经典/最新计算机视觉论文及代码推荐

今日推荐几篇最新/经典计算机视觉方向的论文,涉及诸多方面,其中多篇都是CVPR2022录用的文章,具体内容详见论文原文和代码链接。
用于 2D 和 3D Transformer 的框注意力机制

- 论文题目:BoxeR: Box-Attention for 2D and 3D Transformers
- 论文链接:https://arxiv.org/abs/2111.13087
- 代码链接:https://github.com/kienduynguyen/BoxeR
在本文中,我们提出了一种简单的注意力机制,我们称之为 Box-Attention。它支持输入特征与其相关区域内的网格特征之间的空间交互,提高了 Transformer 在多个视觉任务中的学习能力。具体来说,我们提出了 BoxeR,它预测输入特征的兴趣框相对于参考窗口的平移和尺寸变换,从而注意到变换后兴趣框内的网格特征。BoxeR 在计算这些框的注意力权重时只考虑输入特征和网格结构。值得注意的是,BoxeR-2D 能够在其注意力模块中推理框信息,使其更加适用于端到端的实例检测和分割任务。BoxeR-3D 能够从鸟瞰平面生成判别信息,用于 3D 端到端对象检测,这依赖于 box-attention 3D 模块在 2D 模块的基础上额外预测兴趣框的旋转变换。我们的实验表明, BoxeR-2D 在 COCO 目标检测与实例分割任务上均取得了 SOTA 效果。并且BoxeR-3D 无需任何针对特定物体类别的优化,已经在 Waymo Open Dataset 的车辆类别中获得了有竞争力的性能。

加速DETR收敛的去噪训练
-
论文题目:DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
-
论文链接:https://arxiv.org/abs/2203.01305
-
代码链接:https://github.com/IDEA-opensource/DN-DETR

我们对DETR收敛缓慢给出了一个深刻的理解,并第一次提出了全新的去噪训练(DeNoising training)解决DETR decoder二分图匹配 (bipartite graph matching)不稳定的问题,可以让模型收敛速度翻倍,并对检测结果带来显著提升(+1.9AP)。该方法简易实用,可以广泛运用到各种DETR模型当中,以微小的训练代价带来显著提升,3个审稿人中2个都对论文给出了满分!
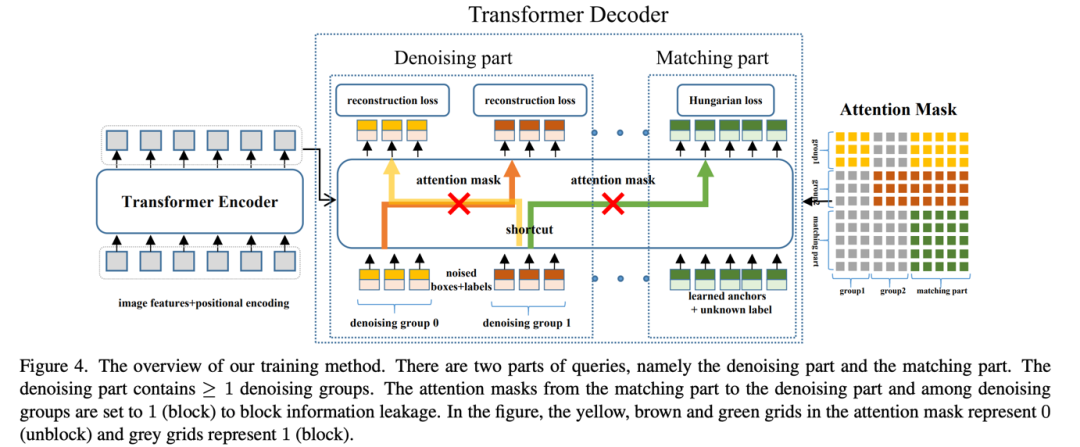
加了Denoising之后模型的输入变为上图。原始DETR的匹配部分我们命名为Matching part,新加的denosing 部分命名为denoising part。需要注意的是,denoising part只需要在训练的时候加上,在inference的时候denoising part会直接移除,和原始模型一样,因此inference的时候不会增加计算量,训练的时候也只需要加入微小的计算量(decoder 部分的denosiing part),我们在文中的实验结果会具体分析。
目标检测的定位蒸馏
-
论文题目:Localization Distillation for Dense Object Detection
-
论文链接:https://arxiv.org/abs/2102.12252
-
代码链接:https://github.com/HikariTJU/LD

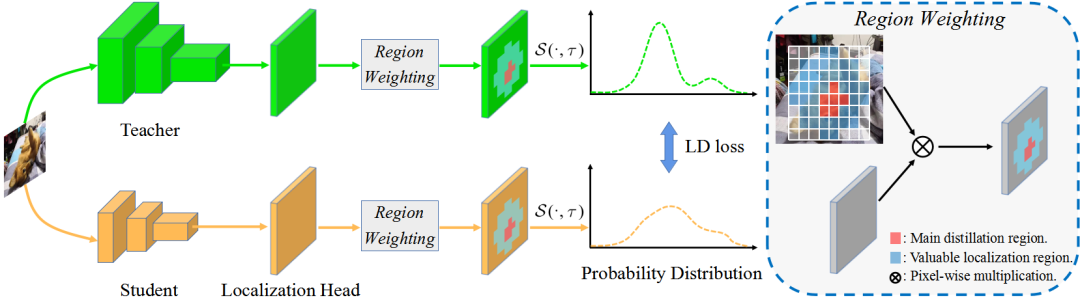
方法概括:把用于分类head的KD(知识蒸馏),用于目标检测的定位head,即有了LD (Localization Distillation)。
做法:先把bbox的4个logits输出值,离散化成4n个logits输出值,之后与分类KD完全一致。
意义:LD使得logit mimicking首次战胜了Feature imitation。分类知识与定位知识的蒸馏应分而治之、因地制宜。
后续
下一期最新/经典视觉论文敬请期待!
文章来源: blog.csdn.net,作者:小小谢先生,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/xiewenrui1996/article/details/126375677

- 点赞
- 收藏
- 关注作者
评论(0)