Cypher查询语言Cypher查询语言入门

Cypher是对图形的声明查询语言, 使用图形模式匹配作为主要的机制作图形数据选择(包括只读和变更操作) 。 Cypher的声明模式匹配性质意味着可以通过描述想从它那里得到什么查询图形数据。
执行Cypher查询方式
有很多种方式可以执行Cypher查询, 与Neo4j一起发布的几个工具都支持Cypher执行, 并且Cypher也可以从Java代码执行, 与SQL非常相似。
使用Neo4j Shell命令执行Cypher查询:Neo4j Shell命令是一个命令行工具, 它是随Neo4j一起发布的, 可以使用它与以下任何一个连接。
本地Neo4j数据库——通过指定shell到Neo4j数据库存储的目录连接。通过RMI连接远程Neo4j服务器——通过给shell提供主机名字和连接端口连接。
使用网页管理控制台执行Cypher查询
Neo4j服务器自带一个操作工具: 网页管理控制台, 即一个基于浏览器的对Neo4j实例多样的网页接口。 它有许多特性, 可以查询、 处理、 可视化Neo4j图形数据库和管理Lucene索引、 维护和监控Neo4j设置。
用Java代码执行Cypher查询
在Java中使用JDBC驱动程序和JDBC API很容易查询关系数据库。 获得连接, 创建和执行声明, 通过结果集迭代, 立刻就会得到JDBC数据库查询, 在Java中执行Cypher查询显然更为简单。
可以看到, 对Cypher查询, 需要做的是实例化Neo4j的执行引擎(ExecutionEngine)并且给它传递有效的Cypher查询 。ExecutionResult.toString() 方法与Neo4j Shell的输出格式相同, 这对调试程
序和排除问题非常有用。在Java中通过Cypher查询结果迭代, 所需要做的就是对execute(…) 方
法返回的ExecutionResult对象进行迭代:
每一个迭代元素都包含着一个结果行, 代表一个Java映射, 这里的主键是列的名字, 值就是实际的结果值。前面的小段程序逐行迭代了Cypher查询结果。 另一个选项是通过单个的列迭代结果, 当不是对返回的所有列都感兴趣时非常有用, 就像下列的程序演示的那样:
尽管核心Neo4j图形引擎是用Java实现的, 但是Neo4jCypher引擎是用Scala实现的。 Scala是一种流行的、 混合的功能编程语言,运行于Java虚拟机上。 关于更多的Scala知识, 请参阅www.scala-lang.org/。
Cypher的替代者
Cypher并不是唯一的图形查询语言, 另一个常用的图形查询语言是Gremlin, Neo4j也支持Gremlin。 Gremlin实际上是一组定义如何遍历和处理图形的接口, 这些接口是通过每一个与之兼容的图形引擎实现的。 这意味着理论上与Gremlin相同的查询可以在任何与之兼容的图形数据库上使用, 使得代码可移植。 Gremlin是一个开源库, 并且是流行的图形库Tinkerpop栈的一部分(https://github.com/tinkerpop/gremlin) 。Cypher和Gremlin的主要区别是它们的性质——Gremlin是命令式语言,用户需要描述如何遍历图形, Cypher是声明性语言, 它使用模式匹配描述需要哪一部分图形数据。 这就使得Cypher易读且易于理解。 Gremlin可以在不同的图形数据库中移植, 而Cypher是由Neo4j团队开发, 并仅应用于Neo4j图形数据库。Gremlin的句法与使用超出了本书的讨论范围, 但是可以在以下网站查阅更多的资料: https://github.com/tinkerpop/gremlin。现在知道了使用基于网页的、 基于命令行应用的和基于使用Java API的执行Cypher查询, 下面开始使用Cypher查询。
Cypher
执行Cypher查询举例

使用Java API遍历图形查找用户看过的所有电影
遍历有三个阶段:1) 通过节点编号查找一个起始节点 2) 从起始节点跟随HAS_SEEN关系遍历图形 3) 返回HAS_SEEN关系最终的节点
使用Cypher编写同样的查询代码, 同样遵循遍历的三个阶段
与Java代码一样, 首先需要使用节点编号查找起始节点, 这个可以使用Cypher的start和node关键词获得。 注意起始节点的名字(user) , 在以后同样的Cypher查询中可以引用。下一步, 设置需要输出结果的匹配模式。 模式就是对需要检查数据库中的子图形的描述, 它是由关系相互连接的一些节点构成。 一个关系连接的两个节点是典型的图形模式, 它是用() -[]-() 描述的。 节点用圆括号()指定, 关系使用方括号[]指定。 节点和关系使用连字符连接。 在start句子中的节点(前面例子中user) 用作确定模式的左边界。 整个模式有两个已知元素(左边界节点和关系) , 将用作查找所有与右边界(在我们的例子中是movie节点) 匹配的所有节点。最后, 要查找所有匹配的电影, 因此, 使用return关键字返回匹配的电影(再一次使用前面介绍的用名字引用节点) 。 使用分号标志Cypher查询的结束。
从Neo4j 2.0版本起, start语句是可选的。 如果省略start语句, Neo4j将会试图在match查询语句中从节点标签和属性推断start语句。 为了清晰和与早期版本的Neo4j兼容, 本章的所有查询都有显式定义的start语句。 关于更多的推断start语句, 请访问http://docs.neo4j.org/chunked/stable/query-start.html。
Cypher的基本句法
Cypher句法由四个不同的部分组成, 每一部分都有一个特殊的规则:
- start——查找图形中的起始节点
- match——匹配图形模式, 可以定位感兴趣数据的子图形
- where——基于某些标准过滤数据
- return——返回感兴趣的结果
模式匹配
模式匹配是Cypher的重要方面, 它提供了强大的功能以人可读的句法描述子图形结构。 以下的程序演示了以单个命名的关系连接的两个节点的模式匹配:
当描述关系时, 在方括号里面的冒号(: ) 后面指定关系的类型。 当建立关系(句法上大小写敏感) 时, 类型必须与它定义的类型严格一致。 这个简单的查询使用[: HAS_SEEN]句法描述了单个HAS_SEEN关系。
关系方向的描述是在Cypher中用ASCII实现的。 关系的连接是用ASCII箭头(单个连字符接着一个大于号或前面有一个小于号[]->或<-[]) 连接着它的端点。 关系的起点使用单个连字符连接([]-) 。 在前面的例子中, 匹配用户看过的电影(match(user) -[: HAS_SEEN]->(movie) ) 模式指定了从user节点指向movie节点的HAS_SEEN关系。
如果不在意关系的方向, 或者不清楚哪一个是关系的起始节点或终止节点, 则可以在关系的两端都使用单个连字符连接, 在这种情况下解读为“任意”。 如果想知道两个用户是否是朋友, 忽略掉方向, 可以使用下面的模式。
使用节点和关系标识
在Cypher查询中, 节点和关系都可以与标识关联, 这种关联使得以后可以在同样的查询中引用同一个图形实体。 下面的例子在返回语句中引用了movie节点。关系也可以命名, 使用稍微不同的语法:
要命名一个关系, 在关系类型之前, 简单地为要命名的关系在方括号里面指定名字即可。当创建复杂的模式时, 命名节点和关系是非常有用的, 因为在以后的Cypher查询的其他地方可以引用它们。 但是, 如果以后不需要引用图形实体, 避免使用标识将会使查询可读和易于理解。
在前面的例子中, 节点是被命名的(user是起始节点而movie是查询需要返回的节点) , 但是关系没被命名, 因为没有任何地方引用它。 要使关系匿名, 只需在方括号内保留冒号后面的关系类型, 就像在原始的查询中做得一样:
类似地, 节点也可以匿名。 要使节点匿名, 使用空的圆括号() 指定节点。 为了演示这种方法, 我们编写另一个Cypher查询, 这里想要从user节点返回所有的HAS_SEEN关系, 而不必担心movie节点:
使用空的圆括号描述一个期望的节点, 但是不在意其任何属性, 以后也不想引用它, 因此不给它命名。
在Cypher查询的match语句中可以不使用圆括号指定命名节点, 例如startuser=node(1) match user-[: HAS_SEEN]->movie return movie。 在复杂的查询中, 如果可能, 也可以去掉圆括号, 以简化查询且使之可读。 匿名节点必须有圆括号。
复杂模式匹配
Cypher查询支持相当复杂的模式匹配。 让我们看看另一个例子: 查找用户1的朋友看过的所有电影。 在第4章中已经使用Neo4j遍历API解决了这个问题, 因此, 现在看看如何使用Cypher查询解决这个问题:
从已知的名字为john(节点编号是1) 开始, 匹配IS_FRIEND_OF关系指向的另一个节点(匿名) , 依次具有HAS_SEEN关系指向另一个movie节点。没有必要命名所有的关系以及紧接着的节点。 所有需要返回的是代表John的朋友已经看过的电影节点。运行这个查询将会返回John的朋友已经看过的所有电影节点, 不管John是否看过:
如果想要这个社交网络基于John的朋友的喜好为John推荐电影, 那么应该跳过他自己已经看过的电影。 要得到想要的结果, 在前一个例子的结果中使用匹配John已经看过的电影模式进行过滤。 使用Cypher查询, 在同一个查询中, 如果需要, 可以在两个模式中引用相同的节点, 匹配多个模式。

Cypher查询中的多个模式使用逗号(, ) 作为分隔符分开。 这里的第一个模式是前一个例子中使用的模式——匹配John的朋友已经看过的电影 。 第二个模式匹配John已经看过的所有电影。作为结果的节点必须匹配所有逗号隔开的模式, 相当于一个“并”(AND) 语句。
如果这里感兴趣的位是使用同一个节点作为两个模式中的锚点(两个模式都从同一个john节点开始, 都匹配同一个movie节点) 。如果运行这个查询, 将会得到单一的结果: Fargo。
很明显这并不是所要的结果。 匹配了所有的John的朋友已经看过的电影(结果是三部电影) , 然后匹配那些John已经看过的, 结果是John和John的一些朋友看过的。尽管这个可以成为一个有用的查询(如果要回答John和John的朋友共同看过的电影这个问题) , 但在这里不是我们想要的答案。需要用匹配不存在的关系: John没有看过的电影, 替换第二个模式。 下面的程序演示了如何使用NOT语句句法查找John的朋友看过, 但是John没有看过的电影。
第一个模式与以前的完全一样——匹配John的朋友看过的电影。第二个模式, where语句的一部分, 过滤第一个模式返回的电影, 通过HAS_SEEN关系有选择的连接 。
查找起始节点
Neo4j图形数据库的查询遵从标准的模式: 查找起始节点并且运行遍历。 到目前为止, 在所有的遍历中, 我们一直使用Neo4j核心API、 遍历API和Cypher遵从这个模式查询。 可以通过特殊的节点编号直接查询以定位起始节点, 或者使用Lucene索引查找, 像在第5章中学习的那样。 首先让我们回顾一下通过编号直接查找。
通过编号查找节点
就Cypher查询而言, 在Cypher查询的开始, 在关键字start之后就指定了起始节点。 在前面的例子中, 到目前为止, 我们一直通过直接编号查找加载起始节点, 如下面的程序所示。
通过在node关键字后面的圆括号中简单指定编号加载节点 。如果有一个起始节点, 这就是可行的。 但是, 有时需要对多个起始节点使用同样的模式并得到所有的匹配结果——例如, 如果想要查找John或者Jack看过的电影。
通过多个节点编号加载多个节点
在start语句中使用多个编号, 需要列出以逗号隔开的编号参数值, 如下面的程序所示。
start语句中使用单个标识符指定了两个节点编号: user。 下一步是模式匹配查找用户看过的所有电影。 user标识符引用了节点1或节点3, 因此该模式匹配了用户1(这里是John) 或者用户3(Jack) 看过的电影。 输出的结果如下:
最后一个查询的return语句中distinct关键字用以删除重复的结果。distinct的作用与SQL查询相同——在结果集中排除重复的结果。 Jack和John都看了Fargo, 因此, 如果不使用关键词distinct, 则Fargo将在结果中出现两次。
但是, 大部分情况下, 我们并不知道感兴趣节点的节点编号——可能知道一些其他的属性, 如用户的名字、 电影的名字或其他一些相似的东西。 在下一节, 我们将学习如何使用这些信息加载起始节点。
使用索引查找起始节点
我们在第5章介绍了索引在遍历中是作为推荐的方法查找起始节点。Cypher也支持直接访问Lucene索引, 因此, Neo4j中常用的遍历术语便成为:1) 使用Lucene索引查找一个或多个节点 2) 从步骤1中找到的节点开始做遍历。
如何在Cypher中使用这种模式? Cypher查询通过使用模式匹配工作, 因此, 常用的用法如下:1) 使用Lucene索引查找一个或多个节点 2) 通过将从步骤1中找到的节点附加到模式中做模式匹配 3) 返回感兴趣的实体。现在唯一的问题是如何在Cypher查询的start语句中做Lucene索引查找,而不是通过编号加载节点。 这非常简单, 下面的程序做出了演示。
现在的start语句句法稍微有一点不同。 node: users部分指定了一个感兴趣的来自users索引的节点。 当给索引添加节点时, 索引的名字必须匹配使用的索引名字。 圆括号中的参数指定了在索引中查找的键——值对; 在这种情况下, 匹配的是name属性与值“John Johnson”。 如果这样的索引入口在users索引中找到, 那个节点将从Neo4j数据库中加载并在Cypher查询中使用。这种索引查找句法需要正好键-值对的匹配, 并且是大小写敏感的, 因此具有name属性“john johnson”或者“John Johnso”将不会返回。 同时, 如果多个节点以同一键-值对(如果在数据库中有多于一个的John Johnson) 索引,所有匹配的节点都要加载; 这与前面具有多个节点编号的例子非常相似。如果使用Lucene查询的完全功能查找起始节点, 可以使用与本地Lucene原始查询稍微不同的句法。
这个例子与前面介绍的例子完全一样, 唯一的区别是索引查找的参数。这一次所有的索引参数都传递到双引号中, 并且包含一个本地Lucene查询。这允许利用强大的Lucene查询结构, 例如, 通配符或多属性匹配。
关于本地Lucene查询功能的文档可以在Lucene网站上找到:http://lucene.apache.org/core/3_6_0/queryparsersyntax.html。
这里是在使用Cypher查询中的本地Lucene查询。
第5章介绍的自动索引也能够以同样的方法用作Cypher查询的一部分。需要做的是对索引名字使用节点自动索引(node_auto_index) , 而不是前面查询中的对users使用节点自动索引。
使用基于模式的索引查找起始节点在前面的几章中, 我们讨论了如何通过给节点指定标签确定Neo4j节点类型。 我们也提到如何使用标签作为基于模式的、 内置索引查找图形。 也可以使用同一个索引在Cypher中查找节点。
让我们看一看如何使用标签通过名字查找用户节点。
指定使用模式索引的标签被定义为节点标识符的一个部分, 用冒号分隔。 必须在圆括号内放一个与标识符相关的标签。 索引查询被指定为where语句的一个部分, 与在SQL所做的非常相似。
基于标签的索引只能用于完全属性值的查找。 对全文的搜索, 必须使用手动方法创建索引, 就像前一节讲的那样。现在, 我们知道了如何在Cypher查询中的start语句使用索引查找节点。但是, 在执行Cypher查询时, 如果要在图形模式中确定多个节点, 并要求对它们分别匹配时应如何做? 如果要查找John和Jack都看过的所有电影应该如何做? 使用Cypher通过指定多个不同的起始节点作为图形数据库入口点也是很容易实现的。
Cypher查询中的多个起始节点
要指定图形数据库的多个入口点, 可以在Cypher查询的start语句中使用逗号分隔列表, 程序如下所示。
起始节点以逗号分隔列表出现, 每一个节点有自己的标识符, 这个标识符可以在整个查询中使用 。 进行匹配时, 所有的起始节点可以用作单个模式的一部分, 或者可以像在本例中用作独立的模式 。 本例中的两个模式都是movie节点(在两个模式中具有同样的名字, 因此代表同一个节点) , 这也是Cypher查询的结果 。
过滤数据
使用Cypher查询只靠起始节点和模式有时并不足以获得需要的结果。 在一些情况下, 需要对节点和关系再做一些过滤以决定返回哪些结果。 与在关系数据库中的SQL查询相同, Cypher查询过滤使用where语句实现。一般情况下, where语句基于节点或关系的一些属性过滤结果。 让我们看一个例子, 查找用户John出生于1980年后的所有朋友。 我们假设每一个用户节点都有一个出生年(yearOfBirth) 的整型属性存储用户的出生年份。 具体程序如下所示。
通过索引查找寻找起始节点, 并用IS_FRIEND_OF关系模式匹配朋友节点, 而不考虑方向 。 下一步, 过滤匹配了的朋友节点, 找出生年份大于1980的朋友节点。 因为出生年份具有整型属性, 因此可以在where语句中做标准的数字比较。对于字符串属性, 除标准的等于号(=) 比较外, 还可以使用正则表达式过滤掉指定的值。 例如, 要查找所有邮箱地址具有“gmail.com”的朋友, 可以运行下面的查询。
如上所示, Cypher中的正则表达式比较符是等于波浪号(=~) 。 正则表达式放在两个正斜杠之间(/) 。 表达式本身遵从标准的Java正则表达式句法(参看http://docs.oracle.com/javase/tutorial/essential/regex/for more information) 。但是, 如果所有的用户或节点没有存储邮箱地址, 则将发生什么情况?就像我们以前讨论的那样, Neo4j允许半结构化、 无机制的数据结构, 因此没有强制两个节点必须有相同的属性。 本书例子的数据集有些user节点具有email属性, 但并不是都有。 让我们看看如何使用Cypher查询并不是所有节点都具有的属性。
要过滤具有给定属性的节点而不管属性的值(例如, 具有Twitter账号的所有朋友) , 则需要使用Cypher的has函数。
获得结果
Cypher查询的结果用return语句返回。 到目前为止, 我们已经使用它返回了感兴趣的节点, 但是return语句不仅仅能返回节点——也可以返回关系、 节点和关系的属性, 甚至子图形的整个路径。
Neo4j的路径代表通过关系连接的节点集, 例如, node1–[:relationship1]-node2–[: relationship2]-node3。
返回属性
在前面的例子中, 使用Cypher查找John的朋友已经看过但John没有看过的所有电影, 并且返回了匹配的movie节点。 如果使用这些数据在网页上显示推荐的电影名字, 则应该返回具有所有属性的整个movie节点——比需要的数据还多。 更好的方法是仅仅从查询中返回感兴趣的node属性。

例如, 如果从Neo4j Shell运行该程序, 程序的输出结果将比以前看到的简单得多。
如果引用的属性并不是结果集中的所有实体都具有, 那对不具备引用属性的实体将返回null。
返回关系
有时查询图形数据库中的某些关系是合理的。 假设想显示一个用户对看过电影的评级, 评级是HAS_SEEN关系的一个属性(实际属性名是stars, 代表给予电影星的数量) , 因此需要返回这些关系。 下面的程序做出了演示。
查询通过从索引查找用户John Johnson开始并匹配所有他看过的movie节点 。 然后返回例子中的HAS_SEEN关系。 注意要返回一个关系, 需要有一个标识符(这里是r) 。这个查询的输出结果如下所示:
如果只对关系属性的星级感兴趣, 可以仅仅从查询中返回那个属性。 就像节点属性一样, 关系属性可以在return语句中引用。 下列的程序演示了这一用法。
这一次不是整个关系实体, 而是仅仅返回了感兴趣的stars属性。
返回路径
除节点和属性外, 还可以从Cypher查询返回整个路径。 例如, 当要基于John的朋友看过的电影推荐电影时, 可能对每一部电影是如何被推荐的感兴趣, 这样可以从开始的用户节点, 通过所有的朋友到推荐的电影, 返回整个路径。 下面的程序对这一方法做了演示:
要返回路径作为查询的结果, 将需要给它一个标识符并能对它做出引用 。 那么, 在return语句中通过指定标识符就可以返回引用的路径。返回的路径输出将包含属于它的所有节点和关系:

在前面的例子中, 从Cypher查询返回了一个node属性和一个路径。 这里讨论的所有可返回的图形实体可以被任意组合指定。当在屏幕上显示或在纸上打印数据时, 通常并不想一次显示所有的结果, 而是把它们分为数页以便更为可读或可用。 下面将要介绍如何对Cypher查询的结果分页。
分页结果
结果中包含很多实体, 可能需要将结果分成几页以显示在网页上。 要对Cypher查询结果进行分页, Neo4j有三个简单明了的语句。
- order——在分页之前, 对结果进行排序, 因此分页返回的结果是一致的, 无论是往前还是往后分页
- skip——划分结果集以便跳到指定的页
- limit——以页面尺寸限制返回结果的数量
假设数据库中的一个用户是一个电影迷, 他看过并评级了上百部电影,如果想在一页上显示这个用户评价的所有电影(给定的星级) , 则显示的字型将小的无法阅读(或者根本容纳不下) 。可以确定以电影名字排序, 每一网页只显示10部电影。 要查询图形数据库得到这样分页的结果, 需要使用order、 limit和skip语句。 下面的查询返回了第三页(21~30项) 。
就像我们讨论过的, 匹配了这个用户看过的电影后, 通过name属性对结果进行排序 。 因为对结果的第三页感兴趣, 所以跳过前两页共20项 。 最后, 限制返回的结果集为页面的大小(本例子中是10)。Neo4j在线手册包括了一份方便打印的Cypher参考卡, 卡中有常用句法和详细的查询: http://neo4j.org/resources/cypher。

用Cypher更新图形数据
从Neo4j 1.7开始, 就可以使用Cypher对图形数据库运行变更操作如创建、 更新、 删除节点与关系以及它们的属性。Cypher图形变更操作是一个Neo4j数据库相对新的特性, 因此, 变更的句法在未来发布的版本中可能会有较大的变化。 本书是基于Neo4j 2.0版的Neo4j句法。 建议读者参考最新版本的句法手册(http://docs.neo4j.org/chunked/stable/query-write.html)。
创建新图形实体
要创建一个具有属性的节点, 可以使用以下的句法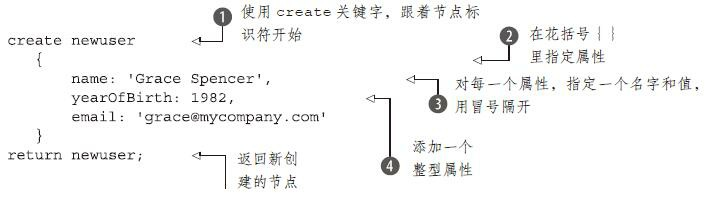
创建(create) 图形实体命令, 并不令人吃惊, 就是create跟着节点标识符 。 紧接着, 指定一个用冒号分隔的属性列表加到节点上, 用花括号括着。 每一个属性用它的名字指定, 跟着一个冒号和一个属性值 。 字符串属性值以单引号括着, 但是数值和布尔属性不需要任何引号 。 最后, 使用它的标识符返回新创建的节点, 就像在前面的Cypher例子一样。
现在已经创建了一个节点, 那么如何创建一个关系呢? 让我们使新创建的用户Grace成为John的朋友。
要想在已存在的两个节点之间创建一个关系, 需要首先引用它们。 这个操作与在只读查询中指定起始节点完全一样, 使用start语句和节点查询 。 下一步, 在create语句中, 简单地指定图形路径作为模式通过它们的标识符引用起始节点并且设置在它们之间想要创建的关系 。
到目前为止, 已经创建了一个具有一些属性的节点和一个关系。 但是可以用一个命令完成所有的这一切。
在本例中, 固定一个已经存在的节点john 。 在create语句中, 指定了一个通过不存在的IS_FRIEND_OF关系从john到一个不存在的节点grace的模式, 同以前一样, 具有相同的属性 。Cypher聪明地知道哪个节点和关系是固定的(start语句中的john) , 哪个是新的并且应该在数据库中创建(IS_FRIEND_OF关系和grace节点) 。 这是一个具有强大功能的, 可以创建具有属性的新节点和关系的整个路径的方法。Cypher create语句将创建匹配模式中的所有元素, 而不管它们是否存在。 如果运行前面的节点程序, 创建了John的朋友Grace Spencer两次, 将得到两个Grace Spencer节点和两个从John节点的IS_FRIEND_OF关系。 这可能不是想要的结果。 要只创建不存在的图形实体, 应该使用创建唯一的(create unique) Cypher命令, 下面的程序作了演示。
对前面例子的唯一改变是使用create unique命令。 多次运行这段程序将不会产生实体数的乘积——将总是有一个Grace Spencer节点和一个在John和Grace节点之间的IS_FRIEND_OF关系。
删除数据
要删除节点, Cypher提供了一个delete命令。 让我们删除刚刚创建的用户节点Grace。
但是, 运行这个命令将会出错, 警告节点具有关系。 在Neo4j中, 只能删除没有任何关系的节点(无论是进还是出的关系) 。 要明确的是删除一个节点, 同时也会删除它的关系, 如下面的程序所示:
这里使用了标准模式匹配grace节点的进或出的所有关系, 并且删除了指定节点的开始或结束的所有关系 。
delete查询的输出不包含任何数据, 但是将指出删除的节点和关系数:
更新节点和关系属性
假设John的出生日期有错误, 需要对其进行更新。 完成这一工作的命令如下:
可以看到句法非常简单: 首先选择要更新的节点 , 然后使用set命令设置选择节点的属性并给予新值。 如果要设置的属性并不存在, 将会创建这一属性。可以选择多个节点添加同一属性:
Neo4j不允许图形实体具有空(Null) 属性值。 事实上, 空属性值认为是不存在的属性。 因此, 如果想要删除一个属性, 将使用delete命令。 下面的程序做出了演示:
Cypher中的图形变更操作是在本书的写作时Neo4j的一个相对较新的特性。 我们已经演示了一些有用的例子帮助理解。 关于更多和最新涉及Cypher句法的信息, 可以在下面网页查阅Neo4j手册: http://docs.neo4j.org/chunked/stable/cypher-query-lang.html。
高级Cypher
聚合
就像在SQL中的GROUP BY一样, Cypher支持查询中的聚合函数。 不是使用一个专用GROUP BY语句, Cypher中的分组关键词被定义为所有的查询非聚合结果。 下面的程序展示如何计算图形数据库中每一个用户的朋友数:
在本例中查找了整个图形数据库, 因此, 所有节点都作为起始节点。 对每一个user节点, 通过跟随一级IS_FRIEND_OF关系匹配他们的直接朋友。 return语句包含一个非聚合条目(user节点) 和一个聚合函数(count)。 这意味着在使用user节点分组结果, 使每一个用户的结果为一行。 也可以在order by语句中使用聚合值排序整个结果集 。除count函数外, Cypher支持SQL的所有常用的聚合函数: SUM的数值求和、 AVG计算平均值到MAX和MIN寻找数值属性中的最大值和最小值。
要求John所有朋友的平均年龄, 可以使用以下查询:
在用于数学计算之前, 这里检查了这个节点具有一个出生年的属性设置 。 然后返回计算的平均值 。
函数
Cypher支持多项函数可用于在查询中计算表达式, 让我们看看其中的一些。Cypher函数用于访问图形实体的内部属性, 例如节点和关系的编号和节点标签(类型) 。 在计数的例子中, 已经看到了用ID(node) 函数获取指定节点的内部编号。 另外, 也可以使用TYPE(relationship) 函数查找一个关
系的类型。为了演示TYPE函数的使用, 让我们对下面的问题寻找答案: “每一类型有多少个关系开始于或结束于用户John? ”, 下面的程序给出了实现这一功能的Cypher查询:
本例中的前两步非常熟悉, 使用索引查找表查找起始节点, 并且使用match语句匹配查找所有的邻居节点 。 在以后的查询中使用标识符rel引用每一个关系。 最后, 使用TYPE函数返回每一个关系的类型与其数量 。 由于TYPE是一个非聚合函数, 结果将会以关系类型分组。Cypher也支持一些这样的函数, 可以在查询内以可迭代集的方式方便地查询。 作为一个例子, 让我们解决下面的问题: John希望在Facebook上介绍给Kate。 他不认识Kate, 但是想找出谁是Kate的朋友, 朋友的朋友认识她,直至第三层的朋友。 因为他需要使用Facebook, 所以他仅仅对Facebook上的人(即有Facebook Id属性设置的人) 感兴趣。 下面的程序给出了需要的查询:
通过在Neo4j数据库中定位知道的代表John和Kate的起始节点开始查询。 在match语句中, 将会找到通过IS_FRIEND_OF关系连接John和Kate的所有路径, 直到关系的第3级。 在后面的查询中使用标识符p引用匹配了的路径。
智能位来自于where语句。 使用NODES(p) Cypher函数提取给定路径上的所有节点集。 使用HAS函数检查每一个节点是否有facebookId属性。 然后使用ALL函数对节点集中的每一个元素使用HAS函数。 如果在给定的可迭代集中每一个元素匹配了HAS函数的定义, ALL函数将会返回true,因此, 如果在路径p上的一个节点没有facebookId属性, 这条路径将被放弃。最终, 返回了符合所有标准的路径( ) 。 这些路径包含所有John将要联系的人, 因此他可以在Facebook上被推荐给Kate。在本例中, 函数的使用如下, 这只是很少的几个函数:
- HAS(graphEntity.propertyName) ——如果一个节点或关系具有给定名字的属性存在, 则返回true。
- NODES(path) ——把一个路径转换成一个可迭代的节点集。
- ALL(x in collection where predicate(x) ) ——如果collection中的每一个单个元素匹配了给定的predicate, 则返回true。
Neo4j支持许多具有相似目的的函数。 例如, 与NODES(path) 函数类似、 RELATIO NSHIPS(path) 函数返回在一个给定路径上的所有节点集。除ALL函数外, Neo4j也支持其他一些基于谓词表述的布尔函数:
NONE(x in collection where predicate(x) ) ——如果提供的集合中没有元素匹配谓词表述, 返回true; 否则, 返回false。
ANY(x in collection where predicate(x) ) ——如果至少有一个元素匹配谓词表述, 返回true; 如果没有匹配的, 返回false。
SINGLE( x in collection where predicate( x) ) ——如果正好有一个元素匹配谓词表述, 返回true; 如果没有或多于一个匹配的, 这个函数返回false。
with语句的管道功能
在Cypher中, 可以将一个查询的输出链接到另一个查询中, 从而创建功能强大的图形结构。 Cypher中的链( 或管道) 语句是with。为了演示它的用法, 让我们在前面例子的基础上来演示, 在前面的例子中使用Cypher统计从john节点的每一类关系的数量。 让我们添加一个需求,仅包含出现多于一次的关系: 如果John已经看了两部电影, 应该包含HAS_SEEN关系, 但是如果他只看了一部电影( 或者一部也没看) , 这些关系不应该包含在内。问题涉及在聚合函数上的过滤。 在SQL中, 在聚合函数上过滤是由HAVING语句完成的, 但是Cypher并不支持这个。 而在Cypher中可以使用with, 就像下面的程序演示的一样。
查询从起始节点以索引查找开始, 然后匹配所有与之相连的关系。 但是, 不是像以前一样返回聚合的结果, 而是用with语句链接它。 在with语句中, 重新命名输出, 这个输出将用于链接命令(type和count) 的输入。 链接以后, 输出用with语句定义为新的where语句的输入。 最后, 返回匹配的结果。
Cypher的兼容性
我们已经提到Cypher是一种发展非常快的语言, 它的句法经常发生变化。 为了给Cypher添加有价值的新功能, 开发者有时需要引入重大的更改,这将使得在早期版本的Neo4j中写的查询在新版本的Neo4j数据库中运行失败。幸运的是, 有一个简单的设置可以让你在任意版本的Neo4j Cypher引擎上运行查询。 即可以在运行查询之前指定查询句法符合的Neo4j版本。
可以在查询的开始, 在start语句之前 使用CYPHER关键词跟着Neo4j版本指定需要的Neo4j版本。除了在所有的查询中使用Cypher分析器版本外, 还可以设置全局配置选项cypher_parser_version。 这个选项在neo4j的属性文件里设置。

- 点赞
- 收藏
- 关注作者
评论(0)