数据库日增 20 万条数据,用读写分离和分库分表加持破它

【摘要】 数据库日增 20 万条数据,用读写分离和分库分表加持破它

🍁 作者:知识浅谈,CSDN签约讲师,CSDN博客专家,华为云云享专家,阿里云星级博主
📌 擅长领域:全栈工程师、爬虫、ACM算法
💒 公众号:知识浅谈
🔥 联系方式vx:zsqtcc
⛳前言:Mysql尽量控制到千万级别,阿里的推荐是达到500万数据可进行分库分表,依据就是如果数据库种数据的增加会导致索引不能一次加载到内存中,IO次数增加降低查询效率。
🤞数据库日增20万条数据,用读写分离和分库分表解决🤞
兼容性最好,适合大多数MySQL库,与半同步复制(AP)可以保障至少有一个从库和主库是一致的。非官方方案,需要额外部署控制节点,部署确实比较麻烦。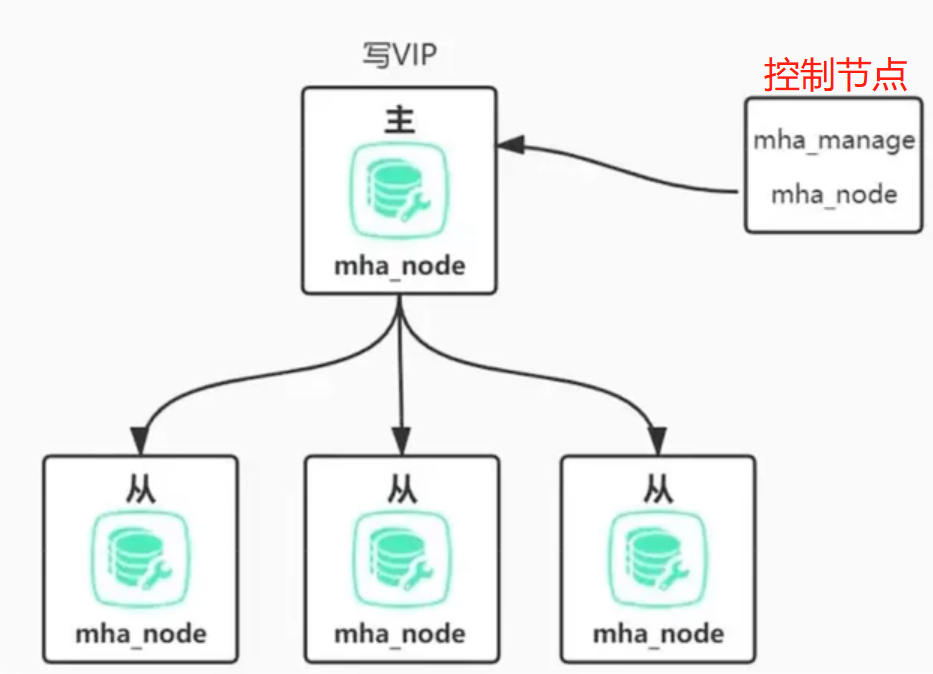
MySQL5.7以后才支持,全同步复制(CP),每个节点状态一致,自带故障转移,部署简单,对Binlog要求较多,最多支持9个节点集群,执行效率略差。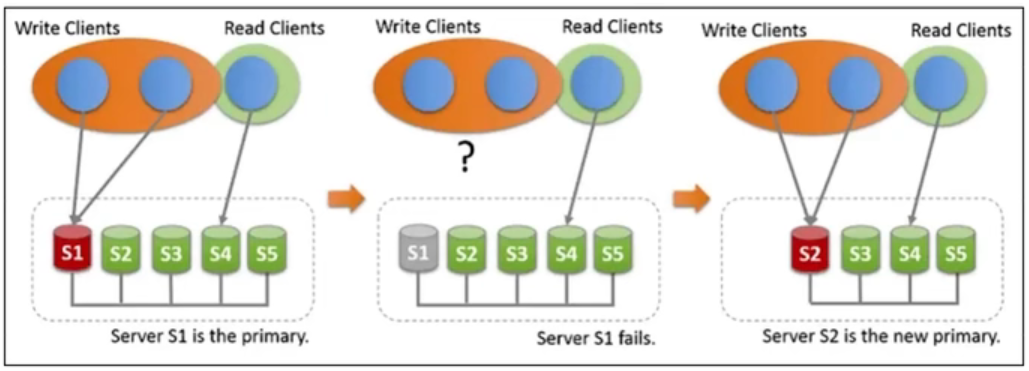
因为每天数据量增加为20万,则每个月增加到600万,所以为了使用的效率,按照每年建立一个数据库,每个月创建一个表,同时每年增加三个MGR节点保证高可用和故障转移。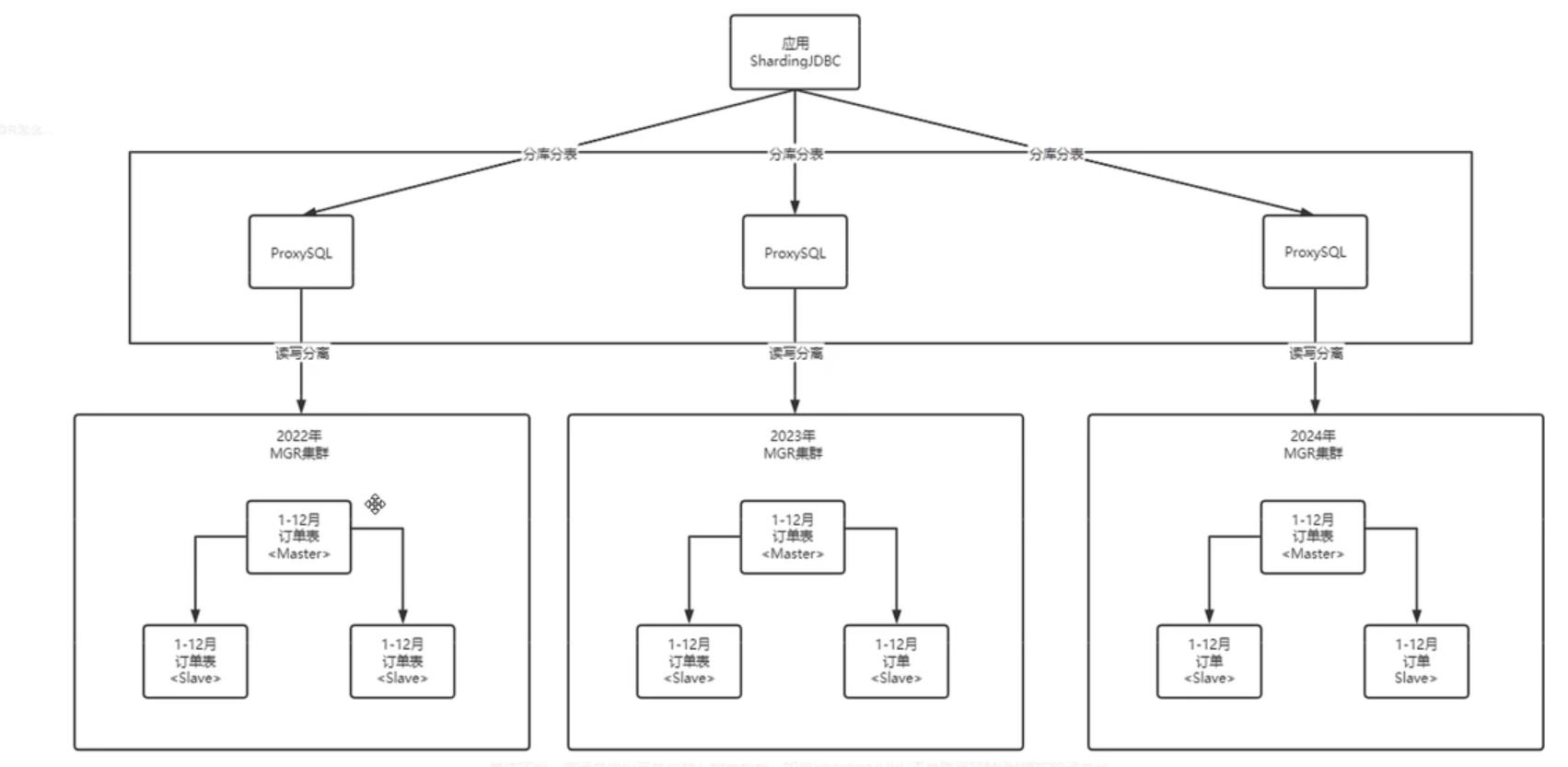
解析过程:从下往上
📐第 1 步: 创建主从节点
每一年增加的三个MGR节点,一个作为主节点,其他两个作为从节点,保证出现故障能够及时转移。
📐第 2 步:ProxySQL集群
ProxySQL主要是作为读写分离,对于主从表的结构进行主从结构。
📐第 3 步:ShardingJDBC
ShardingJDBC主要用于分库分表的功能。
数据库日增20万条数据,用读写分离和分库分表加持破它。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)