【强化学习】读书手札:动态规划(DP)&蒙特卡洛(MC)&时序差分(TD)区别

阅读Sutton著作时,对动态规划、蒙特卡洛、时序差分三种方式有些费解,在此对三者的区别作一些简单的梳理。
动态规划(DP)
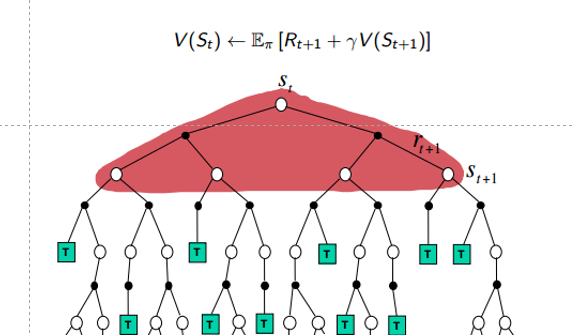
动态规划最主要的特点是转移概率已知,因此可根据贝尔曼方程来进行状态更新,相当于开了“上帝视角”,不适用于实际问题。
蒙特卡洛(MC)
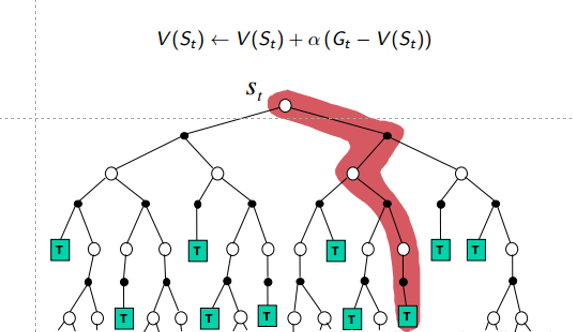
蒙特卡洛主要思想是通过大量的采样来逼近状态的真实价值。该方法的起始点是任意选取的,一直到终止状态才进行一次更新,因此当动作序列很长时或者出现循环,该方法便不适用。
该方法有两种类型:
首次访问型:把状态序列中第一次出现该状态时的收获值纳入到收获平均值的计算
每次访问型:把状态序列中每一次出现该状态都计算对应的收获值并纳入到收获平均值的计算
另外注意:当一幕结束进行更新时, G t G_t Gt是反向进行计算的,即最后一状态的奖励为 R t R_t Rt,倒数第二奖励为 y R t − 1 yR_{t-1} yRt−1…
时序差分(TD)
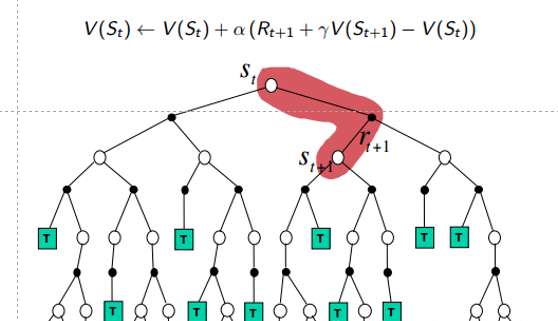
该方法不像MC需要在每个序列终止后再更新,而是每进行一步就进行更新,更适用于实际情况,往往效果比MC更好(数学上并无严格证明)。
三种方法对比

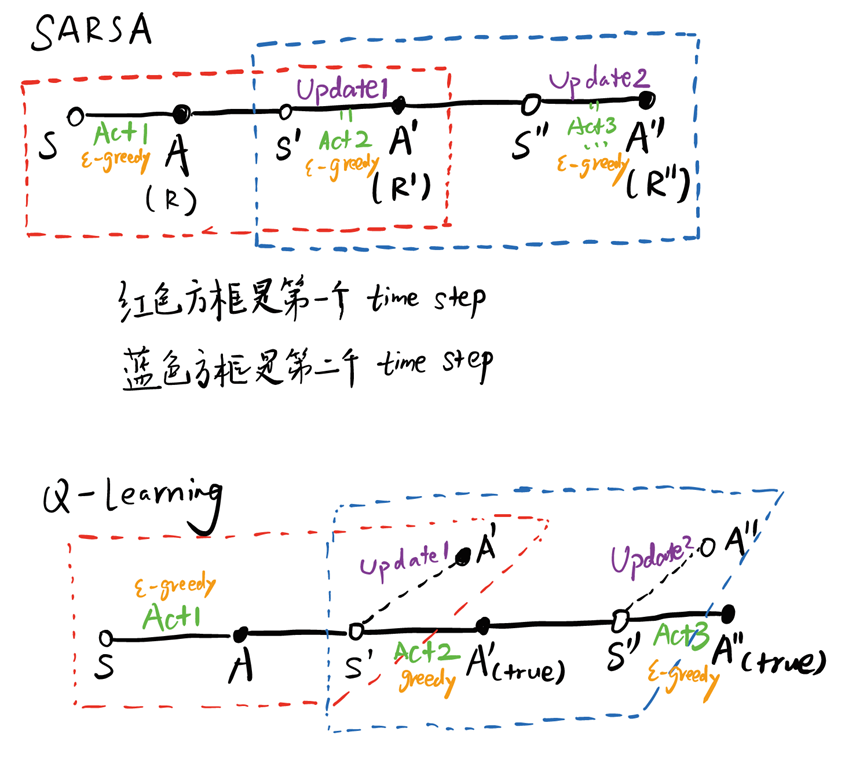
Sarsa和Q-Leaning区别
TD预测中可分为两种方法SARSA和Q-Leaning。
Sarsa
Sarsa属于同轨策略(On-policy)
更新公式:
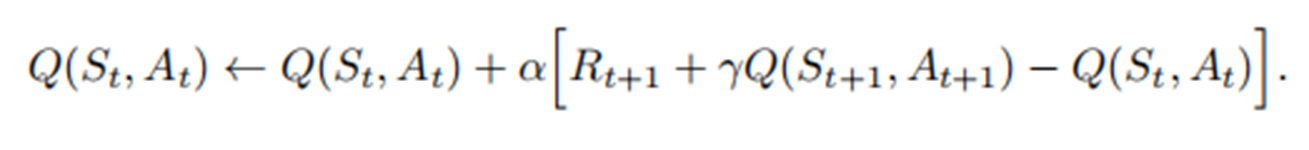
从公式可以看出Sarsa需要五个值:S,A,R,S’,A’,这也是该算法命名由来。
Q-Leaning
Q-Leaning属于离轨策略(Off-policy)
该方法遵循一个策略μ(a∣s)的同时评估另一个策略π(a∣s)具体数学表示为:
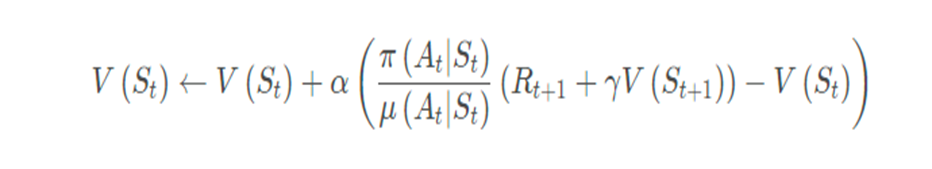

Q-learning的要点在于,更新一个状态动作二元组的价值时,采用的不是当前遵循策略的下一个状态动作二元组的Q价值,而是采用的待评估策略产生的下一个状态动作二元组的Q价值。公式如下:
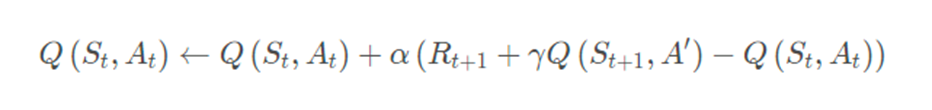
其中动作𝐴_(𝑡+1)由策略μ来产生,目标动作A′由策略π产生。
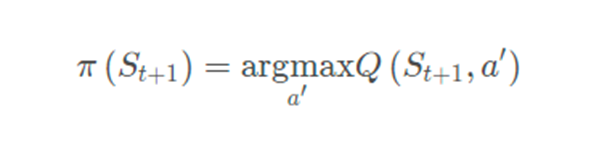
整理上式,TD目标值为:
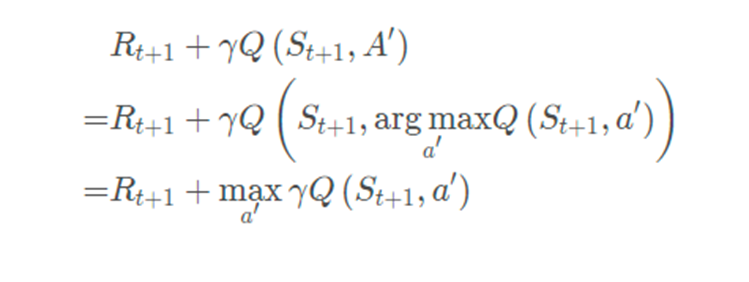
最终化简得到Q-Learning的更新公式:
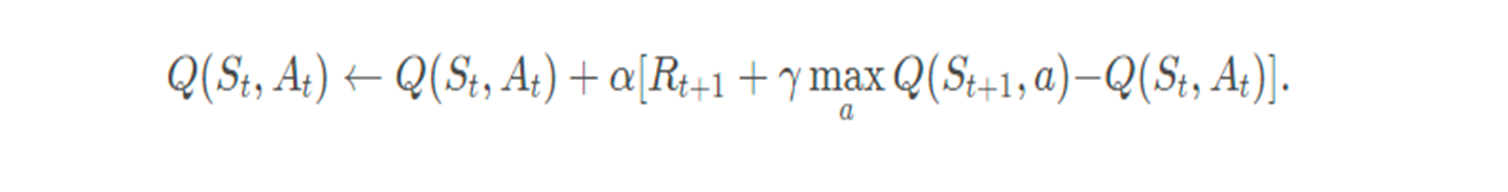
两者对比

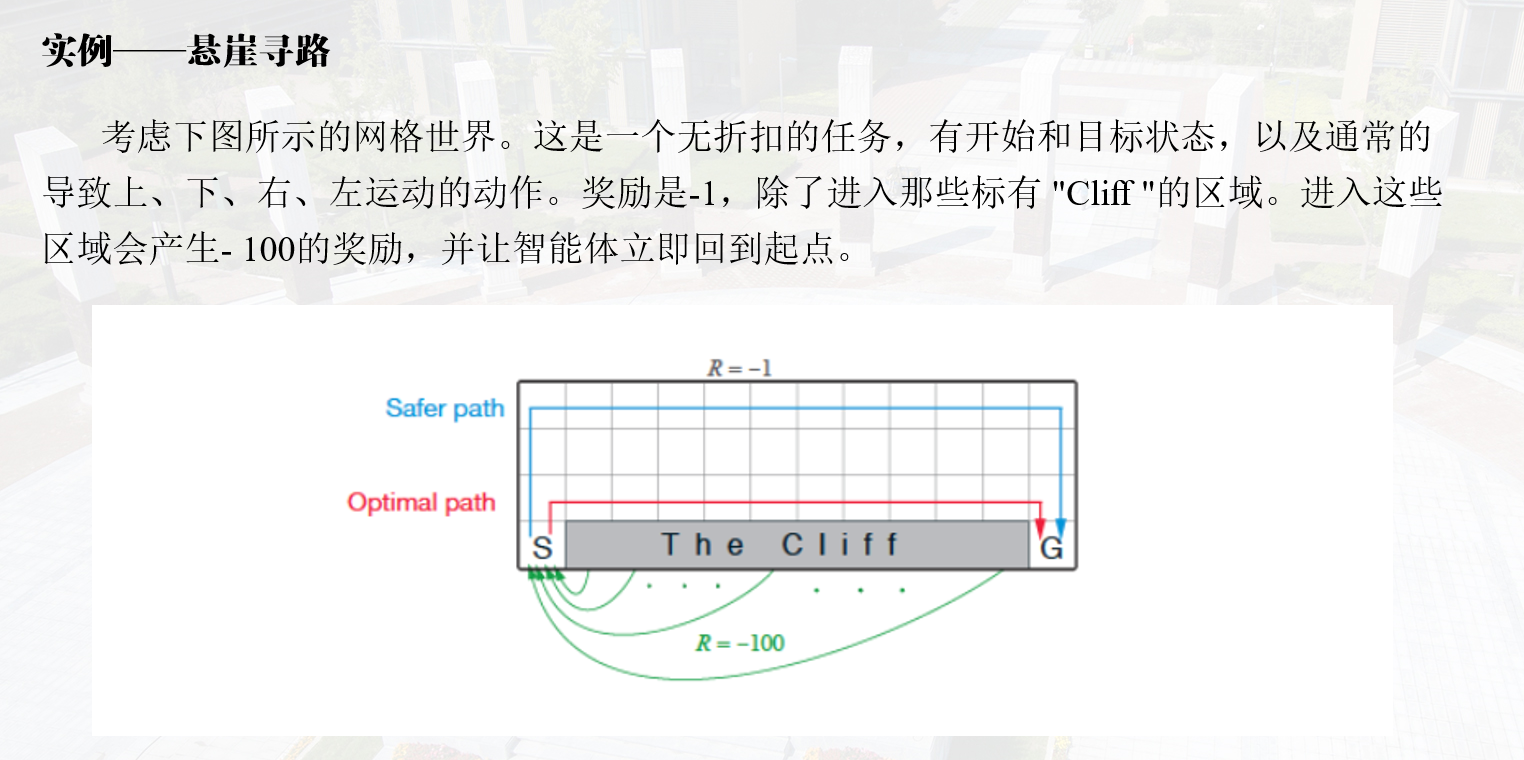
悬崖探路实例
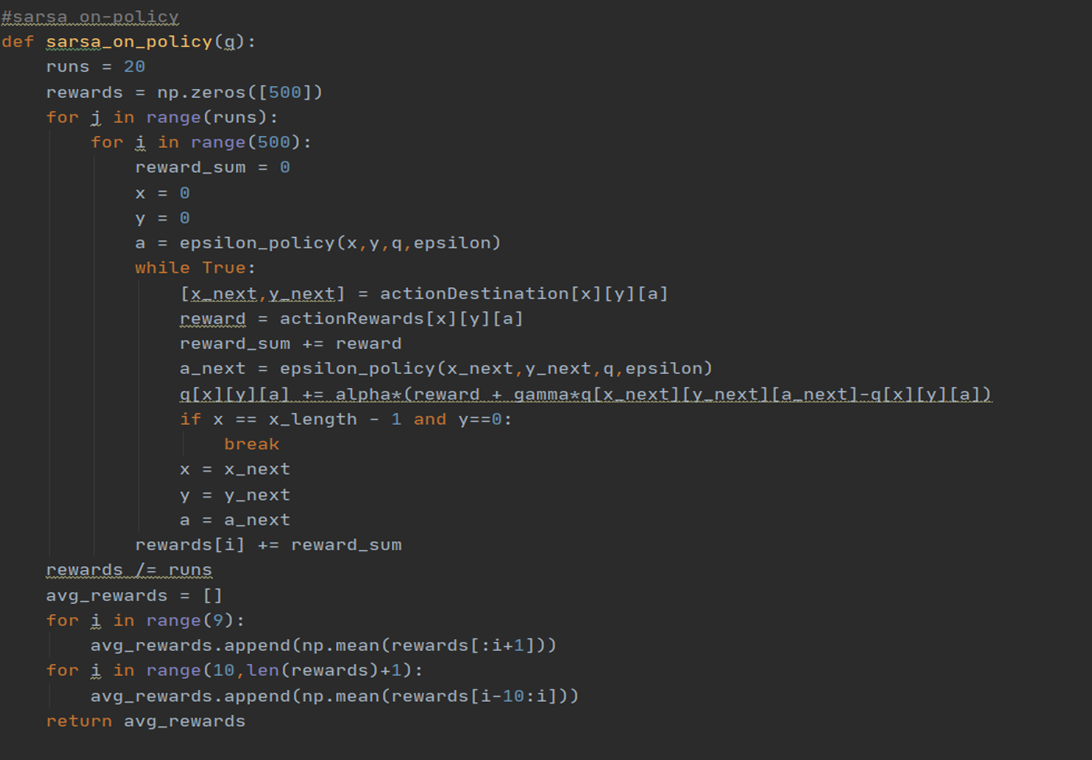
sarsa:
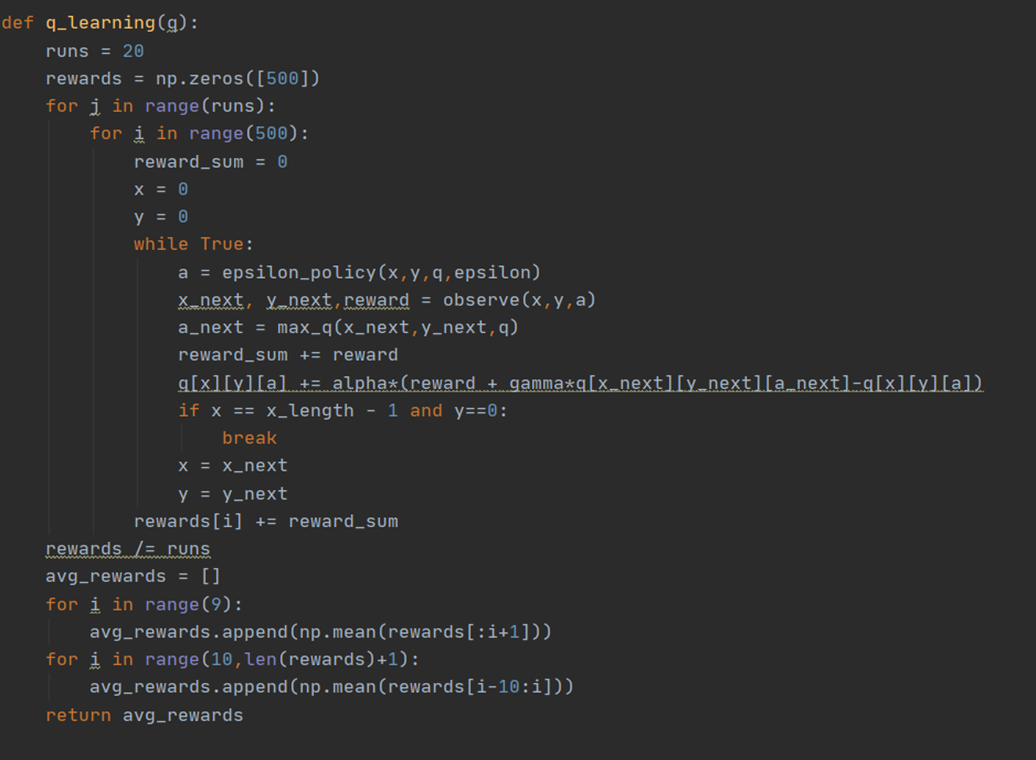
q_learning:
结果:
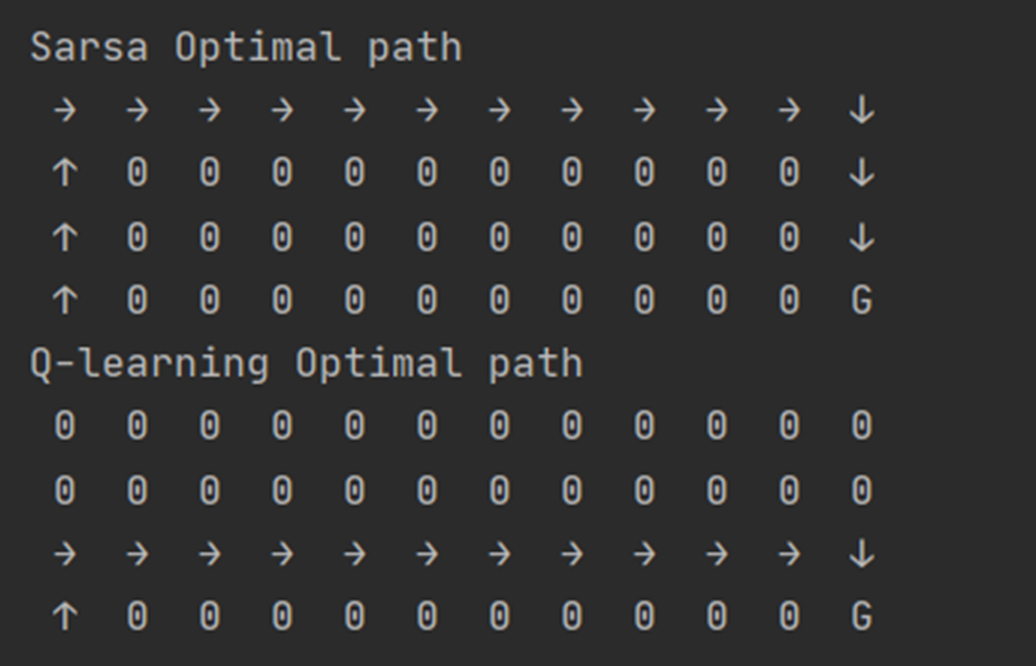
sarsa更趋向保守;Q-learnig更为激进,能够找到最优策略。
参考资料
1.https://blog.csdn.net/sword_csdn/article/details/118144693
2.https://wjn1996.blog.csdn.net/article/details/105194140
3.https://blog.csdn.net/sword_csdn/article/details/118144693
4.https://blog.csdn.net/midnight_DJ/article/details/121875116
5.https://www.cnblogs.com/pinard/p/9492980.html
6.https://piperliu.blog.csdn.net/article/details/104069627
7.https://zhuanlan.zhihu.com/p/54159132
文章来源: zstar.blog.csdn.net,作者:zstar-_,版权归原作者所有,如需转载,请联系作者。
原文链接:zstar.blog.csdn.net/article/details/122795253

- 点赞
- 收藏
- 关注作者
评论(0)