图数据建模图数据模型设计

【摘要】 基于NEO4J图模型的列表推荐一、潜在可能认识的人排序列表二、对可能认识的人进一步筛选三、业务查询和存储过程的编写一、潜在可能认识的人排序列表六度关系以内人脉网络-(只返回账号类型节点)(用户页面触发式接口)(排序:根据关系层数排序)1、首先加载与当前节点相连接的6层以内所有节点。2、寻找当前节点与上一步加载节点的所有最短路径,并过滤出满足特定条件的所有节点。3、计算当前节点与所有节点的关系...
基于NEO4J图模型的列表推荐
一、潜在可能认识的人排序列表
六度关系以内人脉网络-(只返回账号类型节点)(用户页面触发式接口)(排序:根据关系层数排序)
1、首先加载与当前节点相连接的6层以内所有节点。
2、寻找当前节点与上一步加载节点的所有最短路径,并过滤出满足特定条件的所有节点。
3、计算当前节点与所有节点的关系长度更新为节点属性,并且返回这些节点(关系长度在展示时需要因此需要在这里做更新)。
4、 loadRecommendEnginePathSize 关系长度属性(返回结果中更新),此属性做为排序使用。
# 1
MATCH (n)-[*..6]-(m) WHERE id(n)=523261 WITH n,m SKIP 10 LIMIT 100
MATCH p = shortestPath((n)-[*..6]-(m)) WITH filter(x IN nodes(p) WHERE zdr.apoc.relatCalculateRestrict(labels(x),labels(x),'LinkedinID||TwitterID||FacebookID')=true AND x <> n) AS nodes,n
UNWIND nodes AS node
MATCH p=shortestPath((n)-[*..6]-(node)) SET node.loadRecommendEnginePathSize=size(relationships(p)) RETURN node
# 2 优化:
MATCH (n)-[*..6]-(m) WHERE id(n)=25 WITH n,m SKIP 10 LIMIT 100
MATCH p = shortestPath((n)-[*..6]-(m)) SET m.loadRecommendEnginePathSize=size(relationships(p)) RETURN filter(x IN nodes(p) WHERE zdr.apoc.relatCalculateRestrict(labels(x),labels(x),'LinkedinID||TwitterID||FacebookID')=true) AS nodes
# 3 使用allShortestPaths之后加载的节点更加分散
MATCH allShortestPaths((n)-[*..6]-(m)) WHERE id(n)=25 WITH n,m SKIP 10 LIMIT 100
MATCH p = shortestPath((n)-[*..6]-(m)) SET m.loadRecommendEnginePathSize=size(relationships(p)) RETURN filter(x IN nodes(p) WHERE zdr.apoc.relatCalculateRestrict(labels(x),labels(x),'LinkedinID||TwitterID||FacebookID')=true) AS nodes
# 4
# 使用非列表形式返回节点:
# 上面的查询全部都是按照集合格式List<Node>返回节点,但是目前已有的数据解析程序并不支持,因此转为Node形式返回
MATCH allShortestPaths((n)-[*..6]-(m)) WHERE id(n)=25 WITH n,m SKIP 10 LIMIT 10
MATCH p = shortestPath((n)-[*..6]-(m)) SET m.loadRecommendEnginePathSize=size(relationships(p)) WITH filter(x IN nodes(p) WHERE zdr.apoc.relatCalculateRestrict(labels(x),labels(x),'LinkedinID||TwitterID||FacebookID')=true) AS nodes UNWIND nodes AS node RETURN node
#上述所有查询存在BUG,部分返回的节点loadRecommendEnginePathSize属性是空的,而我们需要返回的数据都带有#loadRecommendEnginePathSize属性,做展示时使用;另外在做人物的推荐时,用户更多的是关心可能存在亲密关系的的人,因此进一步优化此人物推荐查询:
MATCH (n)-[*..6]-(m) WHERE id(n)=16236 AND zdr.apoc.relatCalculateRestrict(labels(m),labels(m),'LinkedinID||TwitterID||FacebookID')=true WITH n,m SKIP 10 LIMIT 10
MATCH p = shortestPath((n)-[*..6]-(m)) SET m.loadRecommendEnginePathSize=size(relationships(p))
WITH filter(x IN nodes(p) WHERE zdr.apoc.relatCalculateRestrict(labels(x),labels(x),'LinkedinID||TwitterID||FacebookID')=true AND x.loadRecommendEnginePathSize IS NOT NULL) AS nodes
UNWIND nodes AS node RETURN node
MATCH allShortestPaths((n)-[*..6]-(m)) WHERE id(n)=16236 AND zdr.apoc.relatCalculateRestrict(labels(m),labels(m),'LinkedinID||TwitterID||FacebookID')=true WITH n,m SKIP 10 LIMIT 10
MATCH p = shortestPath((n)-[*..6]-(m)) SET m.loadRecommendEnginePathSize=size(relationships(p))
WITH filter(x IN nodes(p) WHERE zdr.apoc.relatCalculateRestrict(labels(x),labels(x),'LinkedinID||TwitterID||FacebookID')=true AND x.loadRecommendEnginePathSize IS NOT NULL) AS nodes
UNWIND nodes AS node RETURN node
下面再对比一下在此推荐查询中使用 allShortestPaths与不使用 allShortestPaths区别,返回1000个节点:
(1)、返回节点的区别:使用allShortestPaths之后第一步加载到的节点更加分散
(2)、查询效率:
使用allShortestPaths: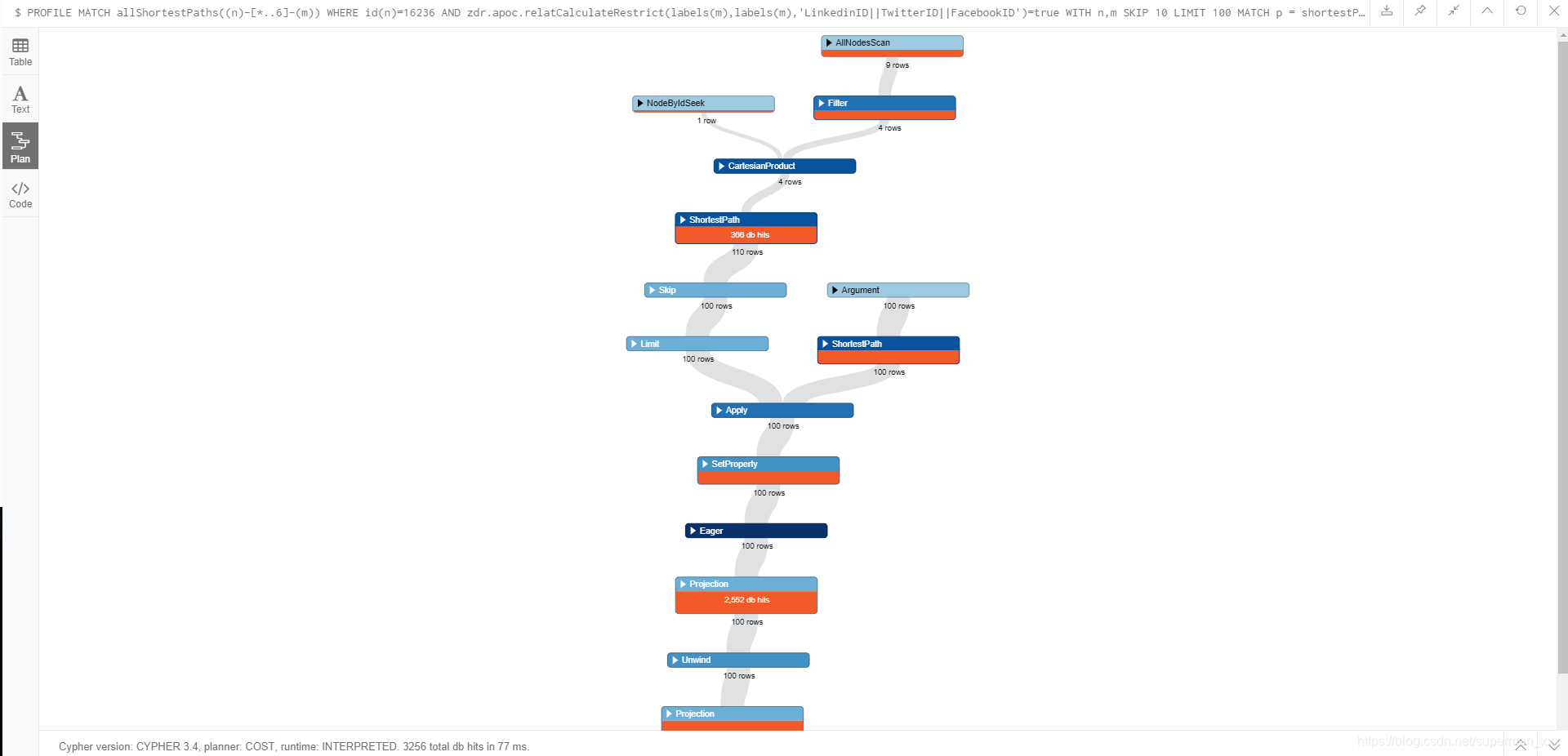
不使用函数allShortestPaths:
结论:在随机返回节点的查询中allShortestPaths比(n)-[*…6]-(m)查询效率差一些。
二、对可能认识的人进一步筛选
六度关系以内人脉-寻找属性包含中文或与中国相关的节点(用户页面触发式接口)(排序:属性中涉及的中文内容做统计)。
loadRecommendEngineChineseSize (返回结果中更新),此属性做为排序使用。
MATCH (n)-[*..6]-(m) WHERE id(n)=16236 AND zdr.apoc.relatCalculateRestrict(labels(m),labels(m),'LinkedinID||TwitterID||FacebookID')=true AND zdr.apoc.isContainChinese(m)>0 WITH n,m SKIP 10 LIMIT 10
MATCH p = shortestPath((n)-[*..6]-(m)) SET m.loadRecommendEnginePathSize=size(relationships(p)),m.loadRecommendEngineChineseSize=zdr.apoc.isContainChinese(m)
WITH filter(x IN nodes(p) WHERE zdr.apoc.relatCalculateRestrict(labels(x),labels(x),'LinkedinID||TwitterID||FacebookID')=true AND x.loadRecommendEnginePathSize IS NOT NULL AND zdr.apoc.isContainChinese(x)>0) AS nodes
UNWIND nodes AS node RETURN node
三、业务查询和存储过程的编写
编写业务查询和存储过程时,尽量在满足业务需求的基础之上一次请求完成,避免多次的查询请求。一个查询完成一个需求,必然会使查询更加的复杂,容易出现BUG,因此对查询进行单独测试是非常必要的。
上述案例中涉及的relatCalculateRestrict自定义函数可进一步简化,isContainChinese等函数源码参考请跳转到GITHUB链接。
NEO4J存储过程参考

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)