超星尔雅不让下载?课件,拿来吧你!

【摘要】
在学校内,老师可能出于版权考虑,课件不开放下载,但这给学生造成了极大的不便。 因为看课件的平台和课上答题互动的平台连在一起,这就导致每次答题都需要进行切换,极为麻烦。 正好,我玩过爬虫,于是便想到可以用爬...
在学校内,老师可能出于版权考虑,课件不开放下载,但这给学生造成了极大的不便。
因为看课件的平台和课上答题互动的平台连在一起,这就导致每次答题都需要进行切换,极为麻烦。
正好,我玩过爬虫,于是便想到可以用爬虫来批量拉取课件图片,再整合成pdf。
图片元素获取
按F12打开开发者工具,通过右键检查,找到了课件图片的url链接。
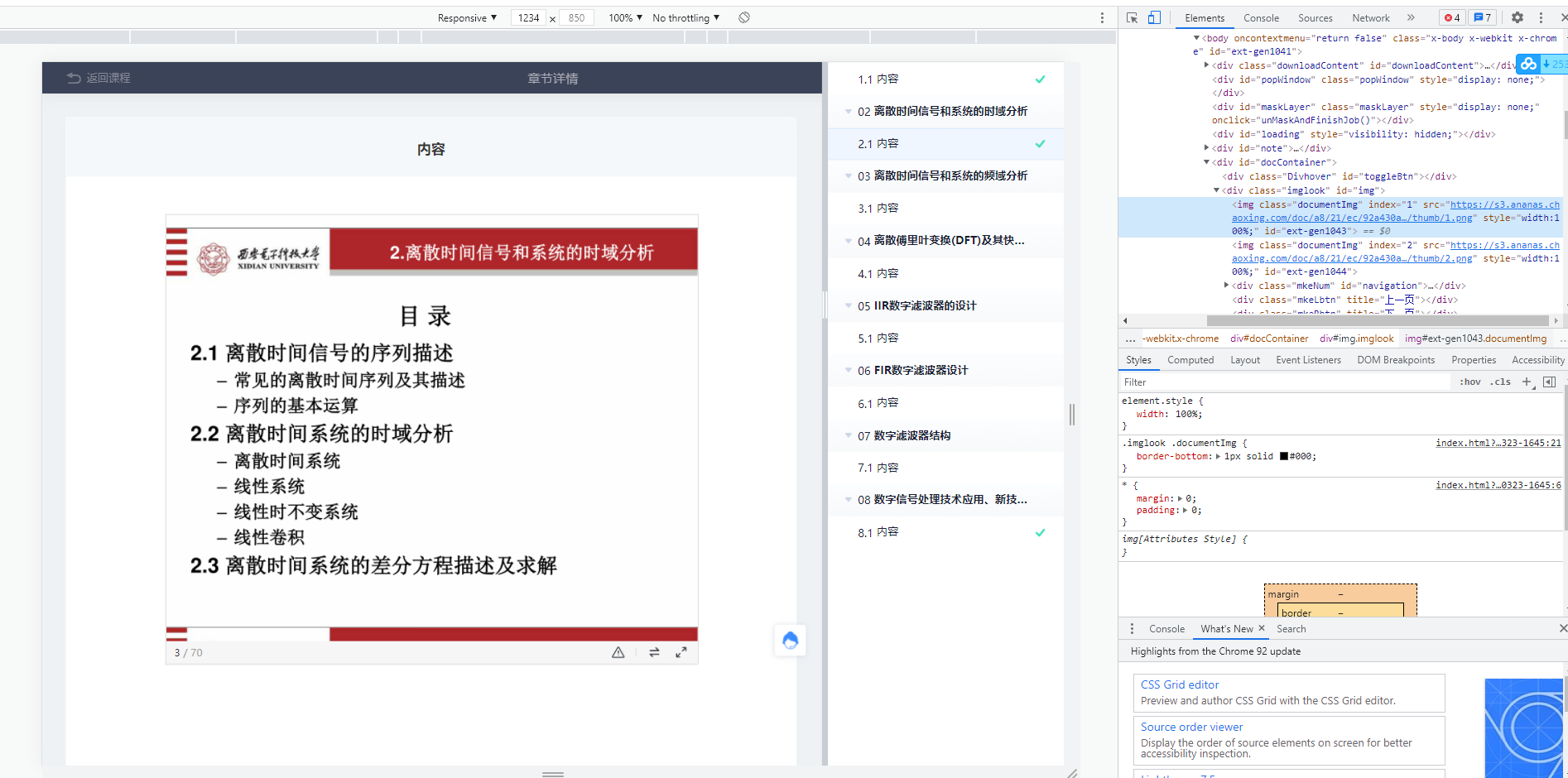
观察发现,课件图片的页数正好对应着url次数的递增,这给批量爬取带来了极大的便利。
批量爬取图片
上传pdf是由一片片图片组成的,因此,不能完整地将源文件的pdf下载到,只能一张张地将课件图片爬取下来。
def download(pages, path):
header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/52.0.2743.116 Safari/537.36'}
i = 1
for num in range(pages):
url = change_url(i)
response = requests.get(url=url, headers=header)
img = response.content
with open((path + "/%s.png") % i, 'wb') as f:
f.write(img)
i = i + 1
def change_url(i):
url = 'https://s3.ananas.chaoxing.com/doc/a8/21/ec/92a430a1e30c0009ec827b4269bc5357/thumb/'
url = (url + "%s.png") % i
return url
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
代码比较好理解,将需要下载的地址封装到change_url中,之后用经典的requests库发送请求,获取图片,写入文件。
将图片转换成pdf
这部分稍有难度,我参考了博主snrxian的文章python几行代码,把图片转换、合并为PDF文档
这里有一些坑需要注意:
1.png文件的编码是RGBA,需要用Img库的convert转换成RGB编码,否则转换成pdf的函数会报错。
2.使用os读取图片时,图片会出现乱序,在读取后需要重新根据名字排序。
代码函数:
def turnpic2pdf(path, name):
img_open_list = [] # 创建打开后的图片列表
for root, dirs, files in os.walk(path):
files.sort(key=lambda x: int(x.split('.')[0])) # 根据文件名排序
# print(files)
for i in files:
file = os.path.join(root, i) # 遍历所有图片,带绝对路径
img_open = Image.open(file) # 打开所有图片
if img_open.mode != 'RGB':
img_open = img_open.convert('RGB') # 转换图像模式
img_open_list.append(img_open) # 把打开的图片放入列表
pdf_name = name + '.pdf' # pdf文件名
img_1 = img_open_list[0] # 打开的第一张图片
# 把img1保存为PDF文件,将另外的图片添加进来,列表需删除第一张图片,不然会重复
img_open_list = img_open_list[1:]
img_1.save(pdf_name, "PDF", resolution=100.0, save_all=True, append_images=img_open_list)
print('转换成功!pdf文件在当前程序目录下!')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
附带main函数的完整代码
import requests
from PIL import Image
import os
def download(pages, path):
header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/52.0.2743.116 Safari/537.36'}
i = 1
for num in range(pages):
url = change_url(i)
response = requests.get(url=url, headers=header)
img = response.content
with open((path + "/%s.png") % i, 'wb') as f:
f.write(img)
i = i + 1
def change_url(i):
url = 'https://s3.ananas.chaoxing.com/doc/a8/21/ec/92a430a1e30c0009ec827b4269bc5357/thumb/'
url = (url + "%s.png") % i
return url
def turnpic2pdf(path, name):
img_open_list = [] # 创建打开后的图片列表
for root, dirs, files in os.walk(path):
files.sort(key=lambda x: int(x.split('.')[0])) # 根据文件名排序
# print(files)
for i in files:
file = os.path.join(root, i) # 遍历所有图片,带绝对路径
img_open = Image.open(file) # 打开所有图片
if img_open.mode != 'RGB':
img_open = img_open.convert('RGB') # 转换图像模式
img_open_list.append(img_open) # 把打开的图片放入列表
pdf_name = name + '.pdf' # pdf文件名
img_1 = img_open_list[0] # 打开的第一张图片
# 把img1保存为PDF文件,将另外的图片添加进来,列表需删除第一张图片,不然会重复
img_open_list = img_open_list[1:]
img_1.save(pdf_name, "PDF", resolution=100.0, save_all=True, append_images=img_open_list)
print('转换成功!pdf文件在当前程序目录下!')
if __name__ == '__main__':
path = "pic" # 输入存放图片的路径
pages = 70 # 输入需要爬取的图片页数
name = '课件二' # 输入保存的pdf名字
download(pages, path)
turnpic2pdf(path, name)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
使用注意:
1、存放图片的文件夹须为空文件夹。
2、更换链接时,需要修改三个参数:1.图片页数pages,2.url,3.保存的pdf名字。
3、当图片过多时,download需要一定时间才能运行完,这时候可以先把后面的转换注释掉,分段运行。
声明
写在最后,声明一下:
本程序仅供学习交流,获取的课件仅供自己学习使用,不向外传播。
文章来源: zstar.blog.csdn.net,作者:zstar-_,版权归原作者所有,如需转载,请联系作者。
原文链接:zstar.blog.csdn.net/article/details/120148214

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)