应用开发和集成Apache Spark连接器

1. MySQL数据准备
1.1 MySQL数据说明
(1)数据库:movie
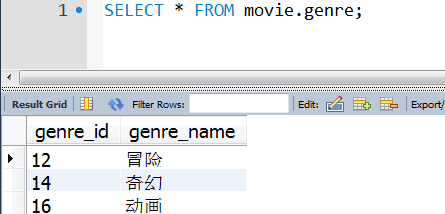
(2)genre:电影类别表
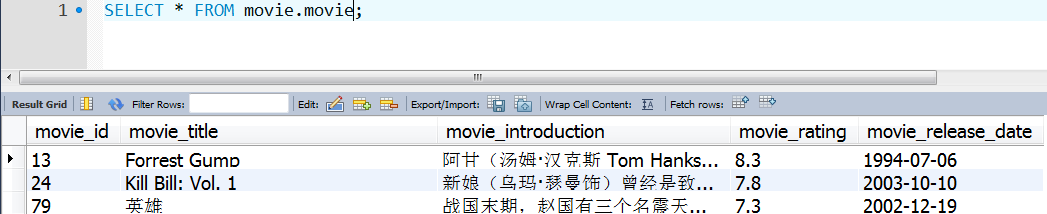
(3)movie:电影基本信息表
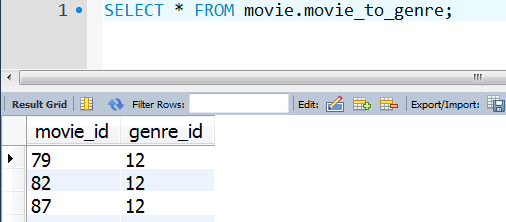
(4)movie_to_genre:电影与类别的对应关系 【电影id == 类别id】
(5)person:演员基本信息表

(6)person_to_movie:演员与电影对应的关系【演员id == 电影id】
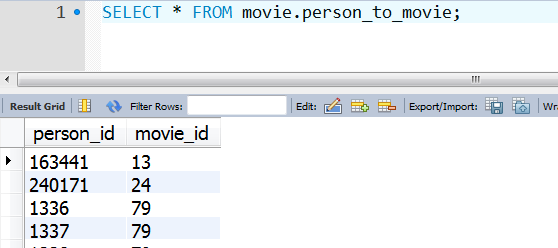
1.2 MySQL数据脚本语句
数据sql脚本下面提供了两种下载方式,如果你使用的mysql客户端可视化连接工具是:MySql WorkBench
可以使用如下的方式导入sql脚本数据
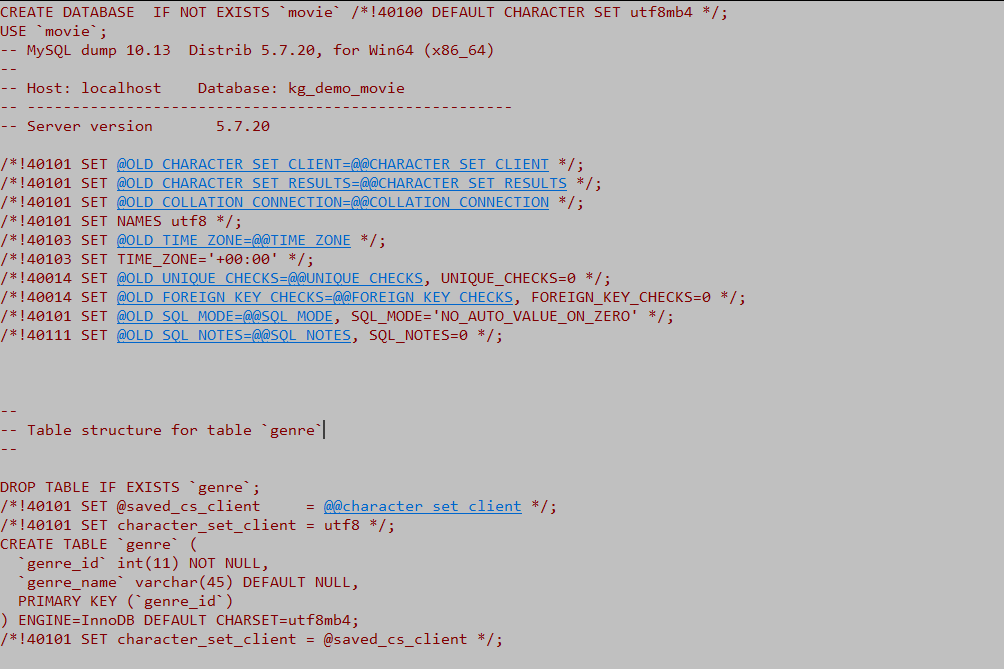
(1)脚本数据部分截图效果
(2)见文件夹中文件 movie_data_import.sql
1.3 MySQL数据导出CSV文件
由于要基于知识图谱进行问答系统的搭建,因此,我们需要把mysql中的数据转移到neo4j图形数据库中,为什么不直接用mysql构建我们的关系呢?
(1)首先我们简单说一下什么是Neo4j?
Neo4j是一个NoSQL的图数据库管理系统,它存储的结构和redis、mongodb一样,都是key-value的形式,因此查询性能是非常棒的,同样是查询电影和电影类别之间的关系,mysql需要用到select连接查询,而neo4j只需要一条cypher语句既能搞定,
(2)什么是cypher呢?
Neo4j使用Cypher查询图形数据,Cypher是描述性的图形查询语言,语法简单,功能强大,由于Neo4j在图形数据库家族中处于绝对的领先地位,拥有众多的用户基数,使得Cypher成为图形查询语言事实上的标准。
(3)为什么不使用MySql数据库呢?
上面第一点已经说过了,不是mysql干不了neo4j的工作,而是neo4j在处理节点(对象)关系这方面性能比较棒,而且查询语句简单,更容易构建我们的电影知识图谱,我们也可以将二者结合起来用,比如,mysql存储对象的详细信息,而对象之间的关系,我们可以存储到neo4j中,二者配合起来使用也是很不错的,而本系列文章中,博主采用neo4j来构建项目,mysql除了一开始提供数据以外,真的是被我完全给晾到一边了。
好了,我们来看一下,电影类别和电影之间的关系在neo4j图形数据中的效果展示吧。
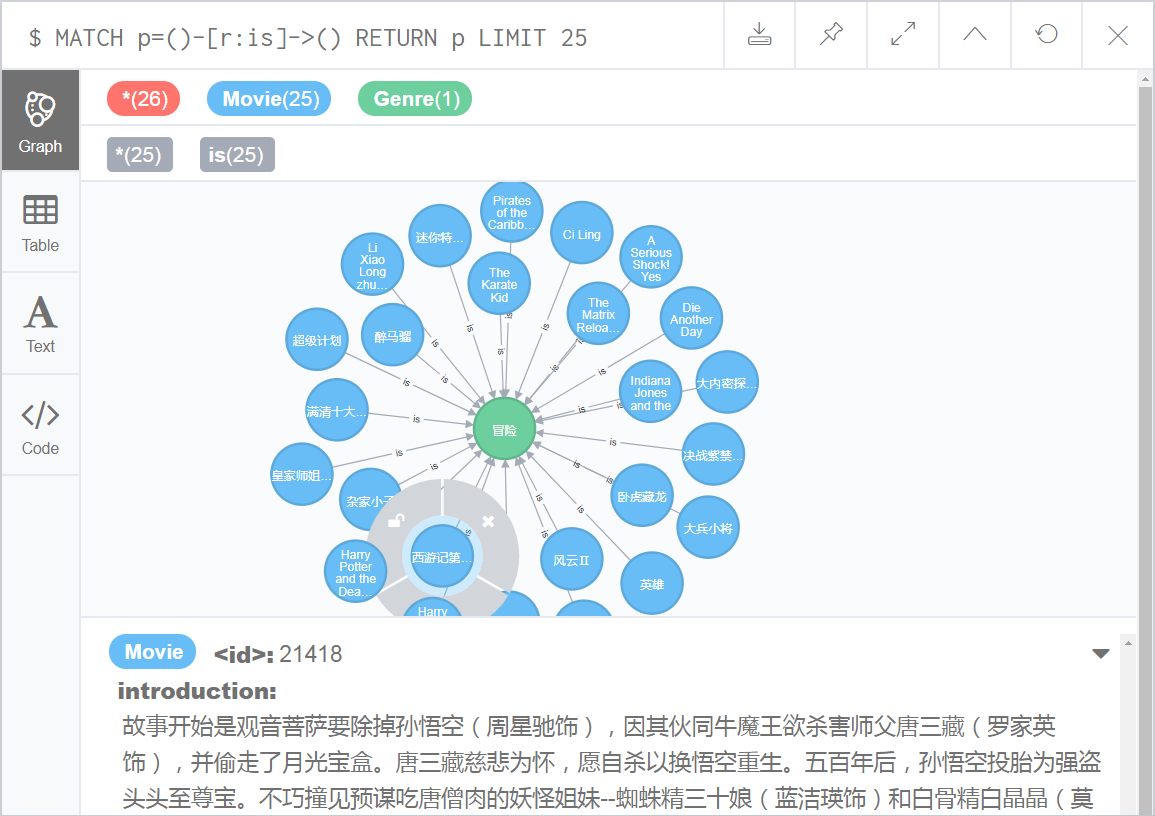
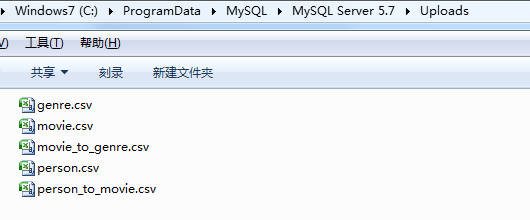
(4)mysql数据导出csv
由于mysql导出数据的默认目录是:安装路径\Uploads\,因此,我们导出csv的时候,一定要在这个目录下指定导出文件名,否则会提示权限不足,如果你有强迫症,可以自行修改mysql的配置文件改这个路径
导出sql脚本语句如下:
use movie;
#CMD命令 查看MySql的导入与导出的目录【其他目录无权限】
# 使用mysql -u root -p 连接mysql
# show variables like '%secure%'
#+--------------------------+------------------------------------------------+
#| Variable_name | Value |
#+--------------------------+------------------------------------------------+
#| require_secure_transport | OFF |
#| secure_auth | ON |
#| secure_file_priv | C:\ProgramData\MySQL\MySQL Server 5.7\Uploads\ |genregenre
#+--------------------------+------------------------------------------------+
#3 rows in set, 1 warning (0.00 sec)
#MySql导出csv数据,带表头
#导出电影的类型
SELECT * INTO OUTFILE 'C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/genre.csv'
FIELDS TERMINATED BY ','
FROM (select 'gid','gname' union select*from genre) genre_;
#导出电影的信息 == 如果太多可以只导出前500个,加限制
SELECT * INTO OUTFILE 'C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/movie.csv'
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\r' #电影描述中出现\r换行字符,
FROM (select 'mid','title','introduction','rating','releasedate' union select*from movie) movie_;
#导出演员person的信息 == 如果有中文名要中文名,如果没有取英文名
SELECT * INTO OUTFILE 'C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/person.csv'
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
FROM (select 'pid','birth','death','name','biography','birthplace' union
select person_id,person_birth_day,person_death_day,case when person_name is null then person_english_name else person_name end
as name,person_biography,person_birth_place from person) person_;
#导出电影ID和电影类别之间的对应 【1对1】
SELECT * INTO OUTFILE 'C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/movie_to_genre.csv'
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
FROM (select 'mid','gid' union select*from movie_to_genre) movie_to_genre_;
#导出演员ID和电影ID之间的对应 【1对多】
SELECT * INTO OUTFILE 'C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/person_to_movie.csv'
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
FROM (select 'pid','mid' union select*from person_to_movie) person_to_movie_;
#解决导出csv中文乱码问题:将csv用txt打开,另存为,选择utf8编码保存覆盖即可执行sql脚本语句后,效果如下

(5)导出的csv文件中文乱码
如果出现csv文件中中文乱码的情况,不要慌,我们可以采用下面的方法进行补救
1、选择问题csv文件,右键打开方式选 "记事本"
2、记事本打开后,选择菜单"文件"下拉框中的另存为
3、打开另存为对话框后,最下面的文件编码格式选择"UTF-8"
4、文件名不用动,然后选择保存,覆盖源文件即可解决中文乱码问题。
至此,我们的数据csv文件算是有了,下一步就是,如何将这些csv文件导入到我们的图形数据库Neo4j中了。
2.Neo4j导入CSV文件
2.1 Neo4j默认导入目录路径
比如我的neo4j安装根路径在D盘下,其默认的导入文件的入口文件夹是
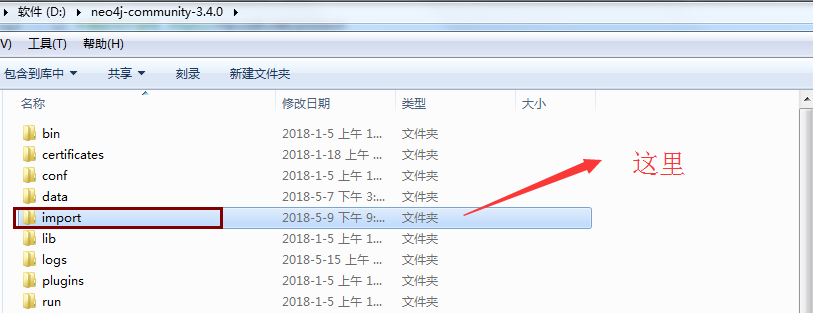
如果没有,请自行创建这个文件夹。
随后我们将我们从mysql导出的csv文件copy到这个文件夹下面
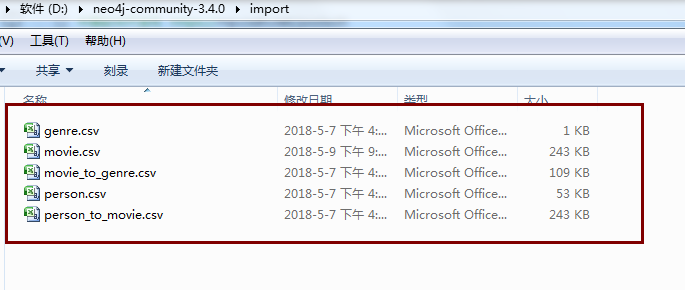
和mysql的导出默认文件夹一样,neo4j的导入文件夹也是默认好的,如果你导入csv文件选择了其他文件夹下,则会报目录不存在或者目录权限不足,如果你有强迫症,可以自行修改默认设置的导入文件夹路径。
2.2 Neo4j导入CSV文件
(1)csv文件导入neo4j语句
找到neo4j的安装路径,并在D:\neo4j-community-3.4.0\目录下创建import目录
完整路径如下D:\neo4j-community-3.4.0\import
因为neo4j支持导入csv文件,其默认目录入口是 ...\import
//导入节点 电影类型 == 注意类型转换
LOAD CSV WITH HEADERS FROM "file:///genre.csv" AS line
MERGE (p:Genre{gid:toInteger(line.gid),name:line.gname})
//导入节点 演员信息
LOAD CSV WITH HEADERS FROM 'file:///person.csv' AS line
MERGE (p:Person { pid:toInteger(line.pid),birth:line.birth,
death:line.death,name:line.name,
biography:line.biography,
birthplace:line.birthplace})
// 导入节点 电影信息
LOAD CSV WITH HEADERS FROM "file:///movie.csv" AS line
MERGE (p:Movie{mid:toInteger(line.mid),title:line.title,introduction:line.introduction,
rating:toFloat(line.rating),releasedate:line.releasedate})
// 导入关系 actedin 电影是谁参演的 1对多
LOAD CSV WITH HEADERS FROM "file:///person_to_movie.csv" AS line
match (from:Person{pid:toInteger(line.pid)}),(to:Movie{mid:toInteger(line.mid)})
merge (from)-[r:actedin{pid:toInteger(line.pid),mid:toInteger(line.mid)}]->(to)
//导入关系 电影是什么类型 == 1对多
LOAD CSV WITH HEADERS FROM "file:///movie_to_genre.csv" AS line
match (from:Movie{mid:toInteger(line.mid)}),(to:Genre{gid:toInteger(line.gid)})
merge (from)-[r:is{mid:toInteger(line.mid),gid:toInteger(line.gid)}]->(to)
-- 问:章子怡都演了哪些电影?
match(n:Person)-[:actedin]->(m:Movie) where n.name='章子怡' return m.title
-- 删除所有的节点及关系
MATCH (n)-[r]-(b)
DELETE n,r,b由于csv导入neo4j的数据都是字符串的数据类型,因此,对于一些有特殊要求的字段,我们需要在导入的时候进行类型转换
比如

再比如

语句一个个执行,最终执行完在neo4j中的的效果如下
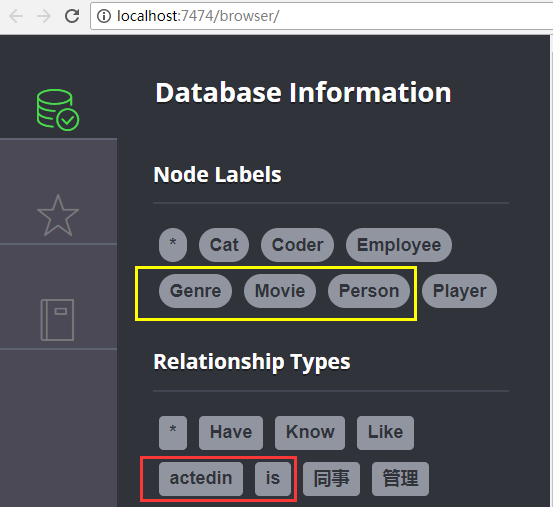
(2)我们利用cypher语句查询一下关系actedin
match (n)-[r:actedin]-(b) return n,r,b limit 10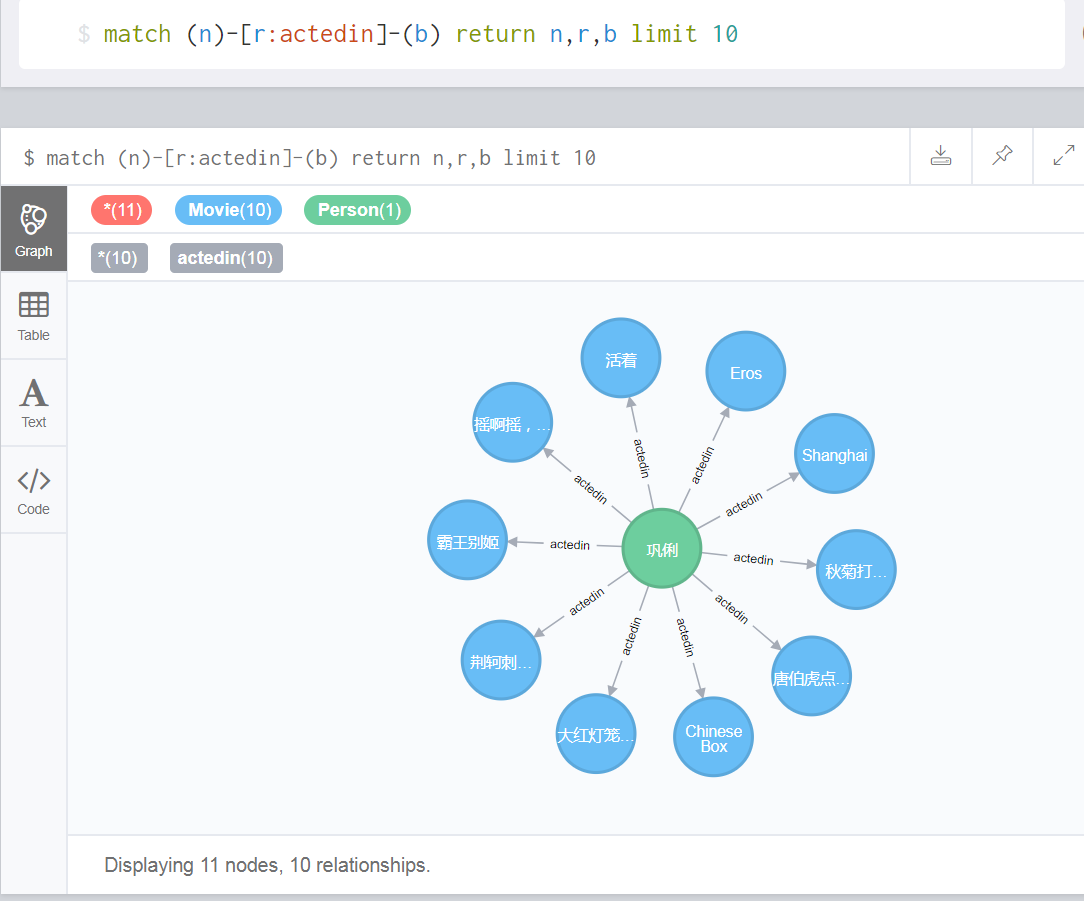
(3)CSV数据包可从文件夹中获得:import.rar
3. Spark环境搭建
由于该项目后期会涉及到spark的朴素贝叶斯分类器,而该分类器可以通过训练问题集合进行问题模板概率匹配,因此,系统中是否搭建了spark环境对项目是否能run起来至关重要。
3.1 工具包及环境搭建简易说明
由于工具包比较大,涉及scala语言安装包、hadoop安装包以及spark-hadoop安装包,见文件夹中的 spark环境搭建.zip
3.2 Windows下Spark环境的搭建
3.3 验证Spark环境是否搭建成功
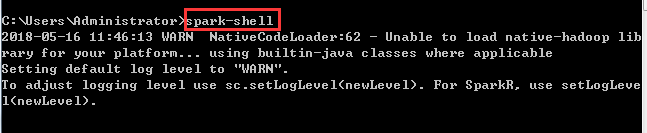
(1)任意目录下,运行 Win+R,并输入spark-shell脚本命令,测试spark
什么是spark-shell?
spark-shell是提供给用户即时交互的一个命令窗口,你可以在里面编写spark代码,然后根据你的命令进行相应的运算
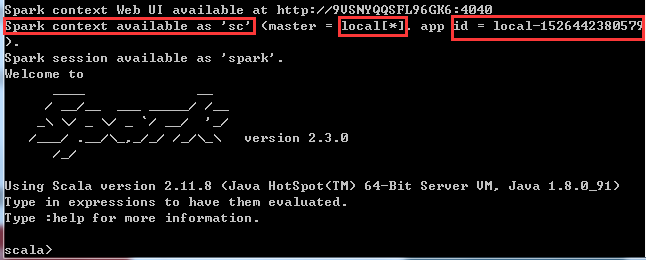
(2)实例化SparkContext对象
什么是SparkContext?
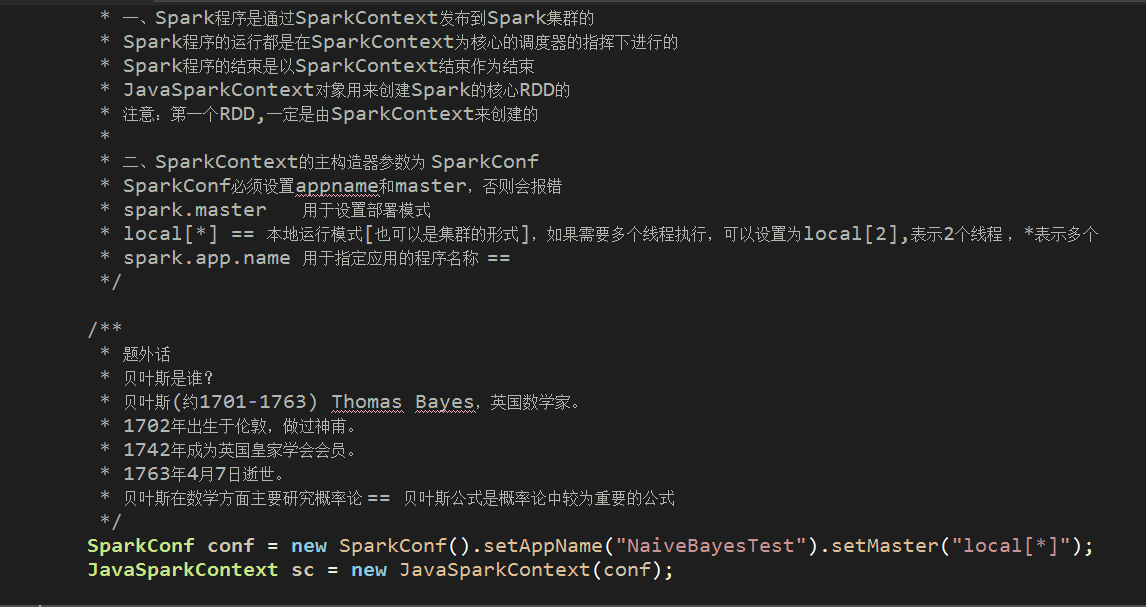
SparkContext是编写Spark程序用到的第一个类,其中包含了Spark程序用到的几乎所有的核心对象,可见其重要性
master:local[*] == 本地运行模式[也可以是集群的形式],*表示多个线程并行执行
在Java中实例化SparkContext对象的demo如下
(3)通过scala语言,编写spark代码,利用reduce计算集合1,2,3,4,5的和
通过调用SparkContext的parallelize方法,在一个已经存在的Scala集合上创建一个Seq对象。集合的对象将会被拷贝,创建出一个可以被并行操作的分布式数据集RDD
体现在Java中的demo如下

体现在脚本语言中如下:
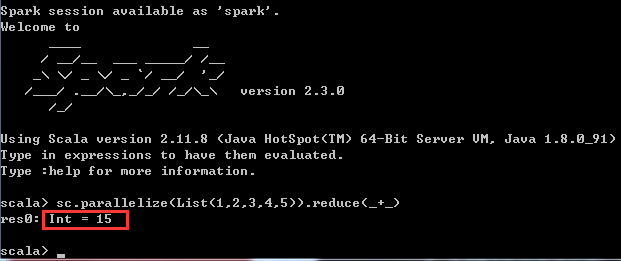
关于reduce,有点类似于Python的高阶函数reduce,有兴趣的可以参考博文:Python3学习(12)--高阶函数 (二)
4. HanLP分词器
4.1 什么是分词器?
分词器,是将用户输入的一段文本,分析成符合逻辑的一种工具。到目前为止呢,分词器没有办法做到完全的符合人们的要求。和我们有关的分词器有英文的和中文的分词器:输入文本-关键词切分-去停用词-形态还原-转为小写中文的分词器分为:
单子分词 例:中国人 分成中,国,人
二分法人词 例:中国人 分成中国,国人
词典分词 例:中国人 分成中国,国人,中国人
现在用的是极易分词和庖丁分词
停用词:不影响语意的词
分词器有很多,比如中文分词器 IK Analyzer,有兴趣的可以看一篇博文,其中有介绍它和Solr的结合使用。
Solr 7.2.1 配置中文分词器 IK Analyzer
4.2 什么是HanLP分词器?
首先:分词器≠自然语言处理!
其次:HanLP也是一种分词器
最后:HanLP不仅能够分词,而且还可以标注单词的词性(这个很关键的,后面章节会再次讲到这个特性)
比如,在Java中随便来个句子使用HanLP进行分词如下:
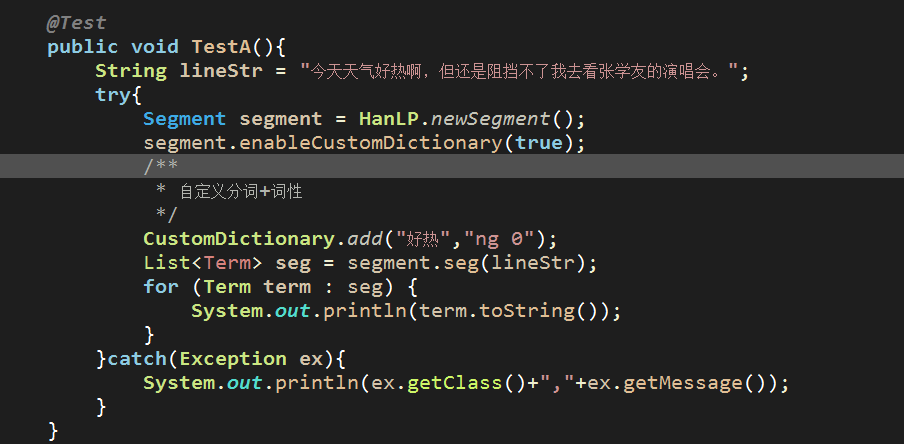
这里我们还额外添加了自己的分词,比如好热啊中的“好热”,我们添加后并标注其词性为ng,当然ng是我们随便起的
执行这段代码,分词效果如下

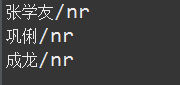
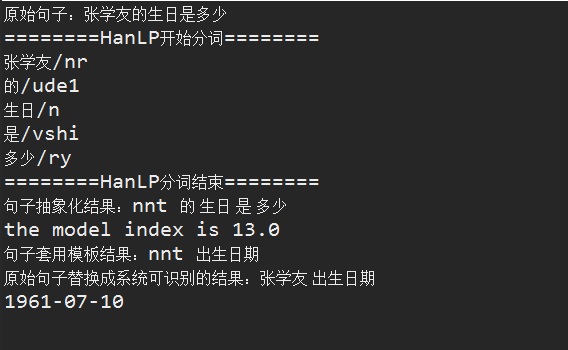
这种词性标注有什么好处呢? 比如,所有人名均可以用nr这个标签来替代,思考下如下3个问题
1、张学友的生日是什么时候
2、巩俐的生日是什么时候
3、成龙的生日是什么时候
如果用HanLP分词后,相信 张学友 、巩俐、成龙的词性均是nr,不信的话,请看下面的截图
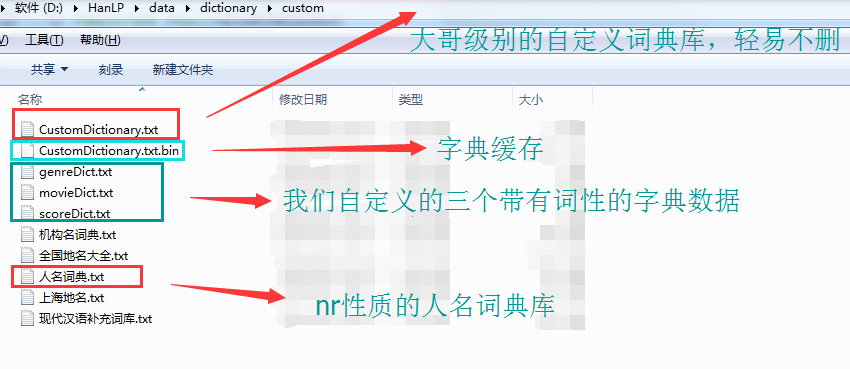
为什么HanLP会有这种能力呢? (博文下面会讲到如何在Spring-Boot项目中集成HanLP)
因为其有一堆的字/词典数据集,其中就包括了人名这个dict,如下
因此,针对1、2、3的问题,我们可以将其做成一个问题模板,如下
nr的生日是什么时候
于是乎,不管你问上述三个哪一个问题,我得到最终答案的步骤如下:
1、拿到原始句子(问题)
2、对原句子进行抽象,将人名用nr替换并抽象句子,比如张学友的生日是多少替换成nr的生日是多少
3、抽象句子匹配问题模板(一堆问题数据集合由Spark进行训练并计算),比如 nr 生日
4、问题模板还原成最终的问题,比如 nr 生日,替换其中的nr=张学友,最后效果就是 张学友 生日
5、拿到问题后,去图形数据库neo4j中查找问题的答案,比如

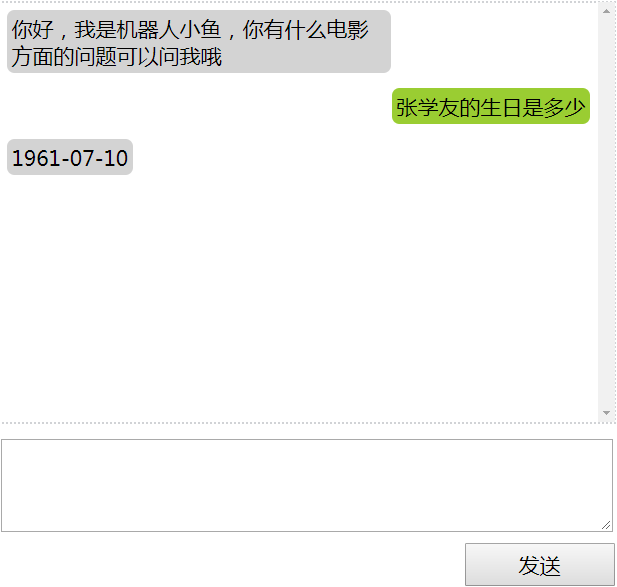
项目中使用HanLP+Spark的效果如下
前端展示如下
4.3 HanLP下载安装
官方地址:https://github.com/hankcs/HanLP https://github.com/hankcs/HanLP/releases
(1)由于我们要集成到Spring-Boot中,因此,需要用到配置文件 hanlp-1.7.8-release/hanlp.properties
 。
。
 。
。(2)有了配置文件后,我们需要下载HanLP的字典数据集
(3)上述两步完成后,接下来就是集成到我们的项目中使用了
4.4 Spring-Boot集成HanLP
(1)pom依赖
<!-- JUnit单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</dependency>
<!-- HanLP汉语言处理包 -->
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.8</version>
</dependency>(2)添加HanLP属性配置文件【基于上述下载下来的】
(3)hanlp.properties属性文件说明
其实也没有什么好说明的,文件里面的注释已经很详细了,唯一注意一点的是这个地方:
!每次更新自定义的新词典xxx.txt的内容时,要删除同目录下的词典缓存文件CustomDictionary.txt.bin!
删除后,重启项目会报一个警告的错误,我们不用理会,由于HanLP会加载数据集到内存中,因此启动的过程会有点慢,等待HanLP加载完数据后,我们就可以使用它了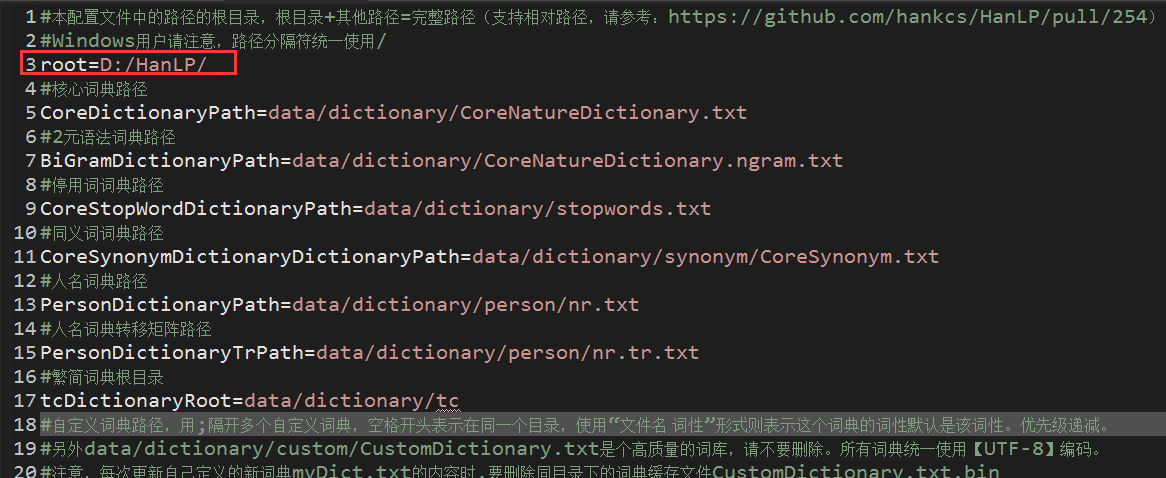
4.5 HanLP单元测试
HanLPTest.java
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.dictionary.CustomDictionary;
import com.hankcs.hanlp.seg.Segment;
import com.hankcs.hanlp.seg.common.Term;
import org.junit.Test;
import java.util.List;
public class HanLPTest {
@Test
public void TestA(){
String lineStr = "明天虽然会下雨,但是我还是会看周杰伦的演唱会。";
try{
Segment segment = HanLP.newSegment();
segment.enableCustomDictionary(true);
/**
* 自定义分词+词性
*/
CustomDictionary.add("好热","ng 0");
List<Term> seg = segment.seg(lineStr);
for (Term term : seg) {
System.out.println(term.toString());
}
}catch(Exception ex){
System.out.println(ex.getClass()+","+ex.getMessage());
}
}
}执行结果如下:
明天/t
虽然/c
会/v
下雨/vi
,/w
但是/c
我/rr
还是/c
会/v
看/v
周杰伦/nr
的/ude1
演唱会/n
。/w
5. Spark朴素贝叶斯分类器
5.1 什么是贝叶斯分类器
贝叶斯分类器主要有四种,分别是:Naive Bayes、TAN、BAN和GBN
由于涉及算法,比较抽象,想了解详情的请参考博文:分类算法之朴素贝叶斯分类(Naive Bayesian classification)
如果上面你看完还是一时接受不了这个算法,那么,我就发挥一下,简明扼要形象的说一下我的理解
假如辨别男人的特征是: 短头发,运动鞋,大鼻梁
假如辨别女人的特征是: 长头发,高跟鞋,皮肤白
这些特征当然不能百分百辨别一个人的性别,比如,女人也可以留短发,女人也可以穿运动鞋,但是,如果我给你两个特征,让你断定下这个人的性别是什么,比如我给你的两个特征是
短头发,运动鞋
你第一反应这个人肯定是男人,如果我说你说错了,这个人是个女性,那么你就尴尬了,别慌,如果给你1000个人,都是这样的特征,再让你猜每个人的性别,答案会怎么样呢?
必然是这1000个人里面性别为男性的概率要大于女性的概率,不要问为什么,因为我知道女生天性爱美,就短头发一点,很多女性都做不到吧,至少我身边的异性是这样的。
如果只是给你一个人的话,你不敢说这话,因为男女占比各一半,但是我给你多加个特征提示,比如
短发,运动鞋,喉结
你第一反应肯定是男人,没错,喉结是男性的象征,但是,我可以告诉你女性雄性激素过高也可以有喉结,变形人说不定也有喉结,,这时候你又慌了,别急,还是同上,给你1000个测试数据,让你做判断,结果肯定是出现男性的概率要大于女性。
因此,概率最大的那个才是我们最终要的结果,而且特征越多,越能根据测试数据进行最大化的概率匹配,得到的答案越是准确。
分类哪去了?
假如我说,上面已经涉及到了分类了,你们有没有发现呢?
男性是一个分类标签,女性也是一个分类标签,而得到一个测试数据属于哪个分类标签的过程就是贝叶斯分类器算法该干的事。
5.2 Java代码实现贝叶斯分类器
注意了,注意了,注意了,下面是本篇的精华所在,千万不要打盹!!!
(1)我们把男性和女性的特征做一个合并
总共6列
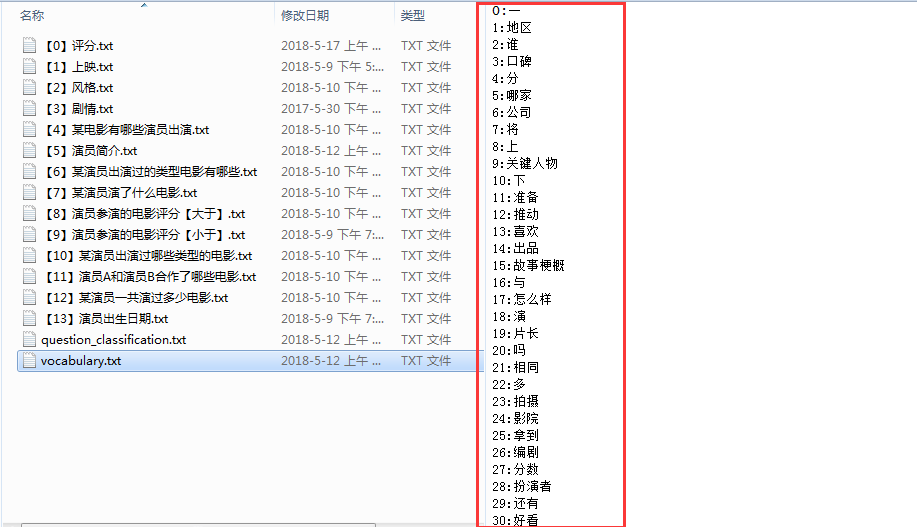
短发(1) 长发(2) 运动鞋(3) 高跟鞋(4) 喉结(5) 皮肤白(6)
我们可以将上述这些关键特征做成词汇表,比如下面的这种【当然本篇只是举个例子,后续章节会继续提到】
(2)假设男性的特征有:短发、运动鞋、喉结这三个,则其分类标签的向量表示我们可以用
(1,0,1,0,1,0) ==> 1表示对应的特征向量值等于true【有】,0表示false【无】
(3)假设女性的特征有:长发、短发、运动鞋、高跟鞋、皮肤白这五个,则其分类标签的向量表示我们可以用
(1,1,1,1,0,1) == 1表示对应的特征向量值等于true【有】,0表示false【无】
(4)假设我们提供了一个人的测试数据,其具有短发(1),运动鞋(3)这两个特征,则用向量表示我们可以用
(1,0,1,0,0,0)== 1表示对应的特征向量值等于true【有】,0表示false【无】
(5)实例化SparkContext对象
/**
* 本地模式,*表示启用多个线程并行计算
*/
SparkConf conf = new SparkConf().setAppName("NaiveBayesTest").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);(6)定义男性和女性两种分类的向量
/**
* MLlib的本地向量主要分为两种,DenseVector和SparseVector
* 前者是用来保存稠密向量,后者是用来保存稀疏向量
*/
/**
* 两种方式分别创建向量 == 其实创建稀疏向量的方式有两种,本文只讲一种
* (1.0, 0.0, 1.0, 0.0, 1.0, 0.0)
* (1.0, 1.0, 1.0, 1.0, 0.0, 1.0)
*/
//稠密向量 == 连续的
Vector vMale = Vectors.dense(1,0,1,0,1,0);
//稀疏向量 == 间隔的、指定的,未指定位置的向量值默认 = 0.0
int len = 6;
int[] index = new int[]{0,1,2,3,5};
double[] values = new double[]{1,1,1,1,1};
//索引0、1、2、3、5位置上的向量值=1,索引4没给出,默认0
Vector vFemale = Vectors.sparse(len, index, values);
女性的向量我就不解释了吧,对照特征词汇表自己翻译。
这里,你可以打印两种向量对象,看看输出值是什么,比如,这里我打印稀疏向量vFemale的值,效果如下

(7)生成训练集,类型 == LabelPoint
/**
* labeled point 是一个局部向量,要么是密集型的要么是稀疏型的
* 用一个label/response进行关联
* 在MLlib里,labeled points 被用来监督学习算法
* 我们使用一个double数来存储一个label,因此我们能够使用labeled points进行回归和分类
* 在二进制分类里,一个label可以是 0(负数)或者 1(正数)
* 在多级分类中,labels可以是class的索引,从0开始:0,1,2,......
*/
//训练集生成 ,规定数据结构为LabeledPoint == 构建方式:稠密向量模式 ,1.0:类别编号 == 男性
LabeledPoint train_one = new LabeledPoint(1.0,vMale); //(1.0, 0.0, 1.0, 0.0, 1.0, 0.0)
//训练集生成 ,规定数据结构为LabeledPoint == 构建方式:稀疏向量模式 ,2.0:类别编号 == 女性
LabeledPoint train_two = new LabeledPoint(2.0,vFemale); //(1.0, 1.0, 1.0, 1.0, 0.0, 1.0)
//我们也可以给同一个类别增加多个训练集
LabeledPoint train_three = new LabeledPoint(2.0,Vectors.dense(0,1,1,1,0,1)); 
训练样本集越多,贝叶斯分类器算法得到的分类结果越精确。
(8)List集合存放训练集样本
//List存放训练集【三个训练样本数据】
List<LabeledPoint> trains = new ArrayList<>();
trains.add(train_one);
trains.add(train_two);
trains.add(train_three);(9)获得JavaRDD
/**
* SPARK的核心是RDD(弹性分布式数据集)
* Spark是Scala写的,JavaRDD就是Spark为Java写的一套API
* JavaSparkContext sc = new JavaSparkContext(sparkConf); //对应JavaRDD
* SparkContext sc = new SparkContext(sparkConf) ; //对应RDD
* 数据类型为LabeledPoint
*/
JavaRDD<LabeledPoint> trainingRDD = sc.parallelize(trains); (10)JavaRDD转RDD【Scala】,并利用贝叶斯分类器对RDD数据集进行训练
/**
* 利用Spark进行数据分析时,数据一般要转化为RDD
* JavaRDD转Spark的RDD
*/
NaiveBayesModel nb_model = NaiveBayes.train(trainingRDD.rdd());(11)模拟测试集数据 == 稠密向量【一个人拥有特征:短发,运动鞋】
//测试集生成 == 以下的向量表示,这个人具有特征:短发(1),运动鞋(3)
double [] dTest = {1,0,1,0,0,0};
Vector vTest = Vectors.dense(dTest);//测试对象为单个vector,或者是RDD化后的vector(12)贝叶斯分类器分类测试
//朴素贝叶斯用法
int modelIndex =(int) nb_model.predict(vTest);
System.out.println("标签分类编号:"+modelIndex);// 分类结果 == 返回分类的标签值
/**
* 计算测试目标向量与训练样本数据集里面对应的各个分类标签匹配的概率结果
*/
System.out.println(nb_model.predictProbabilities(vTest));
if(modelIndex == 1){
System.out.println("答案:贝叶斯分类器推断这个人的性别是男性");
}else if(modelIndex == 2){
System.out.println("答案:贝叶斯分类器推断这个人的性别是男性");
}这一步才算是结果计算:分类器拿到测试数据样本,并和已经训练好的训练集样本进行概率匹配,而训练集样本又是有分类标签号标注的,因此,贝叶斯分类器最后计算返回的结果就是概率最大的那个分类标签号,也就是下面我会提到的问题模板的索引
(13)最后一步,别忘了关闭sc资源
//最后不要忘了释放资源
sc.close();5.3 完整demo
关键pom依赖【如果demo跑不起来,先配置Spark环境】
<!-- JUnit单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.0</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-mllib -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>janino</artifactId>
</dependency>BayesTest.java
import java.util.ArrayList;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.mllib.classification.NaiveBayes;
import org.apache.spark.mllib.classification.NaiveBayesModel;
import org.apache.spark.mllib.linalg.Vector;
import org.apache.spark.mllib.linalg.Vectors;
import org.apache.spark.mllib.regression.LabeledPoint;
import org.junit.Test;
public class BayesTest {
@Test
public void TestA(){
/**
* 本地模式,*表示启用多个线程并行计算
*/
SparkConf conf = new SparkConf().setAppName("NaiveBayesTest").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
/**
* MLlib的本地向量主要分为两种,DenseVector和SparseVector
* 前者是用来保存稠密向量,后者是用来保存稀疏向量
*/
/**
* 两种方式分别创建向量 == 其实创建稀疏向量的方式有两种,本文只讲一种
* (1.0, 0.0, 1.0, 0.0, 1.0, 0.0)
* (1.0, 1.0, 1.0, 1.0, 0.0, 1.0)
*/
//稠密向量 == 连续的
Vector vMale = Vectors.dense(1,0,1,0,1,0);
//稀疏向量 == 间隔的、指定的,未指定位置的向量值默认 = 0.0
int len = 6;
int[] index = new int[]{0,1,2,3,5};
double[] values = new double[]{1,1,1,1,1};
//索引0、1、2、3、5位置上的向量值=1,索引4没给出,默认0
Vector vFemale = Vectors.sparse(len, index, values);
//System.err.println("vFemale == "+vFemale);
/**
* labeled point 是一个局部向量,要么是密集型的要么是稀疏型的
* 用一个label/response进行关联
* 在MLlib里,labeled points 被用来监督学习算法
* 我们使用一个double数来存储一个label,因此我们能够使用labeled points进行回归和分类
* 在二进制分类里,一个label可以是 0(负数)或者 1(正数)
* 在多级分类中,labels可以是class的索引,从0开始:0,1,2,......
*/
//训练集生成 ,规定数据结构为LabeledPoint == 构建方式:稠密向量模式 ,1.0:类别编号 == 男性
LabeledPoint train_one = new LabeledPoint(1.0,vMale); //(1.0, 0.0, 1.0, 0.0, 1.0, 0.0)
//训练集生成 ,规定数据结构为LabeledPoint == 构建方式:稀疏向量模式 ,2.0:类别编号 == 女性
LabeledPoint train_two = new LabeledPoint(2.0,vFemale); //(1.0, 1.0, 1.0, 1.0, 0.0, 1.0)
//我们也可以给同一个类别增加多个训练集
LabeledPoint train_three = new LabeledPoint(2.0,Vectors.dense(0,1,1,1,0,1));
//List存放训练集【三个训练样本数据】
List<LabeledPoint> trains = new ArrayList<>();
trains.add(train_one);
trains.add(train_two);
trains.add(train_three);
/**
* SPARK的核心是RDD(弹性分布式数据集)
* Spark是Scala写的,JavaRDD就是Spark为Java写的一套API
* JavaSparkContext sc = new JavaSparkContext(sparkConf); //对应JavaRDD
* SparkContext sc = new SparkContext(sparkConf) ; //对应RDD
* 数据类型为LabeledPoint
*/
JavaRDD<LabeledPoint> trainingRDD = sc.parallelize(trains);
/**
* 利用Spark进行数据分析时,数据一般要转化为RDD
* JavaRDD转Spark的RDD
*/
NaiveBayesModel nb_model = NaiveBayes.train(trainingRDD.rdd());
//测试集生成 == 以下的向量表示,这个人具有特征:短发(1),运动鞋(3)
double [] dTest = {1,0,1,0,0,0};
Vector vTest = Vectors.dense(dTest);//测试对象为单个vector,或者是RDD化后的vector
//朴素贝叶斯用法
int modelIndex =(int) nb_model.predict(vTest);
System.out.println("标签分类编号:"+modelIndex);// 分类结果 == 返回分类的标签值
/**
* 计算测试目标向量与训练样本数据集里面对应的各个分类标签匹配的概率结果
*/
System.out.println(nb_model.predictProbabilities(vTest));
if(modelIndex == 1){
System.out.println("答案:贝叶斯分类器推断这个人的性别是男性");
}else if(modelIndex == 2){
System.out.println("答案:贝叶斯分类器推断这个人的性别是女性");
}
//最后不要忘了释放资源
sc.close();
}
}5.4 运行效果

明显,根据提供的两个特征,短发和运动鞋,贝叶斯分类器计算的最终答案是男性,因为,具有该特征的男性的概率要大于具有该特征的女性的概率
如果你对这个结果抱有怀疑的态度,你可以再加个特征,高跟鞋(4),试一试
![]()
测试数据集向量数组: double [] dTest = {1,0,1,1,0,0};
效果截图

为什么有高跟鞋特征是女性的概率不是百分百或是百分之九十呢?
首先,短发和运动鞋,这两个特征男性和女性的可能性都有
其次,高跟鞋虽然是女性的特征,但却不是唯一能决定性别走向的因素,因为短发的男生也是有可能穿高跟鞋的,因此,我们不难发现,贝叶斯概率公式真的很NB,他不是乱来的,你以为穿高跟鞋的绝对是女性,但是贝叶斯分类器告诉你,这种概率只有59%,而不是100%!!!
如果还不过瘾,我们再来测试一组,比如一个人具有特征:短发(1),高跟鞋(4),喉结(5)
![]()
测试数据集向量: double [] dTest = {1,0,0,1,1,0};
按理说,有男性特征喉结,就能说明这个人八九不离十就是男性,我们看一下贝叶斯分类器的计算结果是否和我们的猜想吻合。

没毛病,概率和现实很贴切。
我们再来个特征多一点的,比如一个人具有特征:长发(2),运动鞋(3),高跟鞋(4),皮肤白(6)
![]()
备注说明:这个人除了头发固定是长发外,鞋子自备了两双,换着换,其实最关键的是Ta没有喉结!!!
测试数据集向量: double [] dTest = {0,1,1,1,0,1};
最后运行结果

女性的概率居然高达:88.7%
6. 问题训练样本集敲定
根据上面,我们利用朴素贝叶斯分类器(Naive Bayes Model)简单玩了一个男女性别分类的demo,如果你细心的从头到尾跟了一遍demo并进行本机测试后,你会发现,其实分类器的工作原理很简单,总结一下,主要有五点:
1、生成(或外部文件加载)训练集样本 【样本:LabelPoint类型,再细一点就是double数组构造的稠密/稀疏向量】
2、生成(或外部参数传进)测试数据样本【样本:LabelPoint类型,再细一点就是double数组构造的稠密/稀疏向量】
3、根据训练样本集合由SparkContext实例创建出一个可以被并行操作的分布式数据集JavaRDD
4、贝叶斯分类器训练RDD【注意:这一步必须把上一步的JavaRDD类型转RDD后在交由分类器进行训练(train)】
5、贝叶斯分类器拿着测试数据样本跟训练的数据进行概率预测(predict),最后返回我们定义的类别标签号
由于本系列文章是和电影知识挂钩的,前面基于此预热了好几篇了,一直没有进入正题(不预热不行啊,如果一上来就进入主题,估计大伙会吃不消,除非你自己私下里有进行预热,),接下来,我们继续.....
6.1 敲定训练样本集【数据集在文章最后会提供链接供大家参考】
(1)电影评分 == 训练样本数据集如下
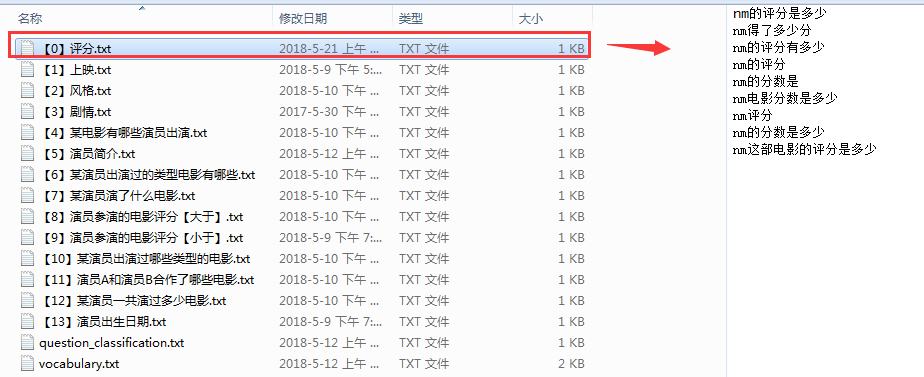
注:我先讲一下这个训练数据集是怎么敲定的,以及它的一些细节,比如,如果训练样本数据少了,会不会和其他的问题模板分类串频了,留个悬念,待会揭晓!!!
我们知道要想从电影知识系统里面查找某个电影的影评分数是多少,只需要确定两个字段条件就Ok了,比如,如果我知道电影名是《卧虎藏龙》,而我又知道查询的是这部电影的分数,那么,在neo4j中,就可以精确的match到答案了,如下:
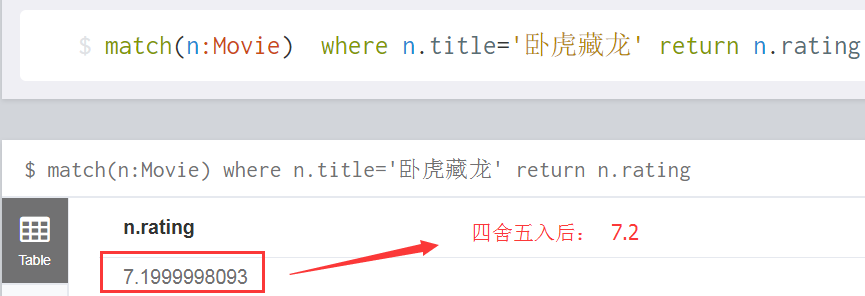
如何精准的从neo4j图库中匹配问题的答案呢?
由于关于电影的分数自然语句的问法有好几种,比如上述中设定好的问题集合
nm的评分是多少
nm得了多少分
nm的评分有多少
nm的评分
nm的分数是
nm电影分数是多少
nm评分
nm的分数是多少
nm这部电影的评分是多少
而我们需要精确的答案,针对上述这些问题集合,我们有必要将其归为一类,问来问去,其实主题思想就一个----nm 分数
如何进行问题模板的分类划分呢?
别忘了,上一篇我们可是预热过了朴素贝叶斯分类器的用法的,本篇直接拿来用!!!
(2)电影评分的分类Model == 标签号如下
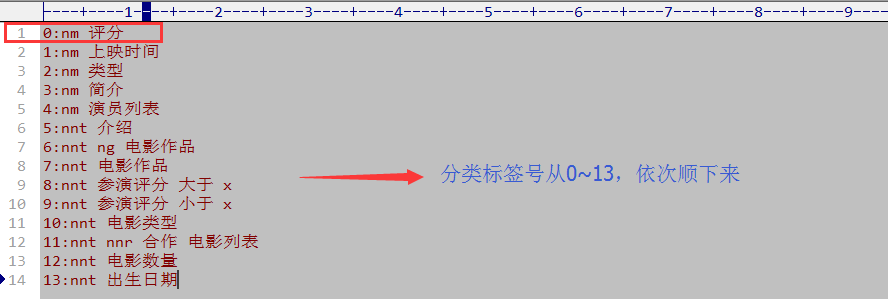
还记得上一节这行demo吗?

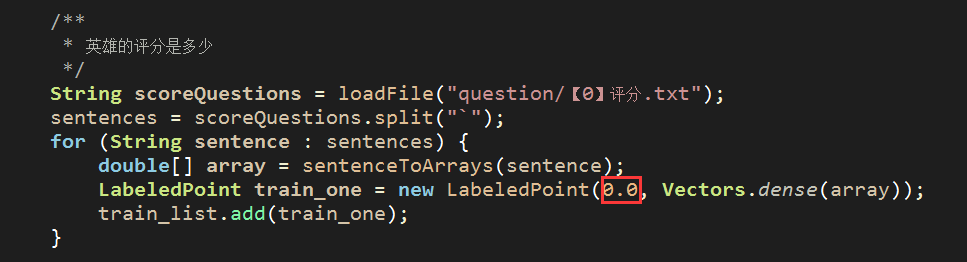
对照我们设定的 0:nm 评分问题模板,可以在deom中替换成
(3)如何构造稠密向量,也就是LabelPoint的第二个参数
比如训练样本数据:nm的评分是多少
我们需提取训练样本数据里面的关键特征词,如: “评分”、“多少”
就像上一篇样本数据集男性的特征有:“短发”、“喉结”、“运动鞋”一样
如何提取?
当然是采用HanLP进行分词提取了,而我们构造向量的时候,一定要有个词汇数据集进行比对,有的话,就置为1,没有话就默认0,像这样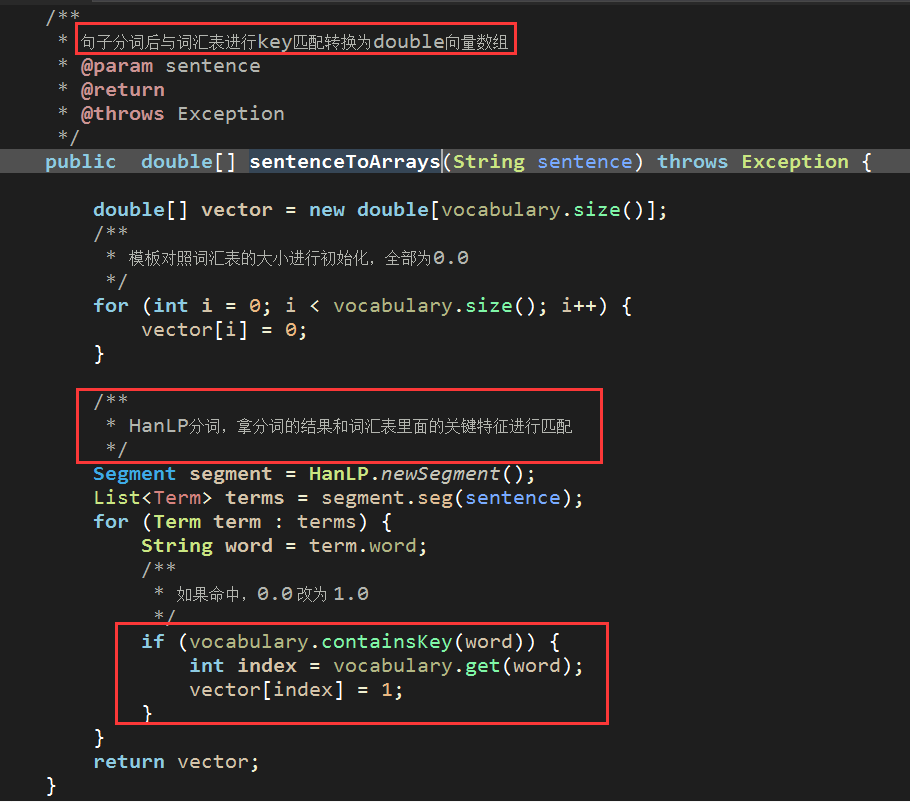
因此,我们需要提供demo中的vocabulary数据集,而这个数据集我已经添加过了,如下:


这样的话,"nm的评分是多少"构建向量的效果如下:
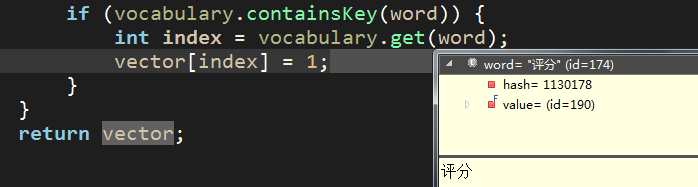
index = 137 【对应词汇表中的key值】
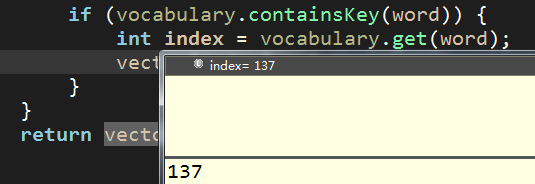
找到后,double向量数组该处设置为1 【其余分词特征不再一一演示说明】
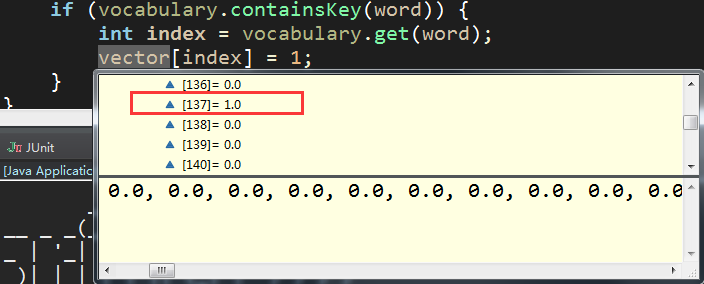
(4)利用Spark朴素贝叶斯分类器对问题测试数据进行分类
例如:卧虎藏龙的分数是多少
注:测试数据也是需要构造向量的,构造向量的方法和训练样本构造向量的方式一样,都是对数据先进行HanLP分词拿到特征词后,与特征词汇表进行比对构造double数组的,如下【sentenceToArrays为数据转double数组的通用方法】:

万事俱备,只欠东风! == 有了样本集,也有了测试数据,我们来演示一下贝叶斯分类器如何对测试数据进行问题模板的分类。
测试demo截图如下:【文章最后会放出数据集和贝叶斯分类器核心单元ModelProcess】
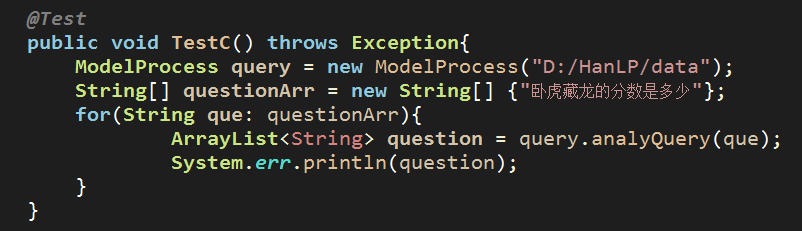
运行效果如下:

注:由于在测试单元中我们没有对HanLP的自定义词典进行个性化设置,因此,这里的卧虎藏龙没有被完整的识别,请忽略!
完整演示如下【先忽略查询结果,这个放在下一篇结合neo4j的查询语句再一起讲】:

6.2 训练样本集不容忽视的问题
上一篇我们提到了,要想分类的结果更精确,就只能让训练样本集更加的多,还拿电影评分这个训练集来说,如果我们把样本数据改为一行的话,如下

我们看一下,再问一次:卧虎藏龙的分数是多少,会出现什么情况
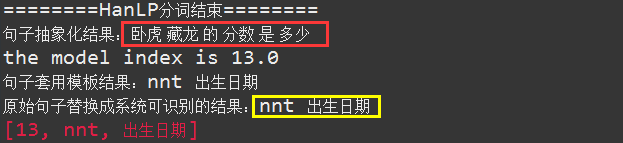
我去,这回分类的结果居然匹配到了问题模板13,我们看一下13这个训练集样本都有哪些

首先这个13的训练样本有好几个,而且其中关于“多少”的特征词有两个【还不包括“的”、“是”】,如果比命中数的话,肯定是分类13对应的概率高一些,信不信我们看数据说话,如下:
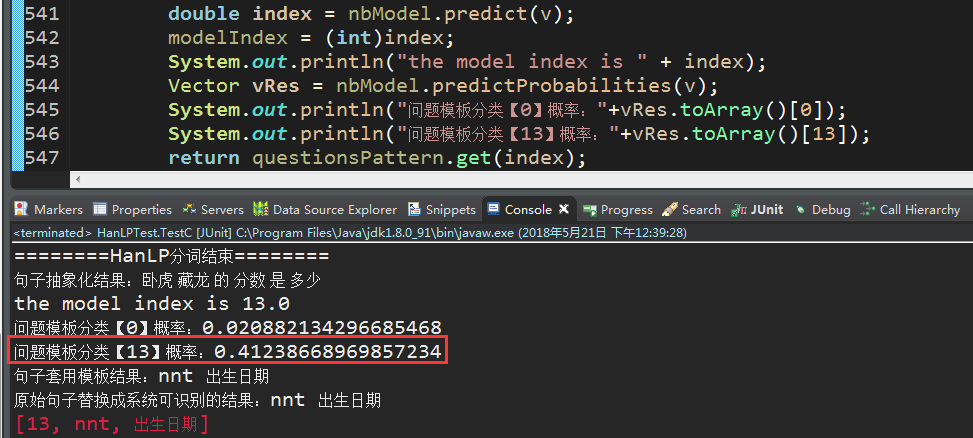
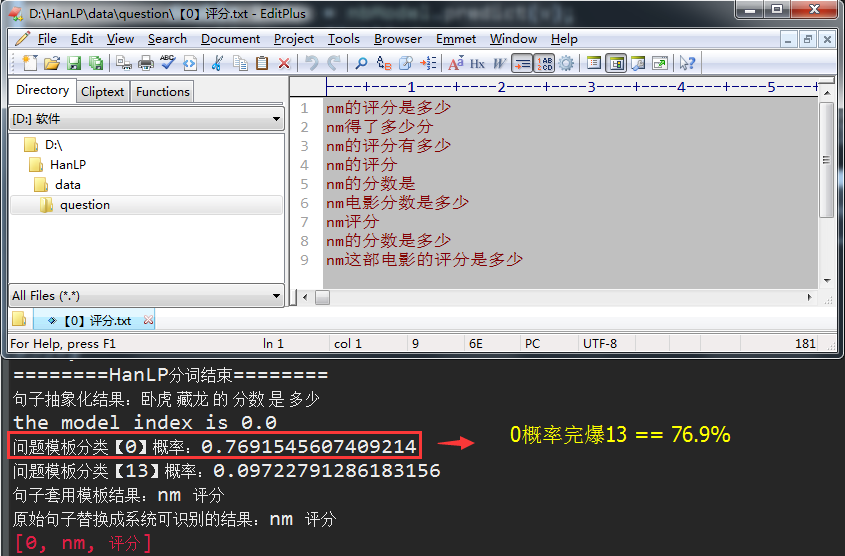
由于分类0的训练集太少了,导致最后的结果串频了,不是我们想要的,唯一补救的措施,就是不断的调整训练集的样本数,使得问题的归类结果更加的精确,比如,恢复到之前的样本数据集,我们再来测试一遍:
6.3 样本数据集和贝叶斯分类器核心代码下载链接

见本地文件夹 question_code/
6.4 最后附上本篇的单元测试demo
import java.util.ArrayList;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.mllib.classification.NaiveBayes;
import org.apache.spark.mllib.classification.NaiveBayesModel;
import org.apache.spark.mllib.linalg.Vector;
import org.apache.spark.mllib.linalg.Vectors;
import org.apache.spark.mllib.regression.LabeledPoint;
import org.junit.Test;
import com.appleyk.process.ModelProcess;
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.dictionary.CustomDictionary;
import com.hankcs.hanlp.seg.Segment;
import com.hankcs.hanlp.seg.common.Term;
public class HanLPTest {
@Test
public void TestA(){
String lineStr = "明天虽然会下雨,但是我还是会看周杰伦的演唱会。";
try{
Segment segment = HanLP.newSegment();
segment.enableCustomDictionary(true);
/**
* 自定义分词+词性
*/
CustomDictionary.add("虽然会","ng 0");
List<Term> seg = segment.seg(lineStr);
for (Term term : seg) {
System.out.println(term.toString());
}
}catch(Exception ex){
System.out.println(ex.getClass()+","+ex.getMessage());
}
}
@Test
public void TestB(){
HanLP.Config.Normalization = true;
CustomDictionary.insert("爱听4G", "nz 1000");
System.out.println(HanLP.segment("爱听4g"));
System.out.println(HanLP.segment("爱听4G"));
System.out.println(HanLP.segment("爱听4G"));
System.out.println(HanLP.segment("爱听4G"));
System.out.println(HanLP.segment("愛聽4G"));
}
@Test
public void TestC() throws Exception{
ModelProcess query = new ModelProcess("D:/HanLP/data");
String[] questionArr = new String[] {"卧虎藏龙的分数是多少"};
for(String que: questionArr){
ArrayList<String> question = query.analyQuery(que);
System.err.println(question);
}
}
@Test
public void TestRDD(){
SparkConf conf = new SparkConf().setAppName("NaiveBayesTest").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
/**
* MLlib的本地向量主要分为两种,DenseVector和SparseVector
* 前者是用来保存稠密向量,后者是用来保存稀疏向量
*/
/**
* 两种方式分别创建向量 == 其实创建稀疏向量的方式有两种,本文只讲一种
* (1.0, 0.0, 2.0)
* (2.0, 3.0, 0.0)
*/
//稠密向量 == 连续的
Vector dense = Vectors.dense(1.0,0.0,2.0);
System.out.println(dense);
//稀疏向量 == 间隔的、指定的,未指定位置的向量值默认 = 0.0
int len = 3;
int[] index = new int[]{0,1};
double[] values = new double[]{2.0,3.0};
Vector sparse = Vectors.sparse(len, index, values);
/**
* labeled point 是一个局部向量,要么是密集型的要么是稀疏型的
* 用一个label/response进行关联
* 在MLlib里,labeled points 被用来监督学习算法
* 我们使用一个double数来存储一个label,因此我们能够使用labeled points进行回归和分类
* 在二进制分类里,一个label可以是 0(负数)或者 1(正数)
* 在多级分类中,labels可以是class的索引,从0开始:0,1,2,......
*/
//训练集生成 ,规定数据结构为LabeledPoint == 构建方式:稠密向量模式 ,1.0:类别编号
LabeledPoint train_one = new LabeledPoint(1.0,dense); //(1.0, 0.0, 2.0)
//训练集生成 ,规定数据结构为LabeledPoint == 构建方式:稀疏向量模式 ,2.0:类别编号
LabeledPoint train_two = new LabeledPoint(2.0,sparse); //(2.0, 3.0, 0.0)
//训练集生成 ,规定数据结构为LabeledPoint == 构建方式:稠密向量模式 ,3.0:类别编号
LabeledPoint train_three = new LabeledPoint(3.0,Vectors.dense(1,1,2)); //(1.0, 1.0, 2.0)
//List存放训练集【三个训练样本数据】
List<LabeledPoint> trains = new ArrayList<>();
trains.add(train_one);
trains.add(train_two);
trains.add(train_three);
//获得弹性分布式数据集JavaRDD,数据类型为LabeledPoint
JavaRDD<LabeledPoint> trainingRDD = sc.parallelize(trains);
/**
* 利用Spark进行数据分析时,数据一般要转化为RDD
* JavaRDD转Spark的RDD
*/
NaiveBayesModel nb_model = NaiveBayes.train(trainingRDD.rdd());
//测试集生成
double [] dTest = {2,1,0};
Vector vTest = Vectors.dense(dTest);//测试对象为单个vector,或者是RDD化后的vector
//朴素贝叶斯用法
System.err.println(nb_model.predict(vTest));// 分类结果 == 返回分类的标签值
/**
* 计算测试目标向量与训练样本数据集里面对应的各个分类标签匹配的概率结果
*/
System.err.println(nb_model.predictProbabilities(vTest));
//最后不要忘了释放资源
sc.close();
}
}7. Neo4j语句那点事
到目前为止,本系列文章快接近尾声了,本篇是该系列文章的倒数第二篇,本来想打算直接跳过进入最后一章的,但是感觉有必要再讲一下neo4j,博主的文章中不止一次介绍过neo4j的使用,但感觉还是不够细致,所以,借助着这个系列文章,再来捋一下neo4j语句的用法,希望给用惯了传统关系型sql语句的兄弟们一个喜欢上Cypher语句的契机!!!
下面,我将一步步的创建节点、创建关系、创建索引、修改属性、删除属性,删除节点、删除关系、删除索引...etc
总结起来就是【数据的操作万变不离其宗】: 增删改查!!!
数据模型参照:美国男子职业篮球联赛【NBA】
7.1 创建节点【create】
第一种方式: merge(n:洛杉矶湖人) == 节点不存在,则创建,存在,则忽略
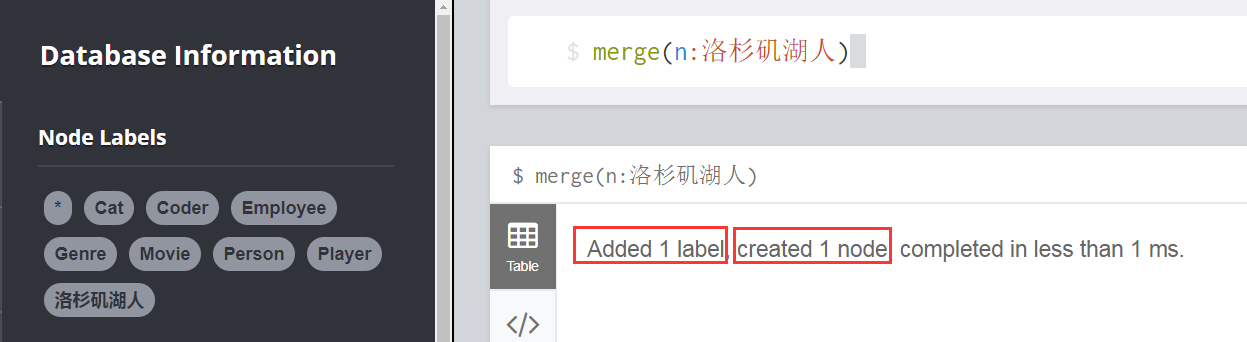
第二种方式: create(n:洛杉矶湖人) == 不管节点存不存在,创建
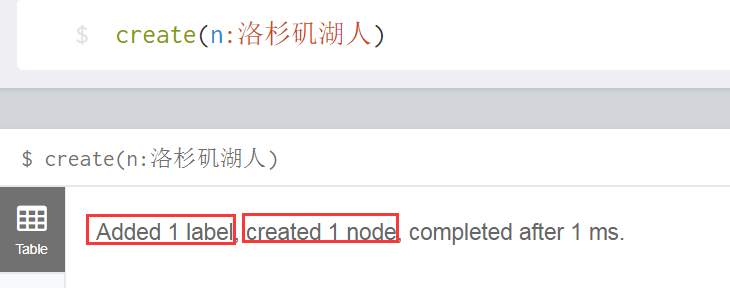
效果就是,洛杉矶湖人这类的节点,一共被创建了两次,因此,查询的时候,会出现两个Node
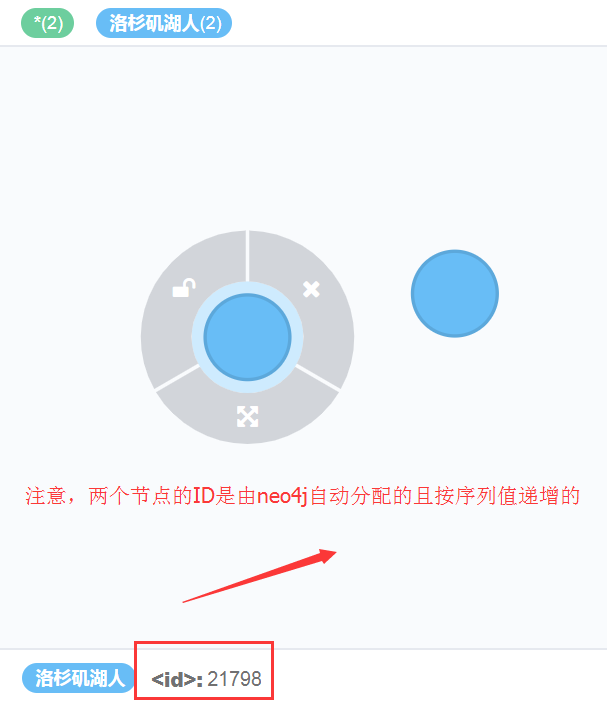
虽然上面我们创建了两个节点,但是这两个节点除了系统给的唯一id外,没有其他属性,下面我就基于这两个节点,分别对它们进行“update”,赋予节点意义
7.2 修改节点的属性
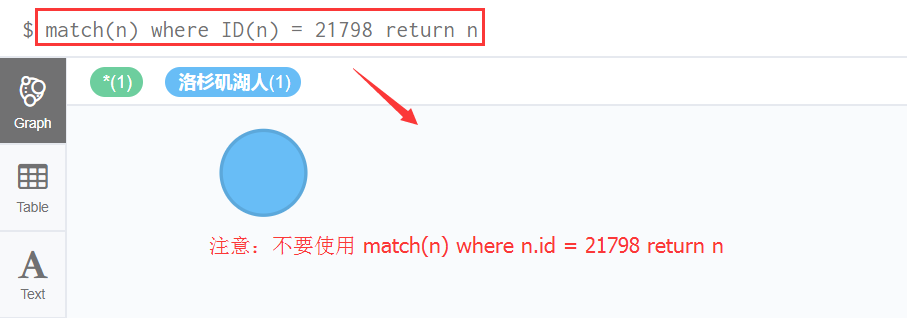
(1)首先:查询ID等于21798的Node
match(n) where ID(n) = 21798 return n == 别忘了查询节点,最后要return n返回节点
(2)其次:给该Node添加三个属性,分别是label(节点标签名),height(身高),position(场上位置)
neo4j查询节点用:match == 相当于关系型数据库的select,相当于非关系数据库mongodb的find
neo4j修改节点属性用:set == 相当于关系型数据库的update...set...
直接接着上面的语句写set:
match(n) where ID(n) = 21798 set n.label='科比',n.height=198,n.position='得分后卫' return n
类似sql语句: update n set label = ‘科比’,height=198,position='得分后卫' where id = 21798
区别:关系型数据库如果字段不存在的话会报错,而NoSql数据库neo4j,如果属性字段不存在的话,就添加。
执行后,效果如下:
(3)如果想删除节点的height属性该怎么做呢?
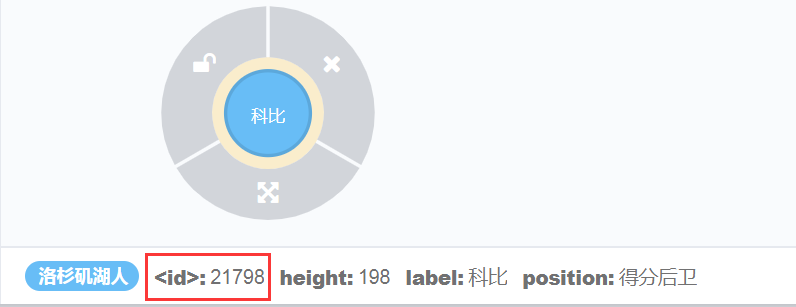
上面说过,设置【添加】属性用set,而删除属性在neo4j中用remove,比如移除点节点的身高属性做法如下
match(n) where ID(n) = 21798 remove n.height return n
执行语句,效果如下
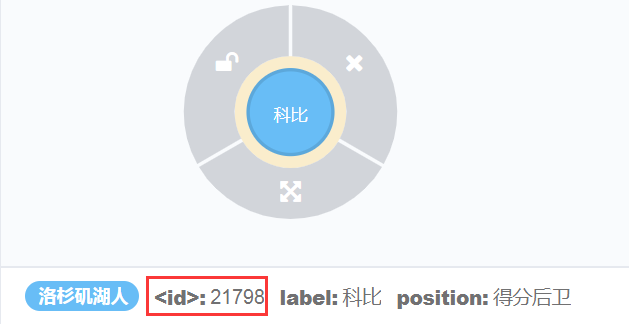
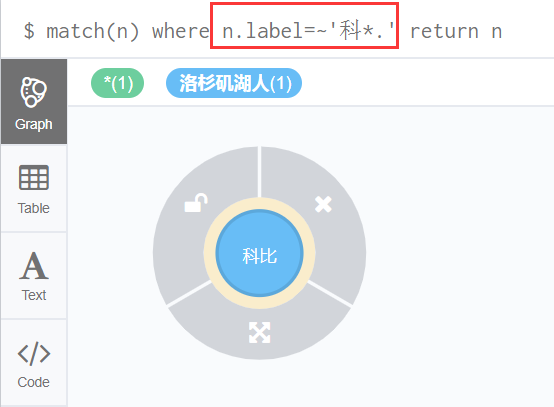
(4)模糊查询:查询属性值label开头是“科”其余任意值的节点信息
match(n) where n.label=~'科*.' return n
执行语句效果如下:
7.3 创建带属性值的节点
我们使用create创建另一位湖人传奇巨星奥尼尔这个节点,语句如下:
create(n:洛杉矶湖人{label:'奥尼尔',height:216,position:'中锋'}) return n
效果如下:

注意:不要写成 如下这种方式的cypher语句
7.4 删除没有意义的节点
(1)我们先查出所有和湖人队有关的节点有哪些
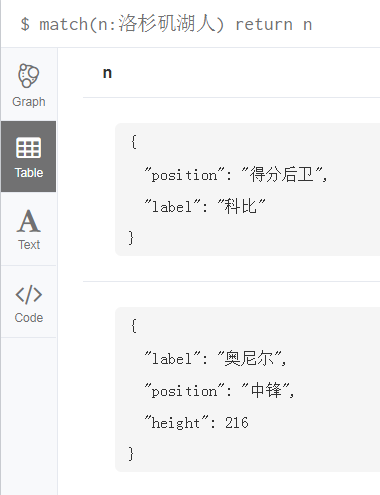
match(n:洛杉矶湖人) return n
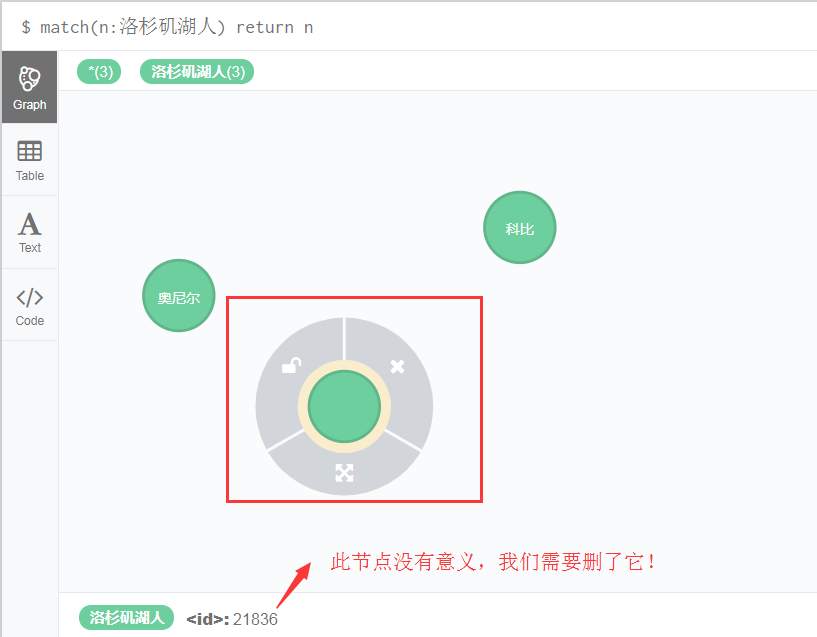
(2)删除节点id=21836的节点
neo4j中不管是删除节点还是删除关系,都是用delete命令进行删除,注意,删除哪个节点必须先查【match】出来:
match(n:洛杉矶湖人) where ID(n) = 21836 delete n
执行【回车键或者执行按钮】效果如下:
(3)这样一来,我们只保留了两个节点,一个是湖人队的科比,一个是巨无霸奥尼尔
五、创建关系
由于关系不能独立存在【比如我吃米钱,如果只有吃这个关系,没有谁来吃,吃什么的话,你知道关系吃是什么玩意嘛,如果你说不出来,那我可以说出一万种这种关系的出处,】,而构成一条关系最基本的要素是要有两个对象,放在neo4j图库中就是,两个节点,一条边,才能称作是一个完整的关系。
创建统一用create命令,而关系的创建,实际上和创建节点差不多,唯一区别就是,关系是有方向的,而且关系用‘[]’表示,而节点用'()'表示。
下面我给目前尚存在的两个节点,科比和奥尼尔创建一条关系,关系的name叫“搭档”,这种关系,不区分方向,因此,无所谓谁是startNode,谁是endNode。
创建语句如下:
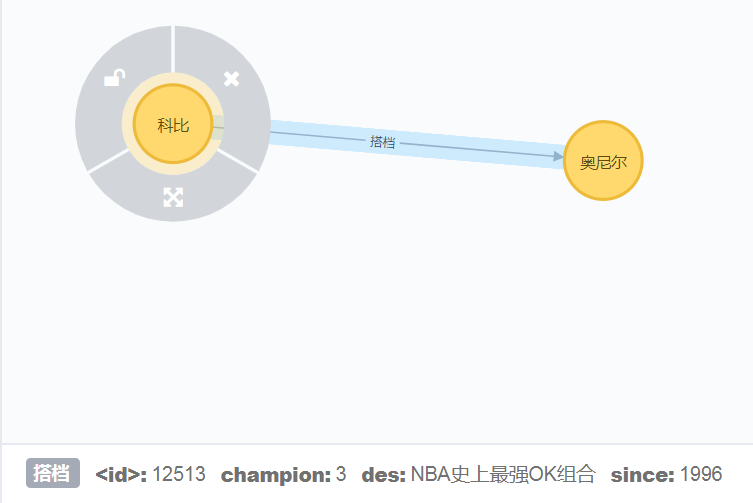
match(n),(b) where n.label='科比' and b.label='奥尼尔'
create(n)-[r:搭档{since:1996,des:'NBA史上最强OK组合',champion:3}]->(b)
return n,r,b解释一下:
1、首先匹配找到节点n和b,也就是科比和奥尼尔代表的节点Node
2、然后创建节点n到节点b的关系r,r有三个属性,一个是从哪一年开始since,一个是关系描述des,另一个是合作拿过的冠军数量champion
3、最后返回n,r,b 完整节点之间的关系结果,table数据如下,总过三列:

graph图效果如下:
7.6 修改关系属性
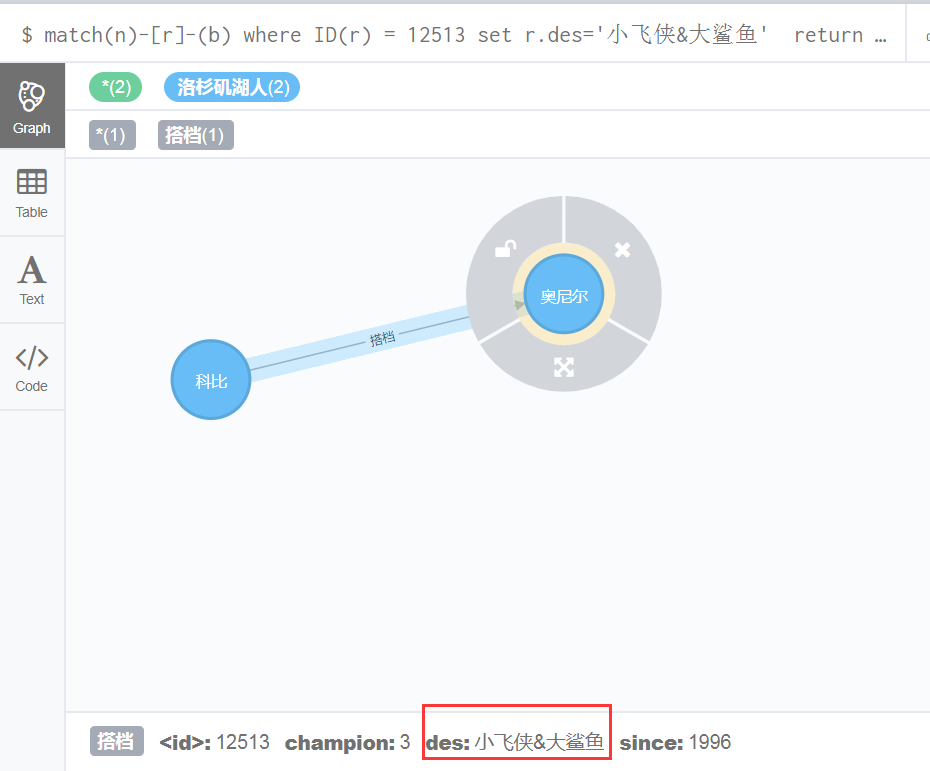
和修改节点的属性一样,修改关系的属性也用set,如修改id等于12513的关系的属性des为“小飞侠&大鲨鱼”的语句如下:
match(n)-[r]-(b) where ID(r) = 12513 set r.des='小飞侠&大鲨鱼'
return n,r,b效果图如下:
7.7 删除节点科比和奥尼尔之间的关系
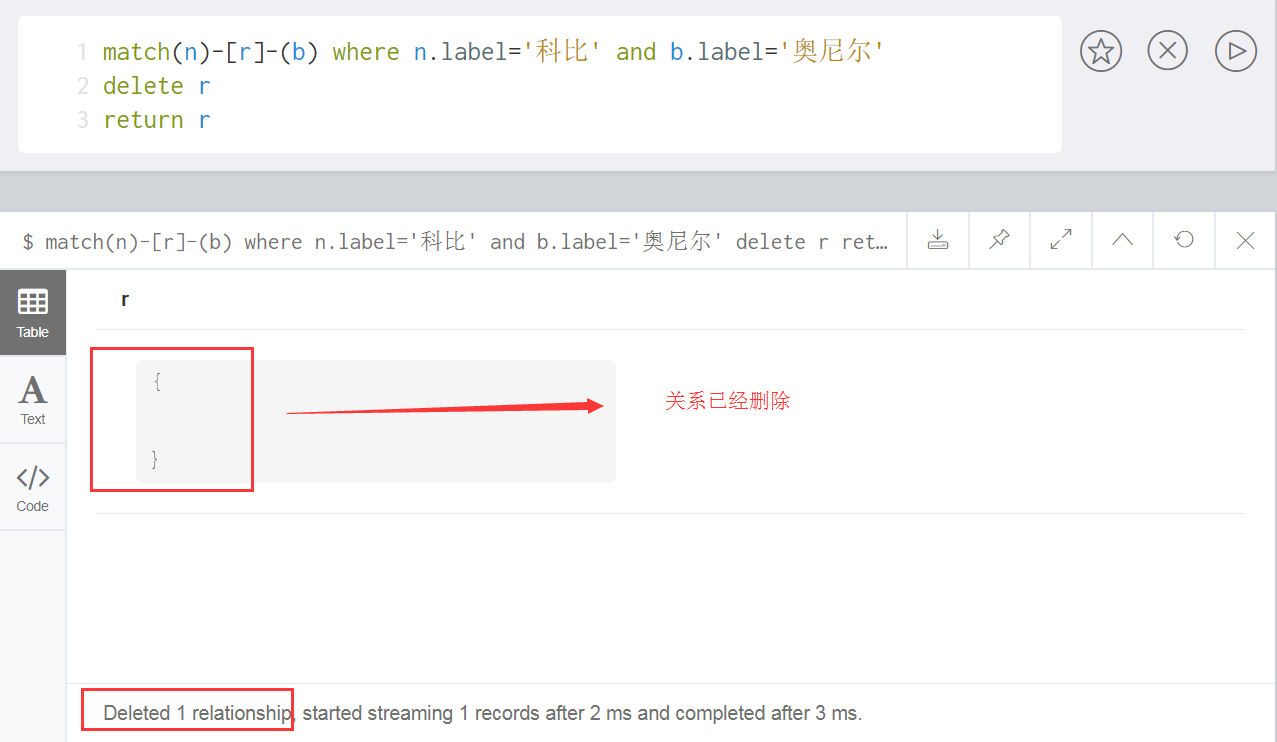
删除统一用命令delete,和删除节点一样,删除关系的语句如下:
match(n)-[r]-(b) where n.label='科比' and b.label='奥尼尔'
delete r
return r执行后,返回关系效果如下【此时关系已经删除】
如果此时,在查询科比和奥尼尔之间的节点关系会怎么样呢,我们来验证一把:

7.8 创建索引
语法:
CREATE INDEX ON :<label_name> (<property_name>)为节点标签洛杉矶湖人基于属性label创建索引,语句如下
create index on:洛杉矶湖人(label)索引都是喜忧参半,这里不再做过多的说明
7.9 删除索引
语法:
DROP INDEX ON :<label_name> (<property_name>)删除上一步创建的索引,语句如下:

7.10 说明
其实neo4j的cypher语句博主在初次写的时候那是相当的别扭啊,总是感觉查询和创建这块特别绕,语句怎么能那么写?后来慢慢在项目中用到了它,便有了时间好好斟酌其语法,几番折腾后,便对其语法越来越上手,后来感觉,查询是那么的简单,因为,不管你查什么,查的无外乎节点、关系、节点间的关系,用表达式表示就是:(n)-[r]-(b)
结合表达式: match(n)-[r] -(b)
如果查询节点n 就 return n
如果查询关系r 就 return r
如果查询节点b 就 return b
如果查询节点n和b之间的关系r 就 return n,r,b
如果查询带条件 就 where n.x = x,r.xx = xx,b.xxx = xxx
如果修改属性 就 where..... set ....
如果删除属性 就 where..... remove .....
如果删除节点或关系 就 where..... delete n 或者 delete r 或者 delete b 或者 delete n , r , b
8. 终极完结篇
github地址:https://github.com/kobeyk/Spring-Boot-Neo4j-Movies
8.1 效果预览
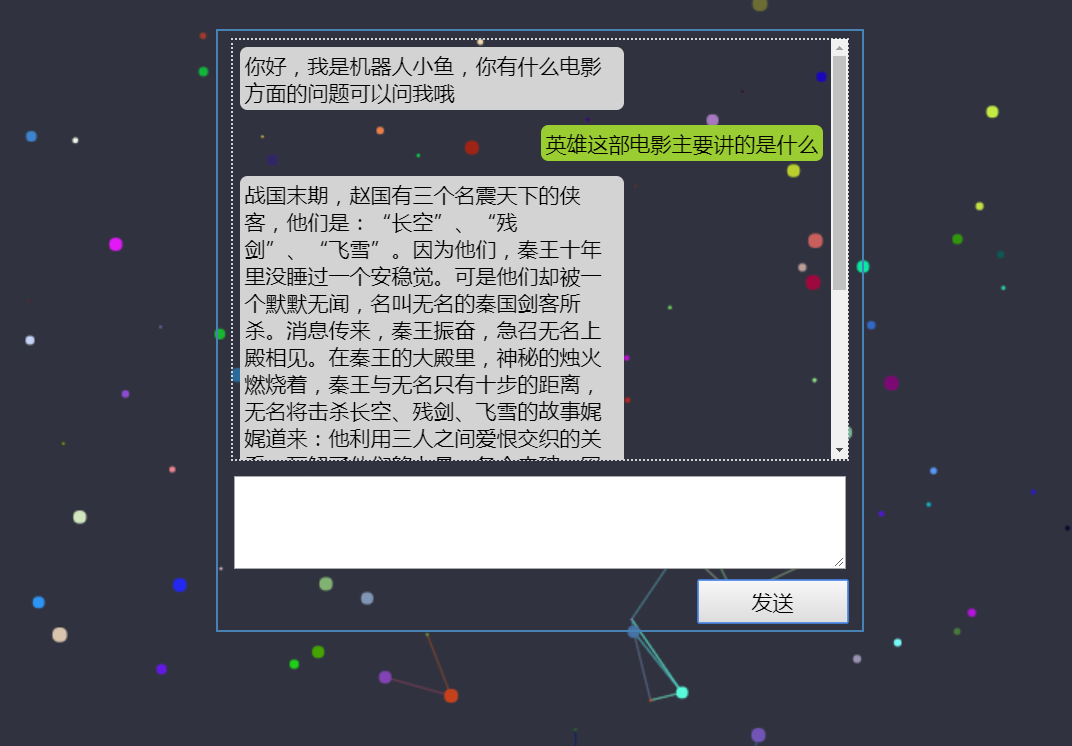
(1)电影简介
前端展示:
后台效果:

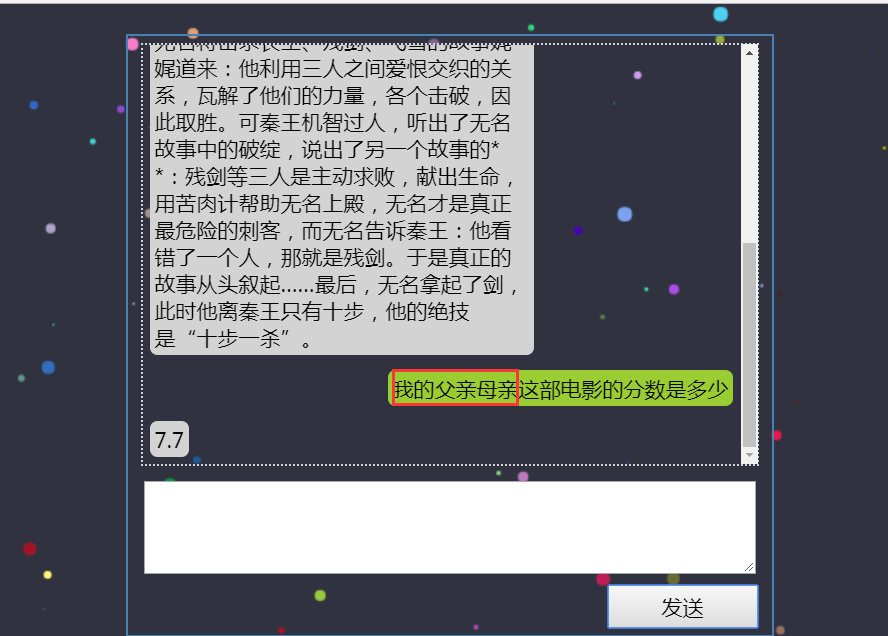
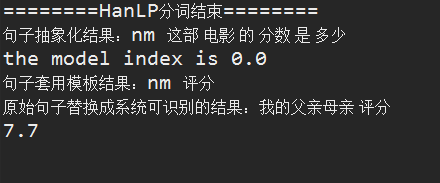
(2)电影评分
前端展示:
后台效果:
(3)电影演员列表
前端展示:
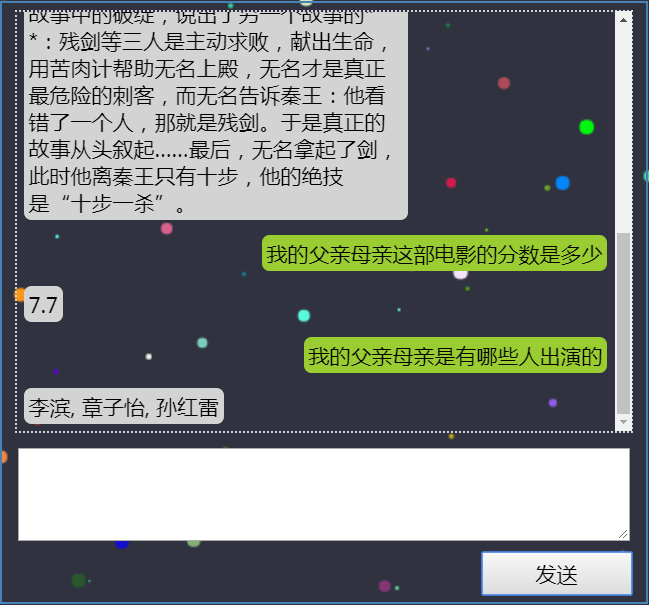
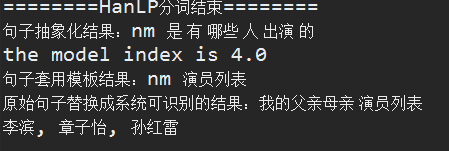
后台效果:
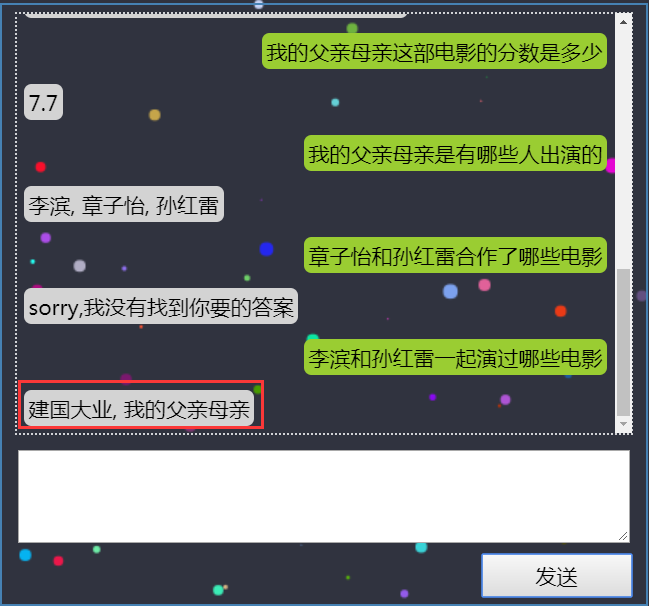
(4)演员A和演员B合作过哪些电影
前端展示:
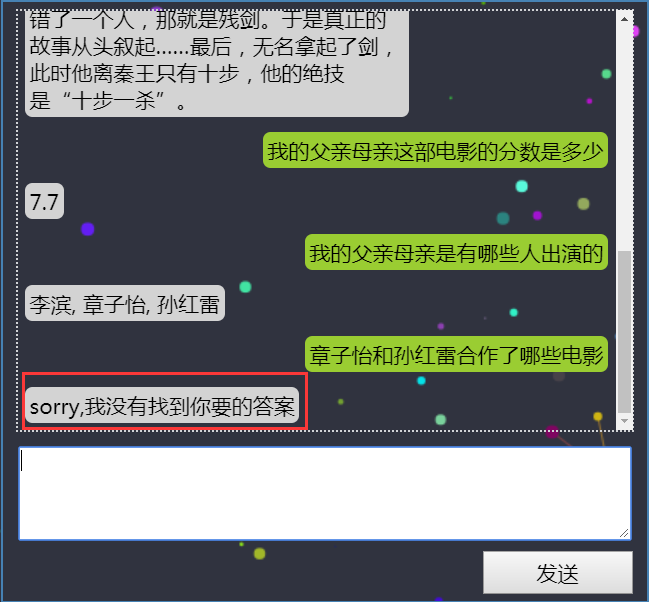
后端效果:
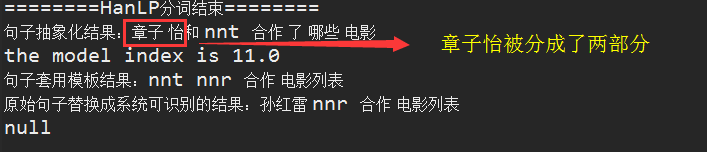
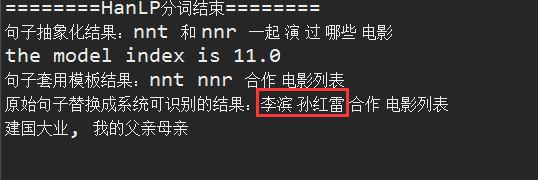
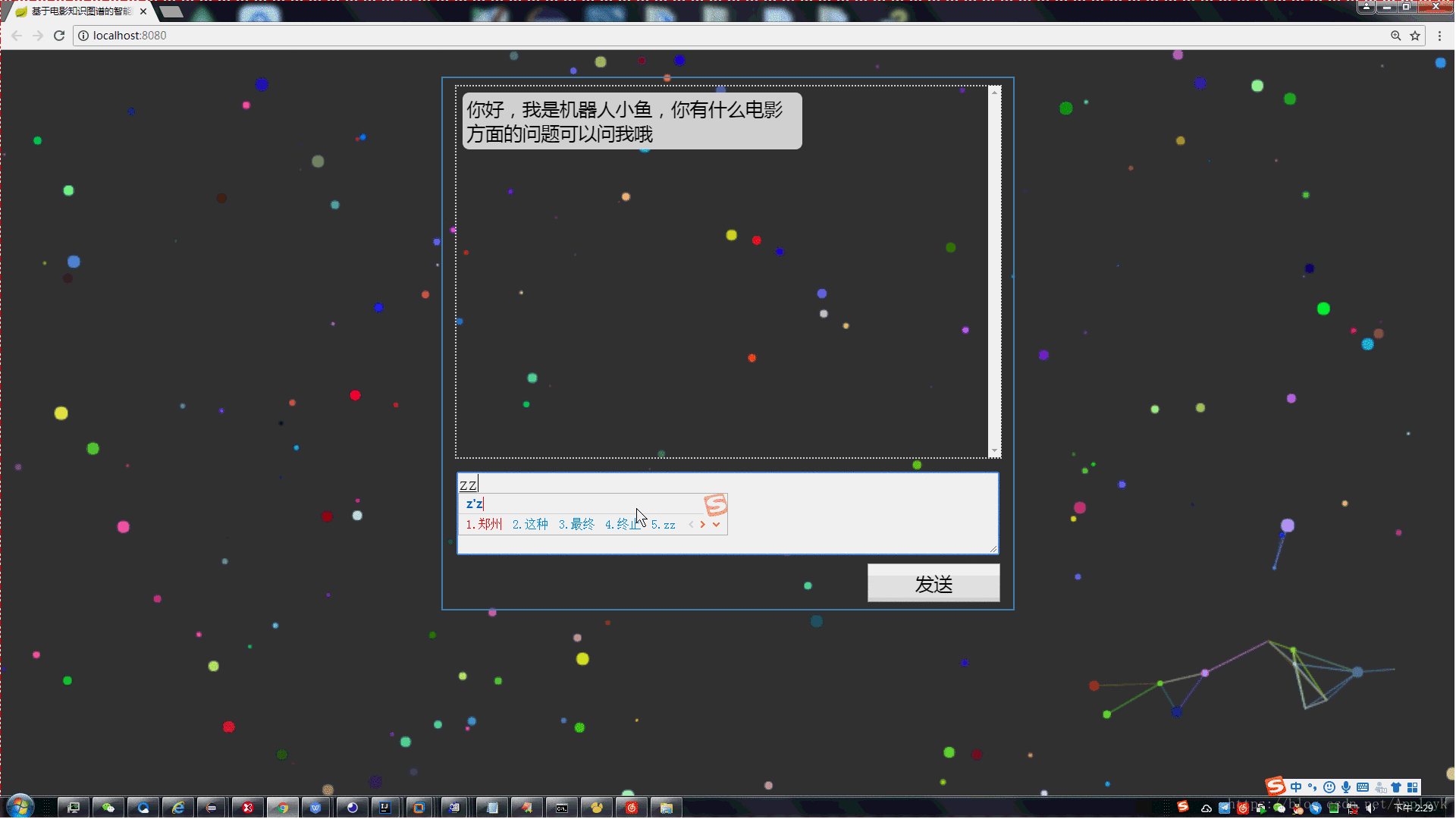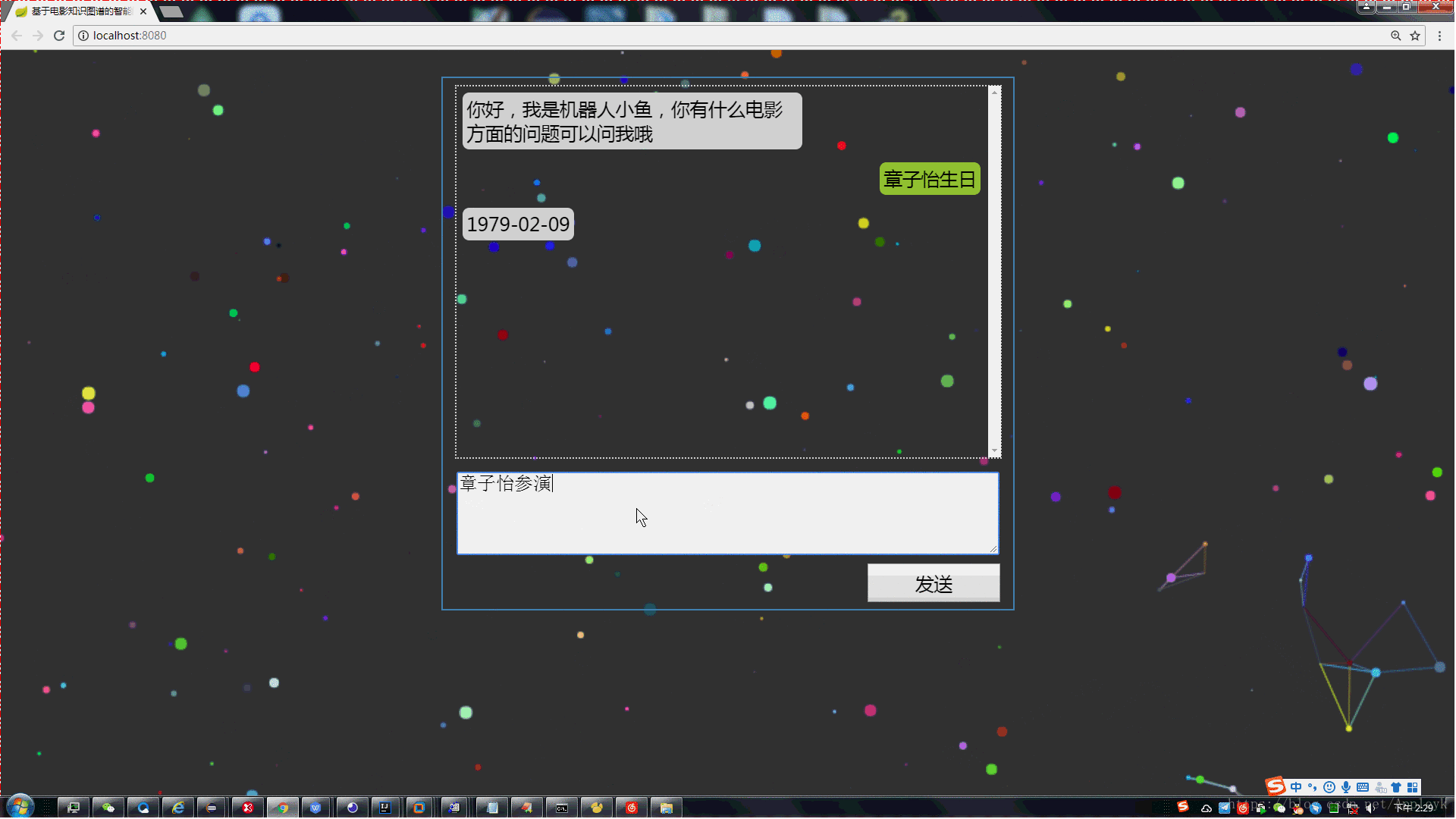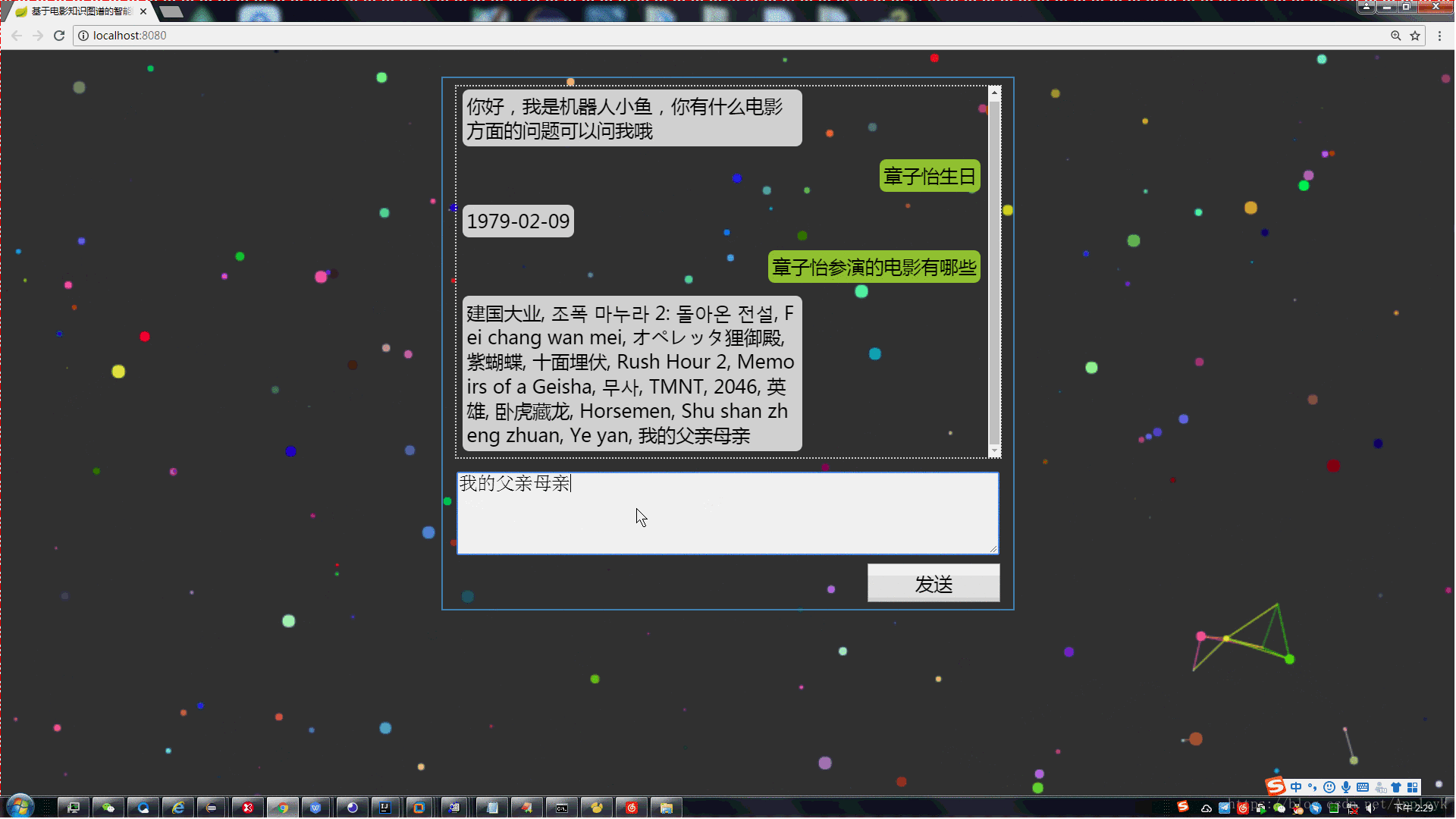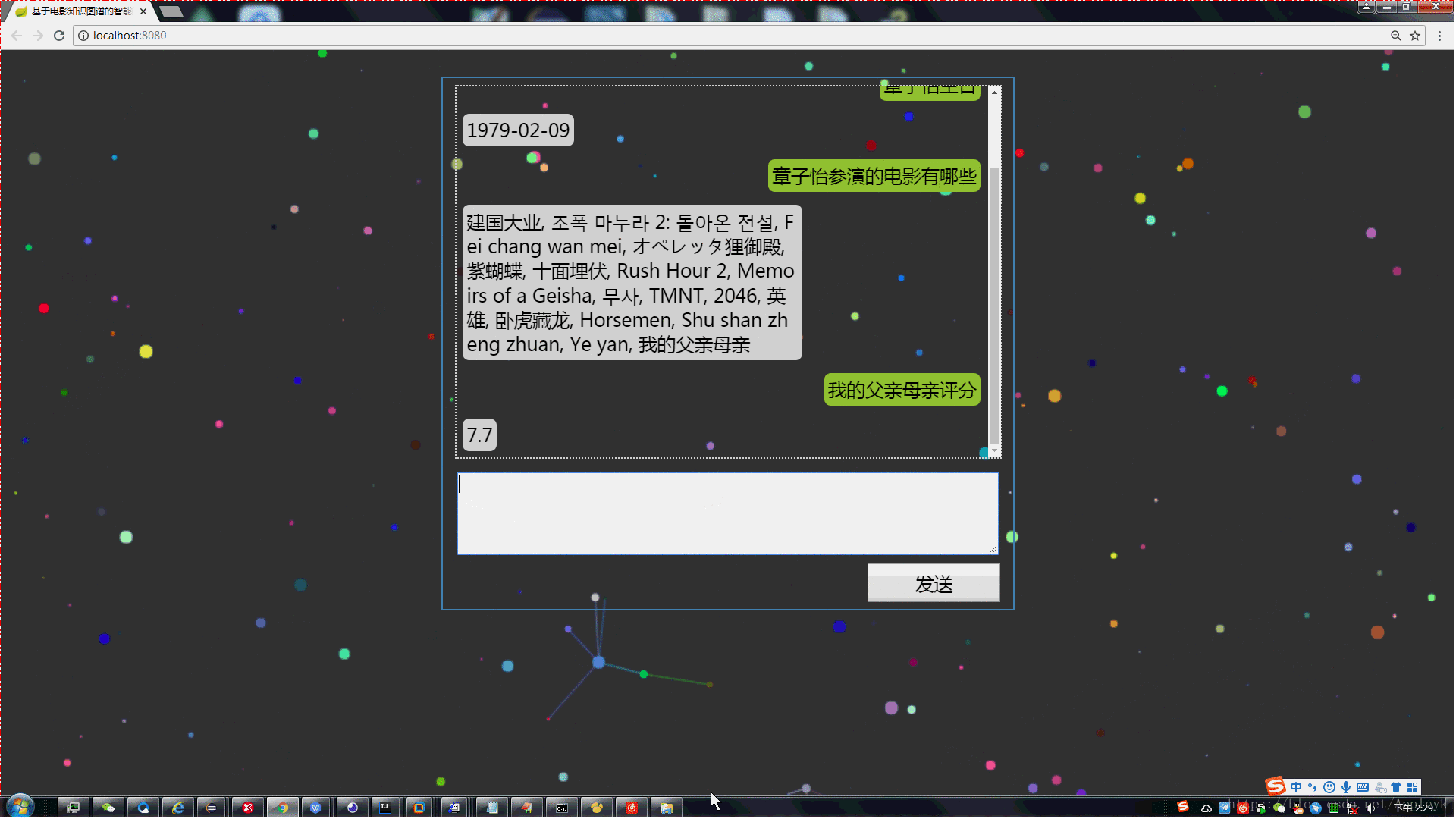
由于章子怡本来是一个完整的人名,但是HanLP分词的时候,却意外的“失手”了,因此导致最后查询无果。
我们再换个问题试验一把
后台效果:
(5)某演员出演过那种类型的电影或演过某种类型的电影有哪些
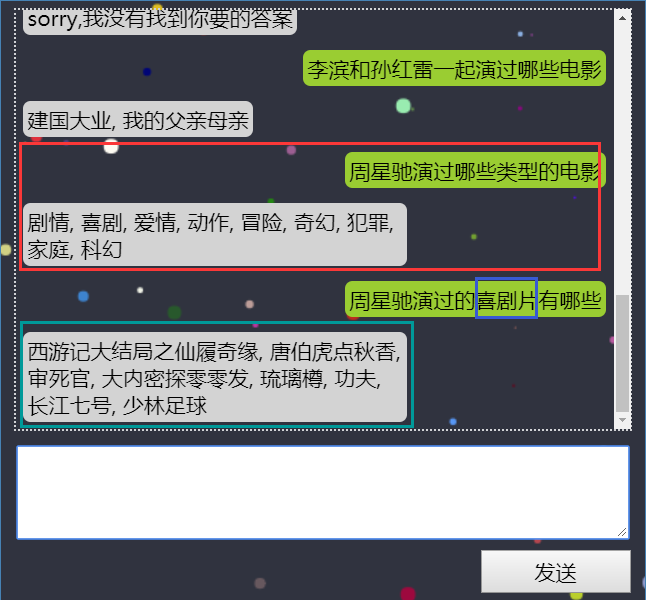
......etc,其余不在做演示,下面直接来看如何利用Spring-Boot搭建我们的智能问答系统
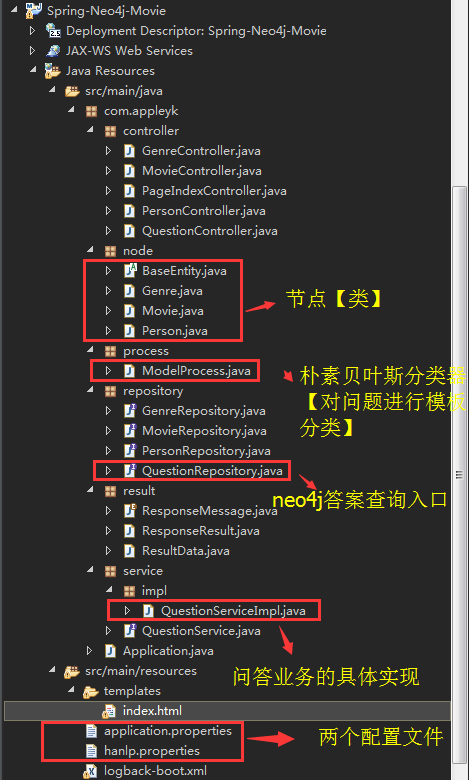
8.2 项目目录结构图
8.3 Movie节点类
这里只拿电影信息的节点类来进行演示,比如,movie对应的节点在Java中定义类如下:
package com.appleyk.node;
import java.util.List;
import org.neo4j.ogm.annotation.NodeEntity;
import org.neo4j.ogm.annotation.Relationship;
import com.fasterxml.jackson.annotation.JsonProperty;
@NodeEntity
public class Movie extends BaseEntity{
private Long mid;
private Double rating;
private String releasedate;
private String title;
private String introduction;
@Relationship(type = "is")
@JsonProperty("电影类型")
private List<Genre> genres;
public Movie() {
}
public Long getMid() {
return mid;
}
public void setMid(Long mid) {
this.mid = mid;
}
public Double getRating() {
return rating;
}
public void setRating(Double rating) {
this.rating = rating;
}
public String getReleasedate() {
return releasedate;
}
public void setReleasedate(String releasedate) {
this.releasedate = releasedate;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getIntroduction() {
return introduction;
}
public void setIntroduction(String introduction) {
this.introduction = introduction;
}
public List<Genre> getGenres() {
return genres;
}
public void setGenres(List<Genre> genres) {
this.genres = genres;
}
}其中属性和neo4j中的movie节点的属性一一对应
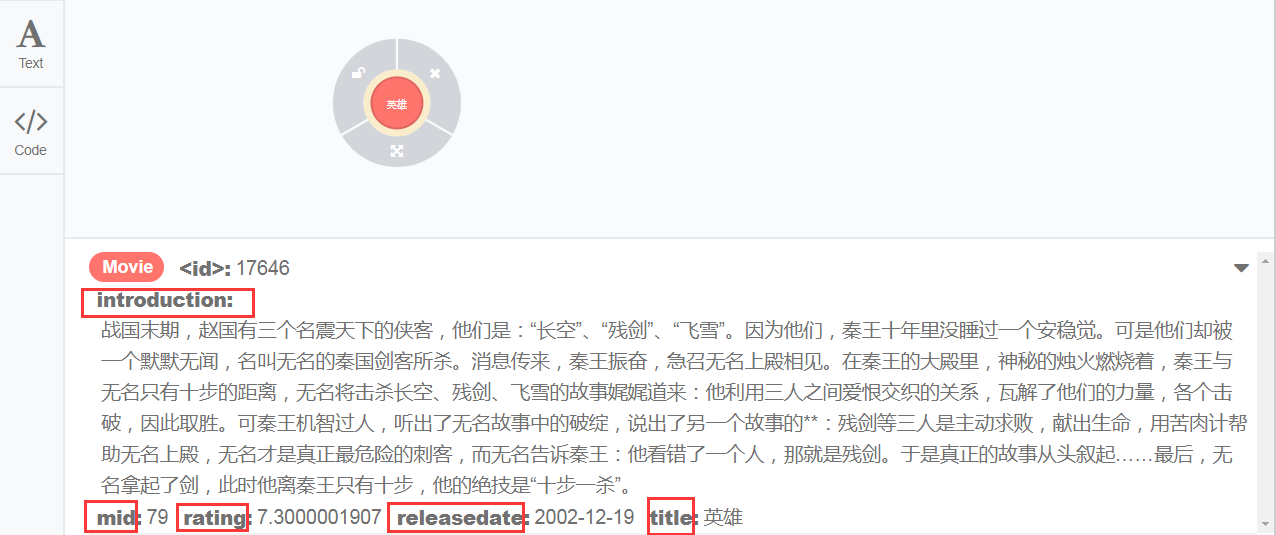
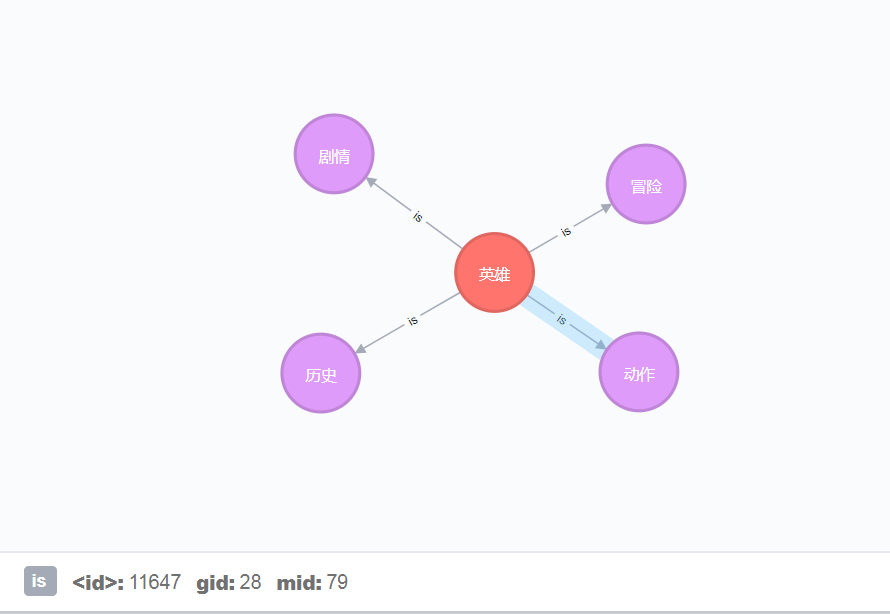
电影信息节点里面带有关系is,对应neo4j中该电影的类型
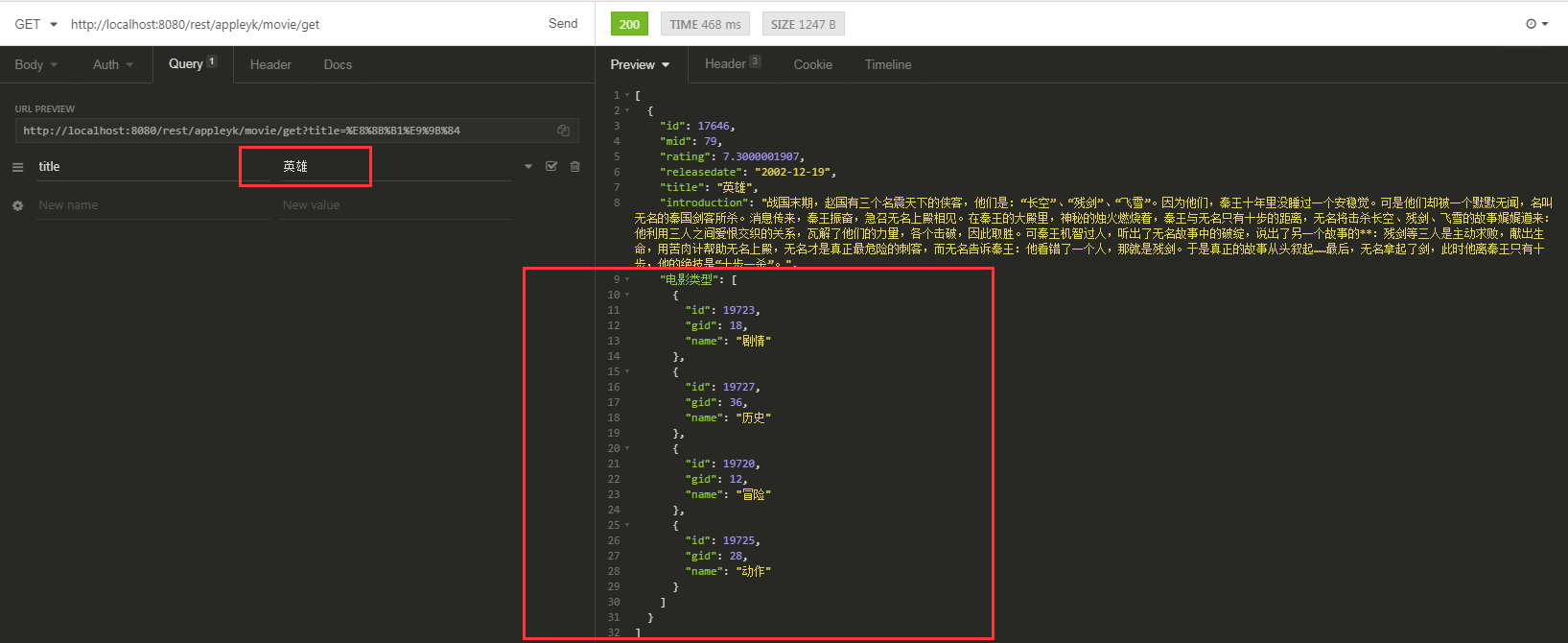
通过Controller对外提供的查询接口如下:

外部调用效果如下:
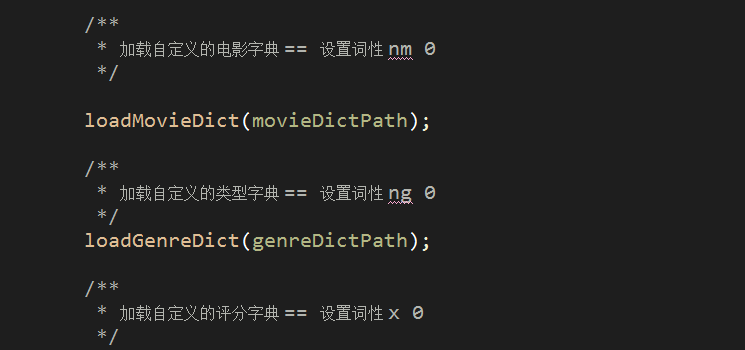
8.4 加载自定义带词性的字典数据
注:不要使用HanLP提供的自定义词典路径,因为这个除了不能随心所欲的定义分词的词性以外,还极容易出现分词紊乱,词性对不上的bug,为了满足我们对专有电影名、电影分数及电影类型词性的定义,我们使用额外加载的方式设置HanLP的自定义分词,application.properties中设置自定义词典的路径如下:
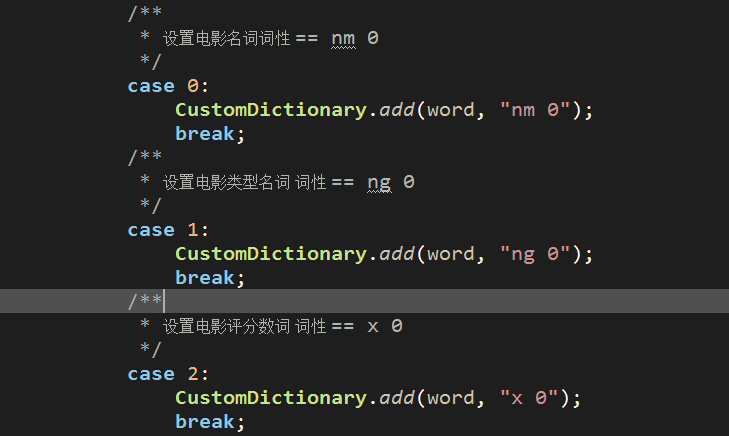
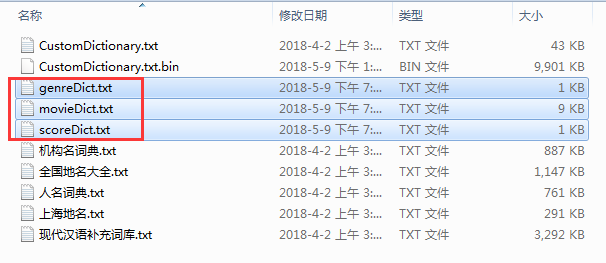
这三个文件的 见文件夹中的 自定义词典.zip
注:也可以根据自己的需求进行设置。
8.5 项目完整地址
github: https://github.com/kobeyk/Spring-Boot-Neo4j-Movies
9. 番外篇:如何将项目导入到IDEA并运行测试效果?
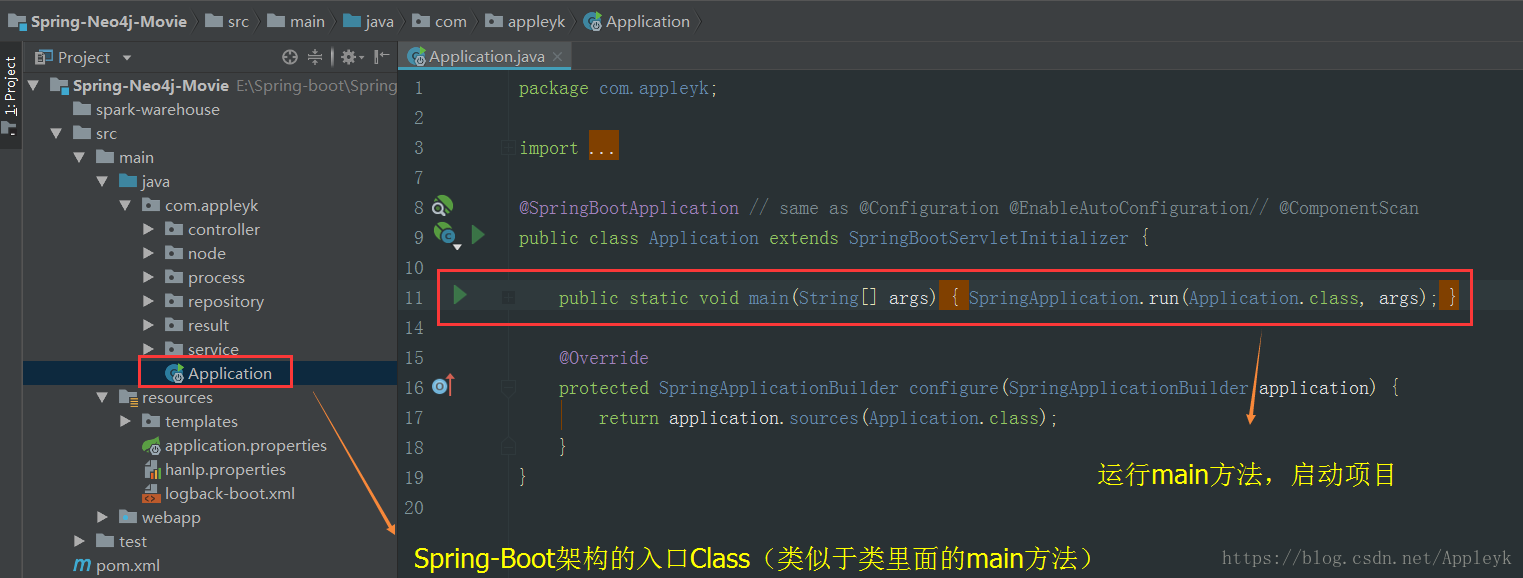
9.1 IDEA项目结构图(导入pom文件,配置好Maven后如下)
9.2 项目配置文件
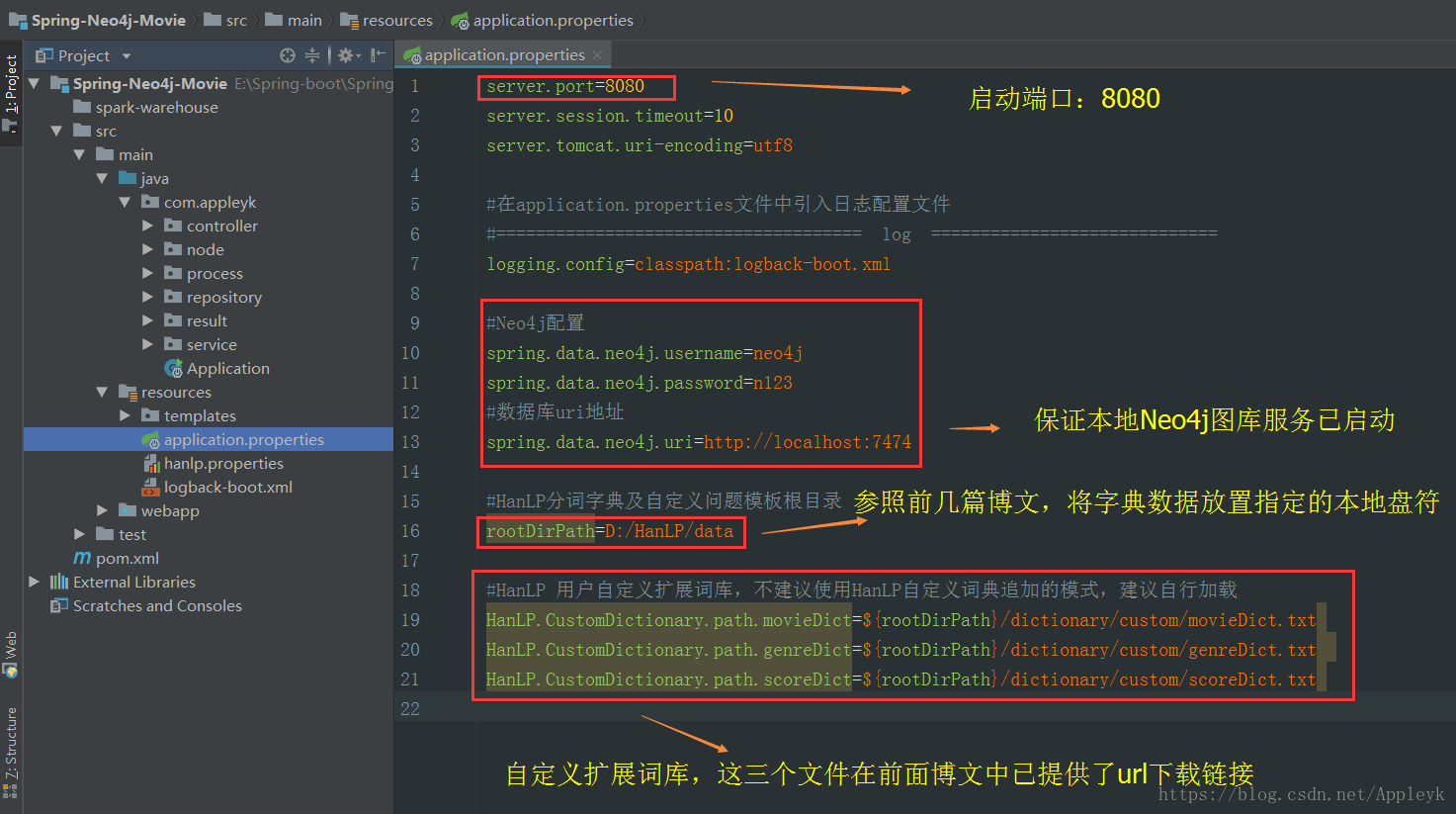
9.3 内嵌html测试前端访问页面
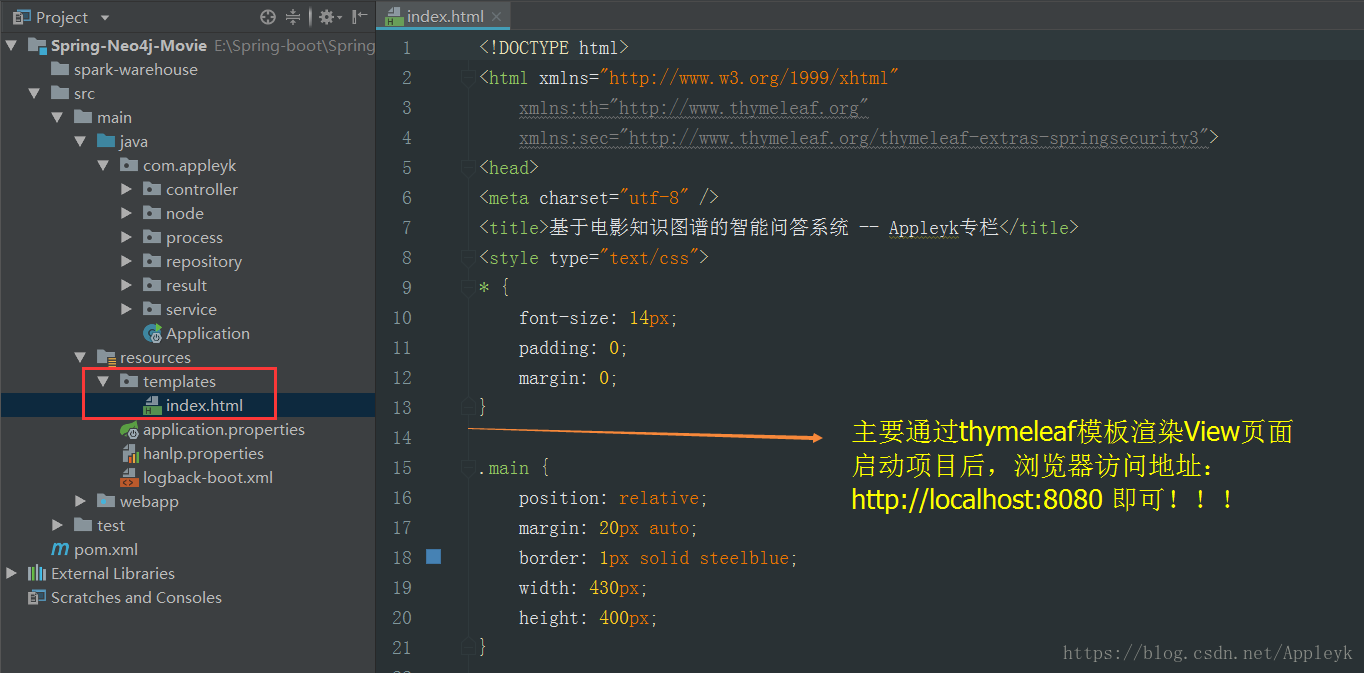
9.4 启动项目
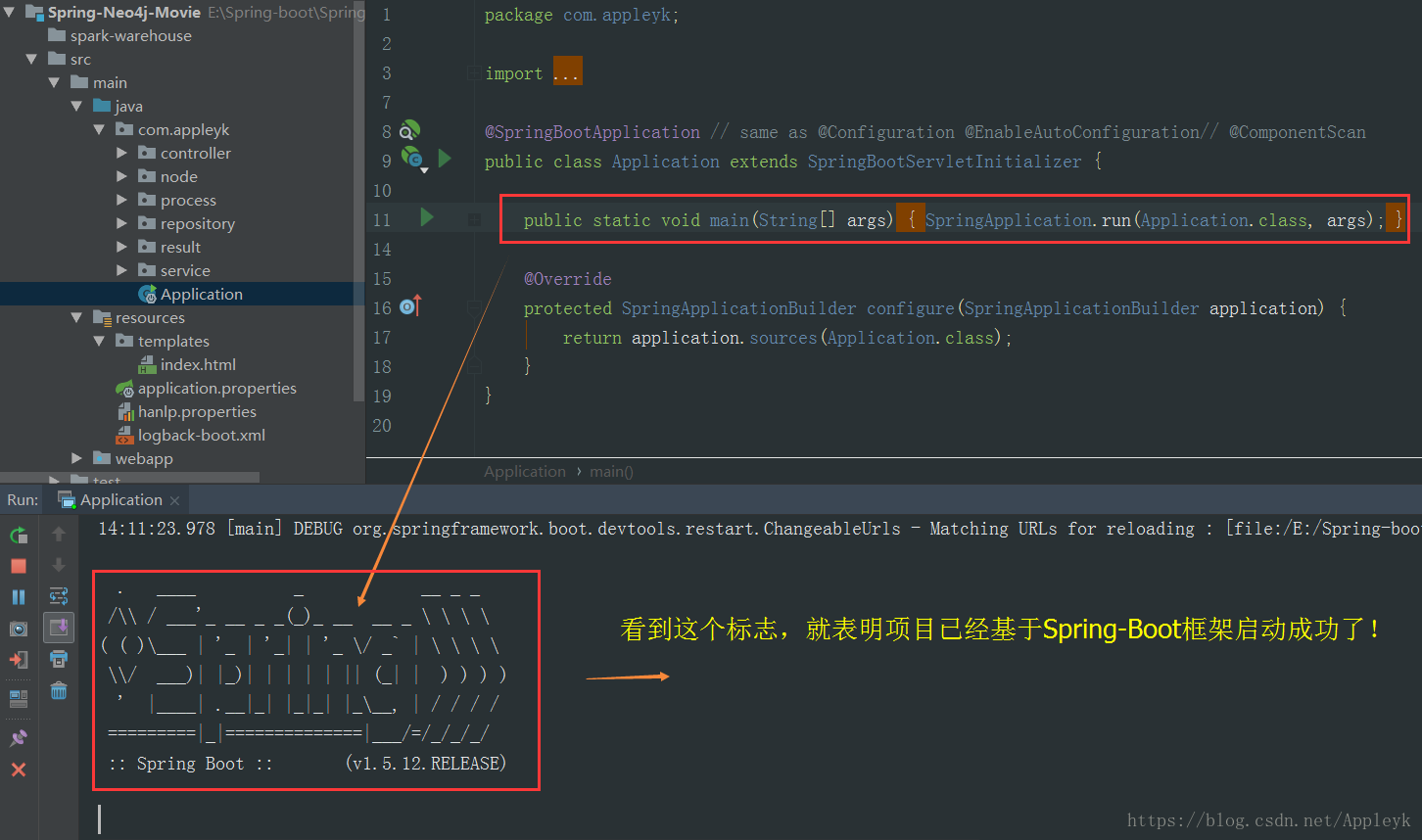
9.5 浏览器访问主页Index.html

- 点赞
- 收藏
- 关注作者
评论(0)