spark实战之:分析维基百科网站统计数据(java版)

【摘要】 在《寻找海量数据集用于大数据开发实战(维基百科网站统计数据)》一文中,我们了解了如何获取维基百科网站的网页点击量统计数据,并且介绍了数据格式的基本内容,本文以这些数据进行实战,练习基本的spark开发
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
- 在《寻找海量数据集用于大数据开发实战(维基百科网站统计数据)》一文中,我们获取到维基百科网站的网页点击统计数据,也介绍了数据的格式和内容,今天就用这些数据来练习基本的spark开发,开发语言是Java;
实战环境信息
-
为了快速搭建spark集群环境,我是在docker下搭建的,您也可以选择用传统的方式来搭建,以下是参考文章:
-
如果您也打算用docker来搭建,请参考《docker下,极速搭建spark集群(含hdfs集群)》,本次实战用到的docker-compose.yml内容如下:
version: "2.2"
services:
namenode:
image: bde2020/hadoop-namenode:1.1.0-hadoop2.7.1-java8
container_name: namenode
volumes:
- ./hadoop/namenode:/hadoop/dfs/name
- ./input_files:/input_files
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
ports:
- 50070:50070
resourcemanager:
image: bde2020/hadoop-resourcemanager:1.1.0-hadoop2.7.1-java8
container_name: resourcemanager
depends_on:
- namenode
- datanode1
- datanode2
env_file:
- ./hadoop.env
historyserver:
image: bde2020/hadoop-historyserver:1.1.0-hadoop2.7.1-java8
container_name: historyserver
depends_on:
- namenode
- datanode1
- datanode2
volumes:
- ./hadoop/historyserver:/hadoop/yarn/timeline
env_file:
- ./hadoop.env
nodemanager1:
image: bde2020/hadoop-nodemanager:1.1.0-hadoop2.7.1-java8
container_name: nodemanager1
depends_on:
- namenode
- datanode1
- datanode2
env_file:
- ./hadoop.env
datanode1:
image: bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8
container_name: datanode1
depends_on:
- namenode
volumes:
- ./hadoop/datanode1:/hadoop/dfs/data
env_file:
- ./hadoop.env
datanode2:
image: bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8
container_name: datanode2
depends_on:
- namenode
volumes:
- ./hadoop/datanode2:/hadoop/dfs/data
env_file:
- ./hadoop.env
datanode3:
image: bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8
container_name: datanode3
depends_on:
- namenode
volumes:
- ./hadoop/datanode3:/hadoop/dfs/data
env_file:
- ./hadoop.env
master:
image: gettyimages/spark:2.3.0-hadoop-2.8
container_name: master
command: bin/spark-class org.apache.spark.deploy.master.Master -h master
hostname: master
environment:
MASTER: spark://master:7077
SPARK_CONF_DIR: /conf
SPARK_PUBLIC_DNS: localhost
links:
- namenode
expose:
- 7001
- 7002
- 7003
- 7004
- 7005
- 7077
- 6066
ports:
- 4040:4040
- 6066:6066
- 7077:7077
- 8080:8080
volumes:
- ./conf/master:/conf
- ./data:/tmp/data
- ./jars:/root/jars
worker1:
image: gettyimages/spark:2.3.0-hadoop-2.8
container_name: worker1
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
hostname: worker1
environment:
SPARK_CONF_DIR: /conf
SPARK_WORKER_CORES: 2
SPARK_WORKER_MEMORY: 2g
SPARK_WORKER_PORT: 8881
SPARK_WORKER_WEBUI_PORT: 8081
SPARK_PUBLIC_DNS: localhost
links:
- master
expose:
- 7012
- 7013
- 7014
- 7015
- 8881
volumes:
- ./conf/worker1:/conf
- ./data/worker1:/tmp/data
worker2:
image: gettyimages/spark:2.3.0-hadoop-2.8
container_name: worker2
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
hostname: worker2
environment:
SPARK_CONF_DIR: /conf
SPARK_WORKER_CORES: 2
SPARK_WORKER_MEMORY: 2g
SPARK_WORKER_PORT: 8881
SPARK_WORKER_WEBUI_PORT: 8081
SPARK_PUBLIC_DNS: localhost
links:
- master
expose:
- 7012
- 7013
- 7014
- 7015
- 8881
volumes:
- ./conf/worker2:/conf
- ./data/worker2:/tmp/data
worker3:
image: gettyimages/spark:2.3.0-hadoop-2.8
container_name: worker3
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
hostname: worker3
environment:
SPARK_CONF_DIR: /conf
SPARK_WORKER_CORES: 2
SPARK_WORKER_MEMORY: 2g
SPARK_WORKER_PORT: 8881
SPARK_WORKER_WEBUI_PORT: 8081
SPARK_PUBLIC_DNS: localhost
links:
- master
expose:
- 7012
- 7013
- 7014
- 7015
- 8881
volumes:
- ./conf/worker3:/conf
- ./data/worker3:/tmp/data
worker4:
image: gettyimages/spark:2.3.0-hadoop-2.8
container_name: worker4
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
hostname: worker4
environment:
SPARK_CONF_DIR: /conf
SPARK_WORKER_CORES: 2
SPARK_WORKER_MEMORY: 2g
SPARK_WORKER_PORT: 8881
SPARK_WORKER_WEBUI_PORT: 8081
SPARK_PUBLIC_DNS: localhost
links:
- master
expose:
- 7012
- 7013
- 7014
- 7015
- 8881
volumes:
- ./conf/worker4:/conf
- ./data/worker4:/tmp/data
worker5:
image: gettyimages/spark:2.3.0-hadoop-2.8
container_name: worker5
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
hostname: worker5
environment:
SPARK_CONF_DIR: /conf
SPARK_WORKER_CORES: 2
SPARK_WORKER_MEMORY: 2g
SPARK_WORKER_PORT: 8881
SPARK_WORKER_WEBUI_PORT: 8081
SPARK_PUBLIC_DNS: localhost
links:
- master
expose:
- 7012
- 7013
- 7014
- 7015
- 8881
volumes:
- ./conf/worker5:/conf
- ./data/worker5:/tmp/data
worker6:
image: gettyimages/spark:2.3.0-hadoop-2.8
container_name: worker6
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
hostname: worker6
environment:
SPARK_CONF_DIR: /conf
SPARK_WORKER_CORES: 2
SPARK_WORKER_MEMORY: 2g
SPARK_WORKER_PORT: 8881
SPARK_WORKER_WEBUI_PORT: 8081
SPARK_PUBLIC_DNS: localhost
links:
- master
expose:
- 7012
- 7013
- 7014
- 7015
- 8881
volumes:
- ./conf/worker6:/conf
- ./data/worker6:/tmp/data
-
如果您打算基于传统方式搭建,请参考《部署spark2.2集群(standalone模式)》;
-
sprak环境的基本情况如下所示:

-
以下是本次实战涉及的版本号:

- 操作系统:CentOS7
- hadoop:2.8
- spark:2.3
- docker:17.03.2-ce
- docker-compose:1.23.2
维基百科网站统计数据简介
- 先回顾一下维基百科网站统计数据的内容和格式,一行数据的内容如下所示:
aa.b User_talk:Sevela.p 1 5786
这一行由空格字符分割成了四个字段:
| 内容 | 意义 |
|---|---|
| aa.b | 项目名称,".b"表示wikibooks |
| User_talk:Sevela.p | 网页的三级目录 |
| 1 | 一小时内的访问次数 |
| 5786 | 一小时内被请求的字节总数 |
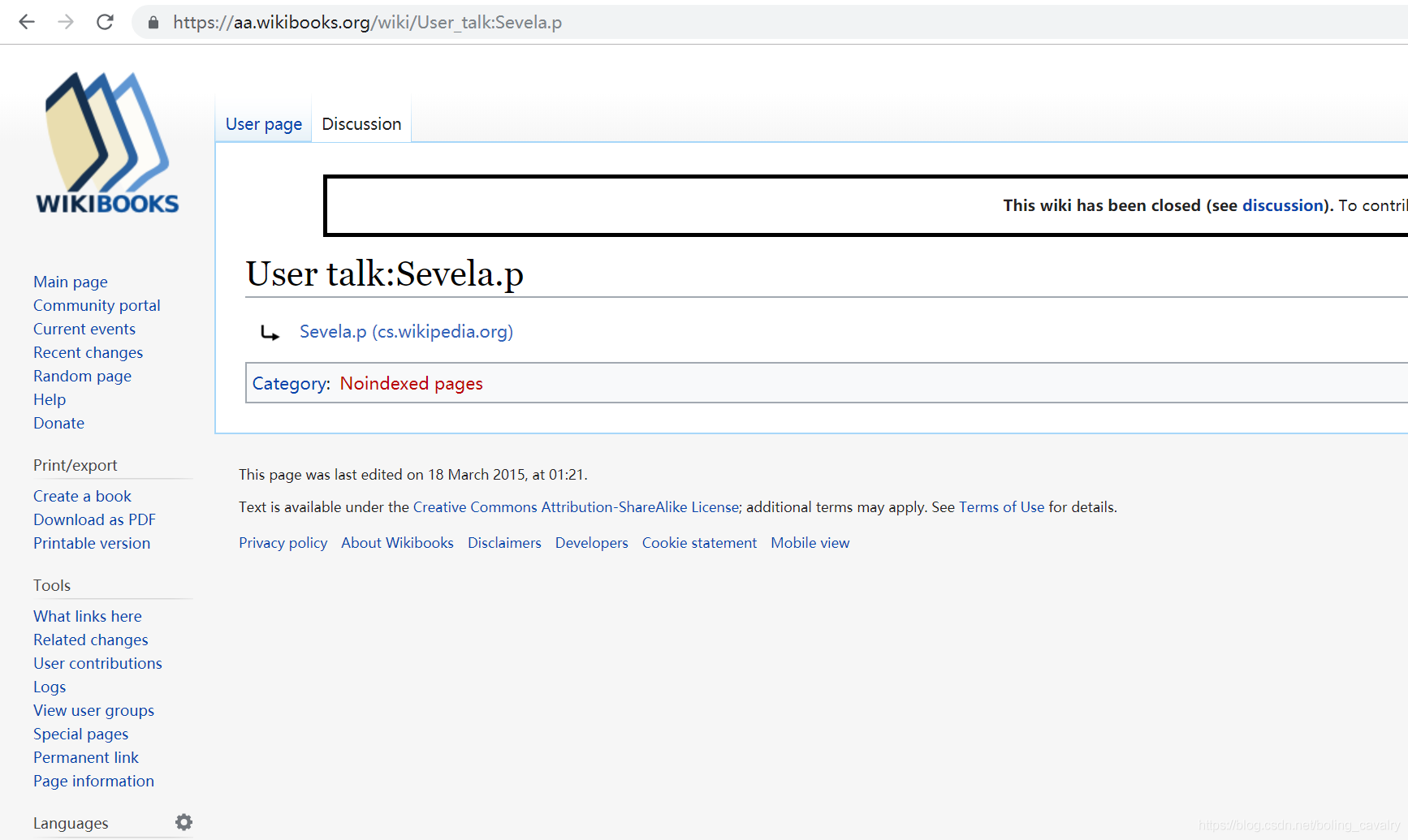
- 上述内容可以还原为一个网址,如下图所示,对应的URL为:https://aa.wikibooks.org/wiki/User_talk:Sevela.p
实战功能简介
- 本次实战开发的spark应用的功能,是对网站统计数据进行排名,找出访问量最高的前100地址,在控制台打印出来并保存到hdsf;
源码下载
- 接下来详细讲述应用的编码过程,如果您不想自己写代码,也可以在GitHub下载完整的应用源码,地址和链接信息如下表所示:
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
- 这个git项目中有多个文件夹,本章源码在sparkdemo这个文件夹下,如下图红框所示:

详细开发
- 基于maven创建工程,pom.xml如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.bolingcavalry</groupId>
<artifactId>sparkdemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.2</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/test/java</testSourceDirectory>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.2.1</version>
<executions>
<execution>
<goals>
<goal>exec</goal>
</goals>
</execution>
</executions>
<configuration>
<executable>java</executable>
<includeProjectDependencies>false</includeProjectDependencies>
<includePluginDependencies>false</includePluginDependencies>
<classpathScope>compile</classpathScope>
<mainClass>com.bolingcavalry.sparkdemo.app.WikiRank</mainClass>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
- 创建一个数据结构类PageInfo,在运行过程中会用到,里面记录了业务所需的字段:
package com.bolingcavalry.sparkdemo.bean;
import java.io.Serializable;
import java.util.LinkedList;
import java.util.List;
/**
* @Description: 数据结构类
* @author: willzhao E-mail: zq2599@gmail.com
* @date: 2019/2/10 15:33
*/
public class PageInfo implements Serializable {
/**
* 还原的url地址
*/
private String url;
/**
* urldecode之后的三级域名
*/
private String name;
/**
* 该三级域名的请求次数
*/
private int requestTimes;
/**
* 该地址被请求的字节总数
*/
private long requestLength;
/**
* 对应的原始字段
*/
private List<String> raws = new LinkedList<>();
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getRequestTimes() {
return requestTimes;
}
public void setRequestTimes(int requestTimes) {
this.requestTimes = requestTimes;
}
public long getRequestLength() {
return requestLength;
}
public void setRequestLength(long requestLength) {
this.requestLength = requestLength;
}
public List<String> getRaws() {
return raws;
}
public void setRaws(List<String> raws) {
this.raws = raws;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}
- 对于前面提到的例子,“aa.b User_talk:Sevela.p 1 5786"对应的网址是"https://aa.wikibooks.org/wiki/User_talk:Sevela.p”,这个转换逻辑被做成了一个静态方法,这样就能把每一行记录对应的地址还原出来了,如下所示:
package com.bolingcavalry.sparkdemo.util;
import org.apache.commons.lang3.StringUtils;
/**
* @Description: 常用的静态工具放置在此
* @author: willzhao E-mail: zq2599@gmail.com
* @date: 2019/2/16 9:01
*/
public class Tools {
/**
* 域名的格式化模板
*/
private static final String URL_TEMPALTE = "https://%s/wiki/%s";
/**
* 根据项目名称和三级域名还原完整url,
* 还原逻辑来自:https://wikitech.wikimedia.org/wiki/Analytics/Archive/Data/Pagecounts-raw
* @param project
* @param thirdLvPath
* @return
*/
public static String getUrl(String project, String thirdLvPath){
//如果入参不合法,就返回固定格式的错误提示
if(StringUtils.isBlank(project) || StringUtils.isBlank(thirdLvPath)){
return "1. invalid param (" + project + ")(" + thirdLvPath + ")";
}
//检查project中是否有"."
int dotOffset = project.indexOf('.');
//如果没有".",就用project+".wikipedia.org"作为一级域名
if(dotOffset<0){
return String.format(URL_TEMPALTE,
project + ".wikipedia.org",
thirdLvPath);
}
//如果有".",就用"."之后的字符串按照不同的逻辑转换
String code = project.substring(dotOffset);
//".mw"属于移动端网页,统计的逻辑略微复杂,详情参考网页链接,这里不作处理直接返回固定信息
if(".mw".equals(code)){
return "mw page (" + project + ")(" + thirdLvPath + ")";
}
String firstLvPath = null;
//就用"."之后的字符串按照不同的逻辑转换
switch(code){
case ".b":
firstLvPath = ".wikibooks.org";
break;
case ".d":
firstLvPath = ".wiktionary.org";
break;
case ".f":
firstLvPath = ".wikimediafoundation.org";
break;
case ".m":
firstLvPath = ".wikimedia.org";
break;
case ".n":
firstLvPath = ".wikinews.org";
break;
case ".q":
firstLvPath = ".wikiquote.org";
break;
case ".s":
firstLvPath = ".wikisource.org";
break;
case ".v":
firstLvPath = ".wikiversity.org";
break;
case ".voy":
firstLvPath = ".wikivoyage.org";
break;
case ".w":
firstLvPath = ".mediawiki.org";
break;
case ".wd":
firstLvPath = ".wikidata.org";
break;
}
if(null==firstLvPath){
return "2. invalid param (" + project + ")(" + thirdLvPath + ")";
}
//还原地址
return String.format(URL_TEMPALTE,
project.substring(0, dotOffset) + firstLvPath,
thirdLvPath);
}
public static void main(String[] args){
String str = "abc.123456";
System.out.println(str.substring(str.indexOf('.')));
}
}
- 接下来是spark应用的源码,主要是创建PageInfo对象,以及map、reduce、排序等逻辑,代码中已有注释说明,就不再赘述:
package com.bolingcavalry.sparkdemo.app;
import com.bolingcavalry.sparkdemo.bean.PageInfo;
import com.bolingcavalry.sparkdemo.util.Tools;
import org.apache.commons.lang3.StringUtils;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import scala.Tuple2;
import java.net.URLDecoder;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.List;
/**
* @Description: 根据wiki的统计来查找最高访问量的文章
* @author: willzhao E-mail: zq2599@gmail.com
* @date: 2019/2/8 17:21
*/
public class WikiRank {
private static final Logger logger = LoggerFactory.getLogger(WikiRank.class);
private static final int TOP = 100;
public static void main(String[] args) {
if(null==args
|| args.length<2
|| StringUtils.isEmpty(args[0])
|| StringUtils.isEmpty(args[1])) {
logger.error("invalid params!");
}
String hdfsHost = args[0];
String hdfsPort = args[1];
SparkConf sparkConf = new SparkConf().setAppName("Spark WordCount Application (java)");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
String hdfsBasePath = "hdfs://" + hdfsHost + ":" + hdfsPort;
//文本文件的hdfs路径
String inputPath = hdfsBasePath + "/input/*";
//输出结果文件的hdfs路径
String outputPath = hdfsBasePath + "/output/"
+ new SimpleDateFormat("yyyyMMddHHmmss").format(new Date());
logger.info("input path : {}", inputPath);
logger.info("output path : {}", outputPath);
logger.info("import text");
//导入文件
JavaRDD<String> textFile = javaSparkContext.textFile(inputPath);
logger.info("do map operation");
JavaPairRDD<String, PageInfo> counts = textFile
//过滤掉无效的数据
.filter((Function<String, Boolean>) v1 -> {
if(StringUtils.isBlank(v1)){
return false;
}
//分割为数组
String[] array = v1.split(" ");
/**
* 以下情况都要过滤掉
* 1. 名称无效(array[1])
* 2. 请求次数无效(array[2)
* 3. 请求总字节数无效(array[3)
*/
if(null==array
|| array.length<4
|| StringUtils.isBlank(array[1])
|| !StringUtils.isNumeric(array[2])
|| !StringUtils.isNumeric(array[3])){
logger.error("find invalid data [{}]", v1);
return false;
}
return true;
})
//将每一行转成一个PageInfo对象
.map((Function<String, PageInfo>) v1 -> {
String[] array = v1.split(" ");
PageInfo pageInfo = new PageInfo();
try {
pageInfo.setName(URLDecoder.decode(array[1], "UTF-8"));
}catch (Exception e){
//有的字符串没有做过urlencode,此时做urldecode可能抛出异常(例如abc%),此时用原来的内容作为name即可
pageInfo.setName(array[1]);
}
pageInfo.setUrl(Tools.getUrl(array[0], array[1]));
pageInfo.setRequestTimes(Integer.valueOf(array[2]));
pageInfo.setRequestLength(Long.valueOf(array[3]));
pageInfo.getRaws().add(v1);
return pageInfo;
})
//转成键值对,键是url,值是PageInfo对象
.mapToPair(pageInfo -> new Tuple2<>(pageInfo.getUrl(), pageInfo))
//按照url做reduce,将请求次数累加
.reduceByKey((Function2<PageInfo, PageInfo, PageInfo>) (v1, v2) -> {
v2.setRequestTimes(v2.getRequestTimes() + v1.getRequestTimes());
v2.getRaws().addAll(v1.getRaws());
return v2;
});
logger.info("do convert");
//先将key和value倒过来,再按照key排序
JavaPairRDD<Integer, PageInfo> sorts = counts
//key和value颠倒,生成新的map
.mapToPair(tuple2 -> new Tuple2<>(tuple2._2().getRequestTimes(), tuple2._2()))
//按照key倒排序
.sortByKey(false);
logger.info("take top " + TOP);
//取前10个
List<Tuple2<Integer, PageInfo>> top = sorts.take(TOP);
StringBuilder sbud = new StringBuilder("top "+ top + " word :\n");
//打印出来
for(Tuple2<Integer, PageInfo> tuple2 : top){
sbud.append(tuple2._2().getName())
.append("\t")
.append(tuple2._1())
.append("\n");
}
logger.info(sbud.toString());
logger.info("merge and save as file");
//分区合并成一个,再导出为一个txt保存在hdfs
javaSparkContext
.parallelize(top)
.coalesce(1)
.map(
tuple2 -> new Tuple2<>(tuple2._2().getRequestTimes(), tuple2._2().getName() + " ### " + tuple2._2().getUrl() +" ### " + tuple2._2().getRaws().toString())
)
.saveAsTextFile(outputPath);
logger.info("close context");
//关闭context
javaSparkContext.close();
}
}
- 编码完成后,在pom.xml所在目录下编译构建jar包:
mvn clean package -Dmaven.test.skip=true
- 编译成功后,target目录下的sparkdemo-1.0-SNAPSHOT.jar就是应用jar包;
- 将sparkdemo-1.0-SNAPSHOT.jar提交到spark服务器上,我这里用的是docker环境,通过文件夹映射将容器的目录和宿主机目录对应起来,只要将文件放入宿主机的jars目录即可,您需要按照自己的实际情况上传;
提交任务
- 当前电脑上,维基百科网站的统计数据文件保存在目录/input_files/input
- 将维基百科网站的统计数据文件提交到hdfs,我这边用的是docker环境,提交命令如下:
docker exec namenode hdfs dfs -put /input_files/input /
-
提交成功后,在hdfs的web页面可见/input目录下的数据,如下:
-
将jar文件上传到spark服务再提交任务,我用的是docker环境,命令如下:

docker exec -it master spark-submit \
--class com.bolingcavalry.sparkdemo.app.WikiRank \
--executor-memory 1g \
--total-executor-cores 12 \
/root/jars/sparkdemo-1.0-SNAPSHOT.jar \
namenode \
8020
-
上述命令调动了12个executor,每个内存为1G,请您按照自己环境的实际情况来配置;
-
由于本次要处理的文件较多(24个128兆的文件),因此耗时较长,需要耐心等待,您也可以减少上传文件数量来缩减处理时间,以下是web页面显示的处理情况:
-
处理完成后,在控制台会打印简单的排名信息:

en 111840450
Main_Page 61148163
ja 20336203
es 18133852
Заглавная_страница 16997475
de 12537288
ru 10127971
fr 9296777
it 9011481
pt 5904807
id 3472100
tr 3089611
pl 3051718
ar 3023412
nl 2372696
zh 1987233
sv 1845525
fa 1687804
ko 1511408
commons 1138613
fi 1123291
th 1012375
vi 1007987
he 822433
Wikipedia:Hauptseite 767106
cs 750085
hu 687040
Wikipédia:Accueil_principal 597885
da 512714
no 507885
Special:Search 493995
ro 488945
uk 419609
Special:NewItem 414436
hi 399883
Antoninus_Pius 345542
el 342715
Hoofdpagina 287517
tl 274145
bg 252691
Wikipedia:Portada 250932
Liste_des_automobiles_Ferrari 237985
hr 228896
メインページ 227591
Начална_страница 220605
Okto 211002
Proyecto_40 207534
- 也可以去hdfs查看更详细的输出内容,先查找到输出文件所在目录:
root@willzhao-deepin:~# docker exec namenode hdfs dfs -ls /output/
Found 3 items
drwxr-xr-x - root supergroup 0 2019-02-16 00:53 /output/20190216005136
drwxr-xr-x - root supergroup 0 2019-02-16 01:50 /output/20190216014759
drwxr-xr-x - root supergroup 0 2019-02-16 02:41 /output/20190216021144
root@willzhao-deepin:~# docker exec namenode hdfs dfs -ls /output/20190216021144
Found 2 items
-rw-r--r-- 3 root supergroup 0 2019-02-16 02:41 /output/20190216021144/_SUCCESS
-rw-r--r-- 3 root supergroup 105181 2019-02-16 02:41 /output/20190216021144/part-00000
-
可见输出文件为/output/20190216021144/part-00000
-
用cat命令查看输出文件内容,以下是部分内容:
(63364,2016_Summer_Olympics ### https://en.wikipedia.org/wiki/2016_Summer_Olympics ### [en 2016_Summer_Olympics 3396 274589952, en 2016_Summer_Olympics 3015 252640325, en 2016_Summer_Olympics 3136 260875102, en 2016_Summer_Olympics 3094 257683527, en 2016_Summer_Olympics 2302 189633601, en 2016_Summer_Olympics 2532 211137547, en 2016_Summer_Olympics 2073 174153850, en 2016_Summer_Olympics 2425 201808231, en 2016_Summer_Olympics 2869 244961273, en 2016_Summer_Olympics 2647 227408637, en 2016_Summer_Olympics 3173 276779678, en 2016_Summer_Olympics 3242 261206575, en 2016_Summer_Olympics 1871 168316209, en 2016_Summer_Olympics 2234 204588727, en 2016_Summer_Olympics 2857 239335148, en 2016_Summer_Olympics 2345 197360752, en 2016_Summer_Olympics 2949 248777317, en 2016_Summer_Olympics 2040 171690687, en 2016_Summer_Olympics 4006 332402716, en 2016_Summer_Olympics 3137 274672915, en 2016_Summer_Olympics 1895 156985346, en 2016_Summer_Olympics 2089 180840058, en 2016_Summer_Olympics 2062 177089806, en 2016_Summer_Olympics 1975 169774986])
(62904,index.html ### https://de.wikipedia.org/wiki/index.html ### [de index.html 1325 16171364, de index.html 2680 30968912, de index.html 2458 27982474, de index.html 2703 30869488, de index.html 2829 32784835, de index.html 2674 30702050, de index.html 2346 26947956, de index.html 2573 29374195, de index.html 2610 30237824, de index.html 2689 32111034, de index.html 2748 31632152, de index.html 2659 30566670, de index.html 2657 30411903, de index.html 2765 32298328, de index.html 2982 34626678, de index.html 2953 33925805, de index.html 2543 29180781, de index.html 2722 31230645, de index.html 2810 32517269, de index.html 2307 26760806, de index.html 2847 33270784, de index.html 2776 32310052, de index.html 2544 29206518, de index.html 2704 31382398])
-
上述第一个网站全天的访问量为63364,如下图,地址是:https://en.wikipedia.org/wiki/2016_Summer_Olympic
-
至此,对维基百科网站统计数据的处理实战就完成了,希望此实战能够给您的大数据分析提供一些参考;

欢迎关注华为云博客:程序员欣宸

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)