OpenCV基础IO与GUI

为程序界面添加滑动条
-
在以前的教程中 (例如 linear blending 和 brightness and contrast adjustments)你有可能注意到需要 input 一些数值到我们的程序中, 例如
 和 。我们会在代码中输入这些数据来配合程序的运行。
和 。我们会在代码中输入这些数据来配合程序的运行。 -
好, 下面来介绍所要用到的一个 GUI 中的工具. OpenCV 提供的 GUI 库在(highgui.h)里. 这是一个 滑动条 的样子
-
在这里教程指导我们修改以前的方案,以便从滑动条中获得那些需要输入数据.
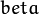 。我们会在代码中输入这些数据来配合程序的运行。
。我们会在代码中输入这些数据来配合程序的运行。
代码
首先来修改一下教程中 使用OpenCV对两幅图像求和(求混合(blending)) 这个例子. 用滑动条来动态输入 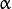 这个值.
这个值.
#include <cv.h>
#include <highgui.h>
using namespace cv;
/// 全局变量的声明与初始化
const int alpha_slider_max = 100;
int alpha_slider;
double alpha;
double beta;
/// 声明存储图像的变量
Mat src1;
Mat src2;
Mat dst;
/**
* @function on_trackbar
* @定义响应滑动条的回调函数
*/
void on_trackbar( int, void* )
{
alpha = (double) alpha_slider/alpha_slider_max ;
beta = ( 1.0 - alpha );
addWeighted( src1, alpha, src2, beta, 0.0, dst);
imshow( "Linear Blend", dst );
}
int main( int argc, char** argv )
{
/// 加载图像 (两图像的大小与类型要相同)
src1 = imread("../../images/LinuxLogo.jpg");
src2 = imread("../../images/WindowsLogo.jpg");
if( !src1.data ) { printf("Error loading src1 \n"); return -1; }
if( !src2.data ) { printf("Error loading src2 \n"); return -1; }
/// 初始化为零
alpha_slider = 0;
/// 创建窗体
namedWindow("Linear Blend", 1);
/// 在创建的窗体中创建一个滑动条控件
char TrackbarName[50];
sprintf( TrackbarName, "Alpha x %d", alpha_slider_max );
createTrackbar( TrackbarName, "Linear Blend", &alpha_slider, alpha_slider_max, on_trackbar );
/// 结果在回调函数中显示
on_trackbar( alpha_slider, 0 );
/// 按任意键退出
waitKey(0);
return 0;
}
程序说明
我们只分析关于滑动条的那段代码:
#.首先, 我们加载了两个图像, 目的是把它们混合显示.
src1 = imread("../../images/LinuxLogo.jpg"); src2 = imread("../../images/WindowsLogo.jpg");
#.在创建滑动条之前, 我们要先创建一个窗体,以便把创建的滑动条放置在上面:
namedWindow("Linear Blend", 1);
-
现在可以创建滑动条了:
createTrackbar( TrackbarName, "Linear Blend", &alpha_slider, alpha_slider_max, on_trackbar );记住下面的参数介绍:
- 在标签中显示的文字(提示滑动条的用途) TrackbarName
- 创建的滑动条要放置窗体的名字 “Linear Blend”
- 滑动条的取值范围从 到 alpha_slider_max (最小值只能为 zero).
- 滑动后的值存放在 alpha_slider 变量里
- 每当滑动条的值改变, 就会调用 on_trackbar 回调函数
-
最后, 我们还要定义这个回调函数 on_trackbar 来实现我们想要的结果
void on_trackbar( int, void* ) { alpha = (double) alpha_slider/alpha_slider_max ; beta = ( 1.0 - alpha ); addWeighted( src1, alpha, src2, beta, 0.0, dst); imshow( "Linear Blend", dst ); }注意回调函数中的整型与双精度型的转换:
- 从滑动条中获取的整型值 alpha_slider (integer) 要转换为双精度类型 alpha.
- alpha_slider 的值会在滑动条滑动后被修改.
- 我们所定义的 src1, src2, dist, alpha, alpha_slider 和 beta 都是全局变量, 因此也可以在回调函数中使用.
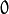 到 alpha_slider_max (最小值只能为 zero).
到 alpha_slider_max (最小值只能为 zero).结果
-
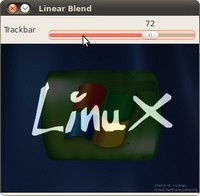
下图是程序的运行结果:
-
也可以使用其它方式验证, 你可以用 改变图像的对比度和亮度 中的例程实现两个滑动条. 一个控制
另一个控制 . 可能的输出会是下面的样子:
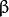 . 可能的输出会是下面的样子:
. 可能的输出会是下面的样子: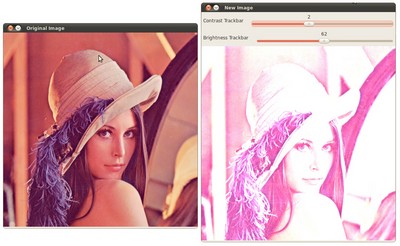
OpenCV的视频输入和相似度测量
目标
现在找一个能拍摄视频的设备真是太容易了。结果大家都用视频来代替以前的序列图像。视频可能由两种形式得到,一个是像网络摄像头那样实时视频流,或者由其他设备产生的压缩编码后的视频文件。幸运的是,OpenCV可以使用相同的C++类、用同一种方式处理这些视频信息。在接下来的教程里你将学习如何使用摄像头或者视频文件。
- 如何打开和读取视频流
- 两种检查相似度的方法:PSNR和SSIM
源代码
就和其他的OpenCV小例子一样,在这里我也创建了一个小程序来读取两个视频文件然后比较它们的相似度。你可以用这个功能来验证视频压缩后的损失程度,这里有一个 参考视频(原始视频) 和 压缩后的视频. 你可以在OpenCV的示例文件夹samples/cpp/tutorial_code/HighGUI/video-input-psnr-ssim/ 下找到源码和示例视频。
|
|
如何读取一个视频流(摄像头或者视频文件)?
总的来说,视频捕获需要的所有函数都集成在 VideoCapture C++ 类里面。虽然它底层依赖另一个FFmpeg开源库,但是它已经被集成在OpenCV里所以你不需要额外地关注它的具体实现方法。你只需要知道一个视频由一系列图像构成,我们用一个专业点儿的词汇来称呼这些构成视频的图像:“帧”(frame)。此外在视频文件里还有个参数叫做“帧率”(frame rate)的,用来表示两帧之间的间隔时间,帧率的单位是(帧/秒)。这个参数只和视频的播放速度有关,对于单独的一帧图像来说没有任何用途。
你需要先定义一个 VideoCapture 类的对象来打开和读取视频流。具体可以通过 constructor 或者通过 open 函数来完成。如果使用整型数当参数的话,就可以将这个对象绑定到一个摄像机,将系统指派的ID号当作参数传入即可。例如你可以传入0来打开第一个摄像机,传入1打开第二个摄像机,以此类推。如果使用字符串当参数,就会打开一个由这个字符串(文件名)指定的视频文件。例如在上面的例子里传入如下参数:
video/Megamind.avi video/Megamind_bug.avi 35 10
前两个参数传入了两个文件名,分别代表原始参考视频和测试视频。这里使用了相对地址,这也代表着系统会从软件的工作目录下的video子目录里寻找文件。然后程序将针对这些参数开始进行相似性检查
const string sourceReference = argv[1],sourceCompareWith = argv[2];
VideoCapture captRefrnc(sourceReference);
// 或者
VideoCapture captUndTst;
captUndTst.open(sourceCompareWith);
你可以用 isOpened 函数来检查视频是否成功打开与否:
if ( !captRefrnc.isOpened())
{
cout << "Could not open reference " << sourceReference << endl;
return -1;
}
当析构函数调用时,会自动关闭视频。如果你希望提前关闭的话,你可以调用 release 函数. 视频的每一帧都是一幅普通的图像。因为我们仅仅需要从 VideoCapture 对象里释放出每一帧图像并保存成 Mat 格式。因为视频流是连续的,所以你需要在每次调用read 函数后及时保存图像或者直接使用重载的>>操作符。
Mat frameReference, frameUnderTest;
captRefrnc >> frameReference;
captUndTst.open(frameUnderTest);
如果视频帧无法捕获(例如当视频关闭或者完结的时候),上面的操作就会返回一个空的 Mat 对象。我们可以用下面的代码检查是否返回了空的图像:
if( frameReference.empty() || frameUnderTest.empty())
{
// 退出程序
}
读取视频帧的时候也会自动进行解码操作。你可以通过调用 grab 和 retrieve 函数来显示地进行这两项操作。
视频通常拥有很多除了视频帧图像以外的信息,像是帧数之类,有些时候数据较短,有些时候用4个字节的字符串来表示。所以 get函数返回一个double(8个字节)类型的数据来表示这些属性。然后你可以使用位操作符来操作这个返回值从而得到想要的整型数据等。这个函数有一个参数,代表着试图查询的属性ID。在下面的例子里我们会先获得食品的尺寸和帧数。
Size refS = Size((int) captRefrnc.get(CV_CAP_PROP_FRAME_WIDTH),
(int) captRefrnc.get(CV_CAP_PROP_FRAME_HEIGHT)),
cout << "参考帧的分辨率: 宽度=" << refS.width << " 高度=" << refS.height
<< " of nr#: " <<
<< endl;
当你需要设置这些值的时候你可以调用 set 函数。函数的第一个参数是需要设置的属性ID,第二个参数是需要设定的值,如果返回true的话就表示成功设定,否则就是false。接下来的这个例子很好地展示了如何设置视频的时间位置或者帧数:
captRefrnc.set(CV_CAP_PROP_POS_MSEC, 1.2); // 跳转到视频1.2秒的位置
captRefrnc.set(CV_CAP_PROP_POS_FRAMES, 10); // 跳转到视频的第10帧
// 然后重新调用read来得到你刚刚设置的那一帧
图像比较 - PSNR and SSIM
当我们想检查压缩视频带来的细微差异的时候,就需要构建一个能够逐帧比较差视频差异的系统。最常用的比较算法是PSNR( Peak signal-to-noise ratio)。这是个使用“局部均值误差”来判断差异的最简单的方法,假设有这两幅图像:I1和I2,它们的行列数分别是i,j,有c个通道。
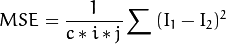
PSNR公式如下:
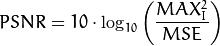
每个像素的每个通道的值占用一个字节,值域[0,255]。这里每个像素会有 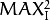 个有效的最大值 注意当两幅图像的相同的话,MSE的值会变成0。这样会导致PSNR的公式会除以0而变得没有意义。所以我们需要单独的处理这样的特殊情况。此外由于像素的动态范围很广,在处理时会使用对数变换来缩小范围。这些变换的C++代码如下:
个有效的最大值 注意当两幅图像的相同的话,MSE的值会变成0。这样会导致PSNR的公式会除以0而变得没有意义。所以我们需要单独的处理这样的特殊情况。此外由于像素的动态范围很广,在处理时会使用对数变换来缩小范围。这些变换的C++代码如下:
double getPSNR(const Mat& I1, const Mat& I2)
{
Mat s1;
absdiff(I1, I2, s1); // |I1 - I2|
s1.convertTo(s1, CV_32F); // 不能在8位矩阵上做平方运算
s1 = s1.mul(s1); // |I1 - I2|^2
Scalar s = sum(s1); // 叠加每个通道的元素
double sse = s.val[0] + s.val[1] + s.val[2]; // 叠加所有通道
if( sse <= 1e-10) // 如果值太小就直接等于0
return 0;
else
{
double mse =sse /(double)(I1.channels() * I1.total());
double psnr = 10.0*log10((255*255)/mse);
return psnr;
}
}
在考察压缩后的视频时,这个值大约在30到50之间,数字越大则表明压缩质量越好。如果图像差异很明显,就可能会得到15甚至更低的值。PSNR算法简单,检查的速度也很快。但是其呈现的差异值有时候和人的主观感受不成比例。所以有另外一种称作 结构相似性的算法做出了这方面的改进。
建议你阅读一些关于SSIM算法的文献来更好的理解算法,然而及时你直接看下面的源代码,应该也能建立一个不错的映像。
See also
请参考下面深度解析SSIM的文章:”Z. Wang, A. C. Bovik, H. R. Sheikh and E. P. Simoncelli, “Image quality assessment: From error visibility to structural similarity,” IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600-612, Apr. 2004.”
Scalar getMSSIM( const Mat& i1, const Mat& i2)
{
const double C1 = 6.5025, C2 = 58.5225;
/***************************** INITS **********************************/
int d = CV_32F;
Mat I1, I2;
i1.convertTo(I1, d); // 不能在单字节像素上进行计算,范围不够。
i2.convertTo(I2, d);
Mat I2_2 = I2.mul(I2); // I2^2
Mat I1_2 = I1.mul(I1); // I1^2
Mat I1_I2 = I1.mul(I2); // I1 * I2
/***********************初步计算 ******************************/
Mat mu1, mu2; //
GaussianBlur(I1, mu1, Size(11, 11), 1.5);
GaussianBlur(I2, mu2, Size(11, 11), 1.5);
Mat mu1_2 = mu1.mul(mu1);
Mat mu2_2 = mu2.mul(mu2);
Mat mu1_mu2 = mu1.mul(mu2);
Mat sigma1_2, sigma2_2, sigma12;
GaussianBlur(I1_2, sigma1_2, Size(11, 11), 1.5);
sigma1_2 -= mu1_2;
GaussianBlur(I2_2, sigma2_2, Size(11, 11), 1.5);
sigma2_2 -= mu2_2;
GaussianBlur(I1_I2, sigma12, Size(11, 11), 1.5);
sigma12 -= mu1_mu2;
/ 公式
Mat t1, t2, t3;
t1 = 2 * mu1_mu2 + C1;
t2 = 2 * sigma12 + C2;
t3 = t1.mul(t2); // t3 = ((2*mu1_mu2 + C1).*(2*sigma12 + C2))
t1 = mu1_2 + mu2_2 + C1;
t2 = sigma1_2 + sigma2_2 + C2;
t1 = t1.mul(t2); // t1 =((mu1_2 + mu2_2 + C1).*(sigma1_2 + sigma2_2 + C2))
Mat ssim_map;
divide(t3, t1, ssim_map); // ssim_map = t3./t1;
Scalar mssim = mean( ssim_map ); // mssim = ssim_map的平均值
return mssim;
}
这个操作会针对图像的每个通道返回一个相似度,取值范围应该在0到1之间,取值为1时代表完全符合。然而尽管SSIM能产生更优秀的数据,但是由于高斯模糊很花时间,所以在一个实时系统(每秒24帧)中,人们还是更多地采用PSNR算法。
正是这个原因,最开始的源码里,我们用PSNR算法去计算每一帧图像,而仅当PSNR算法计算出的结果低于输入值的时候,用SSIM算法去验证。为了展示数据,我们在例程里用两个窗口显示了原图像和测试图像并且在控制台上输出了PSNR和SSIM数据。就像下面显示的那样:
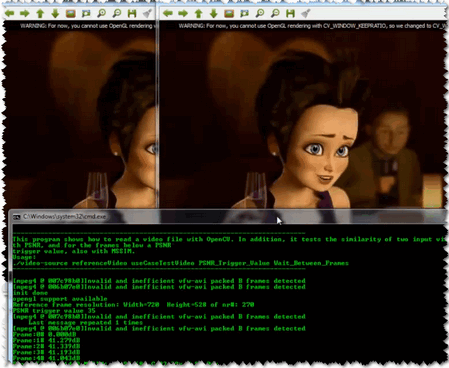
如果你会翻墙,就可以在天朝河蟹掉的 YouTube 上观看操作视频.
用OpenCV创建视频
目标
你可能已经不满足于读取视频,还想要将你产生的一系列结果保存到一个新建的视频文件中。使用OpenCV中的 VideoWriter 类就可以简单的完成创建视频的工作。在接下来的教程中,我们将告诉你:
- 如何用OpenCV创建一个视频文件
- 用OpenCV能创建什么样的视频文件
- 如何释放视频文件当中的某个颜色通道
为了使例子简单,我就仅仅释放原始视频RGB通道中的一个,并把它放入新视频文件中。你可以使用命令行参数来控制程序的一些行为:
- 第一个参数指向你需要操作的视频文件。
- 第二个参数可以是如下的几个字母之一:R G B。用来指定你需要释放哪一个通道。
- 最后一个参数是Y(Yes)或者N(No). 如果你选择N, 就直接使用视频输入格式来创建输出文件,否则就会弹出一个对话框来让你选择编码器。
举例来说,可以使用下面这样子的命令行:
video-write.exe video/Megamind.avi R Y
源代码
你可以在 samples/cpp/tutorial_code/highgui/video-write/ 文件夹中找到源代码和视频文件。或者从 download it from here这里下载源代码。
|
|
视频文件的结构
首先,你需要知道一个视频文件是什么样子的。每一个视频文件本质上都是一个容器,文件的扩展名只是表示容器格式(例如 avi, mov ,或者 mkv )而不是视频和音频的压缩格式。容器里可能会有很多元素,例如视频流,音频流和一些字幕流等等。这些流的储存方式是由每一个流对应的编解码器(codec)决定的。通常来说,视频流很可能使用 mp3 或 aac 格式来储存。而视频格式就更多些,通常是 XVID , DIVX , H264 或 LAGS (Lagarith Lossless Codec)等等。具体你能够使用的编码器种类可以在操作系统的编解码器列表里找到。

如你所见,视频文件确实比图像文件要复杂很多。然而OpenCV只是个计算机视觉库而不是一个视频处理编码库。所以开发者们试图将这个部分尽可能地精简,结果就是OpenCV能够处理的视频只剩下 avi 扩展名的了。另外一个限制就是你不能创建超过2GB的单个视频,还有就是每个文件里只能支持一个视频流,不能将音频流和字幕流等其他数据放在里面。尽管如此,任何系统支持的编解码器在这里应该都能工作。如果这些视频处理能力不够你使用的话,我想你应该去找一些专门处理视频的库例如 FFMpeg 或者更多的编解码器例如 HuffYUV , CorePNG 和 LCL 。你可以先用OpenCV创建一个原始的视频流然后通过其他编解码器转换成其他格式并用VirtualDub 和 AviSynth 这样的软件去创建各种格式的视频文件
VideoWriter 类
在看下面的内容之前,你需要先阅读教程: OpenCV的视频输入和相似度测量 并且确保你知道如何读取视频文件。
要创建一个视频文件,你需要创建一个 VideoWriter 类的对象。可以通过构造函数里的参数或者在其他合适时机使用 open 函数来打开,两者的参数都是一样的:
-
输出的文件名中包含了容器的类型,当然在现在仅仅支持 avi 格式。在这个例子中我们会使用输入文件名+通道名+avi来创建输出文件名。
const string source = argv[1]; // 原视频文件名 string::size_type pAt = source.find_last_of('.'); // 找到扩展名的位置 const string NAME = source.substr(0, pAt) + argv[2][0] + ".avi"; // 创建新的视频文件名 -
然后决定使用的编解码器,现在所有的视频编解码器都使用最多四个字节的名称来标识,例如 XVID, DIVX, 和 H264 等。这个被称作FourCC(four character code)。你可以通过 get 函数来向视频询问这个编码, get 函数会返回一个double数,仅仅是因为double包含了64位数据而已,由于FourCC编码只占据了其中低位的4个字节,所以可以直接通过强制转换成int型来扔掉高位的四个字节。
VideoCapture inputVideo(source); // 打开视频输入 int ex = static_cast<int>(inputVideo.get(CV_CAP_PROP_FOURCC)); // 得到编码器的int表达式OpenCV内部使用这个int数来当作第二个参数,这里会使用两种方法来将这个整型数转换为字符串:位操作符和联合体。前者可以用&操作符并进行移位操作,以便从int里面释放出字符:
char EXT[] = {ex & 0XFF , (ex & 0XFF00) >> 8,(ex & 0XFF0000) >> 16,(ex & 0XFF000000) >> 24, 0};
也可以使用 联合体 来做到:
union { int v; char c[5];} uEx ; uEx.v = ex; // 通过联合体来分解字符串 uEx.c[4]='\0'; 反过来,当你需要修改视频的格式时,你都需要修改FourCC码,而更改ForCC的时候都要做逆转换来指定新类型。如果你已经知道这个FourCC编码的具体字符的话,可以直接使用 *CV_FOURCC* 宏来构建这个int数:如果传入的参数是一个负数的话,就会在执行时弹出一个对话框,在里面包括了所有已安装的编码器类型,你可以在里面选择一个并使用之。
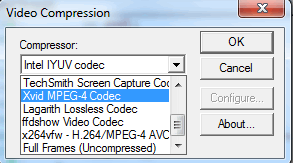
- 输出视频的帧率,也就是每秒需要绘制的图像数,在这里我让输出视频的帧率与输入视频相同,输入视频的帧率可以由 get 函数来获得。
- 输出视频的尺寸,在这里我同样保持和输入视频一样的大小,这个大小同样也可以由 get 函数来获得。
- 最后一个参数是一个可选参数。默认下它是true,来表示输出的视频是彩色的(所以你需要传给它三通道的图像),如果想创建一个灰度视频就传入false。
具体实现请看下面的例子:
VideoWriter outputVideo;
Size S = Size((int) inputVideo.get(CV_CAP_PROP_FRAME_WIDTH), //获取输入尺寸
(int) inputVideo.get(CV_CAP_PROP_FRAME_HEIGHT));
outputVideo.open(NAME , ex, inputVideo.get(CV_CAP_PROP_FPS),S, true);
然后,最好使用 isOpened() 函数来检查是不是成功打开。在成功打开时视频后,就可以用 write 函数向这个对象按照序列发送一些图像帧了,另外使用重载操作符 << 也可以完成这些操作。最后,视频会在 VideoWriter 对象析构时自动关闭。
outputVideo.write(res); //或者
outputVideo << res;
要“释放”出某个通道,又要保持视频为彩色,实际上也就意味着要把未选择的通道都设置为全0。这个操作既可以通过手工扫描整幅图像来完成,又可以通过分离通道然后再合并来做到,具体操作时先分离三通道图像为三个不同的单通道图像,然后再将选定的通道与另外两张大小和类型都相同的黑色图像合并起来。
split(src, spl); // 分离三个通道
for( int i =0; i < 3; ++i)
if (i != channel)
spl[i] = Mat::zeros(S, spl[0].type()); //创建相同大小的黑色图像
merge(spl, res); //重新合并
上面的代码完成了这个过程,最终运行结果就像下面所显示的那样。

当然如果你会翻墙的话,又可以在“不存在”的`YouTube <https://www.youtube.com/watch?v=jpBwHxsl1_0>`_ 上观看到动态视频。

- 点赞
- 收藏
- 关注作者
评论(0)