网络爬虫(一)——爬虫及其实现

1.1 爬虫概述
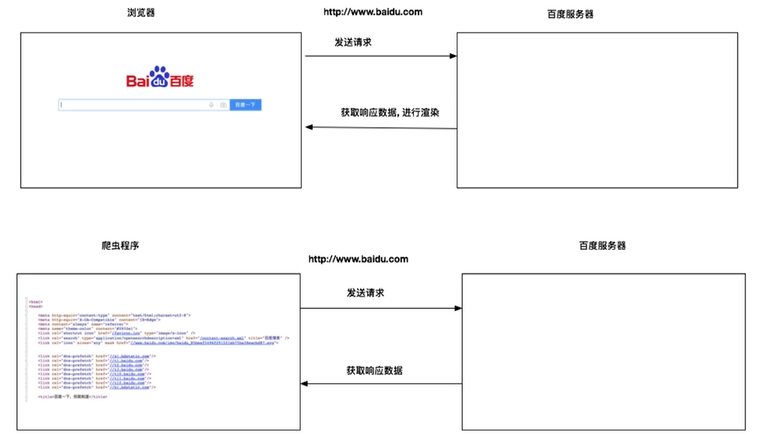
1.1.3 网络爬虫和浏览器的区别
浏览器和爬虫都是在访问网站的服务器,然后返回对应的数据。不同的是,浏览器返回的数据还会经过渲染,变成十分美观的界面。而对于爬虫来说,返回的一般是原生的HTML代码。
1.1.2 网络爬虫的定义
网络爬虫也叫网络蜘蛛或网络机器人,其模拟客户端发送网络请求,获取响应数据。换而言之,它是一种按照一定的规则,自动抓取万维网信息的程序或脚本。
1.2 requests请求库
1.2.1 requests基本概念
requests是一个优雅而简单的pythonHTTP请求库。它的作用是发送请求获取响应数据。如果你想要安装这个库,可以打开anaconda3的prompt黑窗口,然后在对应的环境中输入
pip install requests
安装完成后,我们来试着返回一下百度搜索的源代码
# 导入模块
import requests
# 发送请求,获取响应
response = requests.get("https://www.baidu.com/")
# 获取响应数据
response.encoding = 'utf8'
print(response.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
从以上的演示来看,我们可以从中总结requests使用的步骤:
- 导入模块
- 发送get请求,获取响应
- 从响应中获取数据
这里还要给大家科普response对象的方法。
response.text:响应体str类型
response.ecoding:二进制转换字符使用的编码
response.content:响应体bytes类型
1.2.2 疫情数据爬取
我们来试着爬取一下丁香园新型冠状病毒疫情实时动态首页内容。其url为:全球新冠肺炎疫情地图 - 丁香园·丁香医生 (dxy.cn)
# 导入模块
import requests
# 发送请求,获取响应对象
response = requests.get("http://ncov.dxy.cn/ncovh5/view/pneumonia")
# 从响应对象中获取数据
print(response.content.decode())
#print(response.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
1.2.3 get请求
对于get请求返回的响应对象,实际上含有多种方法可调用。
- response.url:打印请求url
- response.headers:打印请求头
- response.cookies:打印cookie信息
- response.status_code:打印请求状态码
对于状态码来说,有如下几种情况:

1.2.4 headers请求头
对于某些网页,其实现了反爬机制,所有通过get方法无法获取数据。这时候我们可以模拟浏览器的头部信息来访问。
每个浏览器的头部信息不同。如何查看浏览器的头部信息呢?
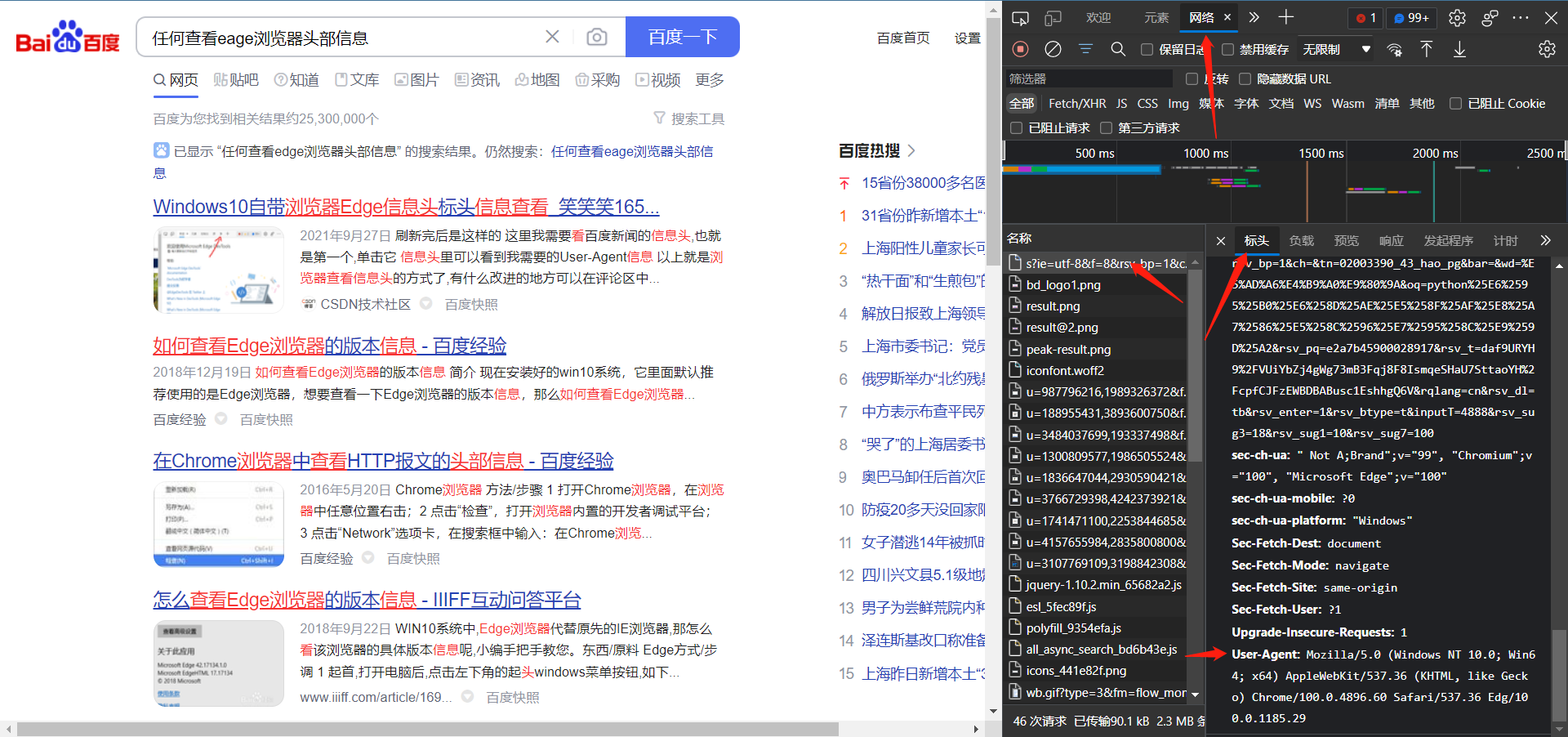
打开一个网页,点检查,然后刷新一下网页,然后按照上图操作即可找到头部信息。
在使用get请求时,只需在get方法的有参构造中传入对应的请求头即可。如下所示:
import requests
# 浏览器头部信息
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36 Edg/100.0.1185.29'}
url = "http://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url, headers=headers)
print(response.status_code)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
1.2.5 Cookies验证
在爬取某些数据时,需要进行网页的登录,才可以进行数据的抓取工作。Cookies登录就像很多网页中的自动登录功能一样,可以让用户第二次登录时在不需要验证账号和密码的情况下进行登录。在使用requests模块实现Cookies登录时,首先需要在浏览器的开发者工具页面中找到可以实现登录的Cookies信息,然后将Cookies信息处理并添加至RequestsCookieJar的对象中,最后将RequestsCookieJar对象作为网络请求的Cookies参数发送网络请求即可。以获取豆瓣网页登录后用户名为例,具体步骤如下:
- 在Google浏览器中打开豆瓣网页地址(https://www.douban.com/),并输入自己的账号+密码登录。
- 右键“检查”,选择“Network”选项。
- 在“name”框中选择其中一个,在Headers选项中选择Request Headers选项,获取登录后的Cookies信息(选中后右键“Copy value”)。
- 导入相应的模块,将复制出来的Cookie信息粘到下面的“此处填写登录后网页的Cookie信息”中,然后创建RequestsCookieJar()对象并对Cookie信息进行处理,最后将处理后的RequestsCookieJar()对象作为网络请求参数,实现网页的登录请求。
让我们试一下下面的代码:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'}
import requests #导入requests模块
cookies = '此处填写登录后网页的Cookie信息'
#发送网络请求
url = 'https://www.douban.com'
#创建requestsCookieJar对象,用于设置Cookies信息
cookies_jar = requests.cookies.RequestsCookieJar()
for cookie in cookies.split(';'):
key,value = cookie.split('=',1)
cookies_jar.set(key,value)
response = requests.get(url,headers=headers,cookies=cookies_jar)
print(response.status_code) #打印相应状态码
print(response.text) #打印相应结果
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
1.3 Beautiful Soup解析库
Beautiful Soup是一个可以从HTML或XML文件中提取数据的python库。如果你不太懂HTML的相关知识,我希望您参考一下我的HTML相关博客。
1.3.1 安装
我们需要安装两个东西:bs4和lxml。
pip install bs4
pip install lxml
1.3.2 对象的创建
BeautifulSoup对象代表要解析的整个文档树。它支持搜索文档树和搜索文档树中描述的大部分方法。
我们来试着创建一个BeautifulSoup对象。解析时,我们采用lxml解析器。
# 导入模块
from bs4 import BeautifulSoup
# 创建对象
soup = BeautifulSoup('<html>data</html>', 'lxml')
print(soup)
- 1
- 2
- 3
- 4
- 5
- 6
out:
<html><body><p>data</p></body></html>
- 1
输入结果时我们可以看到BeautifulSoup对象帮我们自动补全了html的标准格式。


1.3.3 find方法
BeautifulSoup拥有find方法,其作用可以用于搜索文档树。
find(self,name = None,attr = [],recursive = True,text = None,**kwargs)
- name:标签名
- attrs:属性字典
- recursive:是否递归循环查找,如果为False,则无法找到指定标签的子标签
- text:根据文本内容查找
- return :查找到的第一个元素对象
- 如果想要找到所有元素对象,可以使用findAll方法
我们来试着利用bs4来解析以下的HTML语言。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>心得体会——尘鱼</title>
</head>
<body>
<h1>浮世三千</h1>
<hr>
<h2>文章内容</h2>
<p>无非两种人:一种是做了,没成功,所以焦虑;一种是没做,要迎接失败了,所以焦虑。人常常会把自己的所得经验告诫未得之人,就如同许久之前高中的恩师一般念叨;人常常会抱怨世间的不公,想要改变眼前的一切;而人在经历了大起大落后回望,他们总是能发现:自己的付出不像童话里的那般美好,总能得到意外的对待。很少有些许的沉思,或者来自内心深处的拷问:自己至此,该干什么,身边的人说了那么多,自己该不该反思什么。致命的慵懒总是带来成堆的接口,漫天的抱怨似乎幽怨的黑洞,似乎解决的方法就像是时光隧道中那一丝薄弱的亮光微不可及;避开自己心里的拷问,避开一切的一切,似乎拖着拖着生活的美好就能如期而至。</p>
<img src="https://images.cnblogs.com/cnblogs_com/blogs/710924/galleries/2086847/o_220115052557_5af17f7f881b11ebb6edd017c2d2eca2.jpg" alt="图片加载失败" title="该图片来源于尘鱼好美" weight="480" height="360">
<p>“日常所得焦虑,无非是三天打鱼两天晒网,时而努力时而颓废所致。”</p>
<p>约莫些许人同此言,却又忘却其 “人生的悲欢并不相同,他们只觉得你吵闹。
<br>
弃浮沉往事,探前方长路坎坷;弃勿须情感,奔自己心中所想。
<br>
繁琐的慥词现已无人愿细细品味,只愿将心中所得能与伯乐共享,足矣。</p>
如果喜欢该案例可以关注我的网站
<br>
<a href="https://www.cnblogs.com/ChengYuHaoMei/">点此前往</a>
<audio src="https://audio04.dmhmusic.com/71_53_T10051752137_128_4_4_0_sdk-cpm/cn/0103/M00/10/B5/ChR45F8hdhCAJ_unAAdXW5beNxE239.mp3?xcode=e20e7d6d765a63dc97d12357a8578f3cc746bc4" controls autoplay loop>
</body>
</html>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
让我们动手试一下:
# 导入模块
from bs4 import BeautifulSoup
# HTML文档对象
htmlTest = """<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>心得体会——尘鱼</title>
</head>
<body>
<h1>浮世三千</h1>
<hr>
<h2>文章内容</h2>
<p>无非两种人:一种是做了,没成功,所以焦虑;一种是没做,要迎接失败了,所以焦虑。人常常会把自己的所得经验告诫未得之人,就如同许久之前高中的恩师一般念叨;人常常会抱怨世间的不公,想要改变眼前的一切;而人在经历了大起大落后回望,他们总是能发现:自己的付出不像童话里的那般美好,总能得到意外的对待。很少有些许的沉思,或者来自内心深处的拷问:自己至此,该干什么,身边的人说了那么多,自己该不该反思什么。致命的慵懒总是带来成堆的接口,漫天的抱怨似乎幽怨的黑洞,似乎解决的方法就像是时光隧道中那一丝薄弱的亮光微不可及;避开自己心里的拷问,避开一切的一切,似乎拖着拖着生活的美好就能如期而至。</p>
<img src="https://images.cnblogs.com/cnblogs_com/blogs/710924/galleries/2086847/o_220115052557_5af17f7f881b11ebb6edd017c2d2eca2.jpg" alt="图片加载失败" title="该图片来源于尘鱼好美" weight="480" height="360">
<p>“日常所得焦虑,无非是三天打鱼两天晒网,时而努力时而颓废所致。”</p>
<p>约莫些许人同此言,却又忘却其 “人生的悲欢并不相同,他们只觉得你吵闹。
<br>
弃浮沉往事,探前方长路坎坷;弃勿须情感,奔自己心中所想。
<br>
繁琐的慥词现已无人愿细细品味,只愿将心中所得能与伯乐共享,足矣。</p>
如果喜欢该案例可以关注我的网站
<br>
<a href="https://www.cnblogs.com/ChengYuHaoMei/">点此前往</a>
<audio src="https://audio04.dmhmusic.com/71_53_T10051752137_128_4_4_0_sdk-cpm/cn/0103/M00/10/B5/ChR45F8hdhCAJ_unAAdXW5beNxE239.mp3?xcode=e20e7d6d765a63dc97d12357a8578f3cc746bc4" controls autoplay loop>
</body>
</html>"""
# 创建对象
soup = BeautifulSoup(htmlTest, 'lxml')
# 查找title标签
title = soup.find("title")
# 查找a标签
a = soup.find("a")
# 查找所有a标签
a_s = soup.findAll("a")
print(title)
print(a)
print(a_s)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
我们也可以不通过标签查找内容,而通过属性查找内容。那么我们可以使用find有参构造器中attrs属性来构建属性字典,从而进行查找。如下所示:
# 导入模块
from bs4 import BeautifulSoup
# HTML文档对象
htmlTest = """<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>心得体会——尘鱼</title>
</head>
<body>
<h1>浮世三千</h1>
<hr>
<h2>文章内容</h2>
<p>无非两种人:一种是做了,没成功,所以焦虑;一种是没做,要迎接失败了,所以焦虑。人常常会把自己的所得经验告诫未得之人,就如同许久之前高中的恩师一般念叨;人常常会抱怨世间的不公,想要改变眼前的一切;而人在经历了大起大落后回望,他们总是能发现:自己的付出不像童话里的那般美好,总能得到意外的对待。很少有些许的沉思,或者来自内心深处的拷问:自己至此,该干什么,身边的人说了那么多,自己该不该反思什么。致命的慵懒总是带来成堆的接口,漫天的抱怨似乎幽怨的黑洞,似乎解决的方法就像是时光隧道中那一丝薄弱的亮光微不可及;避开自己心里的拷问,避开一切的一切,似乎拖着拖着生活的美好就能如期而至。</p>
<img src="https://images.cnblogs.com/cnblogs_com/blogs/710924/galleries/2086847/o_220115052557_5af17f7f881b11ebb6edd017c2d2eca2.jpg" alt="图片加载失败" title="该图片来源于尘鱼好美" weight="480" height="360">
<p>“日常所得焦虑,无非是三天打鱼两天晒网,时而努力时而颓废所致。”</p>
<p>约莫些许人同此言,却又忘却其 “人生的悲欢并不相同,他们只觉得你吵闹。
<br>
弃浮沉往事,探前方长路坎坷;弃勿须情感,奔自己心中所想。
<br>
繁琐的慥词现已无人愿细细品味,只愿将心中所得能与伯乐共享,足矣。</p>
如果喜欢该案例可以关注我的网站
<br>
<a href="https://www.cnblogs.com/ChengYuHaoMei/">点此前往</a>
<audio src="https://audio04.dmhmusic.com/71_53_T10051752137_128_4_4_0_sdk-cpm/cn/0103/M00/10/B5/ChR45F8hdhCAJ_unAAdXW5beNxE239.mp3?xcode=e20e7d6d765a63dc97d12357a8578f3cc746bc4" controls autoplay loop>
</body>
</html>"""
# 创建对象
soup = BeautifulSoup(htmlTest, 'lxml')
# 根据title属性查找img内容
img = soup.find(attrs={'weight': "480"})
print(img)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
1.3.4 后话
实际上,解析库不止有bs4,还有Xpath、selenium和Scrapy框架。这些后面我想单独再讲,这里有bs4已经足够爬取大部分的网页内容了。
1.4 正则表达式
1.4.1 正则表达式语法
正则表达式可以用于字符串匹配。其可以检查一个字符串是否含有某种子串,还可以替换匹配的子串,最后还能提取某个字符串汇总匹配的子串。
让我们来看一下正则表达式的语法。
| 字符 | 作用 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \ | 转义字符,能使的改变字符原本的意思,变为字符串 |
| […] | 字符集。对应的位置可以是字符集中任意字符。如a[a-c]d,那么其匹配结果是aad、abd、acd。如果要取反,加上^即可。如a[ ^a-c ],其可以匹配除了aa、ab、ac以外的任何带a开头的两位英文字符串。 |
动手试一下吧,能够加深你的印象。
# 正则表达式的常见语法
import re
# 字符匹配
str1 = 'abcdefg'
rs = re.findall('abc', str1)
rs1 = re.findall('a.c', str1)
print(f"字符串匹配结果{rs}")
print(f"点的匹配结果{rs1}")
str2 = 'a.bcdfg'
rs2 = re.findall('a\..c', str2)
print(f"用转义字符匹配点{rs2}")
rs3 = re.findall('a[bc]c', str1)
print(f"用字符集匹配{rs3}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
对于字符集来说,里面可以填上一些字符。
| 预定义字符集 | 匹配 |
|---|---|
| \d | 匹配数字0-9 |
| \D | 匹配^\d |
| \s | 匹配空白字符 |
| \S | 匹配非空白字符 |
| \w | 匹配普通字符,相当于[A-Za-z0-9_] |
| \W | 匹配非英语字母 |
除了以上的字符之外,还有一些数量词。它们一般用于字符或字符集之后。
| 数量词 | 说明 | 实例 | 结果 |
|---|---|---|---|
| * | 匹配前一个字符0或无限次 | abc* | ab,abccc |
| + | 匹配前一个字符1次或无限次 | abc+ | abc,abccc |
| ? | 匹配前一个字符0次或1次 | acb? | ab,abc |
| {m} | 匹配前一个字符m次 | ab{2}c | abbc |
1.4.2 re.findall()方法
re.findall(pattern,string,flag = 0)
- 扫描整个string字符串,返回所有与pattern匹配的列表
- pattern:正则表达式
- string:从那个字符串中寻找
- flags:匹配模式
import re
# 1 findall方法,返回匹配的结果列表
rs = re.findall('\d+', 'Misaki123')
# print(rs)
# 2 findall方法中,flag参数的作用
rs = re.findall('a.bc', 'a\nbc', re.DOTALL)
print(rs)
# 3 findall方法中分组的使用
rs = re.findall('a.+bc', 'a\nbc', re.DOTALL)
rs = re.findall('a(.+)bc', 'a\nbc', re.DOTALL)
print(rs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
在上面的操作中,我们使用小括号进行分组,其中分组是用于返回括号内匹配的结果,如果不加分组则返回整个字符串;当加了分组后,小括号两旁的字符串是用于定位的。
1.4.3 r原串的使用
在我们不使用r原串时,如果我们想要匹配转义符怎么匹配?我们需要四个斜杆。即如果想用正则表达式匹配\,则需要\\\\。
对于re模块来说,其为我们提供了r原串来解决上述的问题。我们来看一下下面的例子:
import re
# 1 不使用r原串,遇到转义符怎么办
rs = re.findall('a\\\nbc', 'a\nbc')
print(rs)
# 2 使用r原串
rs = re.findall(r'a\nbc', 'a\nbc')
print(rs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
1.4.4 案例
让我们来试着利用所学知识提取一下疫情的json字符串,注意,这里可能还有人不认识json是什么,下一讲我们会做阐述,这里我们应该关注的是,如何爬虫和如何正则匹配。
链接:全球新冠肺炎疫情地图 - 丁香园·丁香医生 (dxy.cn)
import requests
from bs4 import BeautifulSoup
import re
# 1 获取首页内容
# 发送请求,获取响应
response = requests.get('http://ncov.dxy.cn/ncovh5/view/pneumonia')
# 从响应中获取数据
page = response.content.decode()
# 2 提取各国疫情数据
# 构建bs对象
soup = BeautifulSoup(page, 'lxml')
# 查找标签
script = soup.find(id='getListByCountryTypeService2true')
# 获取标签内容
countries_text = script.text
# 提取json字符串
json_str = re.findall(r"(\[.*\])", countries_text)
print(json_str)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
1.5 json
1.5.1 json模块
JSON全名JavaScript Object Notation(JavaScript 对象表示法),它是存储和交换文本信息的语法,类似 XML。JSON 比 XML 更小、更快,更易解析。其和python数据类型区别如下:
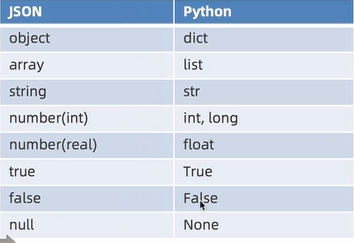
我们来看一段json的文件:
{
"sites": [
{ "name":"google" , "url":"www.google.com" },
{ "name":"微博" , "url":"www.weibo.com" }
]
}
- 1
- 2
- 3
- 4
- 5
- 6
python中提供了json模块,其可用于json格式的文件数据和python文件数据的相互转换。
如何实现装换呢?如果我们是要是json字符串转化为python类型数据的话,只需调用json.load(),将字符串传给构造器即可。
同样地,如果你想将json文件转为python类型的数据,那么首先要实例化json文件,让其变为对象,然后再将对象传入json.load()的构造器中。
import json
# 1 把json字符串转换为python数据
json_str = """{
"sites": [
{ "name":"google" , "url":"www.google.com" },
{ "name":"微博" , "url":"www.weibo.com" }
]
}"""
rs = json.loads(json_str)
# print(rs)
# 2 把json格式文件转换为python类型的数据
with open('Test.json') as fp:
python_list = json.load(fp)
print(python_list)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
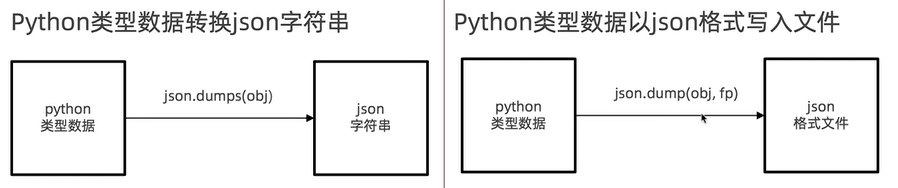
1.5.2 python转json
转换原理如下所示:
import json
# 1 python数据转换为json数据
# json转python
json_str = """{
"sites": [
{ "name":"google" , "url":"www.google.com" },
{ "name":"微博" , "url":"www.weibo.com" }
]
}"""
rs = json.loads(json_str)
# print(rs)
# python转json
json_str = json.dumps(rs, ensure_ascii=False)
# print(json_str)
# 2 把python以json格式存储到文件中
with open('test.json', 'w') as fp:
json.dump(rs, fp, ensure_ascii=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
1.5.3 案例
让我们继续1.4.4中json字符串转换为python的过程。
import json
import requests
from bs4 import BeautifulSoup
import re
# 1 获取首页内容
# 发送请求,获取响应
response = requests.get('http://ncov.dxy.cn/ncovh5/view/pneumonia')
# 从响应中获取数据
page = response.content.decode()
# 2 提取各国疫情数据
# 构建bs对象
soup = BeautifulSoup(page, 'lxml')
# 查找标签
script = soup.find(id='getListByCountryTypeService2true')
# 获取标签内容
countries_text = script.text
# 提取json字符串
json_str = re.findall(r"\[.*\]", countries_text)[0]
print(json_str)
# 3 把json字符串转换为python类型数据
last_day_corona_virus = json.loads(json_str)
print(last_day_corona_virus)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
文章来源: blog.csdn.net,作者:ArimaMisaki,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/chengyuhaomei520/article/details/123991496

- 点赞
- 收藏
- 关注作者
评论(0)