全部内置函数详细认识(上篇)

目录
🏵️前言
🏵️结语
🏵️前言
以下我要讲解的是Python中一些重要的内置函数,其中比较重要的会详细讲解,比较简单的会直接结合代码进行剖析
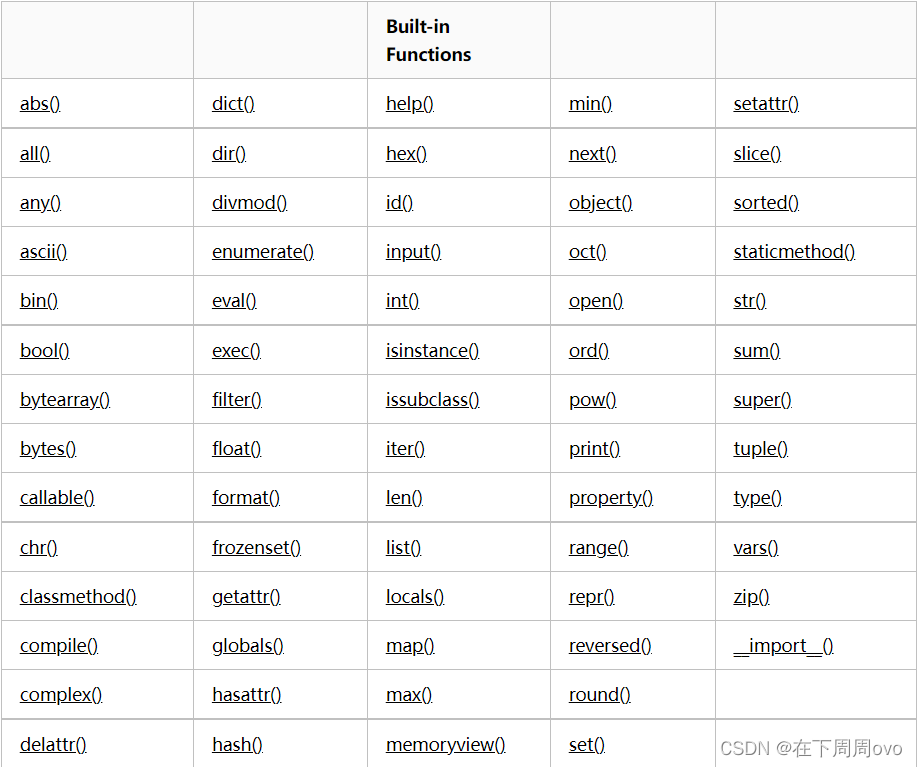
🍁一、globals()和locals()内置函数
基于字典的形式获取局部变量和全局变量
- globals()——获取全局变量的字典
- locals()——获取执行本方法所在命名空间内的局部变量的字典
用一个栗子来了解:
z = 0 print('函数外部的局部变量是:',locals()) print('函数外部的全局变量是:',globals()) def main(): global m #定义了一个全局变量m,修改他的值会对全局产生影响 m = 9 print('函数main内部的局部变量是:',locals()) print('函数main内部的全局变量是:',globals()) def wahaha(): m = 10 print('函数wahaha内部的局部变量是:',locals()) print('函数wahaha内部的全局变量是:',globals()) main() wahaha()
输出结果:

🍁二、len()和__len__()方法的异同
首先我们要知道有__len__()也叫做len的双下方法
先看代码:
lst = [1,2,3,4] print(lst.__len__()) print(len(lst)) 输出结果: 4 4从上面代码可以看出他们的输出结果是相同的,那么这两种方法到底有什么区别呢?
其实使用len()函数后,函数内部会自动帮你调用__len__()方法,相当于
def len(要测量长度的数据): 要测量长度的数据.__len__()那么我们常见的内置函数为什么不使用双下方法,而是习惯用对应函数名加括号的方法呢?
原因很简单那就是双下方法太长了而且还不好写
🍁三、range内置函数
range(10) range(1,11) #前开后闭 for i in range(1,11,2): #隔一个取一个值 print(i) #用下面方法可以证明range是一个可迭代的但不是一个迭代器 print('__next__' in dir(range(1,11,2))) 输出结果: 1 3 5 7 9 False
🍁四、dir内置函数
python中的dir()函数dir() 函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。如果参数包含方法__dir__(),该方法将被调用。如果参数不包含__dir__(),该方法将最大限度地收集参数信息。简而言之dir可以告诉我们所传入的数据类型(参数)所包含的所有内置使用方法
print(dir(list)) #告诉我列表拥有的所有方法 print(dir([1,2])) #告诉我列表拥有的所有方法 #上面的两种方法虽然实参不同但函数返回值相同输出结果:
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort'] ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
🍁五、callable内置函数
callable() 函数用于检查一个对象是否是可调用(拿着这个变量名字后面加括号可以被调用)的。如果返回 True,object 仍然可能调用失败;但如果返回 False,调用对象 object 绝对不会成功。
实例:
print(callable(print)) a = 1 print(callable(a)) print(callable(globals)) def func():pass print(callable(func)) 输出结果: True False True True
🍁六、help内置函数
help() 函数用于查看函数或模块用途的详细说明。
例如:
#返回与str相关的所有帮助 help(str)输出结果:

🍁七、__import__()内置函数
__import__() 函数用于动态加载类和函数 。
如果一个模块经常变化就可以使用 __import__() 来动态载入。
#import time time = __import__('time') #就等价于import time print(time.time()) 1657000816.799121
拓展:
某个方法属于某个数据类型的变量就用 . 调用,如果某个方法不依赖于任何数据类型,就直接调用(比如内置函数 和 自定义函数)
🍁八、writable和readable内置函数
这两个内置函数分别是判断文件是否是可写的和可读的
举个栗子:
f = open('内置函数和匿名函数.py')#首先打开了一个文件 print(f.writable()) print(f.readable()) f.close() 输出结果: False True
🍁九、id和hash内置函数
id() 函数返回对象的唯一标识符,标识符是一个整数。
Python 中 id() 函数用于获取对象的内存地址。
a = '在下周周ovo' print(id(a)) #得到a变量的内存地址 输出结果: 2381052638016hash() 用于获取取一个对象(字符串或者数值等)的哈希值。
能够执行hash函数而不报错的就是可哈希(不可变数据类型)的反之就是不可哈希(可变数据类型)的,
重点:对于可以相同的可hash的数据的hash值在程序没结束的过程中总是不会改变的
print(hash(1234)) print(hash('dscds')) 输出结果: 1234 3749030834196371593
🍁十、print内置函数的高阶使用方法
- 描述
print() 方法用于打印输出,最常见的一个函数。
在 Python3.3 版增加了 flush 关键字参数。
print 在 Python3.x 是一个函数,但在 Python2.x 版本不是一个函数,只是一个关键字。
- 语法
以下是 print() 方法的语法:
print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)
- 参数
- objects -- 复数,表示可以一次输出多个对象。输出多个对象时,需要用 , 分隔。
- sep -- 用来间隔多个对象,默认值是一个空格。
- end -- 用来设定以什么结尾。默认值是换行符 \n,我们可以换成其他字符串。
- file -- 要写入的文件对象。
- flush -- 输出是否被缓存通常决定于 file,但如果 flush 关键字参数为 True,流会被强制刷新。
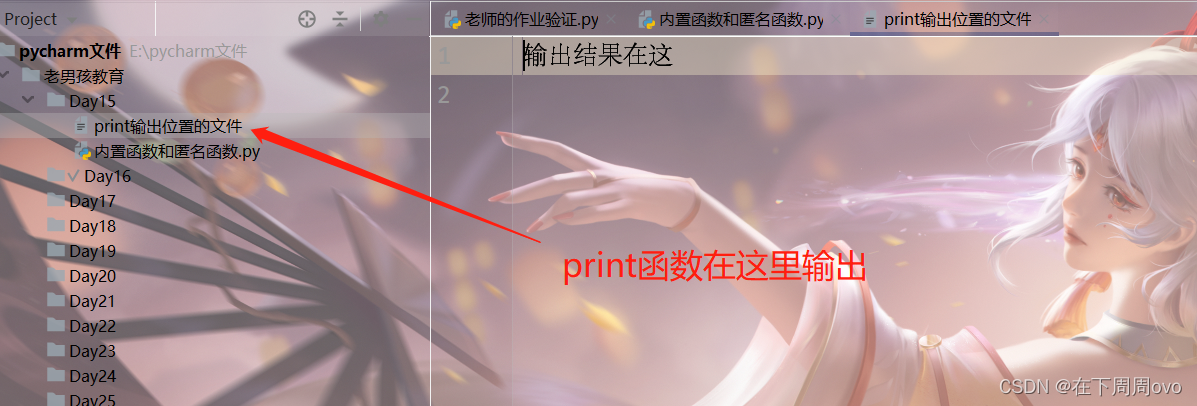
print('在下周周') print('在下周周',end='')#若未指定结尾,则print默认以\n(换行符)结尾 print('在下周周') print(1,2,3,4,5) print(1,2,3,4,5,sep='|')#指定以|为分隔符 f = open('print输出位置的文件','w',encoding='utf8') print('输出结果在这',file=f) #如果不指定默认是打印到屏幕 f.close()输出结果:


- 点赞
- 收藏
- 关注作者
评论(0)