MRS HetuEngine体验跨源跨域分析【玩转华为云】

- 一 场景完整描述
- 二 登录环境并完成准备工作
- 三 体验HetuEngine hive查询性能
- 四 体验HetuEngine跨源,跨仓分析能力
- 五 体验HetuEngine跨湖分析能力

一 💡场景完整描述
1.1 首先说明下
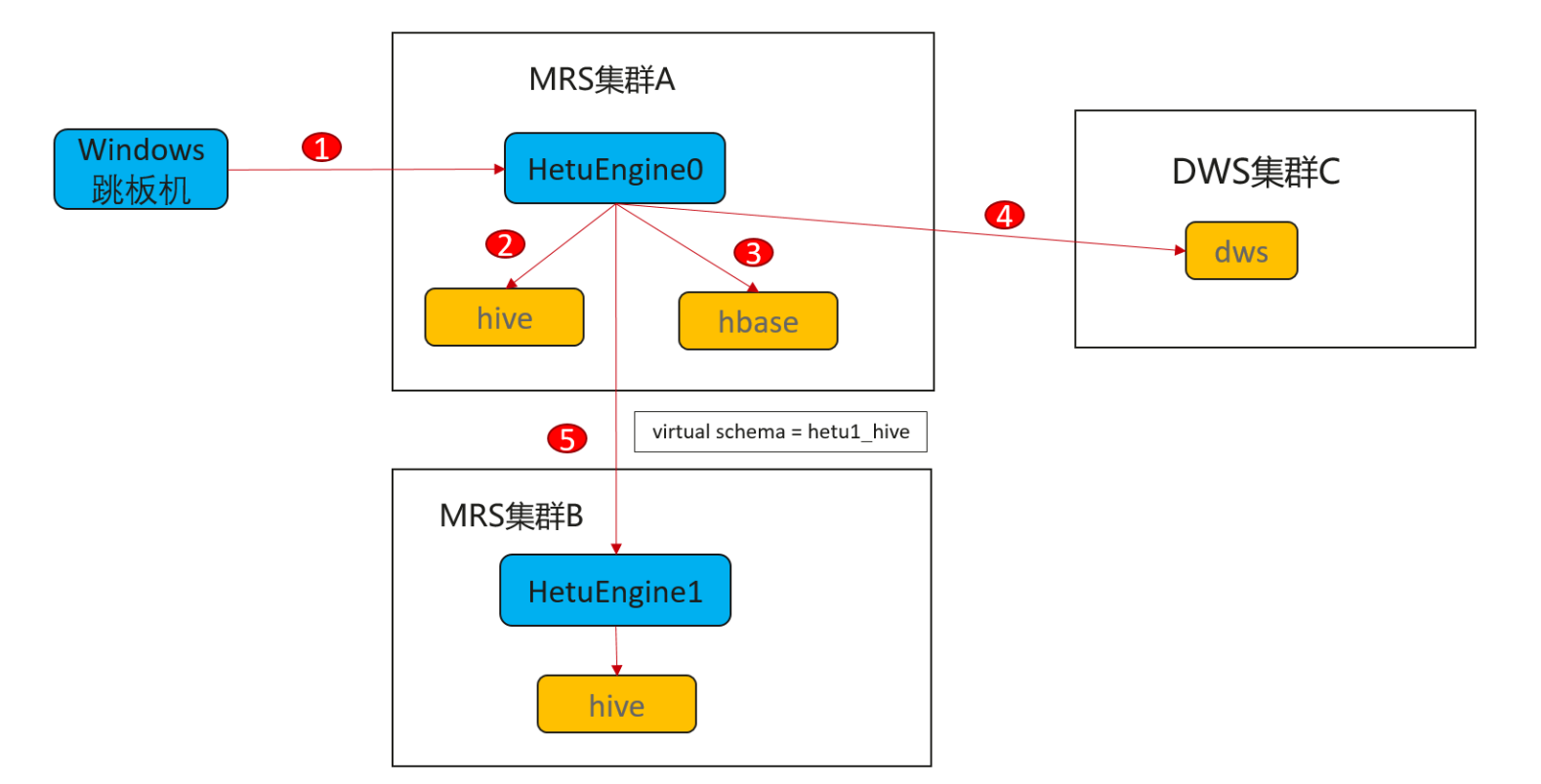
1)用户通过登录Windows跳板机,使用SQL开发工具DBeaver连接MRS集群A的HetuEngine进行分析体验
2)跨源分析体验,通过HetuEngine0连接集群内部数据源hive
3)跨源分析体验,通过HetuEngine0连接集群内部数据源hbase
4)跨仓分析体验,通过HetuEngine0连接关系型数据库DWS
5)跨湖分析体验,通过HetuEngine0连接到MRS集群B的HetuEngine1再连接到集群B的数据源hive
二 😘 登录环境并完成准备工作
2.1. 登录跳板机
登录:http://121.13.226.78:18080/ssh/#/
① 用户名:hdc01,
② 密码:请联系现场引导员获取
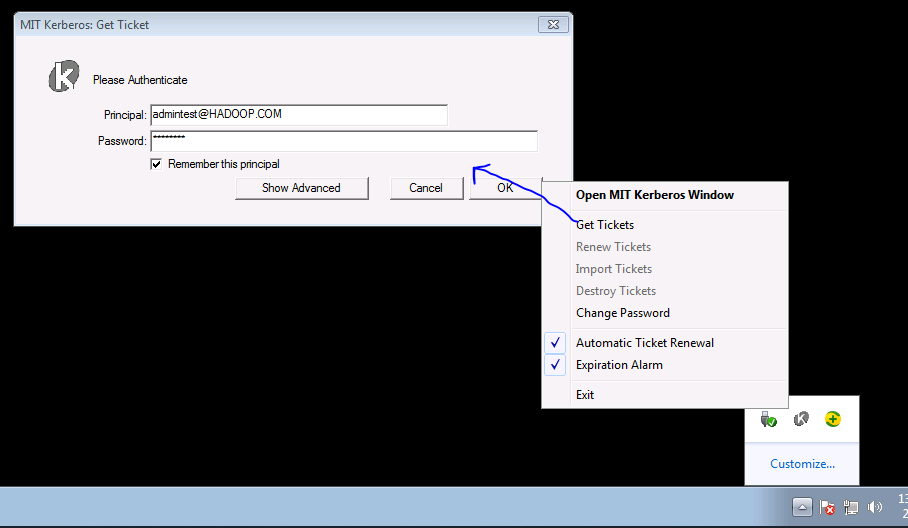
2.2 登录认证软件MIT Kerberos进行认证
点击右下角的MIT Kerberos,选择Get Tickets输入用户名密码获取Kerberos认证票据
① Principal:admintest@HADOOP.COM,
② Password: Admin12!
2.3 打开SQL编辑器软件DBeaver
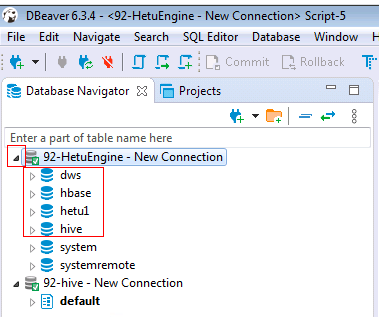
2.4 查看已配置好的MRS集群A的HetuEngine连接
点击三角符号打开已配置好的HetuEngine连接
说明:
① dws: 外部dws数据库
② hbase: MRS集群A中的hbase数据源
③ hetu1: 远端MRS集群B的HetuEngine
④ hive: MRS集群A中的hive数据源
三 🌈 体验HetuEngine hive查询性能提升
3.1 通过普通JDBC查询MRS集群A中的hive表
选择配置好的hive数据源92-hive - New Connection,右键选择SQL Editor
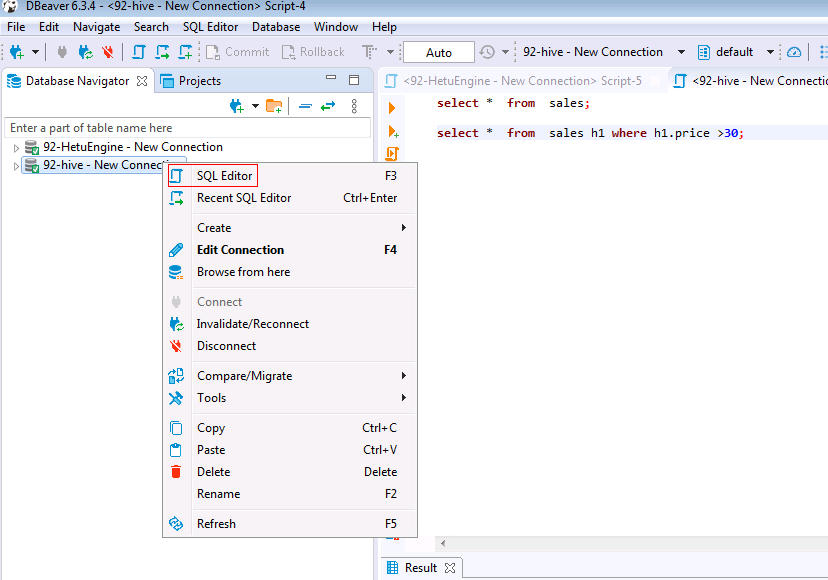
输入以下SQL语句并查看结果与时间
SELECT * FROM sales h1 WHERE h1.price >30;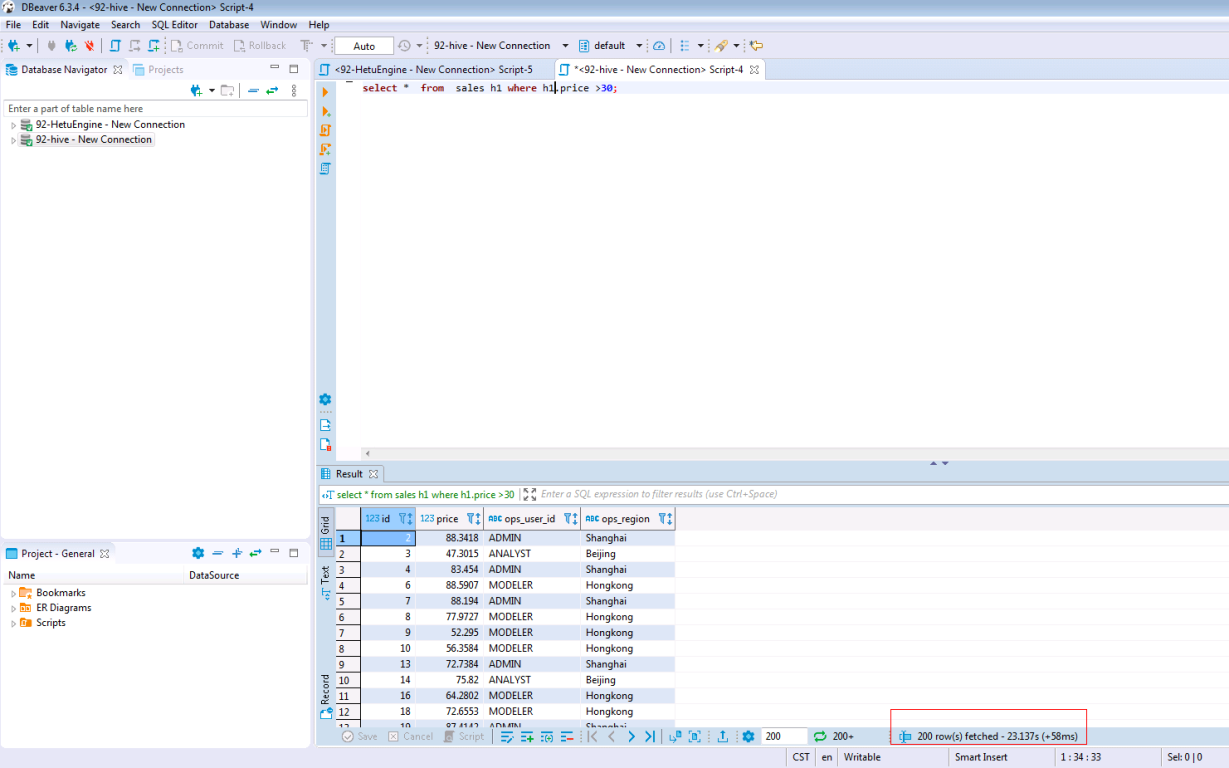
3.2. 通过HetuEngine查询MRS集群A中的hive表
选择配置好的hive数据源92-HetuEngine - New Connection,右键选择SQL Editor
输入以下的SQL语句并查看结果和时间
SELECT * FROM hive.default.sales h1 WHERE h1.price >30;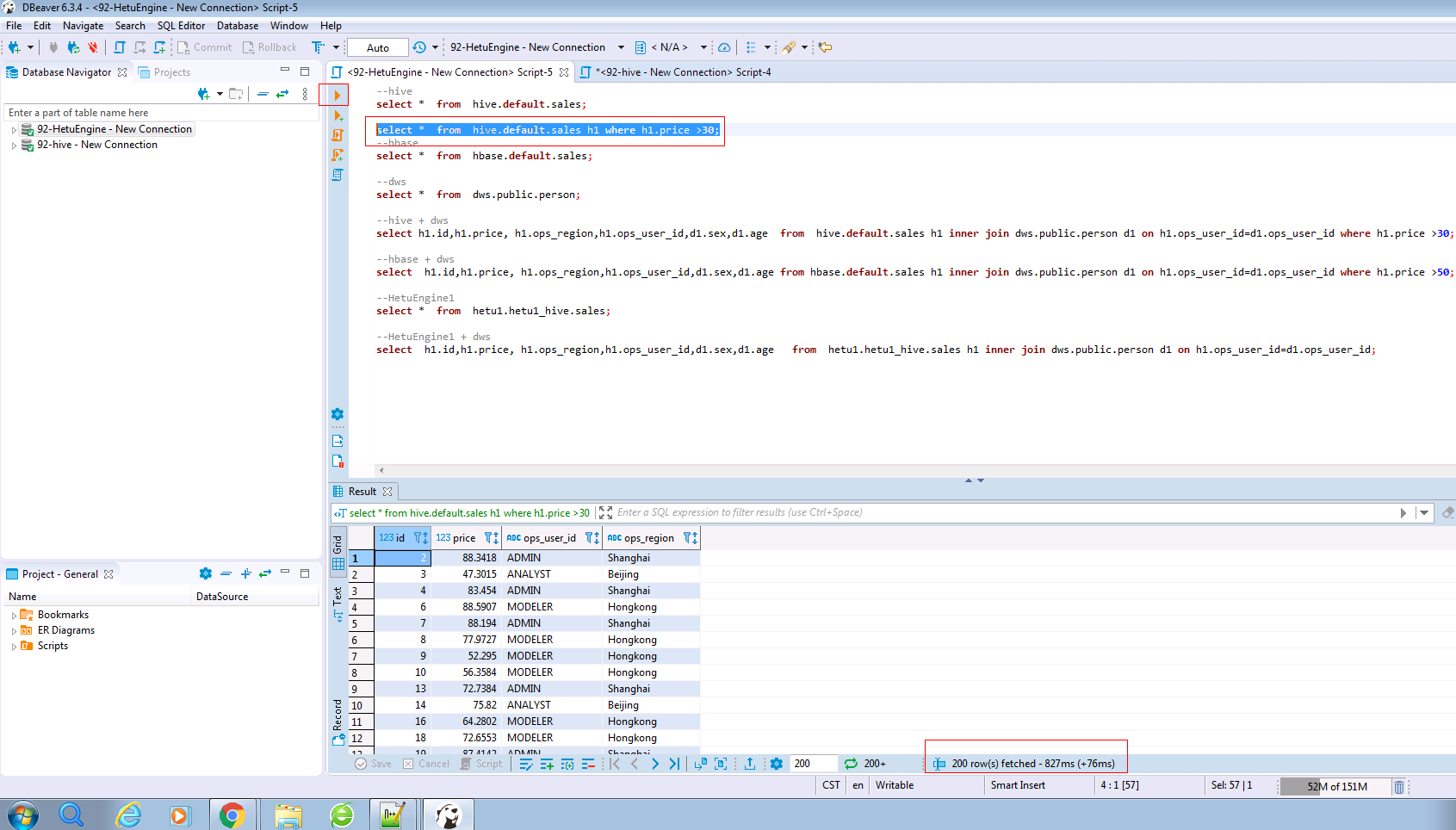
3.3. 结论
通过比较两次查询时间,可以看到HetuEngine会加速查询性能,比普通的hive查询更加快速;
四 🚀 体验HetuEngine跨源、跨仓分析能力
4.1 通过HetuEngine对MRS集群A中的HBase进行跨源数据查询
在打开的SQL Editor中输入如下SQL语句查询MRS集群A的HBase数据
SELECT * FROM hbase.default.sales;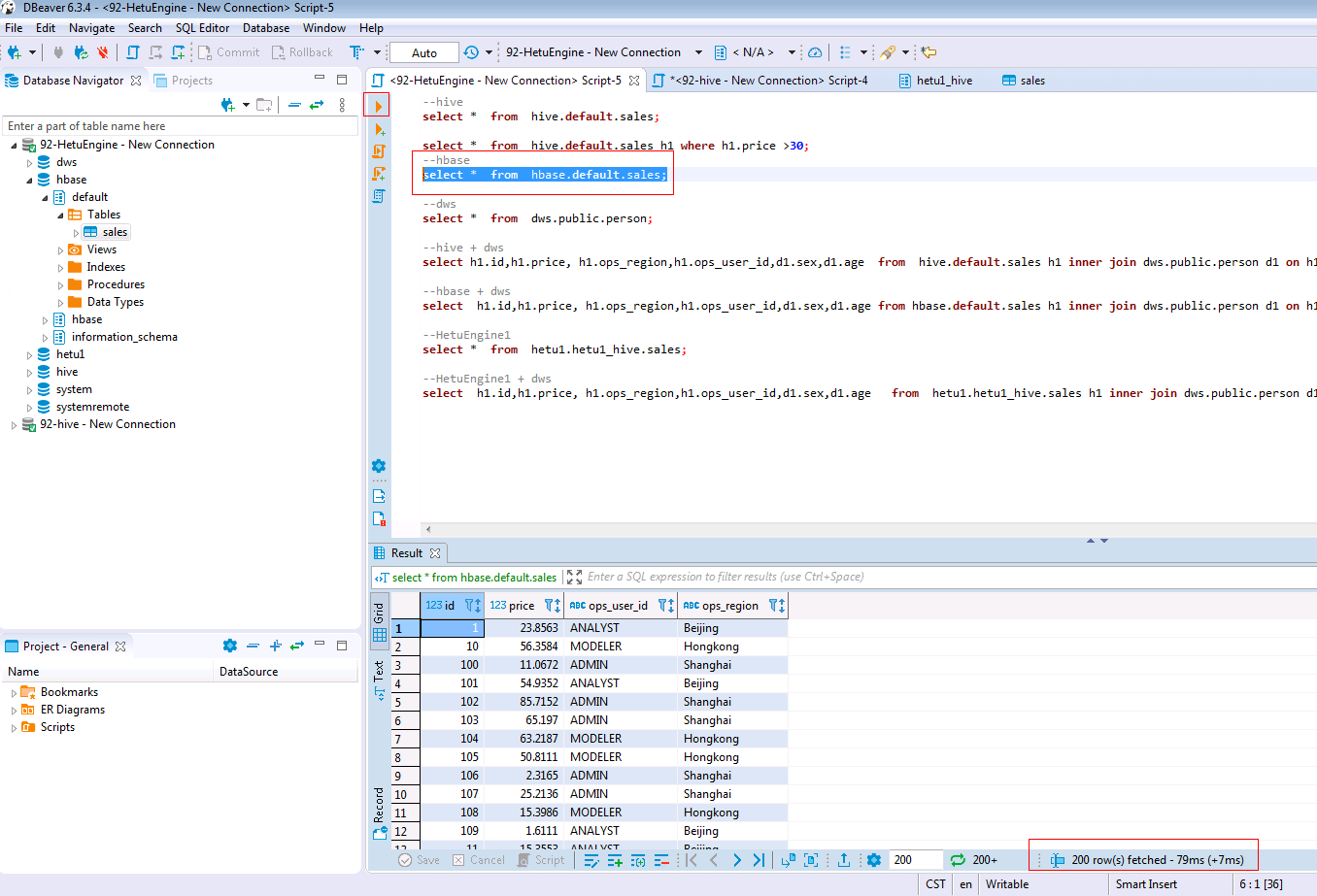
4.2 通过HetuEngine对DWS集群C进行跨仓数据查询
在打开的SQL Editor中输入如下SQL语句查询DWS集群C中的维表数据
SELECT * FROM dws.public.person;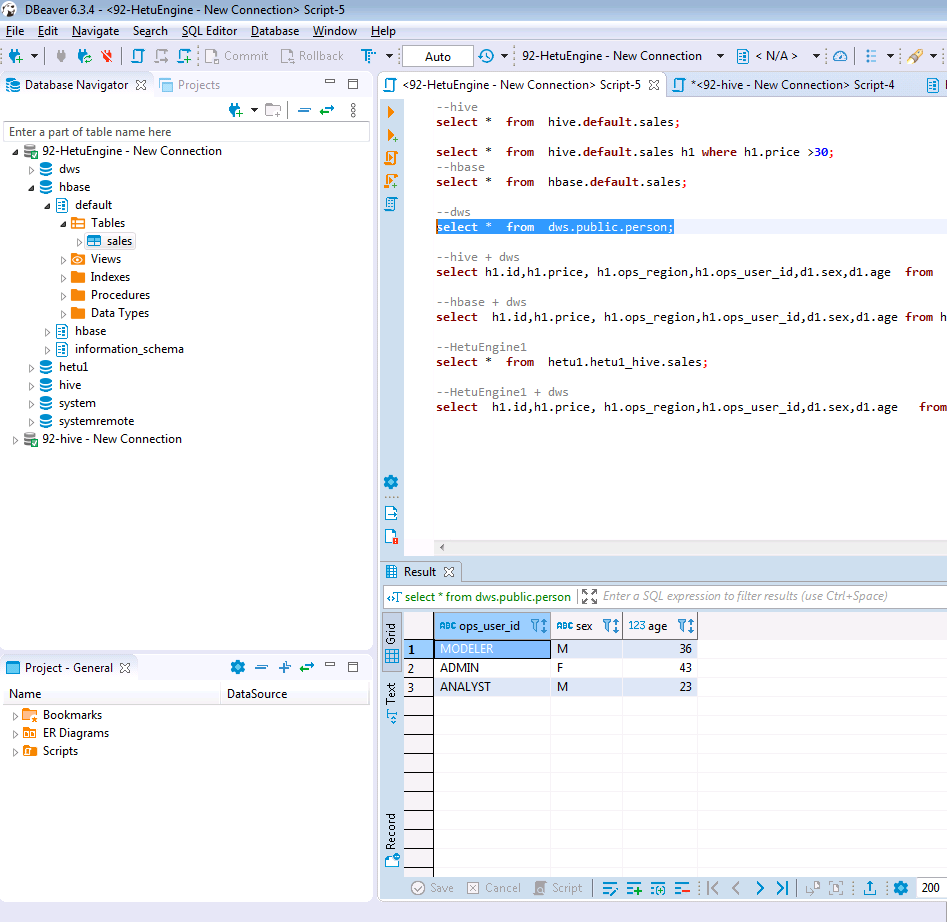
4.3. 体验MRS集群A的hive同DWS集群C跨仓分析查询
在打开的SQL Editor中输入如下SQL语句可做MRS集群A的hive与DWS集群C的跨仓数据分析
SELECT h1.id,h1.price, h1.ops_region,h1.ops_user_id,d1.sex,d1.age FROM hive.default.sales h1 INNER JOIN dws.public.person d1 ON h1.ops_user_id=d1.ops_user_id WHERE h1.price >30;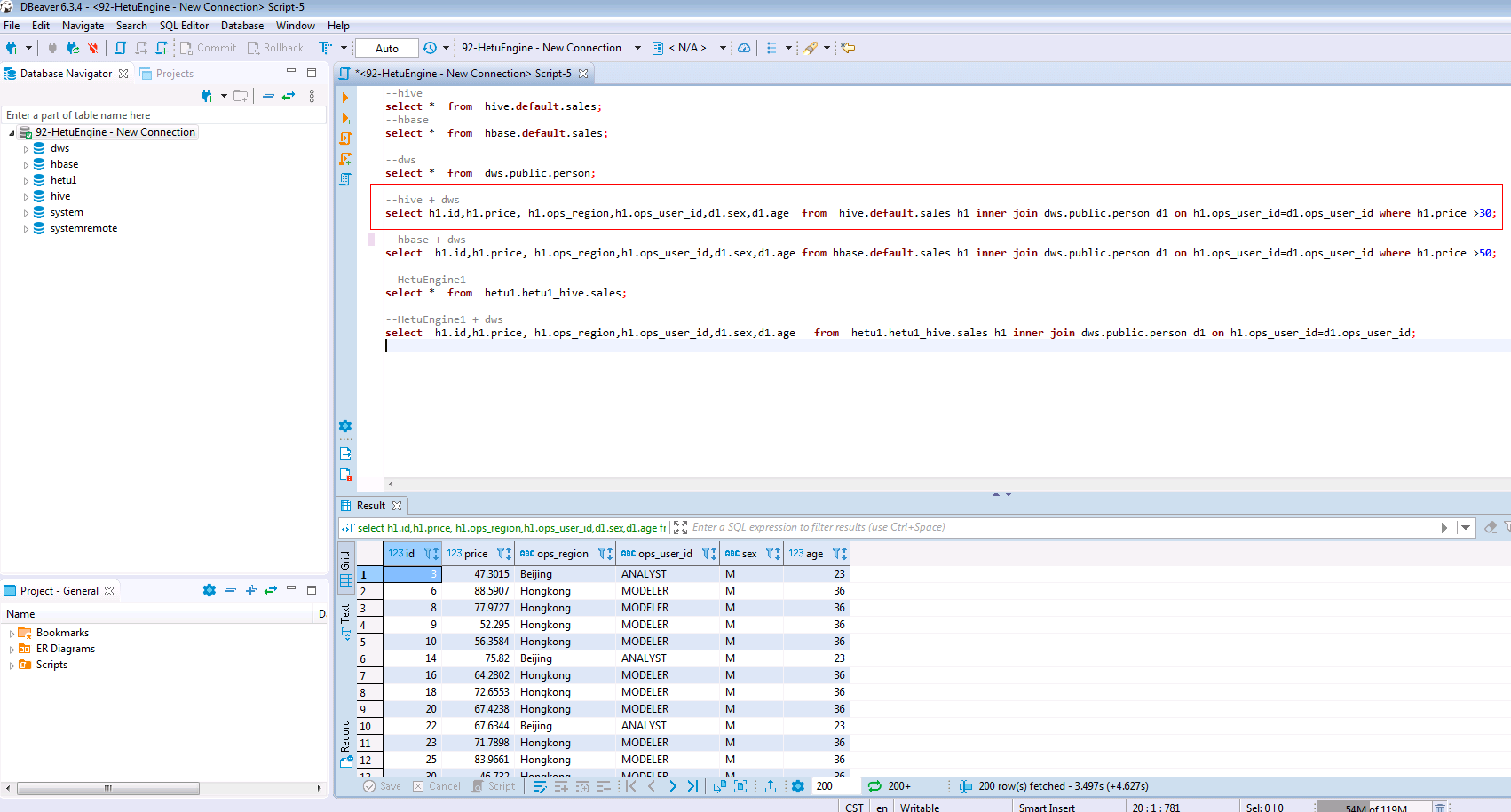
4.4 体验MRS集群A的hbase同DWS集群C跨仓分析查询
在打开的SQL Editor中输入如下SQL语句可做MRS集群A的hbase与DWS集群C的跨仓数据分析
SELECT h1.id,h1.price, h1.ops_region,h1.ops_user_id,d1.sex,d1.age FROM hbase.default.sales h1 INNER JOIN dws.public.person d1 ON h1.ops_user_id=d1.ops_user_id WHERE h1.price >50;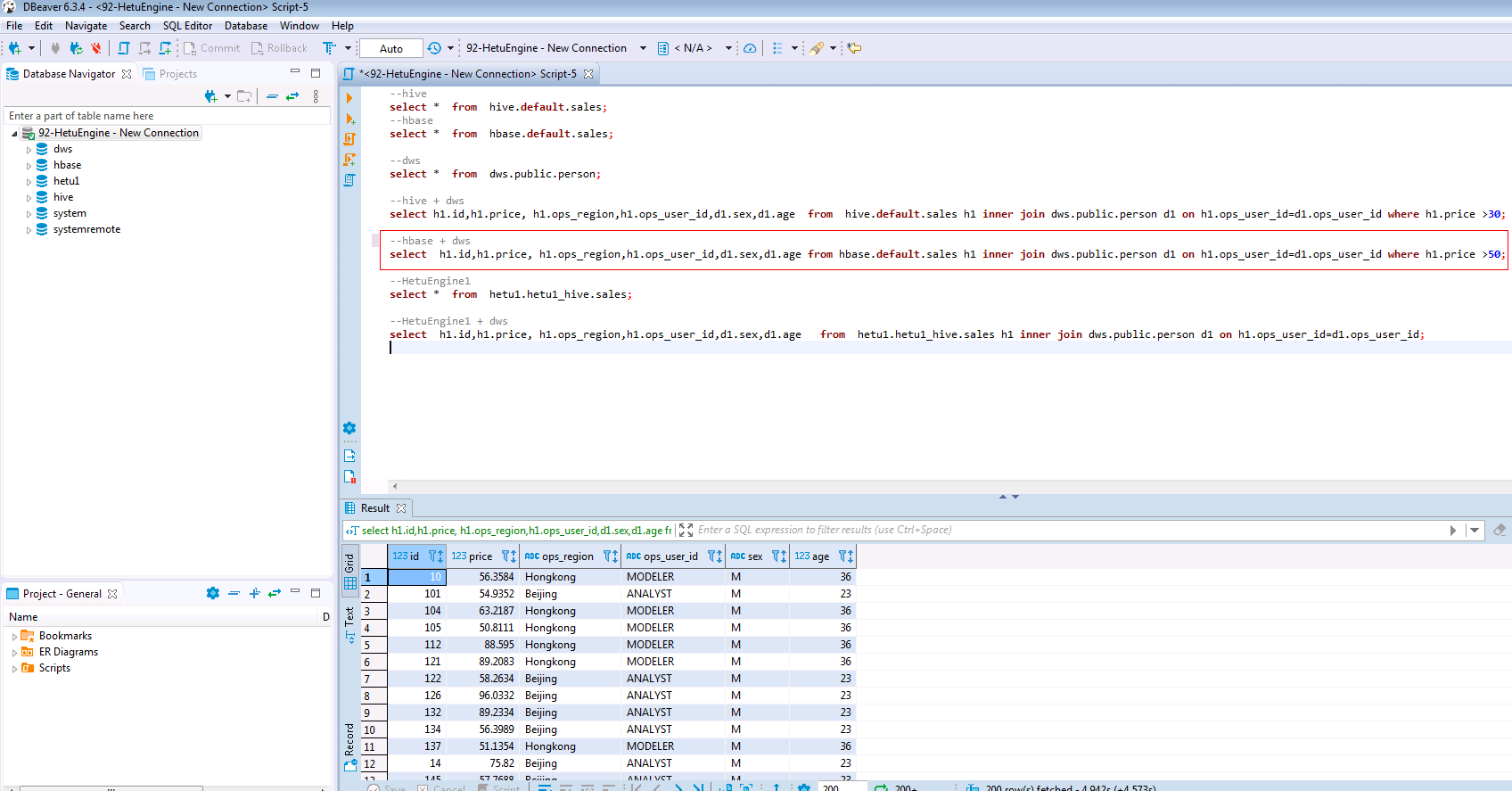
4.5 下结论
出于管理和信息收集的需要,企业内部会存储海量数据,包括数目众多的各种数据库、数据仓库等,此时会面临数据源种类繁多、数据集结构化混合、相关数据存放分散等困境,导致跨源查询开发成本高,跨源复杂查询耗时长。HetuEngine提供了统一标准SQL实现跨源协同分析,简化跨源分析操作;
五 🥩 体验HetuEngine跨湖分析能力
5.1 将MRS集群A的HetuEngine连接到MRS集群B的HetuEngine进行跨湖查询
在打开的SQL Editor中输入如下SQL语句可做MRS集群B中HetuEngine的hive跨湖查询
SELECT * FROM hetu1.hetu1_hive.sales;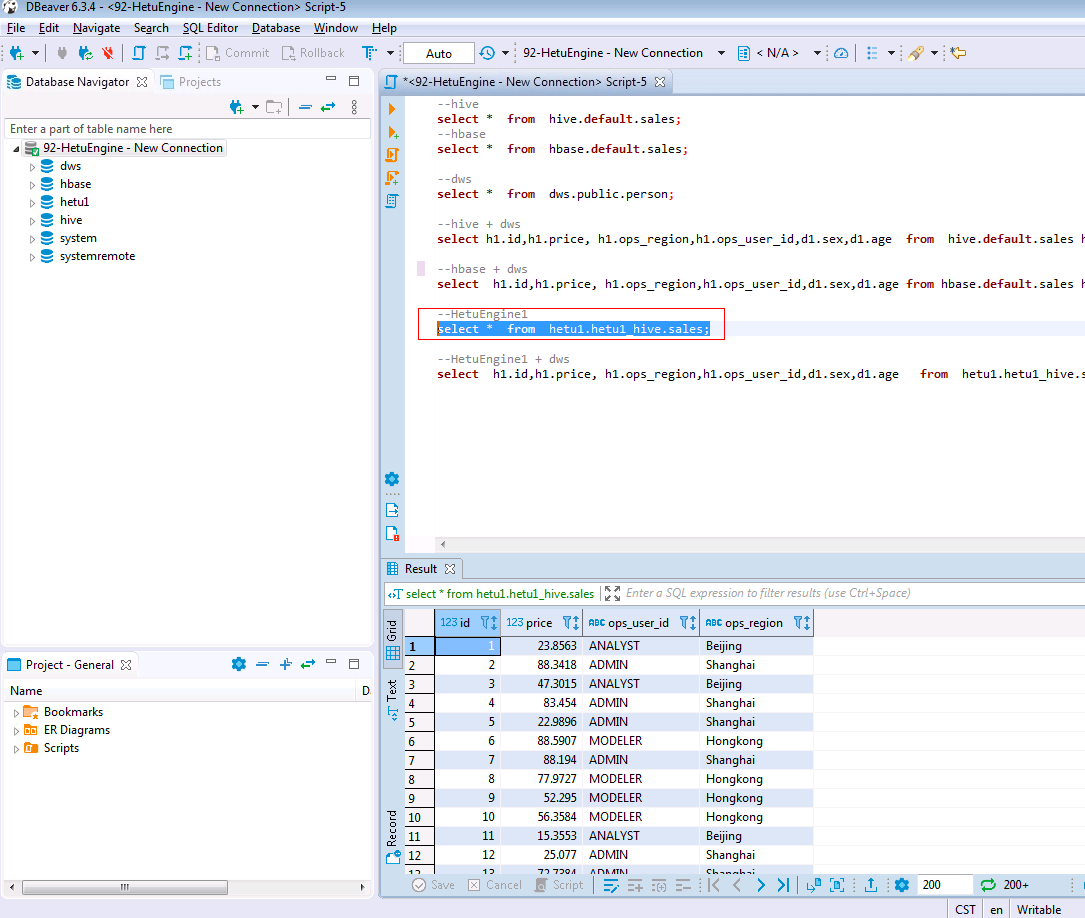
5.2 体验MRS集群B的HetuEngine同DWS集群C跨湖分析查询
打开SQL Editor输入如下SQL语句可做MRS集群B中HetuEngine的hive同DWS集群C的跨湖查询
SELECT h1.id,h1.price, h1.ops_region,h1.ops_user_id,d1.sex,d1.age FROM hetu1.hetu1_hive.sales h1 INNER JOIN dws.public.person d1 ON h1.ops_user_id=d1.ops_user_id;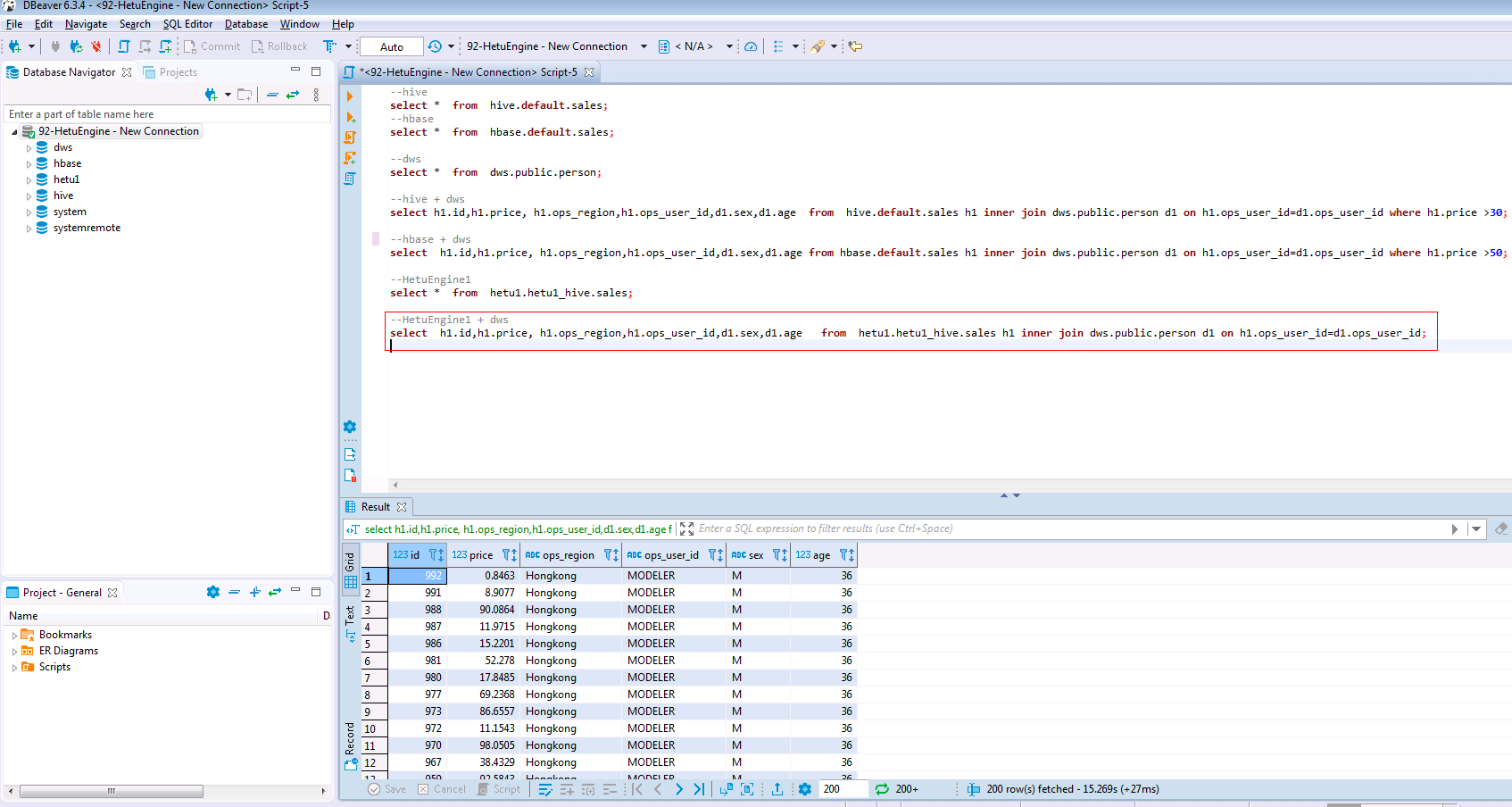
5.3 结论
HetuEngine提供统一标准SQL对分布于多个地域(或数据中心)的多种数据源实现高效访问,屏蔽数据在结构、存储及地域上的差异,实现数据与应用的解耦;

- 点赞
- 收藏
- 关注作者
评论(0)