Neo4j 版本和安装Neo4j 版本一览

1. 目标
在本指南中,我们将逐步介绍如何在Neo4j 4 企业版DBMS中管理多个数据库。
本文原文链接:https://neo4j.com/developer/manage-multiple-databases/
2. 先决条件
请下载并安装Neo4j(4.0或更高版本)企业版。 阅读有关图数据库的部分会有所帮助。
3. 概述
在Neo4j(v4.0 +)中,我们可以同时创建和使用多个活动数据库。 这适用于独立部署和因果群集部署,并允许我们在一个Neo4j数据库安装中维护多个单独的图。
当我们创建数据库时,Neo4j将首先创建系统数据库和默认数据库。 系统数据库名为system,它包含适用于整个数据库的总体信息--管理单个数据库的执行(停止和启动)以及维护用户特权(安全角色和特权)。 默认数据库名为neo4j(可以更改),在这里我们可以在图中存储和查询数据,并与其他应用程序和工具集成。 我们还可以根据需要创建其他数据库,以存储可能与我们的任何其他数据库都不相关的其他图和不同数据。
4. 系统设置
我们将需要运行数据库并打开Neo4j浏览器,以逐步完成本指南。 如果您不确定如何创建和启动数据库,请参照本指南中提供的在Neo4j Desktop里的逐项指导说明。
4.1 查看初始数据库
如前所述,当安装Neo4j并创建一个实例时,它将由两个数据库启动:一个系统数据库和一个默认(neo4j)数据库。 启动Neo4j浏览器将自动将我们指向neo4j默认数据库,如命令行中neo4j$ 提示符所示。

如果要查看系统信息(查看、创建/删除、管理数据库),则需要切换到系统数据库。 我们可以使用:use命令来做到这一点,然后告诉它我们想要哪个数据库。
命令::use system
结果:

现在,我们可以运行命令来查看使用实例创建的数据库。 SHOW DATABASES命令将显示我们实例中的所有数据库(或群集中跨实例的数据库)以及地址、角色、请求和当前状态,任何错误以及默认的数据库。请记住,此时,我们只希望使用系统数据库和默认(neo4j)数据库。

如何我们预期的那样。 现在,将另一个数据库添加到列表中。
4.2 创建一个新的数据库
要将数据库添加到实例中,我们可以使用CREATE DATABASE命令。 现在我们将使用一个名为movieGraph的示例,您可以为此数据库选择任何名称。

数据库命名不区分大小写。 创建数据库movieGraph将在系统信息中显示moviegraph作为名称,但是您可以任意使用movieGraph或moviegraph更改为数据库。 两者都将连接到相同的数据库,并且不允许您使用大写/小写字母(例如MovieGraph,moviegraph,mOvIeGrApH等)的任何其他组合来创建另一个数据库。
虽然结果消息似乎不能说服我们的创建命令起作用,但是我们可以通过再次运行SHOW DATABASES命令来验证新数据库是否显示在列表中,以进行验证!

看起来不错。 我们可以切换到新数据库以开始专门使用该数据库(命令是:use movieGraph)。

加载数据并使用我们的movieGraph数据库
接下来,我们将一些样本数据加载到movieGraph数据库中并使用它。 在执行此操作之前,让我们通过使用CALL db.schema.visualization()过程查看模式来验证数据库是否真正为空。

Neo4j的早期版本使用CALL db.schema()过程,该过程已转换为上面显示的更新过程。
结果中未显示任何节点或关系数据,因此数据库为空。添加一点点数据后,结果中将看到一个可视化的数据模型。 我们可以通过编写Cypher查询以返回任何节点和关系来进行另一项快速测试。
命令:MATCH (node)-[rel]-(other) RETURN node, rel, other
结果:

现在我们再来添加一些数据。
4.2 加载电影数据
我们将使用Neo4j用户可能已经熟悉的电影小数据集。 要加载,请在命令行中输入:play movies命令并执行。 指南将显示在结果窗格中。

我们可以通过单击窗格右侧的箭头导航到第二张幻灯片,然后将出现一个包含长Cypher查询的幻灯片。

右侧的Cypher查询将以灰色虚线标出轮廓。 我们可以单击该查询,它将复制/粘贴到命令行中。 单击以执行查询,这将返回一些结果,确认已加载数据。
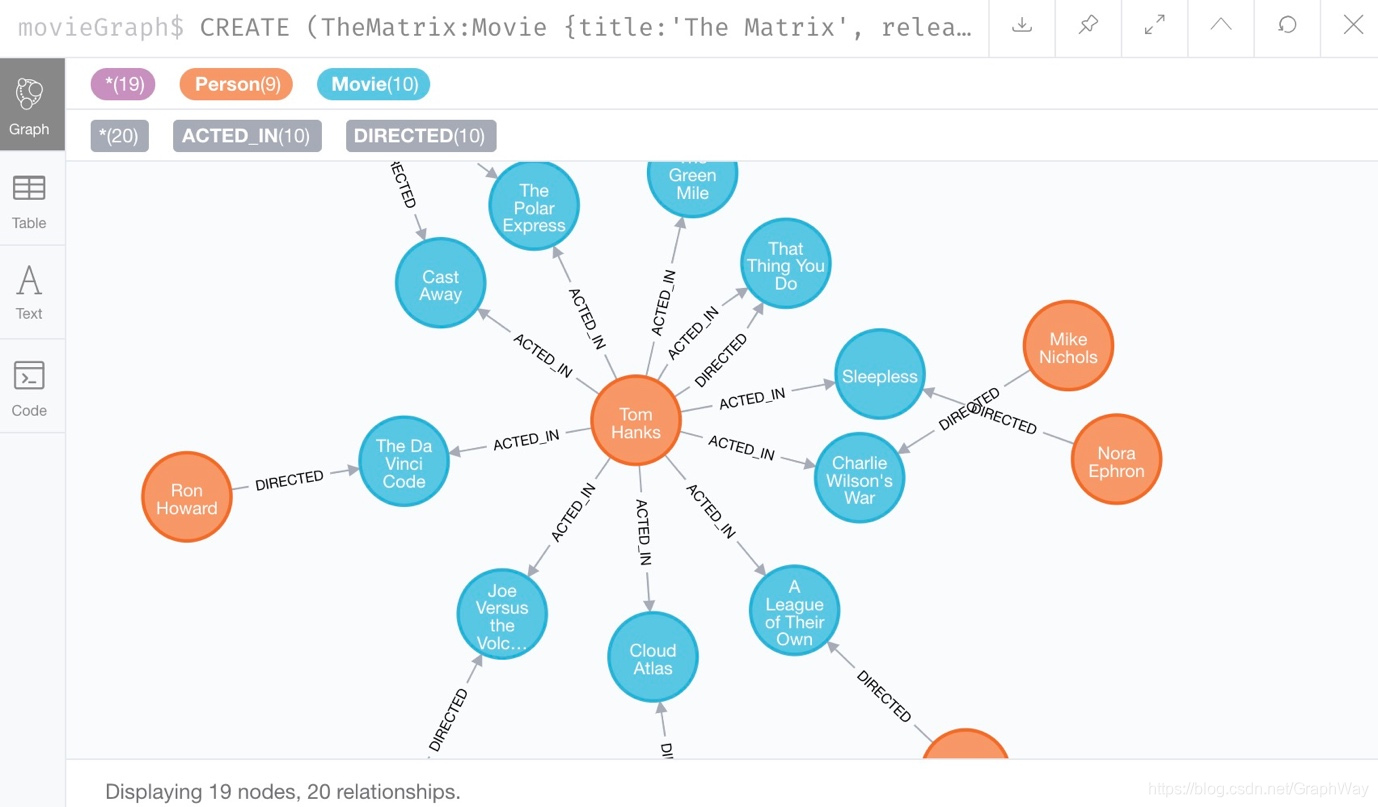
结果窗格中图表的颜色和位置可能会有所不同。 但是,如果在本指南中任何时候数据都不同步,则可以按照本指南底部的步骤清除实例,然后再次尝试加载数据。
我们还可以再次检查架构过程,以查看数据在数据库(数据模型)中的组织方式。 再次使用命令CALL db.schema.visualization()并执行它,以查看我们具有通过几种不同类型的关系连接的Person节点和Movie节点。

现在,我们可以对想要的电影数据运行任何查询。 例如,使用如下所示的通用查询将可以搜索与其他节点有任何关系的节点。

尽管我们可以查询和处理电影数据,但我们希望使用多数据库功能,并看到一个数据库中的数据无法在另一个数据库中访问。 为此,我们需要在另一个数据库中加载一些不同的数据。
4.3 加载数据并使用我们的neo4j数据库
让我们回到默认的neo4j数据库,并在其中加载Northwind零售系统数据。 这样,当我们查看数据库(movieGraph和neo4j)时,将看到两组完全不同的数据。:use neo4j命令会将我们切换到该数据库,并允许我们在该数据库中加载。

为了确认当前该数据库中没有数据,我们可以对neo4j运行CALL db.schema.visualization()过程。

这样就看起来都很清楚。 如果我们要确认的话,我们也可以从上面运行测试查询。 现在我们准备添加一些数据。
4.4 加载northwind数据
我们将使用浏览器指南:play northwind,该指南具有内置的Cypher查询,我们可以运行这些查询来加载零售供应商,产品和产品类别。

单击结果窗格右侧的箭头以转到指南中的下一张幻灯片,将有3个load语句和3个索引语句。
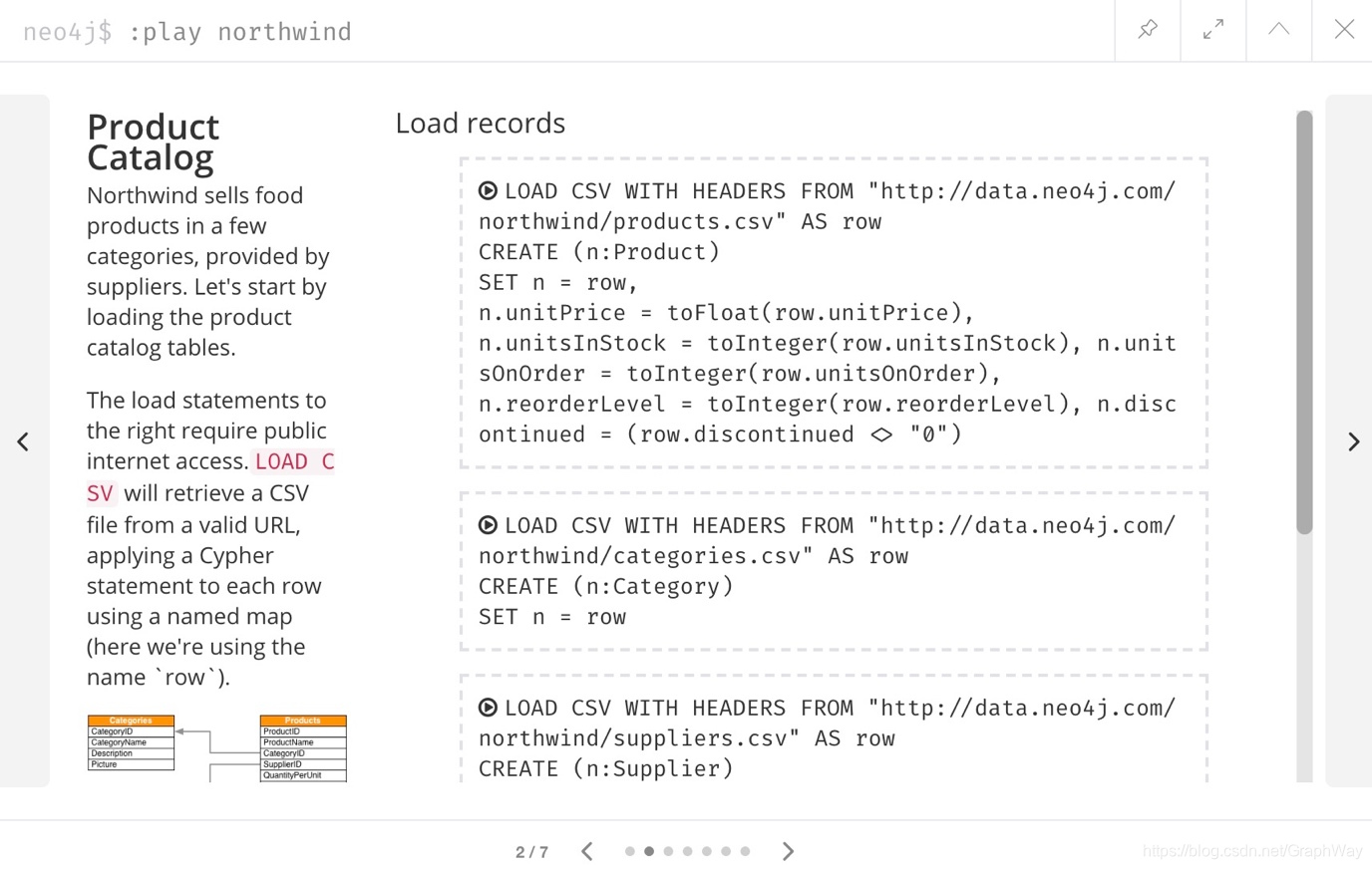
执行所有6个步骤以填充节点,然后再次单击指南上的向右箭头以前进至下一张幻灯片。 在此幻灯片上,我们还有2条语句来查找节点并在它们之间创建关系。
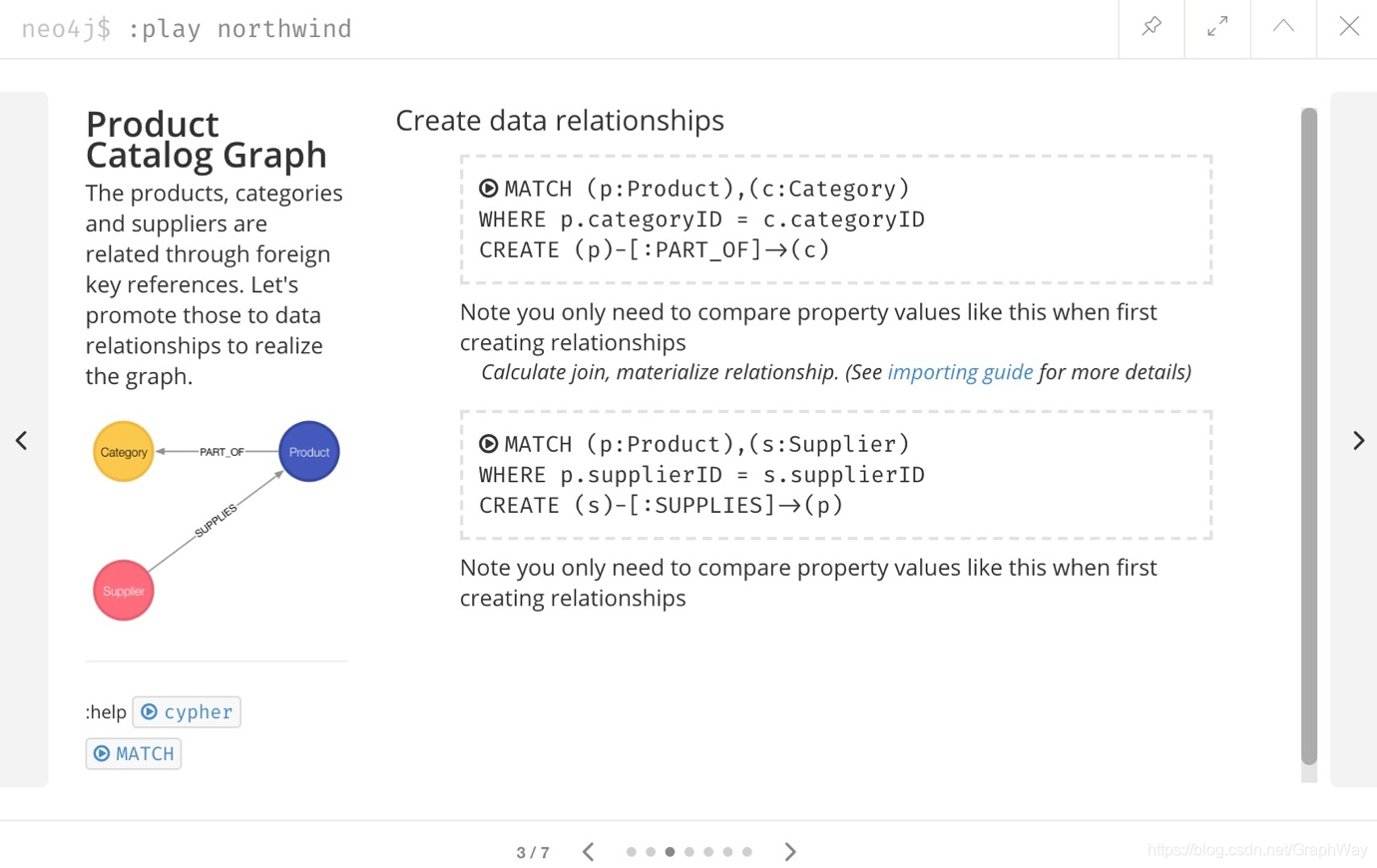
单击并运行这两个语句,然后我们可以通过再次运行模式过程来检查数据是否正确加载。 我们应该期望与产品节点有关系的供应商节点与类别节点有关系的供应商节点。
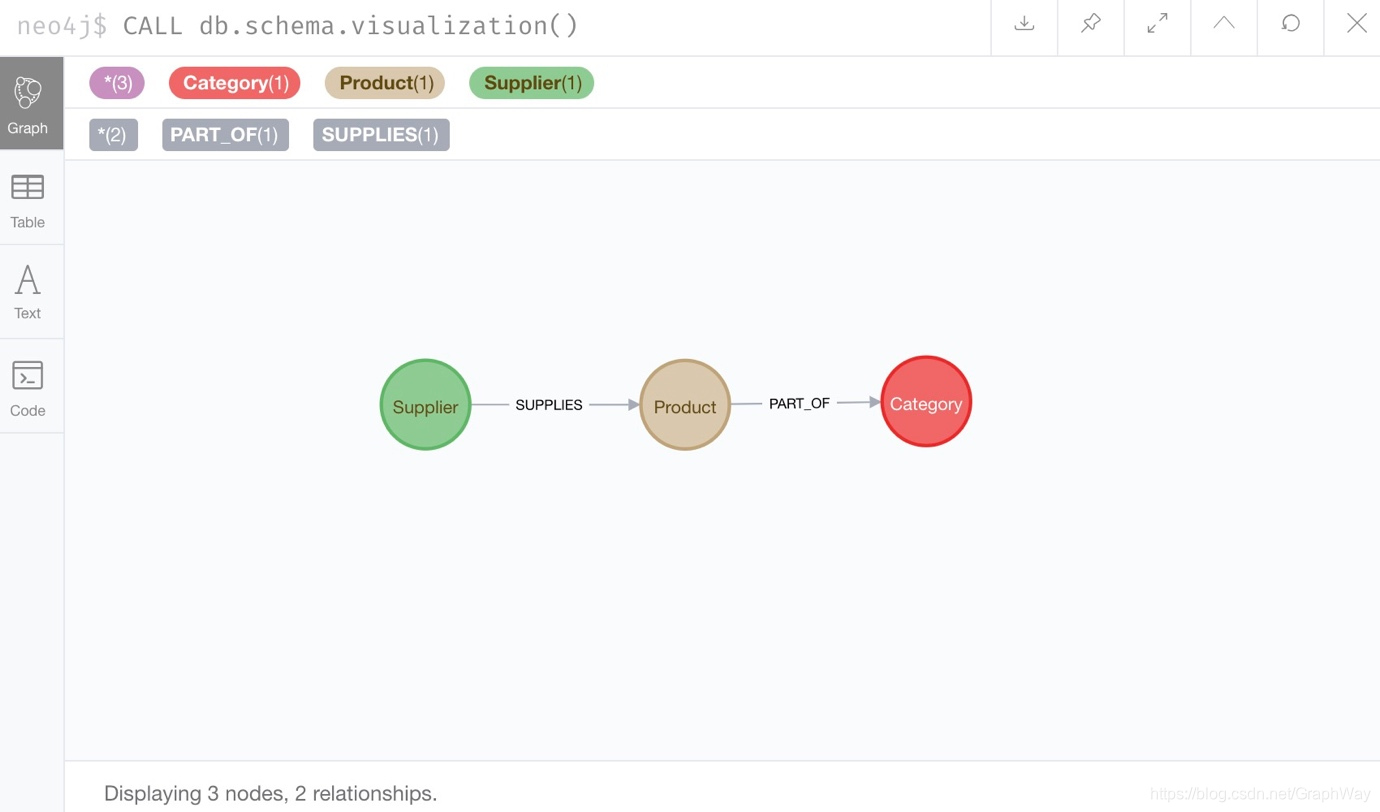
结果窗格中图表的颜色和位置可能会有所不同。 但是,如果在本指南中任何时候数据都不同步,则可以按照本文底部的步骤清除实例,然后再次尝试加载数据。
那就是我们所期望的! 我们可以再次运行通用测试查询以检索一些Northwind数据。

请注意,在数据模型或测试查询中,我们看不到任何电影数据库实体或关系。 这些都在我们的movieGraph数据库中,并且是完全分开的。 如果该图中存在这些节点和关系,则测试查询将检索它们,因为我们在搜索中未指定任何特定类型的节点和关系。
我们可以再做一个步骤来验证Northwind数据是否也不在我们的movieGraph数据库中。
在数据集和数据库之间导航
让我们再次使用 :use movieGraph命令切换回movieGraph数据库。 接下来,我们运行熟悉的CALL db.schema.visualization()过程以拉回我们的数据模型。
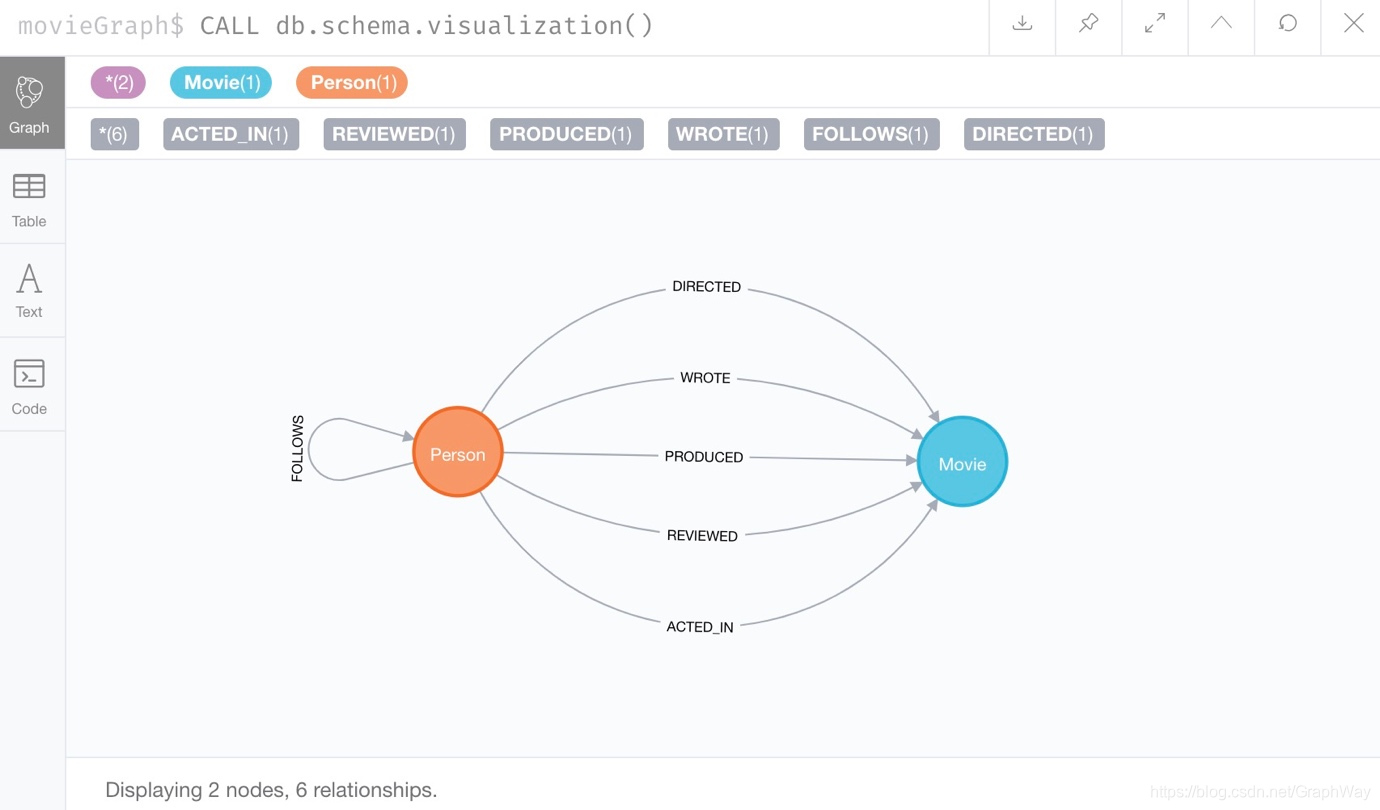
我们看到该图中没有Northwind数据。看起来不错。我们的通用测试查询也可以是另一种验证方法。
我们可以继续分别操作每个图形,但是可以在没有单独实例的情况下连接到同一Neo4j安装中的不同数据集。
4.6 清除同一实例中的数据库
最后一个管理上的区别是如何在不影响具有多个数据库的整个实例的情况下完全清除一个数据库。在处理单个实例和单个数据库方法时,用户可以删除整个实例并重新开始。但是,对于多个数据库,除非我们可以接受可以丢失其他数据库中的所有内容,否则我们无法做到这一点。
这种方法与其他DBMS相似,在这些DBMS中,我们可以删除并重新创建数据库,但保留其他所有内容。 Cypher的命令是CREATE OR REPLACE DATABASE <name>
。这将创建数据库(如果尚不存在)或将现有数据库替换为干净的数据库。
例如,在研究这些示例时,我们可能错误地更改了负载查询,或者意外地添加或删除了所需的数据。在这种情况下,删除所有数据将不会完全擦除数据模型的索引或幻影实体。相反,我们可以使用CREATE OR REPLACE DATABASE命令并重新开始。
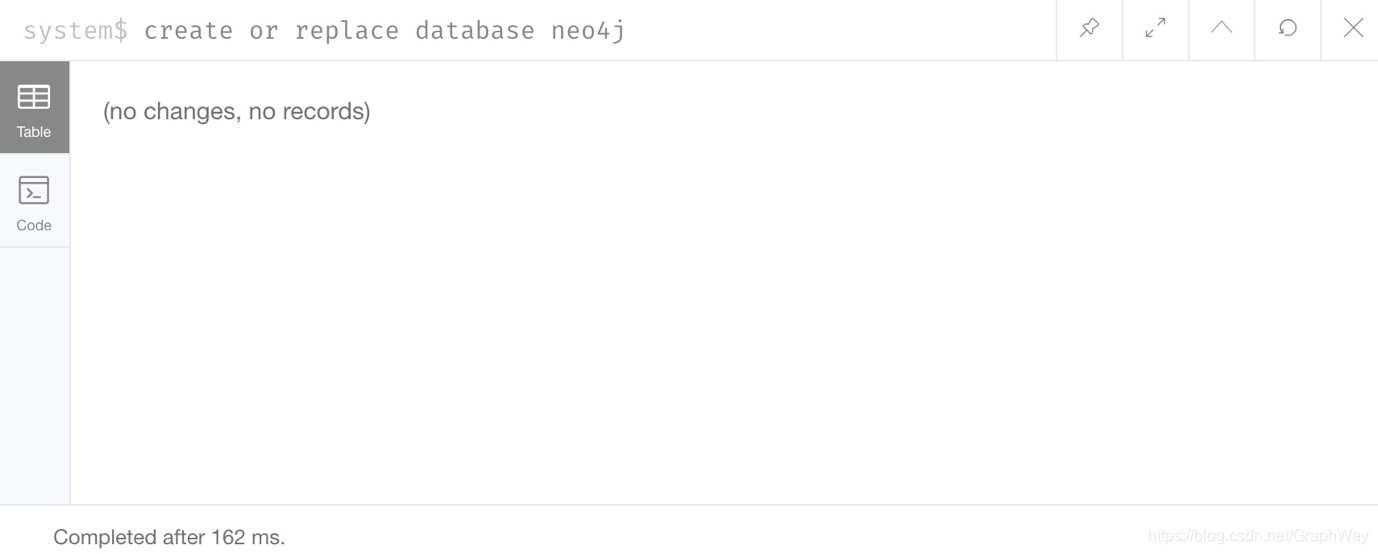
命令:CREATE OR REPLACE DATABASE neo4j
结果:

- 点赞
- 收藏
- 关注作者
评论(0)