【sklearn】2.分类决策树实践——Titanic数据集

【摘要】
在上一篇【sklearn】1.分类决策树学习了sklearn决策树的一些接口后,现在利用kaggle上泰坦尼克号的数据集进行实践。
数据集获取
在Kaggle上下载Tictanic数据集 下载地址:h...
在上一篇【sklearn】1.分类决策树学习了sklearn决策树的一些接口后,现在利用kaggle上泰坦尼克号的数据集进行实践。
数据集获取
在Kaggle上下载Tictanic数据集
下载地址:https://www.kaggle.com/c/titanic/data
数据集中有三个文件,一个是训练集,一个是测试集,还有一个是提交的答案范例。
本次仅使用训练集。
sklearn实战
导入库
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split, cross_val_score
import numpy as np
- 1
- 2
- 3
- 4
- 5
- 6
读取数据
data = pd.read_csv("titanic/train.csv")
# print(data.info()) # 查看大致信息
# print(data.head(5)) # 查看前5条数据
- 1
- 2
- 3
数据预处理
# 筛选特征
data.drop(['Cabin', 'Name', 'Ticket'], inplace=True, axis=1) # inplace覆盖原表,axis=1删除列,axis=0删除行
# 填补缺失值
data['Age'] = data['Age'].fillna(data['Age'].mean())
# 删掉含有缺失值的行
data = data.dropna() # 默认axis=0
# 将[Embarked]的文字部分替换成0,1,2(有三类)
labels = data["Embarked"].unique().tolist()
data["Embarked"] = data["Embarked"].apply(lambda x: labels.index(x))
# 性别转换将male和female转换成1和0
data["Sex"] = (data['Sex'] == 'male').astype('int') # 小技巧:通过条件判断强制转换为int
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
通过预处理,将不重要的特征进行删除,对年龄的缺失行以平均年龄进行填补,对文字数据集进行了数字转换。
样本选取
# 取出 x 和 y 因变量为Survived
x = data.iloc[:, data.columns != "Survived"]
y = data.iloc[:, data.columns == "Survived"]
Xtrain, Xtest, Ytrain, Ytest = train_test_split(x, y, test_size=0.3)
# 随机取出数据,索引会变化,下面重新纠正索引
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
决策树构建
# 使用决策分类树
clf = DecisionTreeClassifier(random_state=25)
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
print(score)
- 1
- 2
- 3
- 4
- 5
- 6
打印出准确率,发现只有76%,下面进行调参。
对最大深度调参
# 准确率只有76%,对最大深度调参
tr = []
te = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=25
, max_depth=i + 1
, criterion="entropy"
)
clf = clf.fit(Xtrain, Ytrain)
score_tr = clf.score(Xtrain, Ytrain)
score_te = cross_val_score(clf, x, y, cv=10).mean() # 交叉验证取均值作测试
tr.append(score_tr)
te.append(score_te)
print(max(te))
plt.plot(range(1, 11), tr, color="red", label="train")
plt.plot(range(1, 11), te, color="blue", label="test")
plt.xticks(range(1, 11)) # 限制x轴显示范围
plt.legend() # 显示图例
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
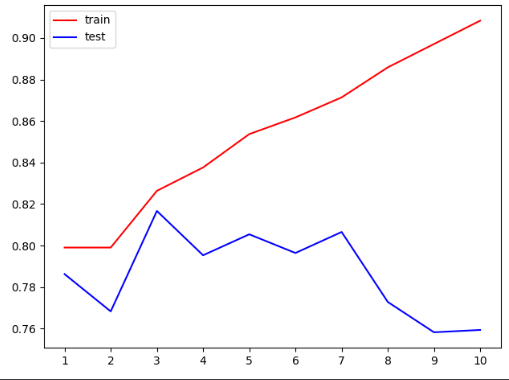
上面的图说明,最大深度很大时,用于交叉验证的test准确率低,train准确率高,产生过拟合现象。
为了减小过拟合,在图中可以发现,最大深度取3最合适。
网格调参
上面仅仅是对最大深度进行了调参,还有很多参数需要进行调节,一个个去调节显然是困难的。
因此,这里采用了一种网格调参的方法。
通俗理解,所有的参数枚举出来,形成了一个个网格,每个网格试过去,直到找到最好的。
# 最好的max的准确度也仅为81.6%,下面使用网格搜索调参
gini_thresholds = np.linspace(0, 0.5, 20) # 20个0到0.5的等差数列
# 设定参数范围
parameters = {"criterion": ("gini", "entropy")
, "splitter": ("best", "random")
, "max_depth": [*range(1, 10)]
, "min_samples_leaf": [*range(1, 50, 5)]
, "min_impurity_decrease": [*np.linspace(0, 0.5, 20)]
}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS = GS.fit(Xtrain, Ytrain)
#返回最佳组合
print(GS.best_params_)
#返回最佳准确率
print(GS.best_score_)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
注:网格调参非常耗时,这段代码跑了10分钟。
最佳组合:
{‘criterion’: ‘entropy’, ‘max_depth’: 3, ‘min_impurity_decrease’: 0.0, ‘min_samples_leaf’: 1, ‘splitter’: ‘best’}
最佳准确率:82.3%
总结
即使经过调参,准确率依旧提升不多,说明决策树对该数据集的效果并不理想。
若要准确进行预测,需要更换其它模型。
参考资料
文章来源: zstar.blog.csdn.net,作者:zstar-_,版权归原作者所有,如需转载,请联系作者。
原文链接:zstar.blog.csdn.net/article/details/120107898

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)