【图像分割】基于matlab麻雀算法优化Kmeans图像分割【含Matlab源码 2030期】

一、麻雀算法及LSTM简介
1 麻雀算法简介
麻雀搜索算法(Sparrow Search Algorithm, SSA)是于2020年提出的。SSA 主要是受麻雀的觅食行为和反捕食行为的启发而提出的。该算法比较新颖,具有寻优能力强,收敛速度快的优点。
1.1 算法原理
建立麻雀搜索算法的数学模型,主要规则如下所述:
(1)发现者通常拥有较高的能源储备并且在整个种群中负责搜索到具有丰富食物的区域,为所有的加入者提供觅食的区域和方向。在模型建立中能量储备的高低取决于麻雀个体所对应的适应度值(Fitness Value)的好坏。
(2)一旦麻雀发现了捕食者,个体开始发出鸣叫作为报警信号。当报警值大于安全值时,发现者会将加入者带到其它安全区域进行觅食。
(3)发现者和加入者的身份是动态变化的。只要能够寻找到更好的食物来源,每只麻雀都可以成为发现者,但是发现者和加入者所占整个种群数量的比重是不变的。也就是说,有一只麻雀变成发现者必然有另一只麻雀变成加入者。
(4)加入者的能量越低,它们在整个种群中所处的觅食位置就越差。一些饥肠辘辘的加入者更有可能飞往其它地方觅食,以获得更多的能量。
(5)在觅食过程中,加入者总是能够搜索到提供最好食物的发现者,然后从最好的食物中获取食物或者在该发现者周围觅食。与此同时,一些加入者为了增加自己的捕食率可能会不断地监控发现者进而去争夺食物资源。
(6)当意识到危险时,群体边缘的麻雀会迅速向安全区域移动,以获得更好的位置,位于种群中间的麻雀则会随机走动,以靠近其它麻雀。
在模拟实验中,我们需要使用虚拟麻雀进行食物的寻找,由n只麻雀组成的种群可表示为如下形式:

其中,d表示待优化问题变量的维数,n则是麻雀的数量。那么,所有麻雀的适应度值可以表示为如下形式:

其中,f表示适应度值。
在SSA中, 具有较好适应度值的发现者在搜索过程中会优先获取食物。此外, 因为发现者负责为整个麻雀种群寻找食物并为所有加入者提供觅食的方向。因此,发现者可以获得比加入者更大的觅食搜索范围。根据规则(1)和规则(2),在每次迭代的过程中,发现者的位置更新描述如下:
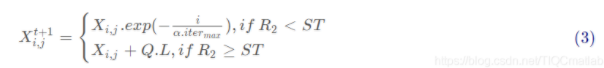
其中, t代表当前迭代数, j=1, 2, 3, …, d.item maz是一个常数,表示最大的迭代次数。Xy表示第i个麻雀在第j维中的位置信息。xE(0,1]是一个随机数。R2(R2E[0,1])和ST(STe[0.5, 1] ) 分别表示预警值和安全值。Q是服从正态分布的随机数.L表示一个1×d的矩阵, 其中该矩阵内每个元素全部为
1.
当R2<ST时,这意味着此时的觅食环境周围没有捕食者,发现者可以执行广泛的搜索操作。如果R2≥ST,这表示种群中的一些麻雀已经发现了捕食者,井向种群中其它麻雀发出了警报,此时所有麻雀都需要迅速飞到其它安全的地方进行觅食。对于加入者,它们需要执行规则(3)和规则(4)。如前面所描述,在觅食过程中,一些加入者会时刻监视着发现者。一旦它们察觉到发现者已经找到了更好的食物,它们会立即离开现在的位置去争夺食物。如果它们赢了,它们可以立即获得该发现者的食物,否则需要继续执行规则(4)。加入者的位置更新描述如下:
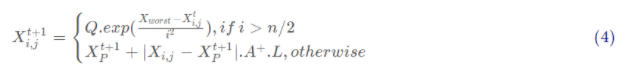
其中, X, 是目前发现者所占据的最优位置, X worst则表示当前全局最差的位置。A表示一个1×d的矩阵, 其中每个元素随机赋值为1或-1,并且A+=A(AA)-.当i>n/2时,这表明,适应度值较低的第i个加入者没有获得食物,处于十分饥饿的状态,此时需要飞往其它地方觅食,以获得更多的能量。在模拟实验中,我们假设这些意识到危险的麻雀占总数量的10%到20%。这些麻雀的初始位置是在种群中随机产生的。根据规则(5),其数学表达式可以表示为如下形式:
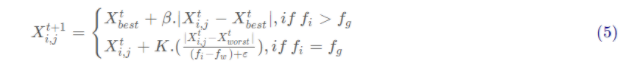
其中, 其中X best是当前的全局最优位置。β作为步长控制参数, 是服从均值为0, 方差为1的正态分布的随机数。KE[-1, 1] 是一个随机数,则是当前麻雀个体的适应度值。f,和fw分别是当前全局最佳和最差的适应度值。e的常数,以避免分母出现零。
为简单起见, 当f:>f, 表示此时的麻雀正处于种群的边缘, 极其容易受到捕食者的攻击。X best表示这个位置的麻雀是种群中最好的位置也是十分安全的。f;=f,时,这表明处于种群中间的麻雀意识到了危险,需要靠近其它的麻雀以此尽量减少它们被捕食的风险。K表示麻雀移动的方向同时也是步长控制参数。
1.2 算法流程
Step1: 初始化种群,迭代次数,初始化捕食者和加入者比列。
Step2:计算适应度值,并排序。
Step3:利用式(3)更新捕食者位置。
Step4:利用式(4)更新加入者位置。
Step5:利用式(5)更新警戒者位置。
Step6:计算适应度值并更新麻雀位置。
Step7:是否满足停止条件,满足则退出,输出结果,否则,重复执行Step2-6;
二、部分源代码
%%
% 基于麻雀优化kemeans的图像分割算法 %
%%
clear all
clc
rng(‘default’);
%读取图像
[im,map]=imread(‘ant.jpg’);
figure
imshow(im,[])
title(‘原始图像’);
%转换为double类型数据并且归一化到0到1
im=im2double(im);
[row,col,cType]=size(im);
%将图像按通道数存放
for i = 1:cType
Temp = im(:,:,i) ;
imIn(:,i) = Temp(😃';
end
%设置聚类个数:
nc=3;
%获取10%采样点
L= rowcol;
rns=(10/100)L;
rp=randperm(L);
sds=imIn(rp(1:rns)😅;
%设置麻雀算法参数
pop=30; % 种群数量
Max_iteration=100; %设定最大迭代次数
lb = zeros(1,nccType); %下边界为0
ub = ones(1,nccType); %上边界为1
dim = nc*cType;%设置维度
fobj = @(X) fun(X,sds);
[Best_pos,Best_score,SSA_curve]=SSA(pop,Max_iteration,lb,ub,dim,fobj); %开始优化
%绘制迭代曲线
figure
plot(SSA_curve,‘Color’,‘g’)
title(‘麻雀算法优化Kmeans迭代曲线’)
xlabel(‘迭代次数’);
ylabel(‘适应度值’);
axis tight
grid on
box on
legend(‘麻雀算法’)
display(['The best solution obtained by SSA is : ', num2str(Best_pos)]);
display(['The best optimal value of the objective funciton found by SSA is : ', num2str(Best_score)]);
%利用麻雀初始化后的点进行kemeans分割
[idx,cs,egr]=kmeanseg(im,Best_pos);
figure
imshow(idx,[])
title([‘聚类个数:’,num2str(nc),‘分割图’]);
gsim=coloring(cs,idx);
gsim=reshape(gsim,row,col,3);
figure;
imshow(gsim);
title([‘聚类个数:’,num2str(nc),‘分割伪彩图’])
三、运行结果




四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1] 张捍东,廖天红,岑豫皖.用模拟退火思想的粒子群算法实现图像分割[J].计算机技术与发展. 2010,20(05)
3 备注
简介此部分摘自互
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/126292015

- 点赞
- 收藏
- 关注作者
评论(0)