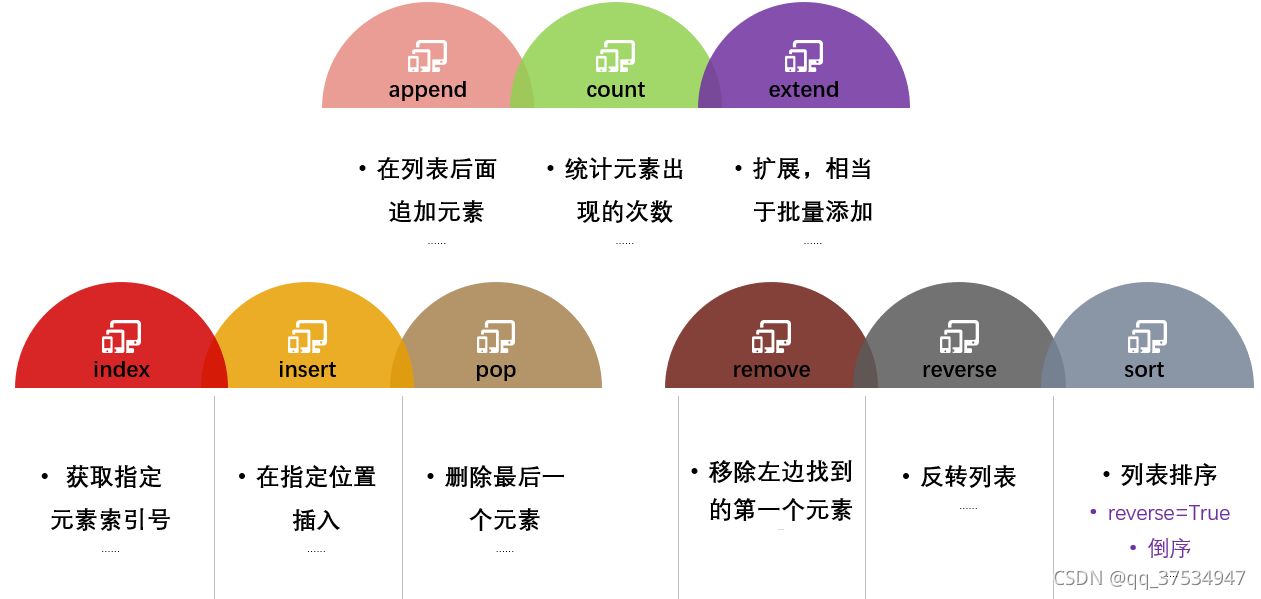
- 2:列表(可变)
- 2.1:支持增删改查
- 2.2:列表中的数据是可以变化的【数据项可以变化,内存地址不会改变】
- 2.3:用[] 来表示列表类型,数据项之间用逗号来分割,注意:数据项可以是任何类型的数据
- 2.4:支持索引和切片来进行操作
# li=[] #空列表 # li=[1,2,3,"你好"] # print(len(li)) #len函数可以获取到列表对象中的数据个数 # strA='我喜欢python' # print(len(strA)) # print(type(li)) # 查找 listA=['abcd',785,12.23,'qiuzhi',True] # print(listA) #输出完整的列表 # print(listA[0]) #输出第一个元素 # print(listA[1:3]) #从第二个开始到第三个元素 # print(listA[2:]) #从第三个元素开始到最后所有的元素 # print(listA[::-1]) #负数从右像左开始输出 # print(listA*3) #输出多次列表中的数据【复制】 # print('--------------增加-----------------------') # print('追加之前',listA) # listA.append(['fff','ddd']) #追加操作 # listA.append(8888) # print('追加之后',listA) # listA.insert(1,'这是我刚插入的数据') #插入操作 需要执行一个位置插入 # print(listA) # rsData=list(range(10)) #强制转换为list对象 # print(type(rsData)) # listA.extend(rsData) #拓展 等于批量添加 # listA.extend([11,22,33,44]) # print(listA) # print('-----------------修改------------------------') # print('修改之前',listA) # listA[0]=333.6 # print('修改之后',listA) listB=list(range(10,50)) print('------------删除list数据项------------------') print(listB) # del listB[0] #删除列表中第一个元素 # del listB[1:3] #批量删除多项数据 slice # listB.remove(20) #移除指定的元素 参数是具体的数据值 listB.pop(1) #移除制定的项 参数是索引值 print(listB) print(listB.index(19,20,25)) #返回的是一个索引下标
-
3:元组(不可变)
-
3.1:不可变
-
3.2:用()创建元组类型,数据项用逗号来分割
-
3.3:可以是任何的类型
-
3.4:当元组中只有一个元素时,要加上逗号,不然后解释器会当做其他类型来处理
-
3.5:同样可是支持切片操作
# 元组的创建 不能进行修改 tupleA=() #空元组 # print(id(tupleA)) tupleA=('abcd',89,9.12,'peter',[11,22,33]) # print(id(tupleA)) # print(type(tupleA)) # print(tupleA) # 元组的查询 # for item in tupleA: # # print(item,end=' ') # print(tupleA[2:4]) # print(tupleA[::-1]) # print(tupleA[::-2]) #表示反转字符串 每隔两个取一次 # # print(tupleA[::-3]) #表示反转字符串 每隔三个取一次 # # print(tupleA[-2:-1:]) #倒着取下标 为-2 到 -1 区间的 # # print(tupleA[-4:-2:]) #倒着取下标 为-2 到 -1 区间的 # tupleA[0]='PythonHello' #错误的 # tupleA[4][0]=285202 #可以对元组中的列表类型的数据进行修改 # print(tupleA) # print(type(tupleA[4])) tupleB=('1',) # 当元组中只有一个数据项的时候,必须要在第一个数据项后面加上 逗号 # print(type(tupleB)) tupleC=(1,2,3,4,3,4,4,1) #tuple(range(10)) print(tupleC.count(4)) #可以统计元素出现的次数
-
-
字典
- 4.1:不是序列类型 没有下标的概念,是一个无序的 键值集合,是内置的高级数据类型
- 4.2:用{} 来表示字典对象,每个键值对用逗号分隔
- 4.3:键 必须是不可变的类型【元组、字符串】,值可以是任意的类型
- 4.4: 每个键必定是惟一的,如果存在重复的键,后者会覆盖前者
# 如何创建字典 dictA={"pro":'艺术','shcool':'北京电影学院'} #空字典 # 添加字典数据 dictA['name']='李易峰' #key:value dictA['age']='30' dictA['pos']='歌手' #结束添加 # print(dictA) #输出完整的字典 # print(len(dictA)) #数据项长度 # print(type(dictA)) # print(dictA['name']) #通过键获取对应的值 dictA['name']='谢霆锋' #修改键对应的值 dictA['shcool']='香港大学' dictA.update({'height':1.80}) #可以添加或者更新 print(dictA) # 获取所有的键 print(dictA.keys()) # 获取所有的值 print(dictA.values()) # 获取所有的键和值 print(dictA.items()) for key,value in dictA.items(): print('%s==%s'%(key,value)) # 删除操作 del dictA['name'] 通过指定键进行删除 dictA.pop('age') 通过指定键进行删除 print(dictA) # 如何排序 按照key排序 print(sorted(dictA.items(),key=lambda d:d[0])) # 按照value排序 print(sorted(dictA.items(),key=lambda d:d[1])) # 字典拷贝 import copy # dictB=copy.copy(dictA) #浅拷贝 dictC=copy.deepcopy(dictA) #深拷贝 print(id(dictC)) print(id(dictA)) # dictB['name']='peter' dictC['name']='刘德华' print(dictC) print(dictA) -
公用方法



总结
6.函数(上)
-
定义
什么是函数:一系列Python语句的组合,可以在程序中运行一次或者多次。 一般是完成具体的独立的功能 为什么要使用函数: 代码的复用最大化以及最小化冗余代码,整体代码结构清晰,问题局部化 函数定义: def 函数名(): 函数体[一系列的python语句,表示独立的功能] 函数的调用: 本质上就是去执行函数定义里面的代码块,在调用函数之前必须先定义。 -
函数的定义、调用、参数
# print('小张的身高是%f'%1.73) # print('小张的体重是%f'%160) # print('小张的爱好是%s'%'唱歌') # print('小张的身高是%s'%'计算机信息管理') #处理其他的逻辑信息 # 多次去打印出小张的信息 print('---------------多次输出相同的信息---------------------') # print('小张的身高是%f'%1.73) # print('小张的体重是%f'%160) # print('小张的爱好是%s'%'唱歌') # print('小张的专业是%s'%'计算机信息管理') # 针对上面的场景 就需要进一步的去优化代码【方案:封装函数】 # 函数的定义 # def 函数名(参数列表):0-n 个 # 代码块 def printInfo(): ''' 这个函数是用来打印个人信息的 是对小张信息显示的组合 :return: ''' # 函数代码块 print('小张的身高是%f' % 1.73) print('小张的体重是%f' % 160) print('小张的爱好是%s' % '唱歌') print('小张的专业是%s' % '计算机信息管理') pass #函数的调用 # printInfo() #函数的调用 # printInfo() #多次调用 # printInfo() # printInfo() # printInfo() # print('我是其他的代码块...') # 进一步的去完善这样的需求【输出不同人的信息】 方案:通过传入参数来解决 def printInfo(name,height,weight,hobby,pro): #形式参数 # 函数代码块 print('%s的身高是%f' %(name,height)) print('%s的体重是%f' %(name,weight)) print('%s的爱好是%s' %(name,hobby)) print('%s的专业是%s' %(name,pro)) pass # 调用带参数的信息 printInfo('小李',189,200,'打游戏','咨询师') #实参 print('------------------带参数的调用---------------------------') printInfo('peter',175,160,'码代码','计算机应用')注:pass的作用?
-
参数的分类——必选参数、默认参数【缺省参数】、可选参数、关键字参数
-
1:必选参数——实际参数和形式参数
-
形参——sum(a,b)// 不占内存地址
-
实参——sum(10,20)// 占内存地址
# 参数的分类: # 必选参数、默认参数[缺省参数]、可选参数、关键字参数 # 参数:其实就是函数为了实现某项特定的功能,进而为了得到实现功能所需要的数据 # 为了得到外部数据的 # 1 必选参数 def sum(a,b): #形式参数:只是意义上的一种参数,在定义的时候是不占内存地址的 sum=a+b print(sum) pass # 函数调用 在调用的时候必选参数 是必须要赋值的 sum(20,15) #20 15 实际参数:实参,实实在在的参数,是实际占用内存地址的 # sum(15) #不能这样写的, -
2:默认参数/缺省参数
# 2:默认参数【缺省参数】 始终存在于参数列表中的尾部 def sum1(a,b=40,c=90): print('默认参数使用=%d'%(a+b)) pass # # 默认参数调用 sum1(10) #在调用的时候如果未赋值,就会用定义函数时给定的默认值 sum1(2,56) -
3:可变参数
#可变参数(当参数的个数不确定时使用,比较灵活 def getComputer(*args): #可变长的参数 ''' 计算累加和 :param args: 可变长的参数类型 :return: ''' # print(args) result=0 for item in args: result+=item pass print('result=%d'%result) pass getComputer(1) getComputer(1,2) getComputer(1,2,3) getComputer(1,2,3,4,5,6,7,8) -
4.关键字可变参数 0-n(字典类型的参数)
# 关键字可变参数 0-n # ** 来定义 # 在函数体内 参数关键字是一个字典类型 key是一个字符串 def keyFunc(**kwargs): print(kwargs) pass # 调用 # keyFunc(1,2,3) 不可以传递的 dictA={"name":'Leo',"age":35} keyFunc(**dictA) keyFunc(name='peter',age=26,) keyFunc() ``` -
5.组合参数
# 组合的使用 def complexFunc(*args,**kwargs): print(args) print(kwargs) pass complexFunc(1,2,3,4,name='刘德华') complexFunc(age=36) # def TestMup(**kwargs,*args): #不符合要求的 ''' 可选参数必须放到关键字可选参数之前 可选参数:接受的数据是一个元组类型 关键字可选参数:接受的数据是一个字段类型 :param kwargs: :param args: :return: ''' # pass -
函数返回值
# 函数返回值 # 概念:函数执行完以后会返回一个对象,如果在函数的内部有return 就可以返回实际的值,否则返回None # 类型:可以返回任意类型,返回值类型应该取决于return后面的类型 # 用途:给调用方返回数据 # 在一个函数体内可以出现多个return值:但是肯定只能返回一个return # 如果在一个函数体内 执行了return,意味着函数就执行完成退出了,return后面的代码语句将不会执行 def Sum(a,b): sum=a+b return sum#将计算的结果返回 pass # rs=Sum(10,30) #将返回值赋给其他的变量 # print(rs) #函数的返回值返回到调用的地方 def calComputer(num): li=[] result=0 i=1 while i<=num: result+=i i+=1 pass li.append(result) return li pass # 调用函数 value=calComputer(10) print(type(value)) #value 类型 print(value) def returnTuple(): ''' 返回元组类型的数据 :return: ''' # return 1,2,3 return {"name":"测试"} pass A=returnTuple() print(type(A)) -
函数嵌套
# 函数嵌套 def fun1(): print("--------------fun1 start-------------------") print("--------------执行代码省略-------------------") print("--------------fun1 end-------------------") pass def fun2(): print("--------------fun2 start-------------------") # 调用第一个函数 fun1() print("--------------fun2 end-------------------") pass fun2() #调用函数2 # 函数的分类:根据函数的返回值和函数的参数 # 有参数无返回值的 # 有参数又返回值的 # 无参数又返回值的 # 无参数无返回值的

总结
7.函数(下)
7.1函数的基本类型

7.2全局变量和局部变量
-
------------局部变量----------------
-
局部变量 就是在函数内部定义的变量【作用域仅仅局限在函数的内部】
-
不同的函数 可以定义相同的局部变量,但是各自用各自的 不会产生影响
-
局部变量的作用:为了临时的保存数据 需要在函数中定义来进行存储
-
------------全局变量----------------
-
下面的pro的定义就是一个全局变量【作用域的范围不同】
-
当全局变量和局部变量出现重复定义的时候,程序会优先执行使用函数内部定义的变量【地头蛇】
-
如果在函数的内部要想对全局变量进行修改的话,对于不可变类型【str、元组 、number】- #必须使用global 关键字进行声明
-
注:
# 以下两个是全部变量 pro='计算机信息管理' name='吴老师' def printInfo(): # name='peter' #局部变量 print('{}.{}'.format(name,pro)) pass def TestMethod(): name='刘德华' print(name,pro) pass def changeGlobal(): ''' 要修改全局变量 :return: ''' global pro #声明全局变量 后才可以修改 pro='市场营销' #局部变量 pass changeGlobal() print(pro) #被修改了吗 TestMethod() printInfo()

7.3引用传值
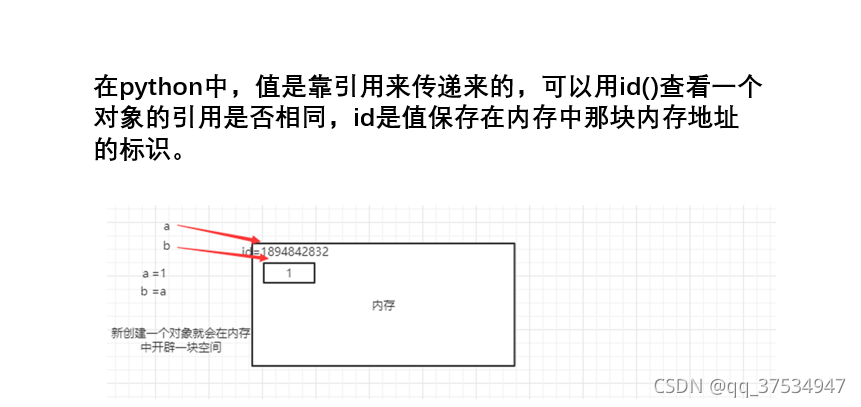
注:这个和java不一样,python是引用传递(记得区分可变类型和不可变类型)。
a=1 #不可变类型
def func(x):
print('x的地址{}'.format(id(x)))
x=2
print('x的值修改之后地址{}'.format(id(x)))
print(x)
pass
# 调用函数
# print('a的地址:{}'.format(id(a)))
# func(a)
# print(a)
# 可变类型
# li=[]
# # def testRenc(parms):
# #
# # li.append([1,3,4,54,67])
# # print(id(parms))
# # print('内部的{}'.format(parms))
# # pass
# #
# # print(id(li))
# # testRenc(li)
# # print('外部的变量对象{}'.format(li))
# 小结
# 1.在python当中 万物皆对象,在函数调用的时候,实参传递的就是对象的引用
# 2.了解了原理之后,就可以更好的去把控 在函数内部的处理是否会影响到函数外部的数据变化
#参数传递是通过对象引用来完成 、参数传递是通过对象引用来完成、参数传递是通过对象引用来完成
7.4匿名函数
-
语法:
-
lambda 参数1、参数2、参数3:表达式
-
特点:
-
7.1使用lambda关键字去创建函数
-
7.2.没有名字的函数
-
7.3匿名函数冒号后面的表达式有且只有一个, 注意:是表达式,而不是语句
-
7.4匿名函数自带return,而这个return的结果就是表达式计算后的结果
-
缺点:
-
lambde只能是单个表达式,不是一个代码块,lambde的设计就是为了满足简单函数的场景,
-
仅仅能封装有限的逻辑,复杂逻辑实现不了,必须使用def来处理
def computer(x,y): ''' 计算数据和 :param x: :param y: :return: ''' return x+y pass # 对应的匿名函数 M=lambda x,y:x+y # 通过变量去调用匿名函数 # print(M(23,19)) # print(computer(10,45)) result=lambda a,b,c:a*b*c # print(result(12,34,2)) age=25 # print('可以参军' if age>18 else '继续上学') #可以替换传统双分支的写法 # funcTest=lambda x,y:x if x>y else y # print(funcTest(2,12)) # rs=(lambda x,y:x if x>y else y)(16,12) #直接的调用 # print(rs) varRs=lambda x:(x**2)+890 print(varRs(10))
7.5递归函数
-
定义
-
递归满足的条件
-
自己调用自己
-
必须有一个明确的结束条件
-
优点: 逻辑简单、定义简单
-
缺点: 容易导致栈溢出,内存资源紧张,甚至内存泄漏
def jiecheng(n): result=1 for item in range(1,n+1): result*=item pass return result # print('10的阶乘{}'.format(jiecheng(10))) # 递归方式去实现 def diguiJc(n): ''' 递归实现 :param n: 阶乘参数 :return: ''' if n==1: return 1 else: return n*diguiJc(n-1) pass # 递归调用 print('5的阶乘{}'.format(diguiJc(5))) # 递归案例 模拟实现 树形结构的遍历 import os #引入文件操作模块 def findFile(file_Path): listRs=os.listdir(file_Path) #得到该路径下所有文件夹 for fileItem in listRs: full_path=os.path.join(file_Path,fileItem) #获取完整的文件路径 if os.path.isdir(full_path):#判断是否是文件夹 findFile(full_path) #如果是一个文件夹 再次去递归 else: print(fileItem) pass pass else: return pass # 调用搜索文件夹对象 findFile('E:\\软件')
总结

8.内置函数
8.1内置函数功能列表


8.2数学运算
# 取绝对值
# print(abs(-34))
# round 取近似值
# print(round(3.66,1))
# pow 求次方
# print(3**3)
# print(pow(3,3))
# max 求最大值
# print(max([23,123,4,5,2,1,786,234]))
# print(max(23,235))
# sum 使用
# print(sum(range(50),3))
# eval 执行表达式
a,b,c=1,2,3
print('动态执行的函数={}'.format(eval('a*b+c-30')))
def TestFun():
print('我执行了吗?')
pass
# eval('TestFun()') #可以调用函数执行
# 类型转换函数
# print(bin(10)) #转换二进制
# print(hex(23)) #十六进制
# 元组转换为列表
tup=(1,2,3,4)
# print(type(tup))
li=list(tup) #强制转换
# print(type(li))
li.append('强制转换成功')
# print(li)
tupList=tuple(li)
# print(type(tupList))
# 字典操作 dict()
# dic=dict(name='小明',age=18) #创建一个字典
# # print(type(dic))
# # # dict['name']='小明'
# # # dict['age']=18
# # print(dic)
# bytes转换
# print(bytes('我喜欢python',encoding='utf-8'))
注:


8.3类型转换运算

8.4序列操作函数

-
all
# all() result:bool 对象中的元素除了是 0、空、FALSE 外都算 TRUE, 所有的元素都为True # 结果就为True print(all([])) #True print(all(())) #True print(all([1,2,4,False]))#False print(all([1,2,4]))#True print(all((3,4,0)))#False -
any
# any result:bool 类似于逻辑运算符 or的判断,只要有一个元素为True 结果就为True print('--------any-------------') print(any(('',False,0))) print(any((1,2,3))) -
sorted(返回的是一个新的结果,原始对象不会变)
# sort 和sorted li=[2,45,1,67,23,10] #原始对象 # li.sort() #list的排序方法 直接修改的原始对象 tupArray=(2,45,1,67,23,10) print('--------排序之前---------{}'.format(li)) varList=sorted(li) #升序排列 varList=sorted(li,reverse=True) #降序排序 print('--------排序之后---------{}'.format(varList)) varRs=sorted(tupArray,reverse=False) print(varRs) -
reverse : list.reverse()
-
range
-
zip
# zip() :就是用来打包的,会把序列中对应的索引位置的元素存储为一个元组 s1=['a','b','c'] s2=['你','我','c他','peter'] s3=['你','我','c他','哈哈','呵呵'] # print(list(zip(s1))) 压缩一个数据 zipList=zip(s2,s3) #两个参数 print(list(zipList)) def printBookInfo(): ''' zip 函数的使用 :return: ''' books=[] #存储所有的图书信息 id = input('请输入编号: 每个项以空格分隔') #str bookName = input('请输入书名: 每个项以空格分隔') #str bookPos = input('请输入位置: 每个项以空格分隔') idList=id.split(' ') nameList = bookName.split(' ') posList = bookPos.split(' ') bookInfo=zip(idList,nameList,posList) #打包处理 for bookItem in bookInfo: ''' 遍历图书信息进行存储 ''' dictInfo={'编号':bookItem[0],'书名':bookItem[1],'位置':bookItem[2]} books.append(dictInfo) #将字典对象添加到list容器中 pass for item in books: print(item) # printBookInfo() -
enumerate
# enumerate 函数用于将一个可遍历的数据对象 # (如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标, # 一般用在 for 循环当中 listObj=['a','b','c'] for index,item in enumerate(listObj,5): print(index,item) pass dicObj={} dicObj['name']='李易峰' dicObj['hobby']='唱歌' dicObj['pro']='艺术设计' # print(dicObj) for item in enumerate(dicObj): print(item)

8.5内置函数set
-
定义:不支持切片和索引,类似字典,但是只有key,是一个无序且不重复的元素集合
-
创建方式:
# set 不支持索引和切片,是一个无序的且不重复的容器 # 类似于字典 但是只有key 没有value # 创建集合 dic1={1:3} set1={1,2,3} set2={2,3,4} print(type(set1)) #集合 print(type(dic1)) #字典 # 添加操作 set1.add('python') print(set1) # 清空操作 set1.clear() print(set1) # 差集操作 rs=set1.difference(set2) print(rs) print(set1-set2) print(set1) # 交集操作 print(set1.intersection(set2)) print(set2&set1) # 并集操作 print(set1.union(set2)) print(set1 | set2) # pop 就是从集合中拿数据并且同时删除 print(set1) quData=set1.pop() print(quData) print(set1) print(set1.discard(3)) #指定移除的元素 print(set1) # update 两个集合 set1.update(set2) print(set1)

总结

--------------------------------面向对象--------------------------------
1.面向对象(上)
1.1定义
- 面向对象编程:oop [object oriented programming] 是一种python的编程思路;
- 面向过程:就是我们一开始学习的,按照解决问题的步骤去写代码 【根据业务逻辑去写代码】,在思考问题的时候, 首先分析’怎么按照步骤去实现’ 然后将问题解决拆解成若干个步骤,并将这些步骤对应成方法一步一步的 最终完成功能。
- 面向对象:关注的是设计思维【找洗车店 给钱洗车】
1.2类和对象
类和对象
类:类是具有一组 相同或者相似特征【属性】和行为【方法】的一系列[多个]对象组合
现实世界 计算机世界
行为---------> 方法
特征---------->属性
对象: 对象是实实在在的一个东西,类的实例化,具象化
类是对象的抽象化 而对象是类的一个实例
1.3定义类和创建对象、实例方法和属性、init方法
实例方法:在类的内部,使用def 关键字来定义 第一个参数默认是 self
【名字标识可以是其他的名字,但是这个位置必须被占用】
实例方法是归于 类的实例所有
属性:类属性 实例属性
在类的内部定义的变量【类属性】
在方法内部定义的【通过类似于self.变量名】 变量,是实例属性
# 定义类和对象
# 类结构 类名 属性 方法
# class 类名:
# 属性
# 方法
class Person:
'''
对应人的特征
'''
# name='小明' #类属性
age=20 #类属性
'''
对应人的行为 实例方法
'''
def __init__(self):
self.name='小明' #实例属性
pass
def eat(parms):
print("大口的吃饭")
pass
def run(self): #实例方法
print('飞快的跑')
pass
pass
def printInfo():
'''
普通方法
:return:
'''
pass
# 创建一个对象【类的实例化】
# 规则格式 对象名=类名()
xm=Person()
xm.eat() #调用函数
xm.run()
print("{}的年龄是:{}".format(xm.name,xm.age))
# 创建另外一个实例对象
xw=Person()
xw.eat() #实例方法
1.4 init方法
# init传递参数 改进
class Pepole:
def __init__(self,name,sex,age):
'''
实例属性的声明
'''
self.name=name
self.sex=sex
self.age=age
pass
def eat(self,food):
'''
吃的行为
:return:
'''
print(self.name+'喜欢吃'+food)
pass
zp=Pepole('张鹏','男生',18)
print(zp.name,zp.age)
zp.eat('香蕉')
lh=Pepole('李辉','男生',28)
lh.eat('苹果')
print(lh.name,lh.age)
xh=Pepole('小花','女生',20)
xh.eat('橘子')
print(xh.name,xh.age)
# 总结 __init__
# 1. python 自带的内置函数 具有特殊的函数 使用双下划线 包起来的【魔术方法】
# 2. 是一个初始化的方法 用来定义实例属性 和初始化数据的,在创建对象的时候自动调用 不用手动去调用
# 3. 利用传参的机制可以让我们定义功能更加强大并且方便的 类
1.5 self理解

小结 self特点
self只有在类中定义 实例方法的时候才有意义,在调用时候不必传入相应的参数 而是由解释器 自动去指向;
self的名字是可以更改的 可以定义成其他的名字,只是约定俗成的定义成了 self
self 指的是 类实例对象本身, 相当于java中 this
class Person:
def __init__(self,pro,name,food):
'''
:param pro: 专业
:param name: 姓名
:param food: 食物
'''
self.pro=pro #实例属性的定义
self.name=name
self.food=food
print('----init-----函数执行')
pass
'''
定义类
'''
def eat(self,name,food):
'''
实例方法
:return:
'''
# print('self=%s',id(self))
print('%s 喜欢吃 %s 修的专业是:%s'%(self.name,self.food,self.pro))
pass
pass
# xw是一个新的实例化对象
xw=Person('心理学','小王','榴莲')
# print('xw=%s',id(xw))
# xw.eat('小王','榴莲')
print(xw) #直接输出对象
1.6 魔术方法
- 定义:

class Person:
def __init__(self,pro,name,food):
'''
:param pro: 专业
:param name: 姓名
:param food: 食物
'''
self.pro=pro #实例属性的定义
self.name=name
self.food=food
print('----init-----函数执行')
pass
'''
定义类
'''
def eat(self,name,food):
'''
实例方法
:return:
'''
# print('self=%s',id(self))
print('%s 喜欢吃 %s 修的专业是:%s'%(self.name,self.food,self.pro))
pass
def __str__(self):
'''
打印对象 自定义对象 是内容格式的
:return:
'''
return '%s 喜欢吃 %s 修的专业是:%s'%(self.name,self.food,self.pro)
pass
def __new__(cls, *args, **kwargs):
'''
创建对象实例的方法 每调用一次 就会生成一个新的对象 cls 就是class的缩写
场景:可以控制创建对象的一些属性限定 经常用来做单例模式的时候来使用
:param args:
:param kwargs:
'''
print('----new-----函数的执行')
return object.__new__(cls) #在这里是真正创建对象实例的
pass
pass
# xw是一个新的实例化对象
xw=Person('心理学','小王','榴莲')
# print('xw=%s',id(xw))
# xw.eat('小王','榴莲')
print(xw) #直接输出对象
# 小结 self特点
# self只有在类中定义 实例方法的时候才有意义,在调用时候不必传入相应的参数 而是由解释器 自动去指向
# self的名字是可以更改的 可以定义成其他的名字,只是约定俗成的定义成了 self
# self 指的是 类实例对象本身, 相当于java中 this
# __new__和__init___函数的区别
# __new__ 类的实例化方法 必须要返回该实例 否则对象就创建不成功
# __init___ 用来做数据属性的初始化工作 也可以认为是实例的构造方法 接受类的实例 self 并对其进行构造
# __new__ 至少有一个参数是 cls 代表要实例化的类 ,此参数在实例化时由python解释器自动提供
# __new__ 函数 执行要早于 __init___ 函数

- 点赞
- 收藏
- 关注作者
评论(0)