急了,Mysql索引中最不容易记的三个知识点通透了

【摘要】 Mysql索引中最不容易记的三个知识点通透了

🍁 作者:知识浅谈,CSDN签约讲师,CSDN博客专家,华为云云享专家,阿里云星级博主
📌 擅长领域:全栈工程师、爬虫、ACM算法
💒 公众号:知识浅谈
🔥 联系方式vx:zsqtcc
🤞索引失效➕索引下推➕changebuffer 总结🤞
正菜来了⛳⛳⛳
- 索引:Mysql中用于为了提高数据的查询效率构建的一个数据结构表,有唯一索引,普通索引,全文索引等。
- 索引字段:常选用区分度高的字段,where后查询条件频繁的字段,外键字段等,并不是所有的字段都创建索引就是最好的。
常见的索引失效的条件:
- 索引字段作为了函数参数;
- 索引字段在表达式中;
- 索引字段进行了隐式转换,就是 本来是数字类型,=后边用的是’123’ 有单引号,就会发生自动隐式转换,就无法使用索引;
- like模糊查询时候对应的%匹配符在前边;
- 范围查询后的字段无法使用索引;
温馨提醒:这个有点不太好理解
索引下推是在5.7时候引入的,5.7之前是没有索引下推这个功能的。
索引下推:是放生在联合索引且发生了回表查询的情况下,才有可能出发索引下推这个功能的。
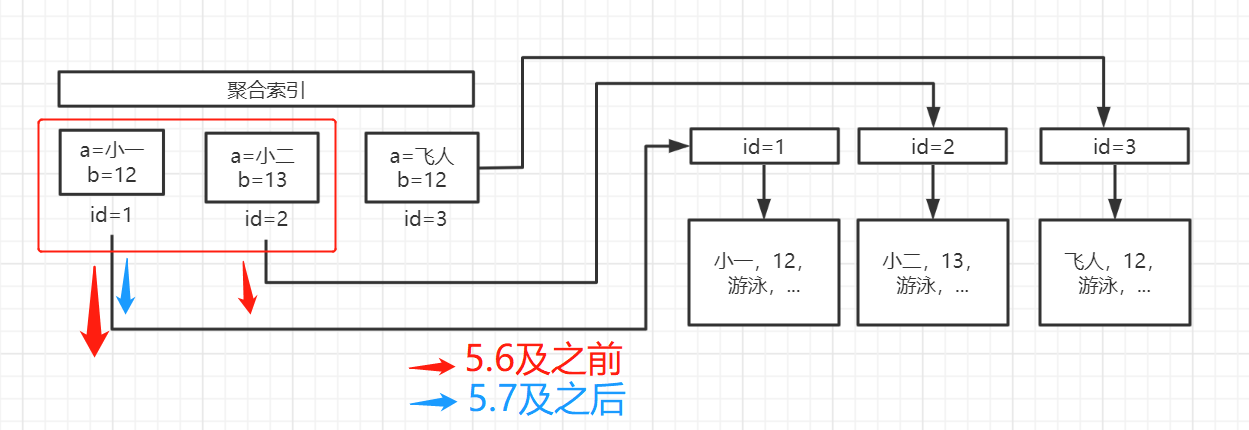
- 举个🌰:
table1字段中含有:a,b,c,d,e; 建立的联合索引为(a,b,c);
查询语句 select * from table1 where a like ‘小%’ and b=12 - 🌰解析:
因为使用到了联合索引,但是因为like使后边部分索引失效了,并且要查询所有字段信息,需要回表查询,但是如果是5.6之前的话,就需要一个个回表查询在匹配字段查找符合条件的即可,但是5.7及其之后的就可以先对聚合索引中b是否等于12这个条件判断,符合这个条件再回表,这个过程就叫做索引下推,区别就在去是否先判断聚合索引中是否有其他字段不满足条件,在进行回表。
和bufferpool有点类似的一块空间,这个changebuffer的作用就是如果更新相应字段数据的时候在内存中存在这个相应字段的数据,可以直接更新,如果没有存在,就可以考虑吧更新的内容写入到changebuffer中去,等到下一次查询或者数据库关闭或者规定时间之后就会更新到数据库,之所以有changebuffer,是因为在频繁更新的时候可以减少写入到磁盘的次数。
使用条件:一般使用在普通索引中,像是唯一索引就不可使用,因为当插入数据的时候因为唯一索引有唯一性的约束,插入的时候需要去遍历数据表中的数据是否是满足唯一性,只有满足了才可以插入,索引需要读取数据到内存中,这时候就用不上changgebuffer了。一般是用在更新频繁,查找不频繁的索引字段上,因为查找的时候会merge也就是更新到数据磁盘上。
补充:changebuffer也是可以持久化的数据,changebuffer不仅在内存中有拷贝,也会被写入到磁盘上。
这三个东西,这回算是整明白了。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)