ShapeNet数据集及dataset代码分析

1.数据集简介
ShpaeNet是点云中一个比较常见的数据集,它能够完成部件分割任务,即部件知道这个点云数据大的分割,还要将它的小部件进行分割。它总共包括十六个大的类别,每个大的类别有可以分成若干个小类别(例如,飞机可以分成机翼,身体等小类别),总共有五十个小类别。下面可视化一下,经过采样和上色后它长什么样子。
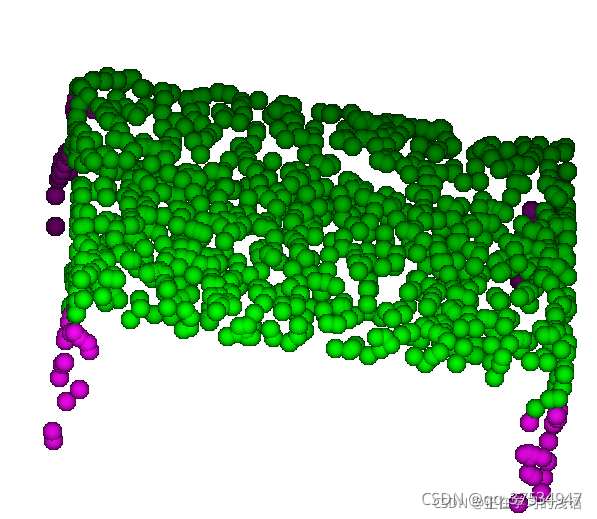
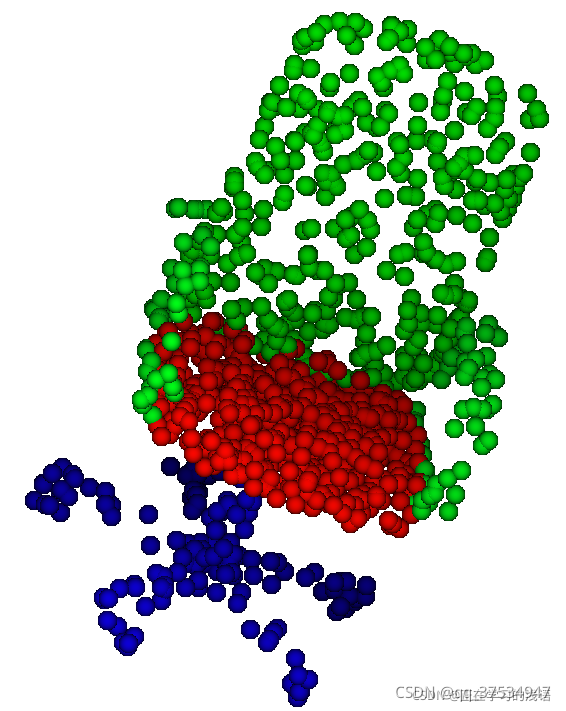
可以发现,它不仅将桌子和椅子进行了分割,还对它的桌子腿等小部件也分割为不同的颜色。
2.数据集结构


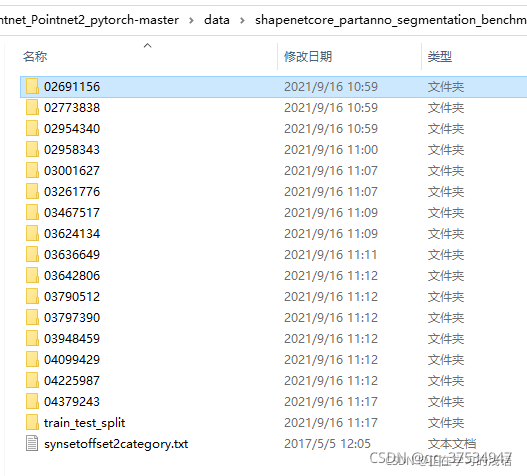
下载好数据集之后,数据集就是这样,其中,数字文件夹里面放的都是每个大类的点云数据。例如,第一个就是飞机大类。
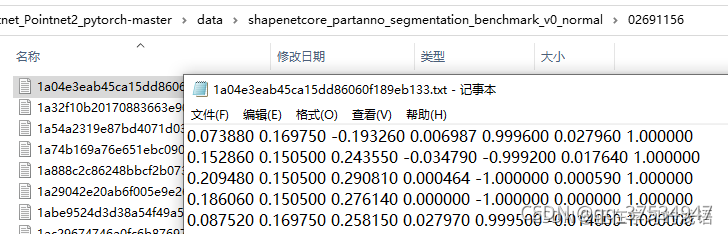
打开其中的文件夹,可以发现里面是很多txt文件。每个txt文件是一个点云数据,相当于2d里面的一张图像。每个点云数据由很多点组成,其中前三个点是xyz,点云的位置坐标,后三个点是点云的rgb颜色坐标。对于shapenet,最好一个点是这个点所属的小类别,即1表示所属50个小类别中的第一个。
其它的文件夹的形式与这个都一样,这里就不过多详细叙述了。
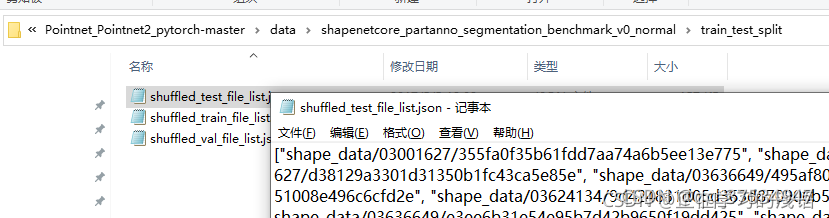
对于train_test_split文件夹是一个划分数据的jason 文件。它将数据集划分为训练集 测试集 和验证集。每个元素都是一个点云数据,按斜杠划分第二个是该点云数据所属的类别,第三个是该点云数据的名称。例如,在test jason文件中的名称 ,就是用来测试的点云数据的名称。
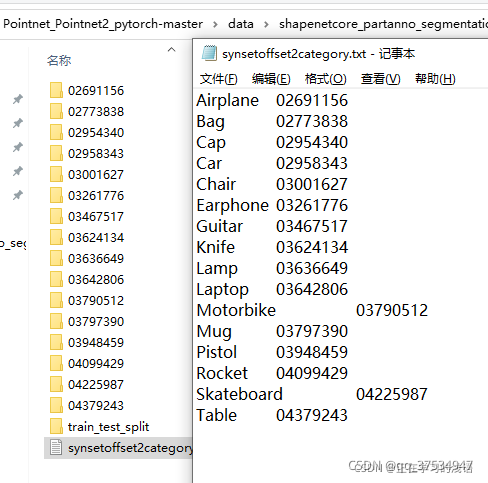
synsetoffset2category.txt 里面存放的就是shapnet 十六个大类别与文件夹名称的对于关系。
3.Datasets 读入代码分析
关于shapenet数据读入的数据集,我参考的是PotinNet的数据集部分。
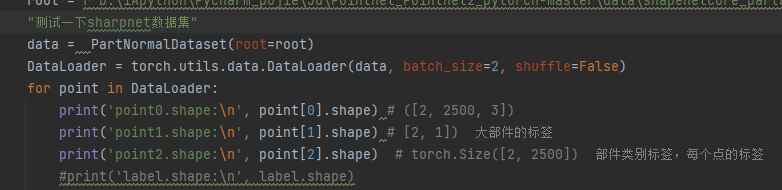
填写好路径,先来测试一些输出部分。可以发现,shapenet数据集会给我们返回三个输出。第一个就是每个点云集合下采样后 的xyz坐标,每个大类别的标签,以及每个点云集中每个点的类别(2,2500)。
下面简要分析一下数据集的代码,关键的代码我都已经做了注释。
# *_*coding:utf-8 *_*
import os
import json
import warnings
import numpy as np
from torch.utils.data import Dataset
warnings.filterwarnings('ignore')
def pc_normalize(pc):
centroid = np.mean(pc, axis=0)
pc = pc - centroid
m = np.max(np.sqrt(np.sum(pc ** 2, axis=1)))
pc = pc / m
return pc
class PartNormalDataset(Dataset):
def __init__(self,root = './data/shapenetcore_partanno_segmentation_benchmark_v0_normal', npoints=2500, split='train', class_choice=None, normal_channel=False):
self.npoints = npoints # 采样点数
self.root = root # 文件根路径
self.catfile = os.path.join(self.root, 'synsetoffset2category.txt') # 类别和文件夹名字对应的路径
self.cat = {
}
self.normal_channel = normal_channel # 是否使用rgb信息
with open(self.catfile, 'r') as f:
for line in f:
ls = line.strip().split()
self.cat[ls[0]] = ls[1]
self.cat = {
k: v for k, v in self.cat.items()} #{'Airplane': '02691156', 'Bag': '02773838', 'Cap': '02954340', 'Car': '02958343', 'Chair': '03001627', 'Earphone': '03261776', 'Guitar': '03467517', 'Knife': '03624134', 'Lamp': '03636649', 'Laptop': '03642806', 'Motorbike': '03790512', 'Mug': '03797390', 'Pistol': '03948459', 'Rocket': '04099429', 'Skateboard': '04225987', 'Table': '04379243'}
self.classes_original = dict(zip(self.cat, range(len(self.cat)))) #{'Airplane': 0, 'Bag': 1, 'Cap': 2, 'Car': 3, 'Chair': 4, 'Earphone': 5, 'Guitar': 6, 'Knife': 7, 'Lamp': 8, 'Laptop': 9, 'Motorbike': 10, 'Mug': 11, 'Pistol': 12, 'Rocket': 13, 'Skateboard': 14, 'Table': 15}
if not class_choice is None: # 选择一些类别进行训练 好像没有使用这个功能
self.cat = {
k:v for k,v in self.cat.items() if k in class_choice}
# print(self.cat)
self.meta = {
} # 读取分好类的文件夹jason文件 并将他们的名字放入列表中
with open(os.path.join(self.root, 'train_test_split', 'shuffled_train_file_list.json'), 'r') as f:
train_ids = set([str(d.split('/')[2]) for d in json.load(f)]) # '928c86eabc0be624c2bf2dcc31ba1713' 这是第一个值
with open(os.path.join(self.root, 'train_test_split', 'shuffled_val_file_list.json'), 'r') as f:
val_ids = set([str(d.split('/')[2]) for d in json.load(f)])
with open(os.path.join(self.root, 'train_test_split', 'shuffled_test_file_list.json'), 'r') as f:
test_ids = set([str(d.split('/')[2]) for d in json.load(f)])
for item in self.cat:
self.meta[item] = []
dir_point = os.path.join(self.root, self.cat[item]) # # 拿到对应一个文件夹的路径 例如第一个文件夹02691156
fns = sorted(os.listdir(dir_point)) # 根据路径拿到文件夹下的每个txt文件 放入列表中
# print(fns[0][0:-4])
if split == 'trainval':
fns = [fn for fn in fns if ((fn[0:-4] in train_ids) or (fn[0:-4] in val_ids))]
elif split == 'train':
fns = [fn for fn in fns if fn[0:-4] in train_ids] # 判断文件夹中的txt文件是否在 训练txt中,如果是,那么fns中拿到的txt文件就是这个类别中所有txt文件中需要训练的文件,放入fns中
elif split == 'val':
fns = [fn for fn in fns if fn[0:-4] in val_ids]
elif split == 'test':
fns = [fn for fn in fns if fn[0:-4] in test_ids]
else:
print('Unknown split: %s. Exiting..' % (split))
exit(-1)
# print(os.path.basename(fns))
for fn in fns:
"第i次循环 fns中拿到的是第i个文件夹中符合训练的txt文件夹的名字"
token = (os.path.splitext(os.path.basename(fn))[0])
self.meta[item].append(os.path.join(dir_point, token + '.txt')) # 生成一个字典,将类别名字和训练的路径组合起来 作为一个大类中符合训练的数据
#上面的代码执行完之后,就实现了将所有需要训练或验证的数据放入了一个字典中,字典的键是该数据所属的类别,例如飞机。值是他对应数据的全部路径
#{Airplane:[路径1,路径2........]}
#####################################################################################################################################################
self.datapath = []
for item in self.cat: # self.cat 是类别名称和文件夹对应的字典
for fn in self.meta[item]:
self.datapath.append((item, fn)) # 生成标签和点云路径的元组, 将self.met 中的字典转换成了一个元组
self.classes = {
}
for i in self.cat.keys():
self.classes[i] = self.classes_original[i]
## self.classes 将类别的名称和索引对应起来 例如 飞机 <----> 0
# Mapping from category ('Chair') to a list of int [10,11,12,13] as segmentation labels
"""
shapenet 有16 个大类,然后每个大类有一些部件 ,例如飞机 'Airplane': [0, 1, 2, 3] 其中标签为0 1 2 3 的四个小类都属于飞机这个大类
self.seg_classes 就是将大类和小类对应起来
"""
self.seg_classes = {
'Earphone': [16, 17, 18], 'Motorbike': [30, 31, 32, 33, 34, 35], 'Rocket': [41, 42, 43],
'Car': [8, 9, 10, 11], 'Laptop': [28, 29], 'Cap': [6, 7], 'Skateboard': [44, 45, 46],
'Mug': [36, 37], 'Guitar': [19, 20, 21], 'Bag': [4, 5], 'Lamp': [24, 25, 26, 27],
'Table': [47, 48, 49], 'Airplane': [0, 1, 2, 3], 'Pistol': [38, 39, 40],
'Chair': [12, 13, 14, 15], 'Knife': [22, 23]}
# for cat in sorted(self.seg_classes.keys()):
# print(cat, self.seg_classes[cat])
self.cache = {
} # from index to (point_set, cls, seg) tuple
self.cache_size = 20000
def __getitem__(self, index):
if index in self.cache: # 初始slef.cache为一个空字典,这个的作用是用来存放取到的数据,并按照(point_set, cls, seg)放好 同时避免重复采样
point_set, cls, seg = self.cache[index]
else:
fn = self.datapath[index] # 根据索引 拿到训练数据的路径self.datepath是一个元组(类名,路径)
cat = self.datapath[index][0] # 拿到类名
cls = self.classes[cat] # 将类名转换为索引
cls = np.array([cls]).astype(np.int32)
data = np.loadtxt(fn[1]).astype(np.float32) # size 20488,7 读入这个txt文件,共20488个点,每个点xyz rgb +小类别的标签
if not self.normal_channel: # 判断是否使用rgb信息
point_set = data[:, 0:3]
else:
point_set = data[:, 0:6]
seg = data[:, -1].astype(np.int32) # 拿到小类别的标签
if len(self.cache) < self.cache_size:
self.cache[index] = (point_set, cls, seg)
point_set[:, 0:3] = pc_normalize(point_set[:, 0:3]) # 做一个归一化
choice = np.random.choice(len(seg), self.npoints, replace=True) # 对一个类别中的数据进行随机采样 返回索引,允许重复采样
# resample
point_set = point_set[choice, :] # 根据索引采样
seg = seg[choice]
return point_set, cls, seg # pointset是点云数据,cls十六个大类别,seg是一个数据中,不同点对应的小类别
def __len__(self):
return len(self.datapath)
if __name__ == '__main__':
import torch
root = r'D:\1Apython\Pycharm_pojie\3d\Pointnet_Pointnet2_pytorch-master\data\shapenetcore_partanno_segmentation_benchmark_v0_normal'
"测试一下sharpnet数据集"
data = PartNormalDataset(root=root)
DataLoader = torch.utils.data.DataLoader(data, batch_size=2, shuffle=False)
for point in DataLoader:
print('point0.shape:\n', point[0].shape) # ([2, 2500, 3])
print('point1.shape:\n', point[1].shape) # [2, 1]) 大部件的标签
print('point2.shape:\n', point[2].shape) # torch.Size([2, 2500]) 部件类别标签,每个点的标签
#print('label.shape:\n', label.shape)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
4.数据集下载
https://download.csdn.net/download/qq_37534947/84081763
文章来源: blog.csdn.net,作者:Studying_swz,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_37534947/article/details/121579653

- 点赞
- 收藏
- 关注作者
评论(0)