数据导入从CSV文件中导入

csv文件导入neo4j、数据批量导入
neo4j数据的csv导出与备份参见我的另一篇博客: https://blog.csdn.net/weixin_44078713/article/details/107058364
一、数据准备阶段
1.创建文件夹
首先进入neo4j文件夹,看一下是否有import这个文件夹,没有的话就新建一个。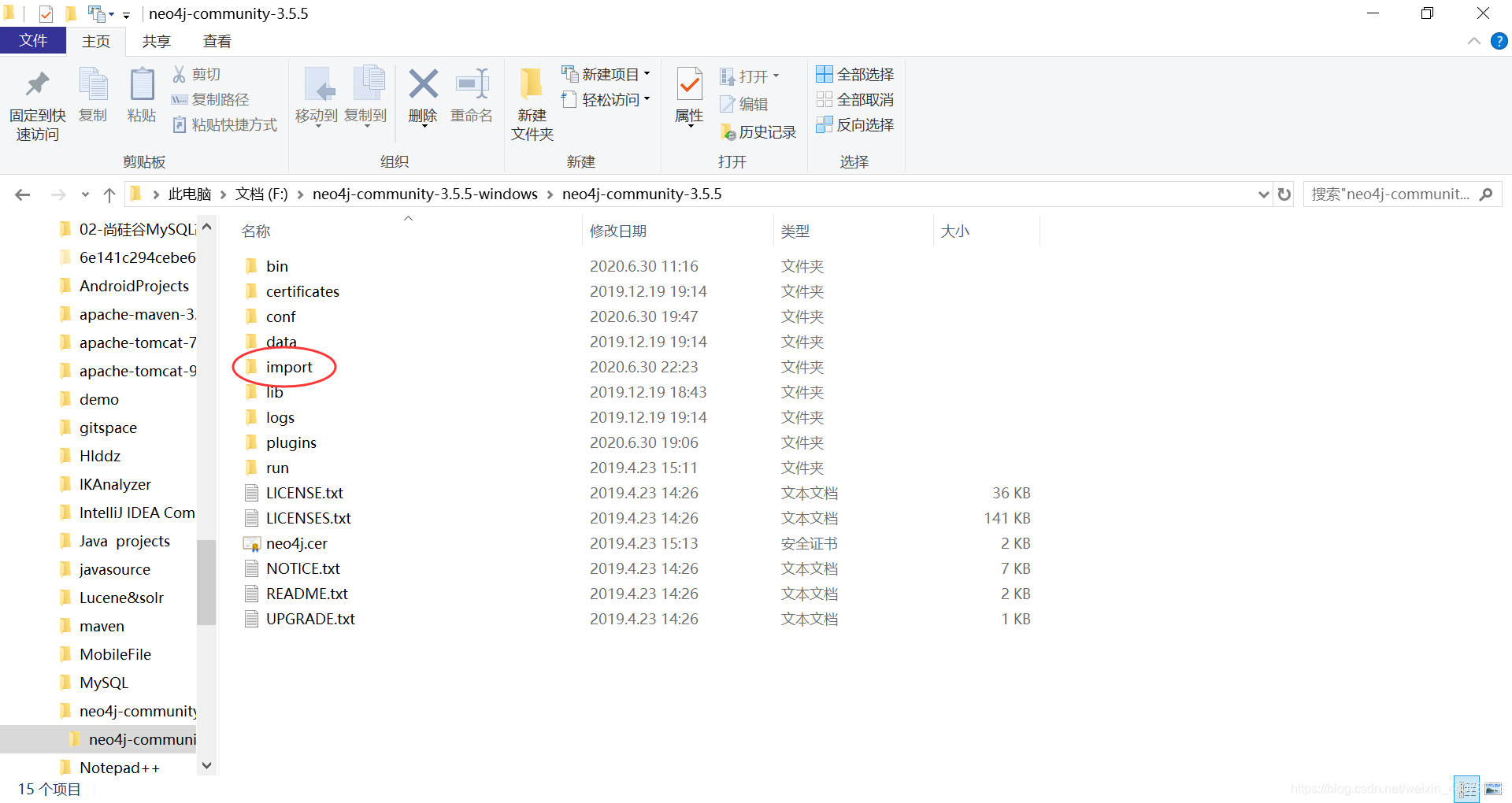
2.导入neo4j数据格式
2.1 结点类型
csv文件需要指定一个唯一标识id,如果需要标签的话用 :LABEL。第一行的其他表头即为节点属性值,第一行使用英文会更好,不然指不定后面会报错。
标签这一列除表头的冒号可以省略,例如下表中:Category可以简化为Category。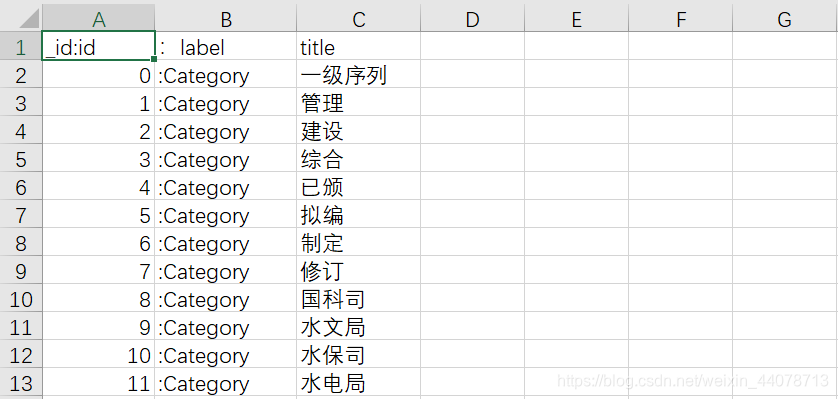
2.2 关系类型
关系类型的csv文件至少需要三列,即起止结点、关系的名称,当然,同2.2中所说,其他列也可以增加关系的属性值。
tip:起止id需要在其他csv文件中定义过且为 :id类型,如下图中我的ENDID为1,代表指向上表中的管理这个节点的一条名为一级序列的关系。(这里应该可以理解吧,要想好自己要建立的一些关系和结点的逻辑关系再下手)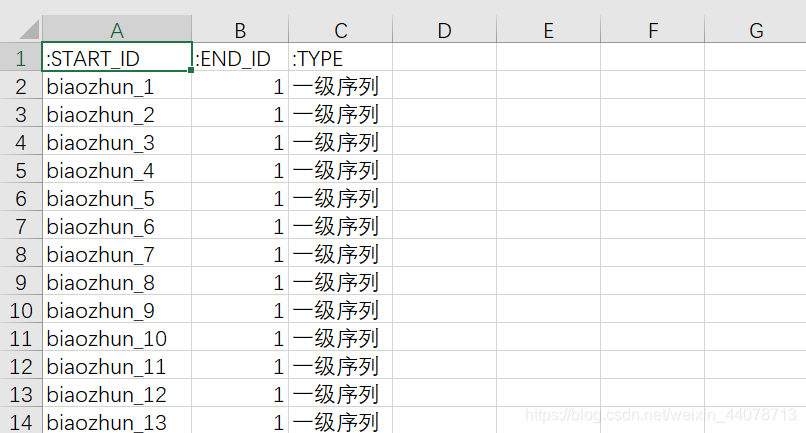
2.3.csv文件转换
如果使用excel创建的表格,如下图另存为csv格式即可。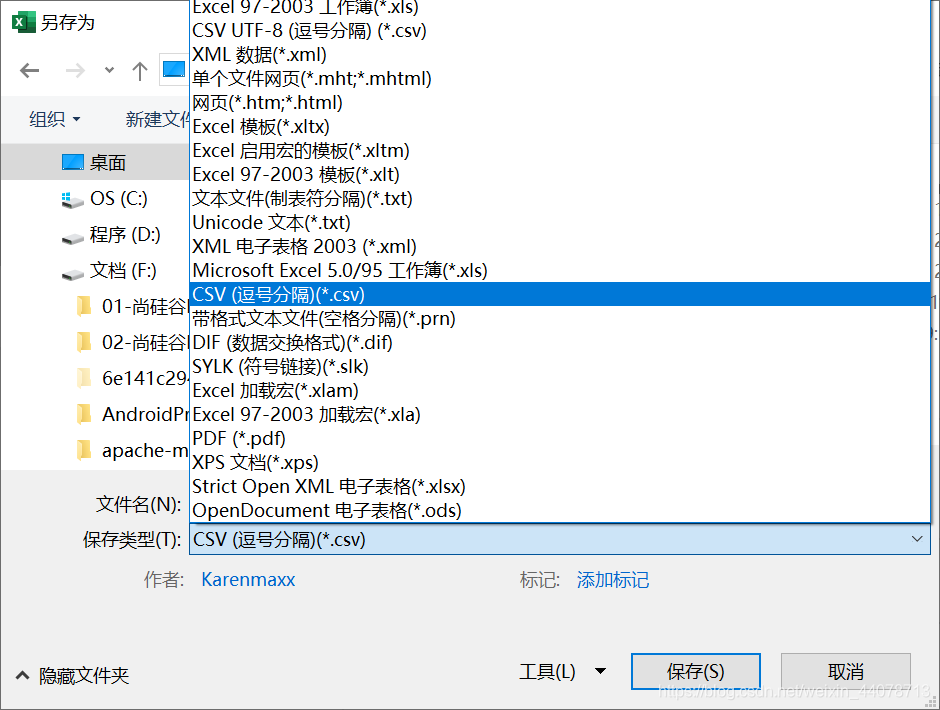
二、数据导入阶段
Import文件夹
将自己所有的结点和关系类型csv文件放入刚刚创建的import文件夹。
导入的代码语句
导入时需要保证neo4j是停止运行状态,wn+r进入命令行,cd进入neo4j的bin目录即可输入。--mode=csv指定导入格式,--database company_outbound.db是这些数据导入的数据库名称,graph.db已经生成,Neo4j导入数据只能在一个数据库中,所以新建了一个数据库,后面改为graph.db即可导入图谱,--nodes:Category 告诉我们这个文件是节点文件且指定了标签,如果多个结点文件可以再来一次--nodes,关系类型也是一样。后面的一些语句是容错处理。
neo4j-admin import --mode=csv --database company_outbound.db --nodes:Category “F:\neo4j-community-3.5.5-windows\neo4j-community-3.5.5\import\profession.csv” --relationships “F:\neo4j-community-3.5.5-windows\neo4j-community-3.5.5\import\shuyu_to_biaozhun.csv” --ignore-extra-columns=true --ignore-missing-nodes=true --ignore-duplicate-nodes=true
大功告成
看到这样的界面就是成功啦!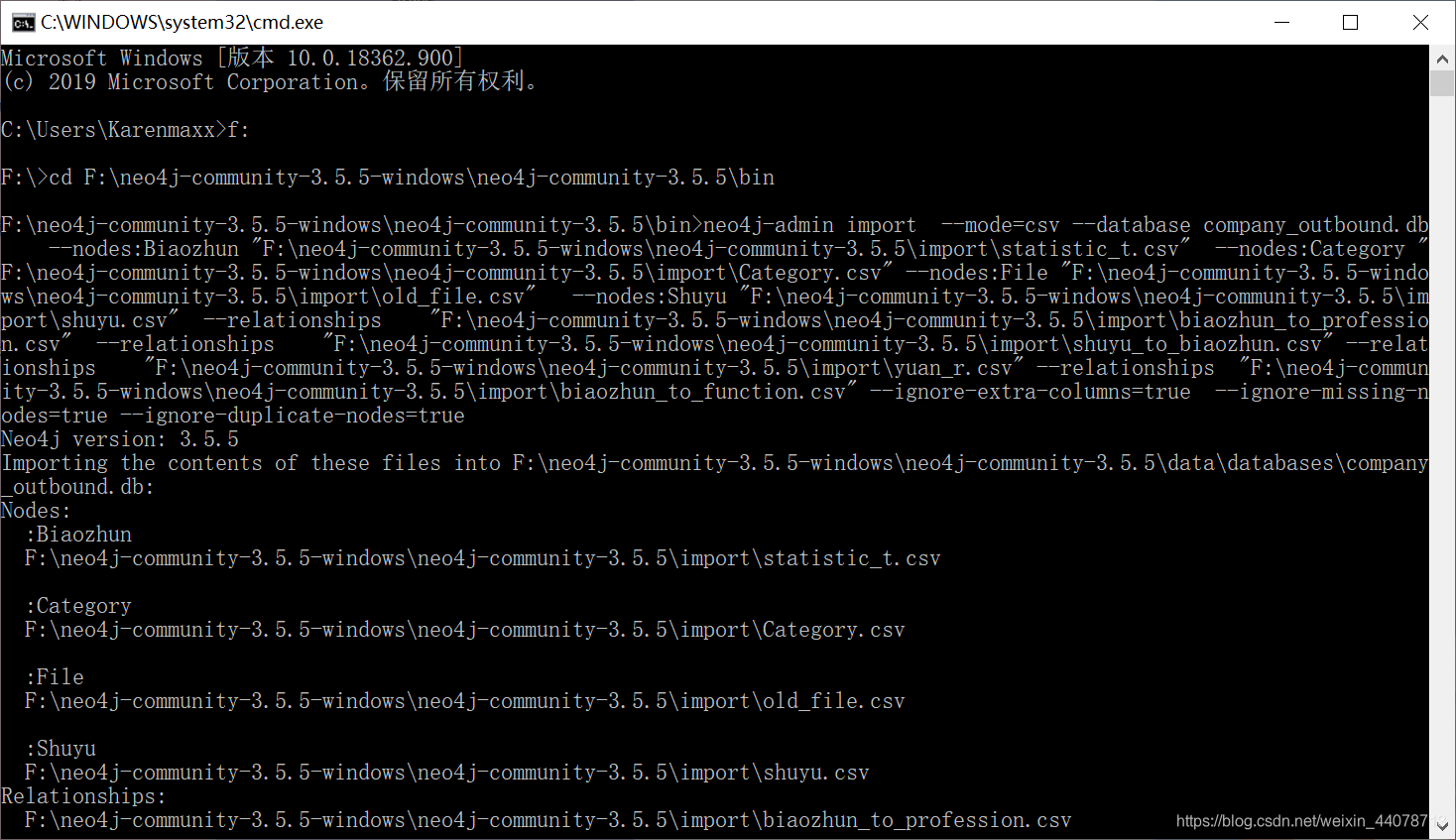
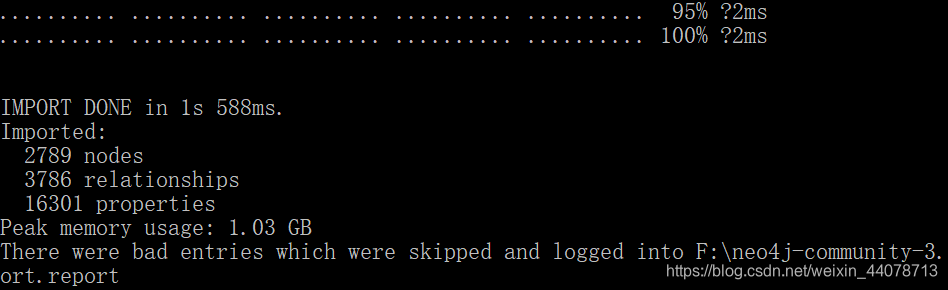
导入之后查看自己的以下路径是否生成company_outbound.db文件,删除原来的graph.db文件夹并把现在生成的这个更名为graph.db。
完成之后运行neo4j就可以看到自己的图谱啦。
三、一些问题
导入neo4j后乱码问题
有同学导入neo4j后发现一些英文名称是可以显示的,但是中文的就是一堆乱码,什么原因呢?是因为我们excel另存为之后默认是ANSI格式,需要手动调成utf8编码,如果电脑上没有安装notepad++的同学可以直接使用记事本来转换。
首先用记事本打开,右下角可以看到编码方式,文件-另存为-修改编码方式utf8即可。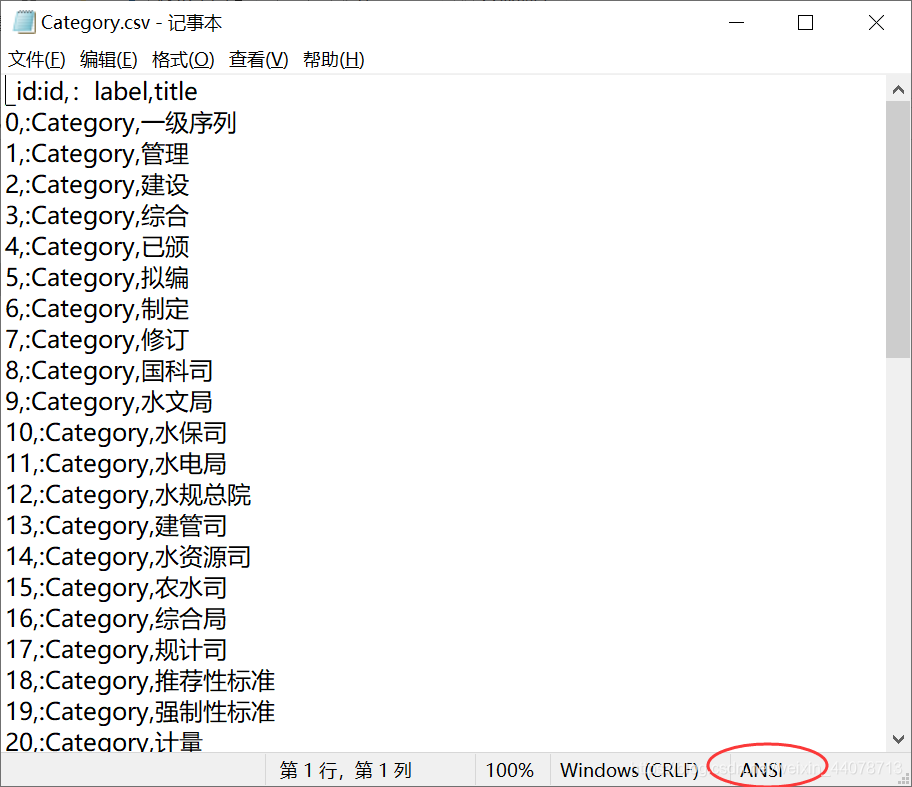
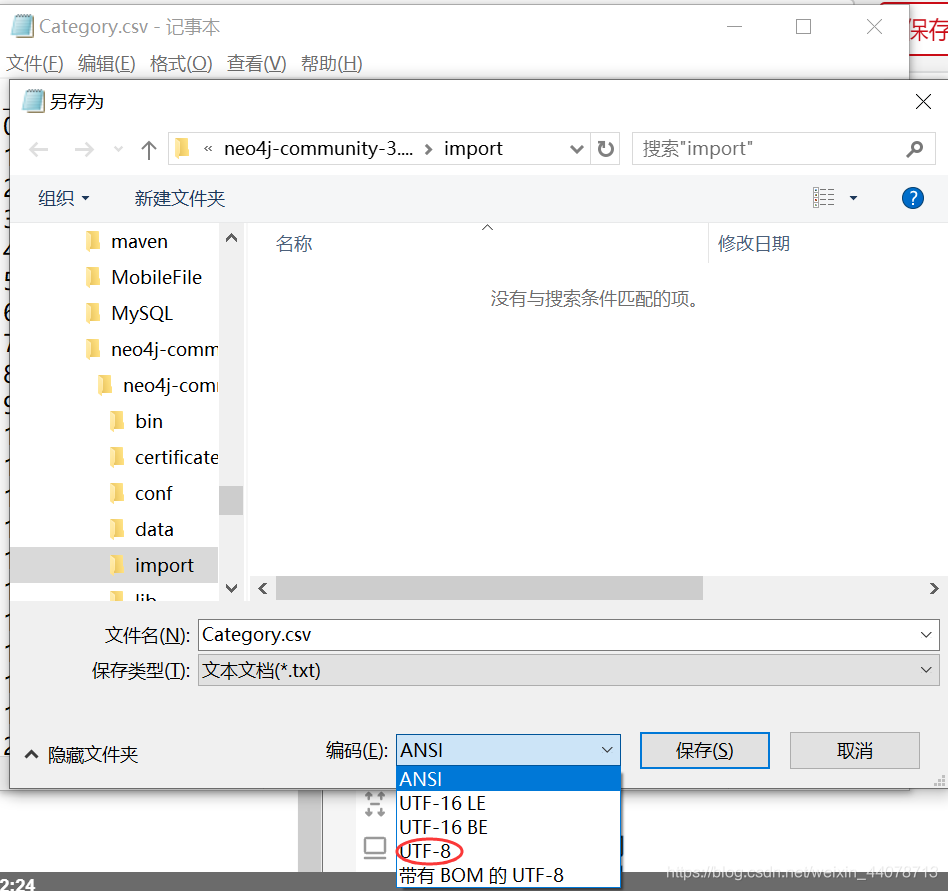
tip:我的电脑上csv转换为uft8格式后直接用excel打开就是乱码的,如果后面需要改动的话可以再转化成ANSI用excel修改。
Unable to parse header
有时导入后台报错Unable to parse header,这是因为无法解析表头引起的,推荐一下排查思路:
①保证每个文件中的id是唯一的一个id,互不重复。
②关系文件中各个表头的名字应该与对应节点名称完全一样,不要多空格多符号等,后来我是直接复制过去解决的。
③lable和type的形式应该对应相等,不要一个文件是是中文的冒号一个文件是英文的冒号。:LABEL 和:LABEL是不一样的,要统一。我的文件中除了LABLE是统一用中文冒号,其他像ID,TYPE都是用的英文冒号。
好啦,今这篇文章就写到这儿,一些坑和经验都记录下来了,防止自己和别的同学踩坑,希望大家的探索之路更加顺利~

- 点赞
- 收藏
- 关注作者
评论(0)