一幅长文细学华为MRS大数据开发(三)——Hive

3 HIVE
Apache Hive数据仓库软件有助于使用SQL读取,写入和管理驻留在分布式存储中的大型数据集。可以将结构投影到已经存储的数据上。提供了命令行工具和JDBC驱动程序以将用户连接到Hive上。
3.1 Hive概述
Hive简介
Hive:Hive是基于Hadoop的数据仓库软件,可以查询和管理PB级别的分布式数据。
Hive特性:
- 灵活方便的ETL(extract/transform/load)。
- 支持Tez,Spark等多种引擎
- 可直接访问HDFS文件以及HBase
- 易用易编程
Hive应用场景
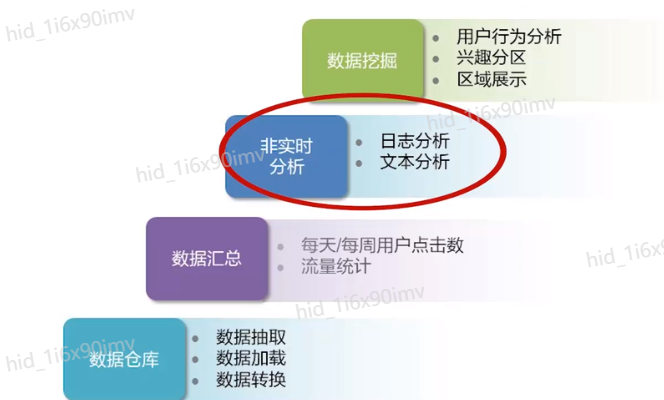
Hive与传统数据仓库比较
| Hive | 传统数据仓库 | |
|---|---|---|
| 存储 | HDFS,理论上有无限拓展的可能 | 集群存储,存在容量上限,而且随着容量的增长,计算速度急剧下降,只能适应与数据量比较小的商业应用,对于超大规模数据无能为力 |
| 执行引擎 | 默认执行引擎Tez | 可以选择更加高效的算法来查询,也可以进行更多的优化措施来提高速度 |
| 使用方式 | HQL | SQL |
| 灵活性 | 元数据存储独立于数据存储之外,从而解耦合元数据和数据 | 低,数据用途单一 |
| 分析速度 | 计算依赖于集群规模,易拓展, | 在数据容量较小时非常快速,数据容量较大时,急剧下降 |
| 索引 | 效率较低 | 高效 |
| 易用性 | 需要自行开发应用模型,灵活度较高,但易用性较低 | 集成一整套成熟的报表解决方案,可以较为方便的进行数据的分析 |
| 可靠性 | 数据存储在HDFS,可靠性高、容错性高 | 可靠性较低,一次查询失败需要重新开始。数据容错依赖于硬件Raid |
| 依赖环境 | 依赖硬件较低,可适应一般的普通机器 | 依赖于高性能的商业服务器 |
| 价格 | 开源产品 | 商用比较昂贵 |
Hive优点
- 高可靠、高容错:HiveServer采用集群模式,双MetaStore,超时重试机制
- 类SQL:指HQL,其类似于SQL语法,内置了大量函数
- 可扩展:自定义存储格式和函数
- 多接口:Beeline、JDBC、Thrift、Python、ODBC
3.2 Hive功能及架构
Hive运行流程
- Client提交HQL命令
- Tez执行查询
- YARN为集群中的应用程序分配资源,并未YARN队列中的Hive作业启用授权
- Hive根据表类型更新HDFS或Hive仓库的数据
- Hive通过JDBC连接返回查询结果
Hive数据存储模型
表中可分区或分桶,分区还可继续分区或分桶。

Hive数据存储模型-分区和分桶
分区:数据表可以按照某个字段的值划分分区。我们可以这么理解:将一个表的数据拆分出来放在不同的文件夹(目录)下。这样的话,分区的本质就是目录,分区数量也不固定,分区下可再有分区或者桶。
桶:数据可以根据桶的方式将不同数据放入不同的桶中。我们可以这么理解:一个表的数据拆分出来后肯定不是说直接放在文件夹下,而是放在文件中,至于这个文件是在根目录还是某个分区目录我们就不得而知了,我们称这个文件为桶。桶中基本的原理遵循数据结构中的桶排序,建表时可以指定桶个数,桶内可排序。数据按照某个字段的值Hash后放入某个桶中。
Hive数据存储模型-托管表和外部表
托管表:创建表若不指定表的类型即默认为托管表,Hive会将创建后的表移动到仓库目录。
外部表:若指定创建外部表,则Hive会到数据仓库目录以外的位置访问该表的数据。
说明:如果所有处理都有Hive完成,建议使用托管表。如果要用Hive和其他工具搭配使用来处理同一个数据集,建议使用外部表。
| 托管表 | 外部表 | |
|---|---|---|
| CREATE/LOAD | 数据移动仓库目录 | 数据位置不移动 |
| DROP | 元数据和数据会被一起删除 | 只删除元数据 |
Hive支持的函数


内置函数:
- 数学函数:如round(),floor(),abs(),rand()等
- 日期函数:如to_date(),month(),day()等
- 字符串函数:如trim(),length(),substr()等
用户自定义函数(UserDefinedFunction)
3.3 Hive基本操作
Hive使用
打开服务器
$HIVE_HOME/bin/hiveserver2
//通过beeline连接
$HIVE_HOME/bin/beeline -u jdbc:hive2://$HS2_HOST:$HS2_PORT
- 1
- 2
- 3
向其他大数据组件公开自己元数据
$HIVE_HOME/hcatalog/sbin/hcat_server.sh
- 1
从Hive发行版0.11.0及更高版本的shell中运行WebHCat服务器
$HIVE_HOME/hcatalog/sbin/webhhcar_server.sh
- 1
DDL操作
创建表
create table pokes(foo int,bar string);
//指定分区
create table invites(foo int,bar string) partitioned by (ds string);
- 1
- 2
- 3
浏览表
show tables
- 1
描述表
describe invites
- 1
修改表
alter table events rename to 3koobecaf;
alter table pokes add columns (new_col int)
- 1
- 2
DML操作
向表里加载数据
load datalocal inpath './exaples/files/kv1.txt' overwrite into table pokes;
load data local inpath './examples/files/kv2.txt' overwrite into table invites partition (ds='2008-08-15')
- 1
- 2
导入数据出HDFS
export table invites to '/department'
- 1
DQL操作
selects and filters
select a.foo from invites a where a.ds = '2008-08-15';
insert overwrite directory '/tmp/hdfs_out' select a.* from invires a where a.ds='2008-08-15';
- 1
- 2
group by
from invites a insert overwrite table events select a.bar,count(*) where a.foo > 0 group by a.bar;
insert overwrite table events select a.bar,count(*) from invites a where a.foo>0 group by a.bar;
- 1
- 2
多次插入
from src
insert overwrite table dest1 select src.* where src.key<100
insert overwrite table dest2 select src.key,src.value where src.key >= 100 and src.key<200;
- 1
- 2
- 3
多表联查
from pokes t1 join invites t2 on (t1.bar == t2.bar) insert overwrite table events select t1.bar,t1.foo,t2.foo;
- 1
文章来源: blog.csdn.net,作者:ArimaMisaki,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/chengyuhaomei520/article/details/126422500

- 点赞
- 收藏
- 关注作者
评论(0)