【NLP】自然语言处理学习笔记(二)语音转换

前言
本笔记参考的课程是李宏毅老师的自然语言处理
课程Link:https://aistudio.baidu.com/aistudio/education/lessonvideo/1000466
Voice Conversion
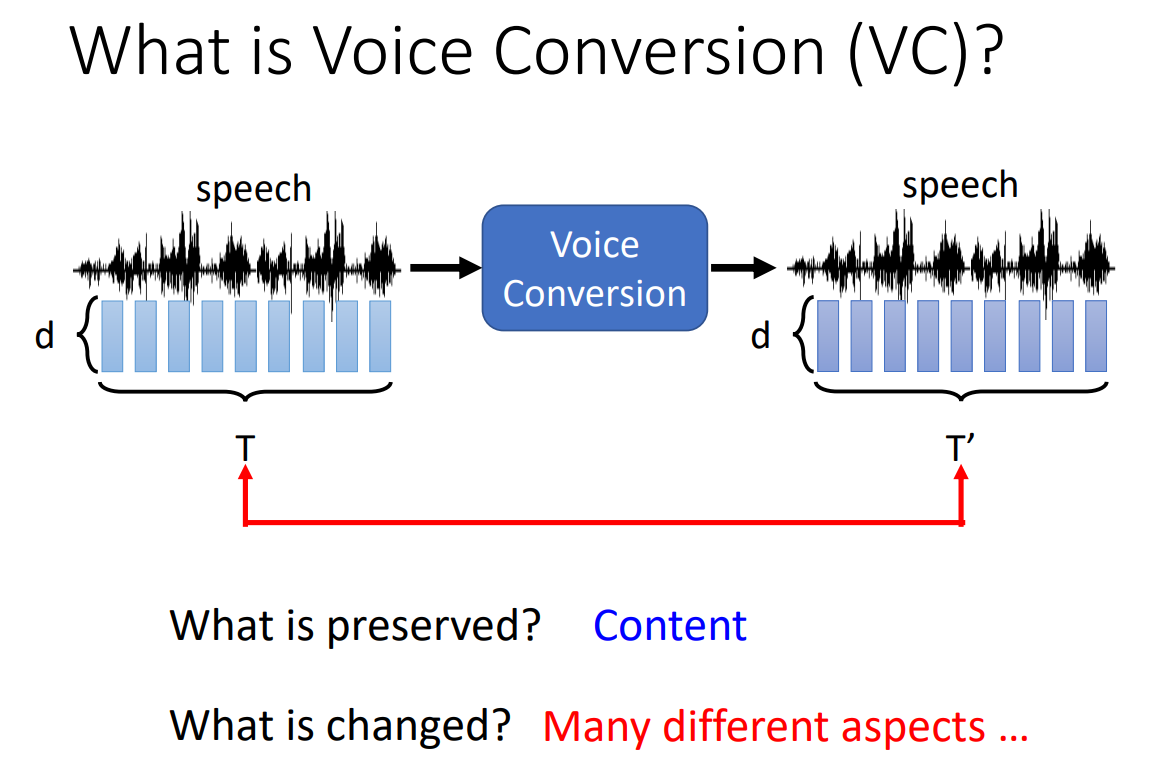
什么是语音转换?
语音转换就是将一段语音转换成另一段语音,内容保持不变。
比如,最常见的应用是变声器。此外,也可以实现语音降噪,语音加噪等其它应用场景。
Categories
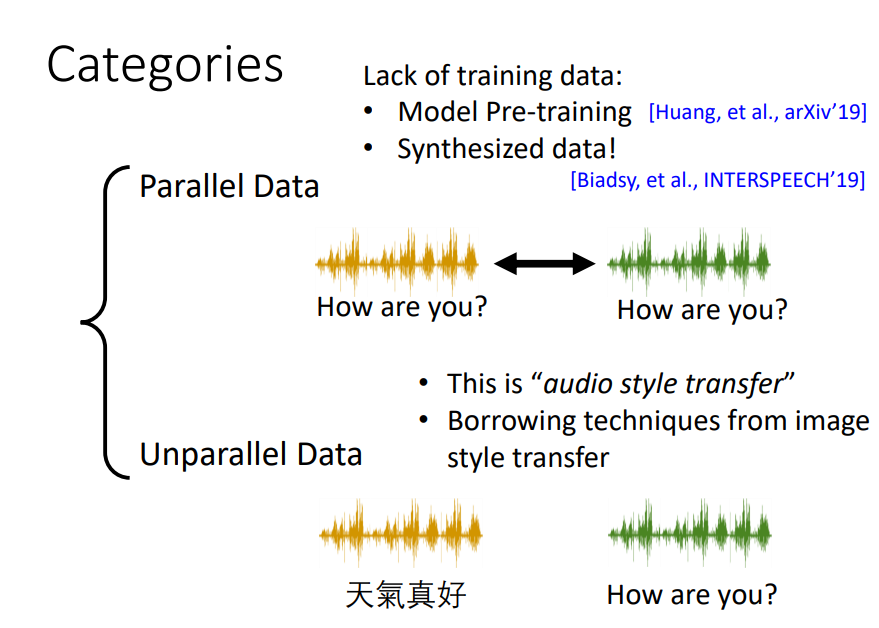
语音数据可分为两个种类:Parallel Data和Unparallel Data
Parallel Data即一对对的数据集,两段相同内容的语音由不同音源来发出。
Unparallel Data即不同内容的语音。
Parallel Data比较难获取到足够的数据,因此,后续模型采用的均是Unparallel Data。
Methods
语音转换的主要方法分两大类:Feature Disentangle 和 Direct Transformation
Feature Disentangle
Feature Disentangle,顾名思义是将特征进行提取分离。
例如,下图中,将两段语音分别提取内容信息和说话人的特征信息,将提取出的信息进行结合,就达到了替换声音的说出相同内容的效果。
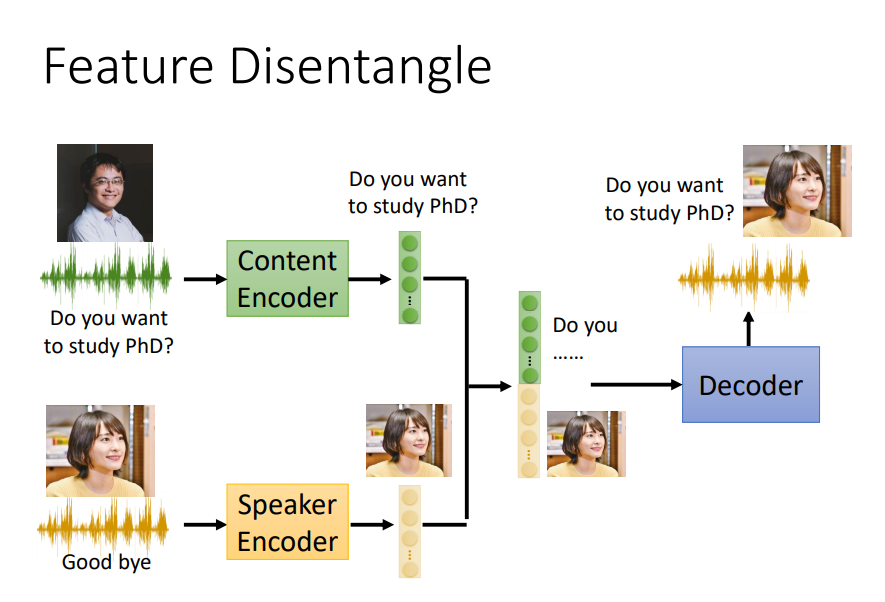
想法很美好,但是要提取得非常干净是比较困难的。
那么,下面就要训练两个编码器,因为是非对称的信息,没有GroundTruth无法训练,因此就直接用一段语音进行训练。
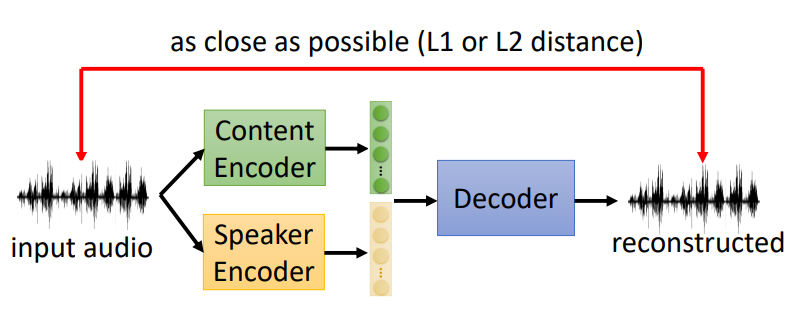
图中,输入一段语音,经过Encoder和Decoder之后,将重塑的语音和之前的语音比较,越接近越好,这样就能训练。然而,存在的一个问题是,怎么保证Content Encoder和Speaker Encoder能够提取出对应的内容呢,因为像这样两个Encoder的地位是一样的,提取的特征肯定会出现混杂。
有一种解决方式是不用Speaker Encoder,输入对应说话人的独热向量。
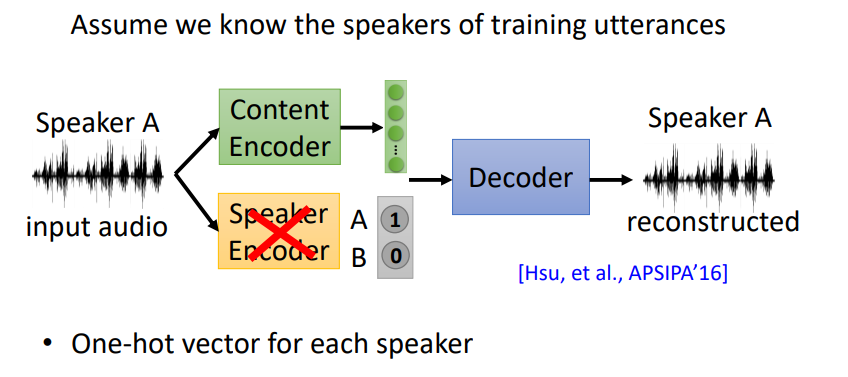
这种方法必须提前知道所有语音库中有多少个说话人,并且每一段输入的语音必须单独只有一个说话人。因此,仍然有局限性。
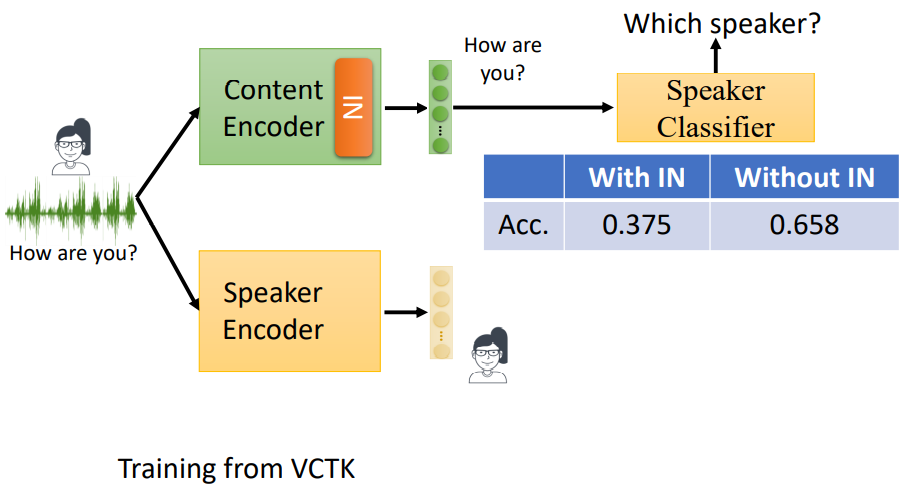
另一种解决方式是保持Speaker Encoder不变,在Content Encoder后面加上一个Speaker Classifier作为鉴别器(Discriminator)。在训练Content Encoder的过程中,同时训练Speaker Classifer,形成对抗结构。如果Content Encoder的效果好,那么Speaker Classifer的效果就越差。利用Speaker Classifer的效果来反推Content Encoder的效果,因此目标是Speaker Classifer的准确率越低越好。
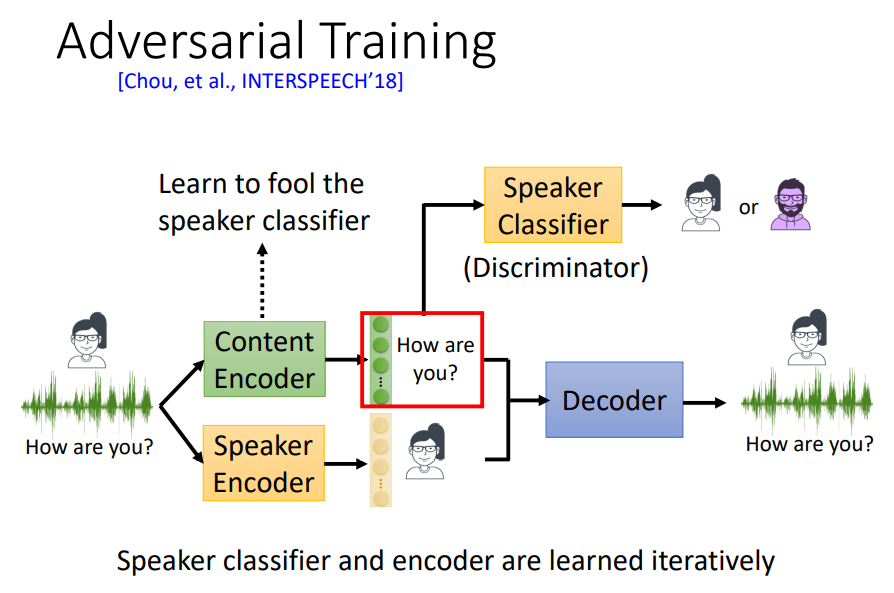
在这个思路的基础上,还能做进一步改进,在Content Encoder后面加一层instance normalization,如下图所示:
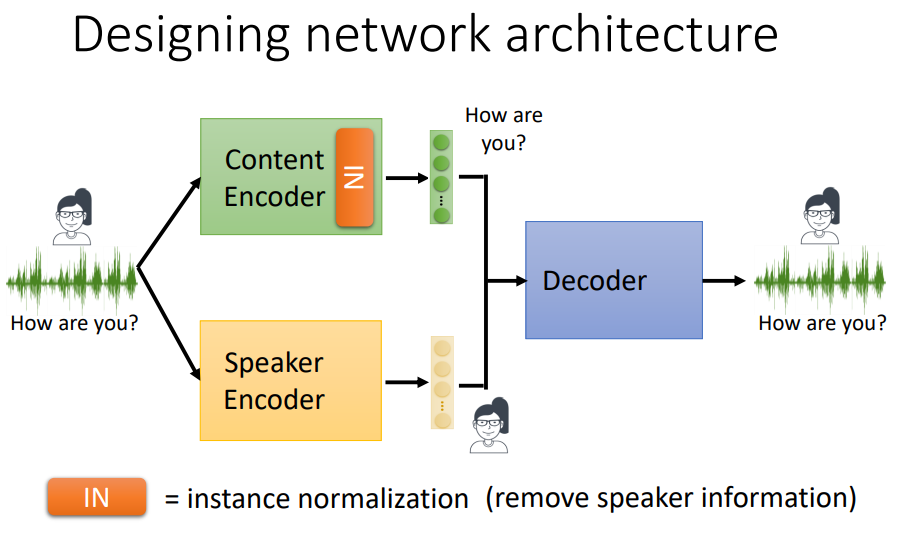
IN的作用就类似于图像领域的BN层,下图中,对于一段语音信号,使用一维卷积进行特征提取,经过IN后,将每个Filter提取出信息减去均值并除以方差,这样就将每个channel标准化,均值为0,方差为1。
为什么这样做可以过滤说话人的特征信息呢?举个例子,比如男生的声音普遍是低频信号,女生的声音普遍是高频信号,这样标准化之后,就将两者放在同一个范围内,有效滤除了说话者的声音特征。
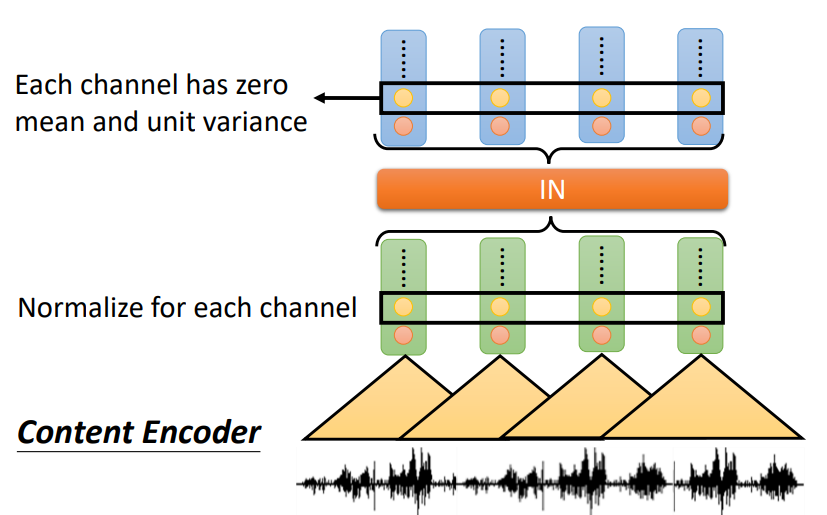
利用Content Encoder的分类器,可以来判断这样操作是否有效,如图所示,有IN层的准确率为37.5%,没有IN层的准确率为65.8%,前面说过,这个准确率要越小,代表Content Encoder越有效。数据说明,加入IN层是work的。
当然,还能进一步优化,比如,在Decoder后面加一层AdaIN。
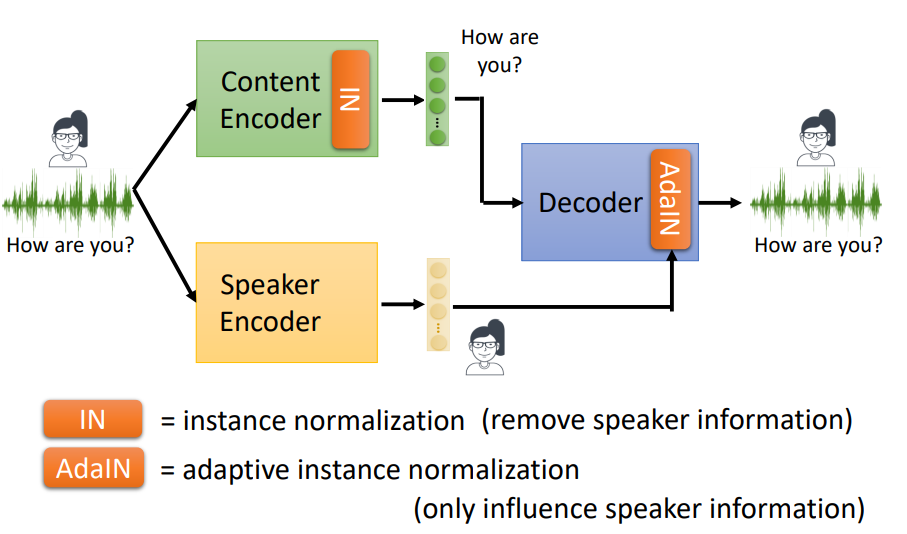
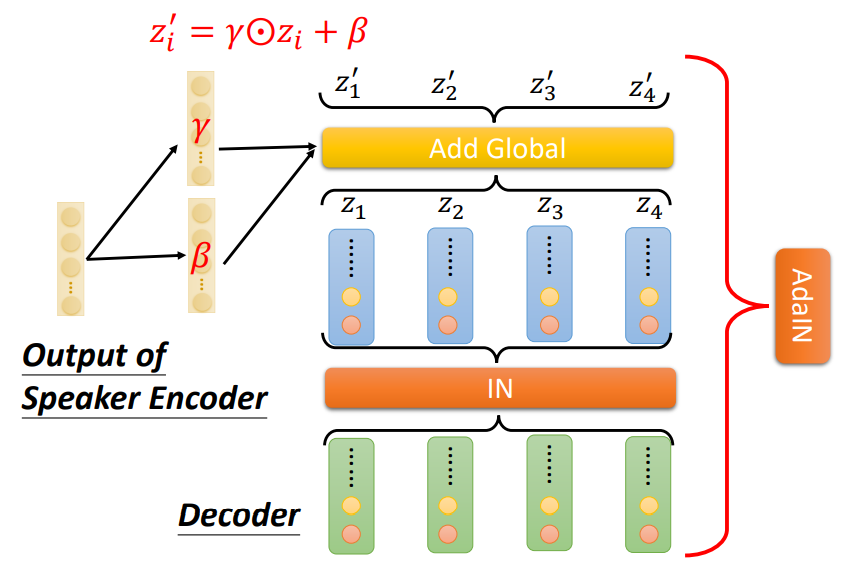
AdaIN的步骤是先将Decoder出来的结果标准化(IN),然后再将Speaker Encoder的结果用下图中的公式进行添加。
这样操作的原因也不难理解,因为直接将两个Encoder的结果混杂输出,效果不一定好,这样处理能够优化输出的结果。
这套方法在训练阶段似乎是可行的,但在测试时,会产生一个新的问题。
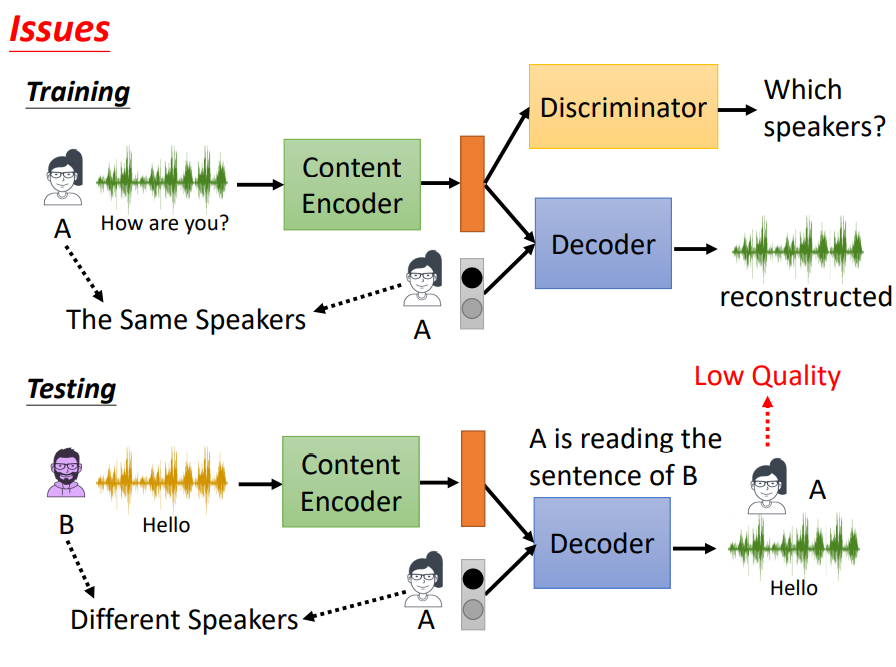
如图所示,训练时两个Encoder是采用的相同的说话人或者是同一段音频,但是在测试时,我们需要的目的是用A的语音来替换B的内容,这和训练时的场景并不一致,从而会出现导致结果不好(Low Quality)
于是,为解决这一问题,就有了2nd Stage Training方法。
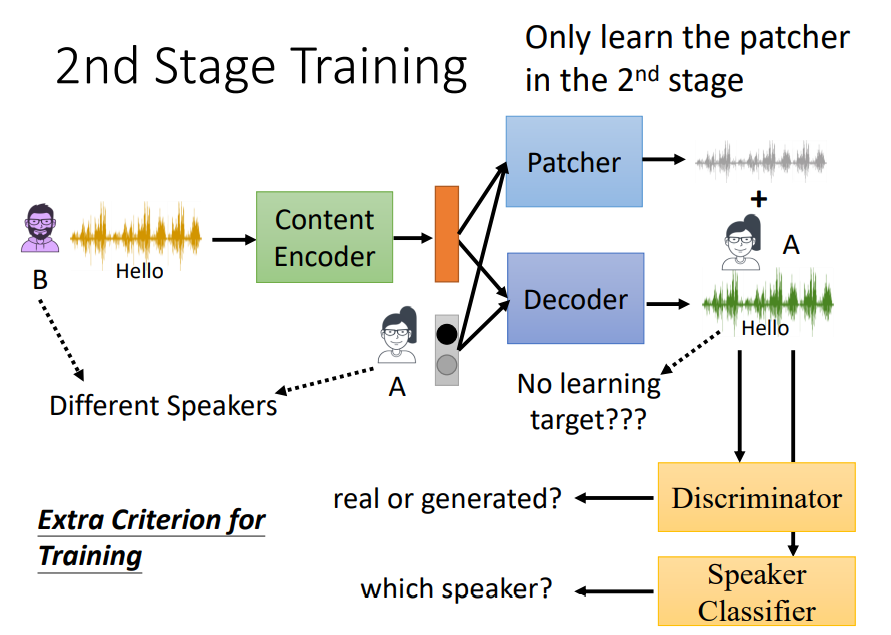
2nd Stage Training是保持训练场景和测试场景一致,即Content Encoder和Speaker Encoder是不同的说话人(下图中Speaker Encoder简化成了独热码)。然而,前面也提到过,这样做的话Decoder出来的结果是没有Groundtruth的,无法直接进行监督训练。
那么,2nd Stage Training的办法是在Decoder后面添加一个判别器(Discriminator)和一个分类器(Speaker Classifier),判别器用来判断输出的语音是否像真人,分类器用来判断输出语音属于哪个说话人。但是这样仍然容易造成模型输出不稳定的情况,因此给Decoder打上一个补丁(Patcher),Patcher输入输出和Decoder一样,这样将两者的输出加在一起,可以增强模型的稳定性。
Direct Transformation
除了分离特征的方法外,还有一种思路是借鉴图像领域的生成对抗网络(Gan),从而直接进行转换。
Cycle GAN
Cycle GAN的结构如下图所示:
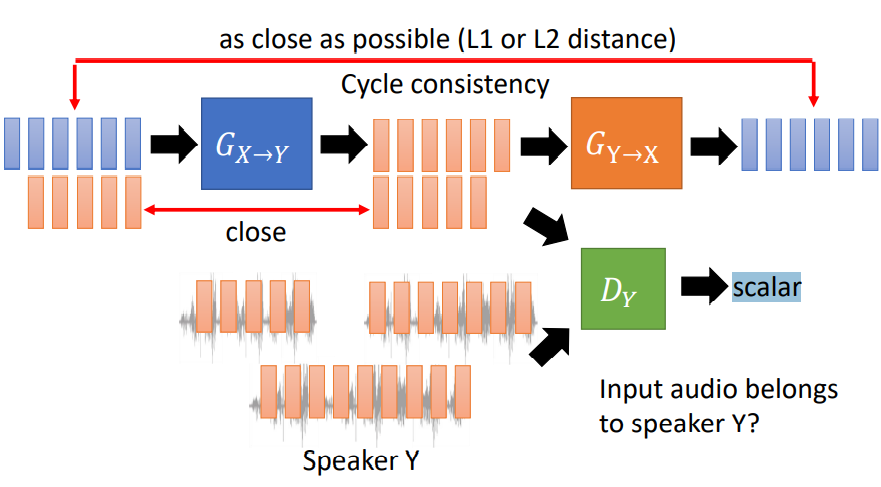
图中蓝色代表说话人X的语音信号,红色代表说话人Y的语音信号。
首先输入X到判生成器Gx->y中,生成器会将X的信号转换成Y,然后将该信号和真实的Y信号来一起输入到判别器Dy中,让其分辨输入的语音是否真正属于Y,假如判别器无法正确判别,说明生成器的效果不错,能够“骗过”判别器。
值得注意的是,在生成器Gx->y后又加了一个生成器Gy->x,重新将信号还原成X,再比较输入输出X的接近程度。这样做的目的是确保生成器Gx->y是正常工作的。如果没有这个步骤,可能生成器Gx->y会“偷懒”,一直生成同一个Y语音,这不是我们想要的。
其次,Gx->y下面还有一对信号,输入Y,之后再输出Y,然后比较两者的接近程度,正常情况下,不应该发生变化,这样做是为了模型训练的稳定性。
Cycle GAN中的X和Y是对称的,也就是说,将其互换,也可以work。
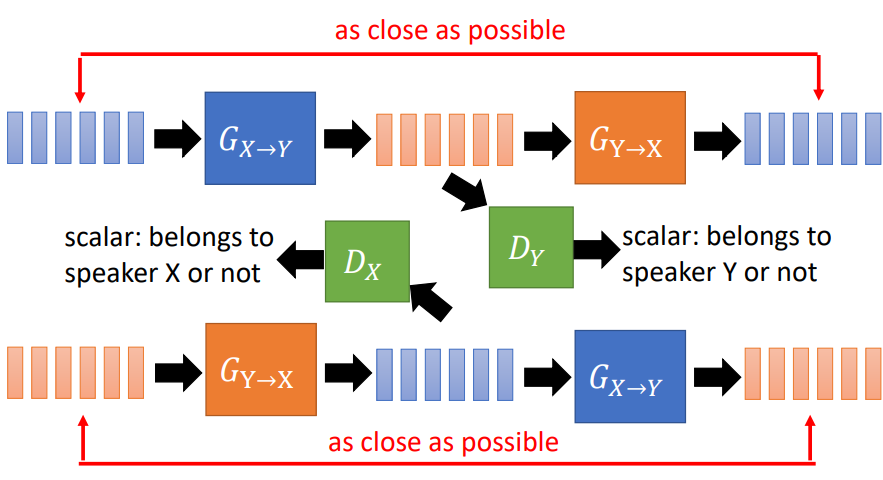
StarGAN
CycleGAN能够比较好得处理两个说话者的情况,如果说话者增多,假如有N个说话者,每两个人之间就需要2个生成器,总共需要N x (N-1)个生成器。
StarGAN的主要思想是把每个说话者转变成一个向量的形式,这样就可以在同一个模型中来表示多个说话者。它的结构如图中下半部分所示:
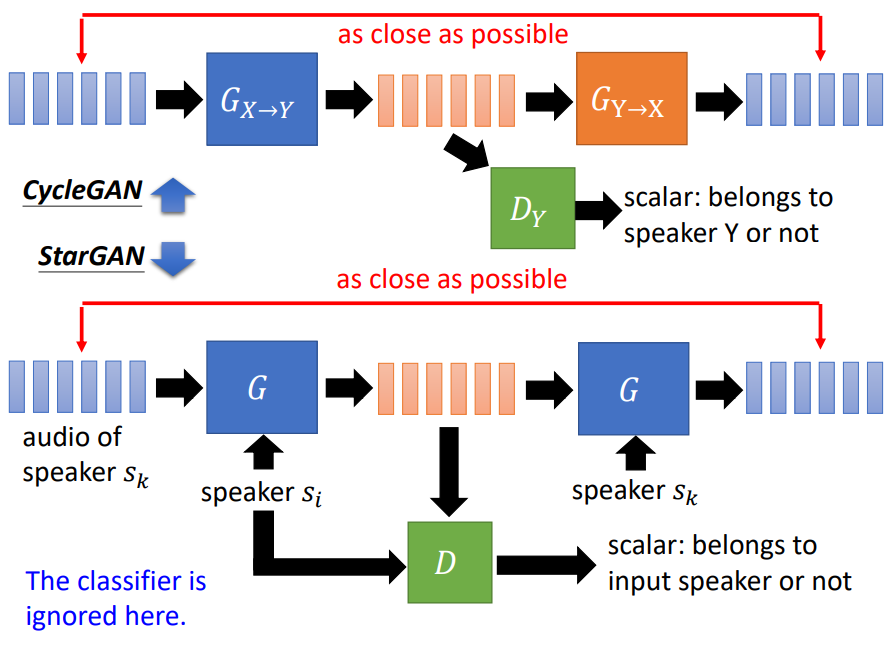
从图中可以看出StarGAN的结构和CycleGAN几乎一样,不同之处仅在于输入的speaker向量可以选择多个。
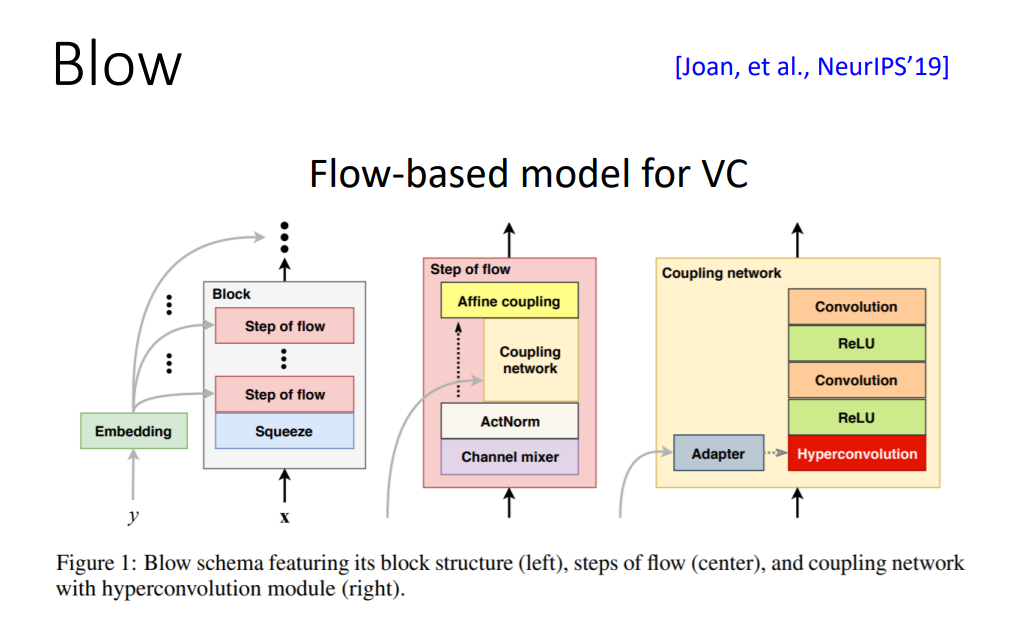
Blow
还有另一种思路不是利用Gan,而是利用流模型(flow-based model)来做语音转换,这里不作详细展开。
文章来源: zstar.blog.csdn.net,作者:zstar-_,版权归原作者所有,如需转载,请联系作者。
原文链接:zstar.blog.csdn.net/article/details/125328508

- 点赞
- 收藏
- 关注作者
评论(0)