YOLOP——全景驾驶感知理论解读与实践上手

前言
YOLOP是华中科技大学研究团队在2021年开源的研究成果,其将目标检测/可行驶区域分割和车道线检测三大视觉任务同时放在一起处理,并且在Jetson TX2开发板子上能够达到23FPS。
论文标题:YOLOP: You Only Look Once for Panoptic Driving Perception
论文地址: https://arxiv.org/abs/2108.11250
官方代码: https://github.com/hustvl/YOLOP
网络结构
相比于其它论文,YOLOP的论文很容易阅读。YOLOP的核心亮点就是多任务学习,而各部分都是拿其它领域的成果进行缝合,其网络结构如下图所示:

三个子任务共用一个Backbone和Neck,然后分出来三个头来执行不同的任务。
Encoder
根据论文所述,整个网络可以分成一个Encoder和3个Decoder。
Encoder包含Backbone和Neck,Backbone照搬了YOLOv4所采用的CSPDarknet,Neck也和YOLOv4类似,使用了空间金字塔(SPP)模块和特征金字塔网络(FPN)模块。
Decoders
Decoders即三个任务头
Detect Head
目标检测头使用了Path Aggregation Network (PAN)结构,这个结构可以将多个尺度特征图的特征图进行融合,其实还是YOLOv4那一套。
Drivable Area Segment Head & Lane Line Segment Head
可行驶区域分割头和车道线检测头都属于语义分割任务,因此YOLOP使用了相同的网络结构,经过三次上采样,将输出特征图恢复为(W, H, 2)的大小,再进行具体任务的处理。
Loss Function
损失函数包括三部分,即三个任务的损失。
目标检测损失
目标检测是直接照搬YOLOv4的,因此和YOLOv4采用的损失一样,经典的边界框损失、目标损失和类别损失,各自加了个权重。
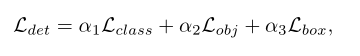
语义分割损失
另外两个语义分割损失采用的均是交叉熵损失。
总体损失
总体损失为三部分损失之和:

实验数据对比
作者后续做了一些对比实验,实际上,这样的对比实验并不“公平”,YOLOP是多任务,其它算法基本上都是单任务。
目标检测对比

首先是在目标检测方面和其它主流算法进行对比,可以看到YOLOP的速度和准确率还不如YOLOv5s,但是召回率却比它要高,这意味着YOLOP能够有更少的漏检目标。
语义分割对比

语义分割方面,可以看到YOLOP无论是速度还是准确性上都是完胜的。
对比效果可视化
最后作者用大量的篇幅分别针对白天和黑夜场景下的三个子任务,和主流算法进行对比。
目标检测对比
作者和Faster R-CNN进行对比,可以看到两者差别并不是非常明显。

可行驶区域分割对比
作者和PSPNet进行对比,可以看到YOLOP效果更好,图中黄线圈出的是漏检,红线框出的是误检。

车道线分割对比
作者和ENet-SAD进行对比,可以看到这方面也是YOLOP取得明显优势。

实践上手
YOLOP的代码结构和YOLOv6差不多,贴心的作者不仅提供了测试样例,而且还提供了训练好的模型权重,直接放在代码仓库里面,无需额外进行下载。
实现推理是需要运行demo.py这个主函数,超参数根据自己的路径进行调整:

效果演示
我将YOLOP输出的结果和之前multiyolov5输出的结果进行对比,效果可以参见下面的视频。
【Demo】YOLOP&multiyolov5行车场景效果演示
文章来源: zstar.blog.csdn.net,作者:zstar-_,版权归原作者所有,如需转载,请联系作者。
原文链接:zstar.blog.csdn.net/article/details/126286578

- 点赞
- 收藏
- 关注作者
评论(0)