机器学习的练功方式(九)——线性回归

致谢
为什么计算函数极值用梯度下降算法而不直接令导数为0求解? - 知乎 (zhihu.com)
解释为什么用梯度下降而不是直接求导数为0的解?_weixin_43167121的博客-CSDN博客_梯度下降为什么不直接导数=0
python的numpy向量化语句为什么会比for快? - 知乎 (zhihu.com)
机器学习:波士顿房价数据集 - wjunneng - 博客园 (cnblogs.com)
随机梯度下降(SGD)与经典的梯度下降法的区别_米兰小子SHC-CSDN博客_随机梯度下降和梯度下降的区别
9 线性回归再相遇
在第二讲中,实际上我们已经谈论了线性回归的基本知识。但是你是否在当时发现了我的一些漏洞呢?如果你没有发现,你要好好反思自己了。
在当时我们谈到了对于损失函数如何求最小值的问题,那时候我对于求导避而不谈,转而使用了梯度下降来作为求最小值的方法,这是为何呢?
首先我们来试想,我们用求导来求极小值是怎么求的?我们是通过令导函数为0来求导的,可是实际问题中,如果损失函数非凸,那势必会出现 y = x 3 y = x^3 y=x3中 x 0 x_0 x0位置的拐点。因此我们可以得出:并不是所有的函数都可以根据导数求导取得0值的点的,我们需要一种更通用的方式来解决损失函数极小值的问题。
在最优化中,牛顿迭代和梯度下降都可以计算极值。区别在于,梯度下降法的算法复杂度低一些, 但是迭代次数多一些; 牛顿迭代法计算的更快(初值必须设置的很合理), 但是牛顿迭代法因为有"除法"参与(对矩阵来说就是求逆矩阵), 所以每一步迭代计算量很大. 一般会根据具体的情况取舍。
梯度下降相比于牛顿迭代法还有一个好处就是,它的完成方式允许一个简单的并行化,即在多个处理器或机器上分配计算,所以当你使用神经网络来训练模型时,梯度下降变得尤为重要。
好了,坑填上了,下面进入我们这一讲学习的部分。
9.1 再遇
9.1.1 概述
线性回归并不是我们初中学习的那个一次函数了,实际上在机器学习中的线性回归更加地广义。我们初中熟知的一次函数在机器学习中被称为单变量回归。而自变量大于一个的我们叫做多元回归。在第二讲中我们谈到房价预测的模型 h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 h_θ(x) = θ_0+θ_1x_1+θ_2x_2 hθ(x)=θ0+θ1x1+θ2x2即为多元回归。
我们给出通用公式: h ( w ) = w 1 x 1 + w 2 x 2 + . . . w n x n + b = w T + b h(w) = w_1x_1+w_2x_2+...w_nx_n+b = w^T+b h(w)=w1x1+w2x2+...wnxn+b=wT+b
其中w,x可以理解为矩阵,这实际上是向量化的一种应用方式,在后面,我会提到向量化,不必担心。但是在这之前,我们必须重温线性代数。
9.1.2 矩阵和向量
矩阵一般用方括号括起,里面写有若干个数字。我们一般表示矩阵的维度通常是采用行数×列数来表示的。如下图所示:

有时我们也会遇见下图所示的符号:

这个看似像R的符号实际上代表任意2×3规模的矩阵集合。
如上面的矩阵所示,我们会用 A i j A_{ij} Aij来表示A矩阵中第i行第j列的某一个元素。
对于向量也是相应的表示方法,它实际上是一个n×1的矩阵,也就是说,实际上标量是0维,向量是2维,矩阵是三维。
9.1.3 矩阵加减乘除
9.1.3.1 矩阵——矩阵加减
矩阵的加法和减法实际上就是,两个矩阵对应元素相加相减即可。但是在这里需要注意,如果两个矩阵不是同型(即不同维度的)的,那么两个矩阵是不能相加相减的。
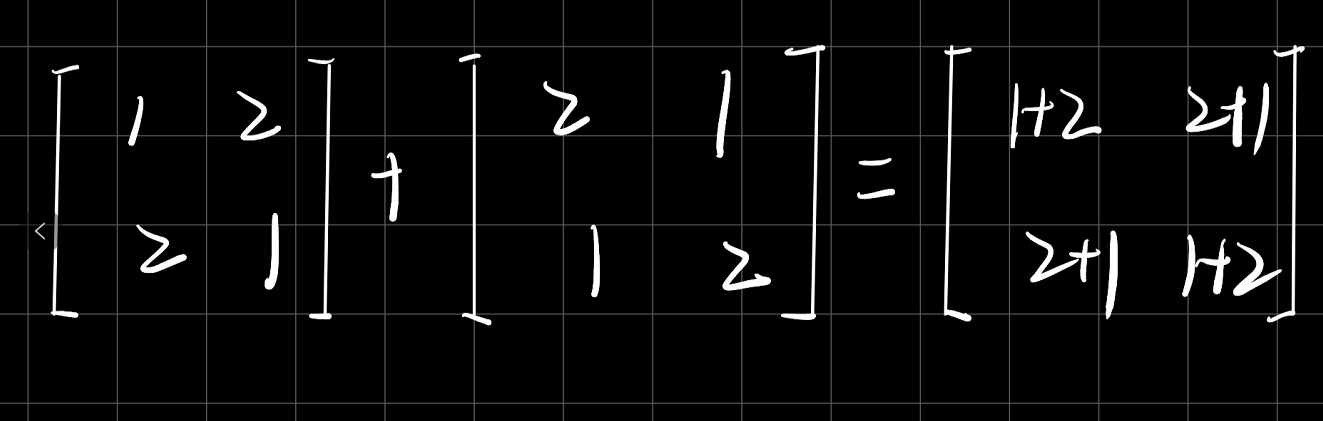
在python中两个矩阵即使不同型也能相加,即python的广播机制,在后面的论述中,我们再细谈。
9.1.3.2 矩阵——标量加减乘
对于一个标量和一个矩阵相加相减,如果该标量是n,那么实际上我们可以把该标量看成是一个n的单位矩阵(n的单位矩阵是主对角线全n,可不是矩阵所有元素都是n哈),且与另外需要相加相减的矩阵同型。也就是说,标量加矩阵,即矩阵对应元素全部加上或减去该标量。
同样地,标量和矩阵相乘,即矩阵所有元素全部乘上该标量。

9.1.3.3 矩阵——向量相乘
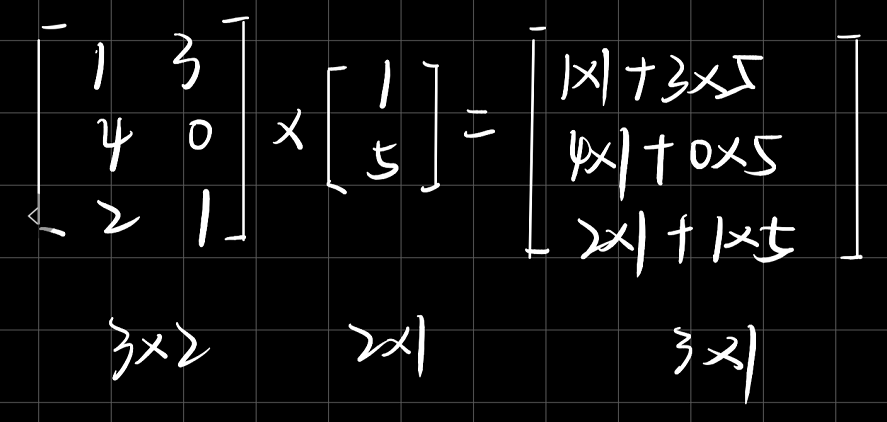
矩阵和一个向量相乘,假如一个矩阵为m×n,则要求向量一定要为n×1,否则不能相乘。
相乘的时候,矩阵的行元素与向量的列元素对应相乘再相加。
9.1.3.4 矩阵——矩阵相乘
矩阵矩阵相乘和矩阵向量相乘同理,假如一个矩阵为m×n,则要求另外一个矩阵必须是n×k,否则不能相乘。其相乘的结果矩阵为m×k。
相乘的时候,A矩阵的行元素和B矩阵的列元素对应相乘再相加。
实际上,AB矩阵相乘和BA矩阵相乘是不一样的,也就是说,其不享有标量运算中的乘法交换律。所以在进行计算的时候,这个问题是十分需要注意的。不过有一个特例,假如矩阵和单位矩阵进行相乘,两者是满足乘法交换律的。
9.1.3.5 矩阵的逆
有些人很奇怪,上面怎么都是相加相减相乘,可就是没有相除呢?这是因为在线性代数中矩阵的除法不太一样。
在线性代数中,矩阵的除法叫做逆。比如标量1/3和3/1相乘,其必定为1。我们称3/1为1/3的逆。在矩阵中,假如有A矩阵和A的逆矩阵 A − 1 A^{-1} A−1,则满足 A ( A − 1 ) = I ( I 为 单 位 矩 阵 ) A(A^{-1}) = I(I为单位矩阵) A(A−1)=I(I为单位矩阵)。且需要提到的是,只有形如m×m的方阵才有逆矩阵。
逆矩阵一般怎么求呢?外国学生一般用软件算,而中国学生就比较“惨”了,一般靠手算。
如果靠手算,我们一般使用初等行变换法或者利用伴随矩阵来求,这里我们就不过多叙述了,因为脱离了主要内容了。
9.1.3.6 矩阵的转置
转置就不多说了,直接行列互换即可。假如一个A为m×n,则 A T A^T AT为n×m。
9.1.4 向量化
在线性回归中,我们会把若干个特征放入x向量中,而把若干个w放入w向量中,最后运用上述的线性代数知识将其加上b。这么做的话,相比于用for循环一个特征一个特征的去扫描,然后一个样本一个样本训练模型来说,使用numpy来启用线性代数机制去计算明显速度要提高几番不止。至于为什么用线性代数机制快,你可以去网上查查,这里涉及底层知识,这里不过多讲解。
9.1.5 广义线性模型
线性模型中实际上有狭义线性模型和广义线性模型。狭义的线性模型就是我们所知的y = kx+b,而广义线性模型即为 y = w 1 x 1 + w 2 x 2 + b y = w_1x_1+w_2x_2+b y=w1x1+w2x2+b,画在图上实际上这个函数是一个平面。甚至于你可以无限扩展其维度,变成 y = w 1 x 1 + w 2 x 2 + . . . w n x n + b y = w_1x_1+w_2x_2+...w_nx_n+b y=w1x1+w2x2+...wnxn+b。
然而,线性模型也并非一定要线性,也可以是非线性的。形如 y = w 1 x 1 + w 2 x 2 2 + b y = w_1x_1+w_2x_2^2+b y=w1x1+w2x22+b也被称为线性模型。线性模型实际上追求的不是线性,而是追求模型中某个东西一次(方):即自变量一次或参数一次。
参数和自变量多,实际上可以提高模型精度;但是不控制好,则会导致过拟合,这一点在第五讲我们已经做过论述了,这里不再提了。
9.2 正规方程
我们在第二讲曾经提到过正规方程。现在是时候填上我们的坑了。
正规方程和梯度下降都是求得损失函数最小值对应参数的方法。但是不同的是,正规方程并不需要进行迭代,它可以一步求解。而对于梯度下降,其必须勤勤恳恳进行迭代无限逼近最小值。
但是正规方程也有不好的地方,当特征过多过复杂的时候,正规方程求解速度会很慢,且常常求不出结果。所以其实际上具有局限性。
正规方程的基本形式为:
w = ( X T X ) − 1 X T y w = (X^TX)^{-1}X^Ty w=(XTX)−1XTy
由于正规方程的不通用性,所以这里我们不做过多讲解,初学者只需牢牢掌握梯度下降即可。
9.3 线性回归的实现
结合第二讲和这一讲的叙述,相信我们对线性回归都有一定地了解了,现在让我们看看,我们如何使用sklearn为我们提供的API。
sklearn.linear_model.LinearRegression(fit_intercept = True)
- 通过正规方程优化
- fit_intercept:是否计算偏置
- LinearRegression.coef_:回归系数
- LinearRegression.intercept_:偏置
sklearn.linear_model.SGDRegression(loss = “squared_loss”,fit_intercept = True,learning_rate = ‘invscaling’,eta0 = 0.01)
- loss:损失类型
- loss = “squared_loss”:普通最小二乘法
- fit_intercept:是否计算偏置
- learning_rate:string,optinal
- 用于学习率填充
- ‘constant’:eta = eta0
- ‘optimal’:eta = 1.0/(alpha*(t+t0))[default]
- ‘invscaling’:eta = eta0/pow(t,power_t)
- power_t = 0.25:存在于父类中
- 对于一个常数值的学习率来说,可以使用’constant’,并使用eta0来指定学习率
- SGDRegressor.coef_:回归系数
- SGDRegressor.intercept_:偏置
我们利用上面的API,对sklearn内置的波士顿房价数据集做预测。
波士顿房价数据集
使用sklearn.datasets.load_boston即可加载相关数据。该数据集是一个回归问题。每个类的观察值数量是均等的,共有 506 个观察,13 个输入变量和1个输出变量。
每条数据包含房屋以及房屋周围的详细信息。其中包含城镇犯罪率,一氧化氮浓度,住宅平均房间数,到中心区域的加权距离以及自住房平均房价等等。
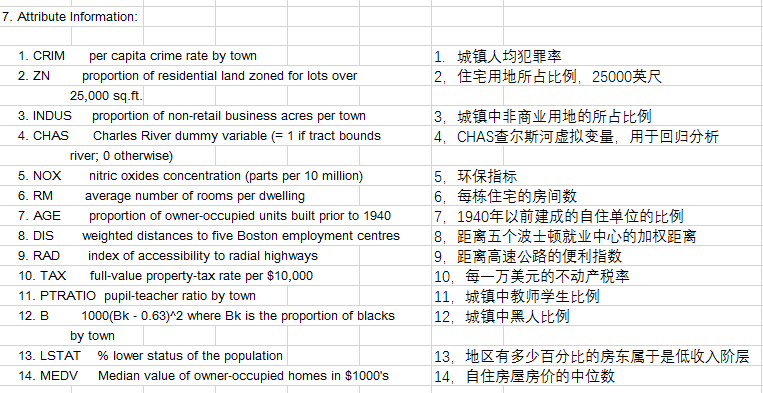
在上面的数据中,我们可以总结出以下处理步骤:
- 获取数据集
- 划分数据集
- 特征工程:标准化(各项指标有小数有整数,需要标准化一下)
- 预估器流程
- 模型评估
代码如下所示:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import SGDRegressor
def linear_model_1():
"""利用正规方程来优化损失函数"""
# 1 获取数据
boston_data = load_boston()
# 2 划分数据
x_train, x_test, y_train, y_test = train_test_split(boston_data.data, boston_data.target, random_state=22)
# 3 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4 预估器
estimator = LinearRegression()
estimator.fit(x_train, y_train)
# 5 得出模型
print("------经果正规方程的优化后------")
print("权重系数为:\n", estimator.coef_)
print("偏置为:\n", estimator.intercept_)
def linear_model_2():
"""利用梯度下降来优化损失函数"""
# 1 获取数据
boston_data = load_boston()
# 2 划分数据
x_train, x_test, y_train, y_test = train_test_split(boston_data.data, boston_data.target, random_state=22)
# 3 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4 预估器
estimator = SGDRegressor()
estimator.fit(x_train, y_train)
# 5 得出模型
print("------经果梯度下降的优化后------")
print("权重系数为:\n", estimator.coef_)
print("偏置为:\n", estimator.intercept_)
linear_model_1()
linear_model_2()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
9.4 模型评估
在回归任务中,其不像分类任务一样直接对比分类效果获得准确率即可。对于模型的好坏采用的是评估指标,评估指标一般都是用我们在第二讲讲到的那几个误差函数。在线性回归中,常用的误差函数即为平方误差函数,即均方误差(Mean Square Error,MSE)。其他的误差函数,在神经网络中会一一涉及。
均方误差如下所示:
M S E = 1 m ∑ i = 1 m ( y ^ − y i ) 2 MSE = \frac{1}{m}\sum^m_{i = 1}(\hat y - y^i)^2 MSE=m1i=1∑m(y^−yi)2
MSE的作用就是当你训练出了模型后,我用测试集中的数据来对比你预测出来的结果,看看差距到底有多大,这个多大是用均方误差来估计的。
在sklearn中也有相应的API,如下所示:
sklearn.metrics.mean_squared_error(y_true, y_pred)
- 均方误差回归损失
- y_true:真实值
- y_pred:预测值
- return:误差,浮点数结果
应用在上面的线性回归中:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error
def linear_model_1():
"""利用正规方程来优化损失函数"""
# 1 获取数据
boston_data = load_boston()
# 2 划分数据
x_train, x_test, y_train, y_test = train_test_split(boston_data.data, boston_data.target, random_state=22)
# 3 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4 预估器
estimator = LinearRegression()
estimator.fit(x_train, y_train)
y_predict = estimator.predict(x_test)
# 5 得出模型
print("------经果正规方程的优化后------")
print("权重系数为:\n", estimator.coef_)
print("偏置为:\n", estimator.intercept_)
# 6 评估模型
error = mean_squared_error(y_test, y_predict)
print("均方误差为:\n", error)
def linear_model_2():
"""利用梯度下降来优化损失函数"""
# 1 获取数据
boston_data = load_boston()
# 2 划分数据
x_train, x_test, y_train, y_test = train_test_split(boston_data.data, boston_data.target, random_state=22)
# 3 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4 预估器
estimator = SGDRegressor()
estimator.fit(x_train, y_train)
y_predict = estimator.predict(x_test)
# 5 得出模型
print("------经果梯度下降的优化后------")
print("权重系数为:\n", estimator.coef_)
print("偏置为:\n", estimator.intercept_)
# 6 评估模型
error = mean_squared_error(y_test, y_predict)
print("均方误差为:\n", error)
linear_model_1()
linear_model_2()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
9.5 正规方程和梯度下降
正规方程和梯度下降在上面的案例中已经有了很明显的对比:
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习率 | 不需要 |
| 需要迭代求解 | 一次运算就能得出 |
| 特征数量较大可以使用 | 需要解方程,时间复杂度很高 |
在选择优化方法时,我觉得真的没必要花里胡哨,梯度下降就对了。如果那你真的很想搞事,那么sklearn给了一个参考图,你可以根据这个来判定你要使用哪种优化方法。
9.6 关于优化方法
实际上,我们在上面提到的sklearn.linear_model.SGDRegression并不是传统的梯度下降(GD),而是经过多次改进的随机梯度下降(SGD)。
传统的梯度下降需要在迭代过程中使用所有的训练数据。记得梯度下降怎么做的吗?
线性代数的损失函数假设为: J ( θ 1 ) = 1 2 m ( y ^ − y ) 2 J(θ_1) = \frac {1}{2m}(\hat y - y)^2 J(θ1)=2m1(y^−y)2,则模型参数更新为: θ j = θ j − α ∂ ∂ θ j J ( θ 0 , θ 1 ) θ_j = θ_j - \alpha \frac{\partial}{\partial θ_j} J(θ_0,θ_1) θj=θj−α∂θj∂J(θ0,θ1)
因此,在经典的梯度下降法中每次对模型参数进行更新时,需要遍历所有的数据。当m很大的时候,就需要耗费巨大的计算资源和计算时间。为此,随机梯度下降(SGD)应运而生。
随机梯度下降不再去求平均数了,而是使用随机的单个样本的损失来作为平均损失。它是一种简单但非常有效的方法。适用于支持向量机和回归中。在以前小数据是SGD实际上作用并不明显,但是在数据愈发蓬勃发展的时刻它越来越重要。
所以综上所述,SGD的优点就是效率高易于实现。而SGD的缺点是其包含众多的超参数,需要自己指定,而且其对于标准化很敏感。
9.7 后话
实际上回归远不止于此,线性回归是回归问题一种最为简单的实现方式。除了线性回归,前面学过的决策树也能做回归,贝叶斯也可以,如果后面有机会,我们还会接触到岭回归、逻辑斯蒂回归(实际上是分类)、最小角回归、弹性网络、感知机、稳健回归等,它们都属于广义线性模型。
好了,这一讲有点长,你也累了,晚安。
文章来源: blog.csdn.net,作者:ArimaMisaki,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/chengyuhaomei520/article/details/123476544

- 点赞
- 收藏
- 关注作者
评论(0)