数据导入数据导入工具

常见的Neo4j数据导入方式如下:
1.通过Cypher中的create语句。
2.Cypher中的load csv方式。
3.官方提供的neo4j-import工具。
4.官方提供的Java API BatchInserter。
5.batch-import 工具。
6.neo4j-apocload.csv +apoc.load.relationship。
其各自使用对比如下图(网上):
现就LOAD CSV及neo4j-import工具进行说明。
**
LOAD CSV
**
LOAD CSV可支持读取本地文件及远程文件,语法分别为:
本地:LOAD CSV FROM "file:///data.csv"
远程:LOAD CSV FROM 'https://neo4j.com/docs/cypher-manual/3.5/csv/artists.csv'
使用参数:
1.using periodic commit n : 每n条自动提交一次
2.with headers :文件第一行作为参数名,加上该参数才能使用line.name这种方式
3.with line :为每行数据重命名
Neo4j数据导入中最关键的是csv文件数据的格式,要求如下,
即字符编码为UTF-8,行分隔符为\n,默认列分隔符为逗号,但可加FIELDTERMINATOR参数指定分隔符,当dbms.import.csv.legacy_quote_escaping参数为true时,默认转义字符为\。
示例
节点
csv文件为:
导入:
load csv from 'file:///node.csv' As line create (a:qianfu{name:line[1],post:line[2]});
得到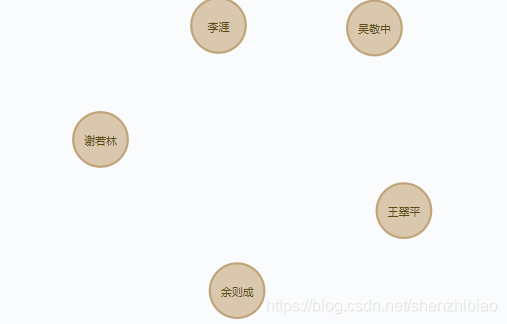
这里若将csv文件改为:
则语句可为
load csv with headers from 'file:///node.csv' As line create (a:qianfu{name:line.name,post:line.post});
为避免重复插入,可将create关键字换为merge。
还有个值得注意的点是csv文件目录的问题,笔者第一次导入时就碰到了这个坑,报Couldn’t load the external resource at: file…错误,仔细一看报错信息,是路径的问题。
原来load csv的时候会去/usr/local/neo4j-community-3.5.11/import目录下找相应文件,所以写相对路径就ok。
若想使用绝对路径或修改默认路径,可在neo4j.conf配置文件中,找到 dbms.directories.import=import,将该行注释掉或者改成自己习惯的路径。
关系
csv文件为:
导入,
load csv with headers from "file:///relation.csv" As line match (from:qianfu{name:line.name1}),(to:qianfu{name:line.name2})
merge (from) -[r:rel{pro:line.rela}]-> (to);
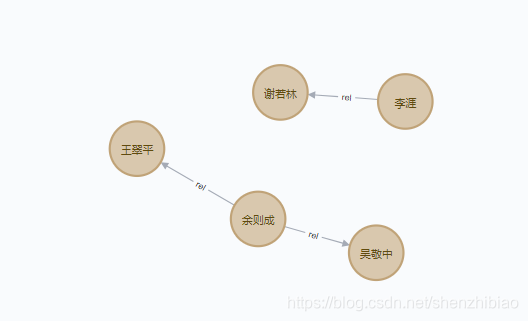
**
neo4j-import
**
neo4j-import同neo4j-admin import (官方推荐),使用前提是关闭neo4j服务,原有库不存在。
语法:
neo4j-admin import [--mode=csv] [--database=<name>]
[--report-file=<filename>]
[--nodes[:Label1:Label2]=<"file1,file2,...">]
[--relationships[:RELATIONSHIP_TYPE]=<"file1,file2,...">]
[--id-type=<STRING|INTEGER|ACTUAL>]
[--input-encoding=<character-set>]
[--ignore-extra-columns[=<true|false>]]
[--ignore-duplicate-nodes[=<true|false>]]
[--ignore-missing-nodes[=<true|false>]]
[--multiline-fields[=<true|false>]]
[--delimiter=<delimiter-character>]
[--array-delimiter=<array-delimiter-character>]
[--quote=<quotation-character>]
[--max-memory=<max-memory-that-importer-can-use>]
[--f=<File containing all arguments to this import>]
[--high-io=<true/false>]
主要选项说明:
mode:默认为csv。
database:默认为graph.db。
report-file:为文件导入记录(导入时会生成import.report文件,记录未导入成功的条目)。
nodes:待导入的节点csv文件,可直接使用nodes:Label的方式显示指定标签。
relationships:待导入的关系csv文件,relationships:RELATIONSHIP_TYPE指定关系。
id-type:每个节点需有唯一标识,id-type指定唯一标识类型,默认为string。
input-encoding:导入数据的字符集,默认UTF-8。
delimiter:csv文件数据间分隔符,默认逗号。
ignore-extra-columns:导入时忽略未指定的列。默认false。
ignore-duplicate-nodes:导入时节点忽略重复节点。默认false。
ignore-missing-nodes:导入时忽略关系里缺失的节点。默认false。
示例
csv文件分别为:
customers.csv
customerId:ID(Customer),name
23,Delicatessen Inc
42,Delicous Bakery
products.csv
productId:ID(Product),name,price,:LABEL
11,Chocolate,10,Product;Food
orders_header.csv
orderId:ID(Order),date,total,customerId:IGNORE
orders1.csv
1041,2015-05-10,130,23
orders2.csv
1042,2015-05-12,20,42
order_details.csv
:START_ID(Order),amount,price,:END_ID(Product)
1041,13,130,11
1042,2,20,11
customer_orders_header.csv
:END_ID(Order),date:IGNORE,total:IGNORE,:START_ID(Customer)
导入:
关闭neo4j: ./neo4j stop
删除原有graph.db库: rm -rf /usr/local/neo4j-community-3.5.11/data/databases/graph.db
导入:./neo4j-admin import --id-type=STRING --nodes:Customer=customers.csv --nodes=products.csv --nodes="orders_header.csv,orders1.csv,orders2.csv" --relationships:CONTAINS="order_details.csv" --relationships:ORDERED="customer_orders_header.csv,orders1.csv,orders2.csv"
出现下图所示即导入成功。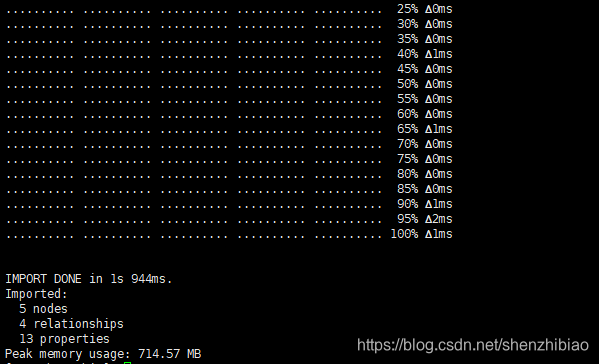
启动neo4j。
导入过程中出现了 Expected ‘–nodes’ to have at least 1 valid item, but had 0 []报错信息,意思是找不到有效的节点,后检查为csv文件路径及文件名称问题,值得注意。
csv文件格式说明:
customers.csv文件头 customerId:ID(Customer),name 指定customerId属性为唯一标识,指定id-group名称为Customer(为避免多个节点有重复的id,所以需指定,若只导入单个实体可不指定),且该文件未指定Label,故在导入语句中显示指定Label --nodes:Customer=customers.csv。
products.csv文件 productId:ID(Product),name,price,:LABEL 最后一列为标签,该文件内容指定Chocolate为Product;Food两标签,分号隔开。
orders_header.csv文件中最后一列加:IGNORE表示导入忽略该列。
关系csv文件order_details.csv中文件头*:START_ID(Order),amount,price,:END_ID(Product)* 中 :START_ID(Order)表示关系起点,为Order组的id,:END_ID表示关系终点,为Product组id。与节点类似,也可在文件中最后一列加:TYPE指定关系类型。
总结
用户可根据所需选择数据导入方式,就上述两种方式而言,LOAD CSV更适合数据量较小,且不能关闭neo4j的情况,通常用于增量更新。neo4j-admin import方式更适用于大量数据情况,且必须关闭neo4j,通常适用于数据初始化。但无论哪种方式,csv文件数据格式处理都是最重要的一环。

- 点赞
- 收藏
- 关注作者
评论(0)