数据分析 -- Pandas②

数据筛选
沿用上一篇的数据:
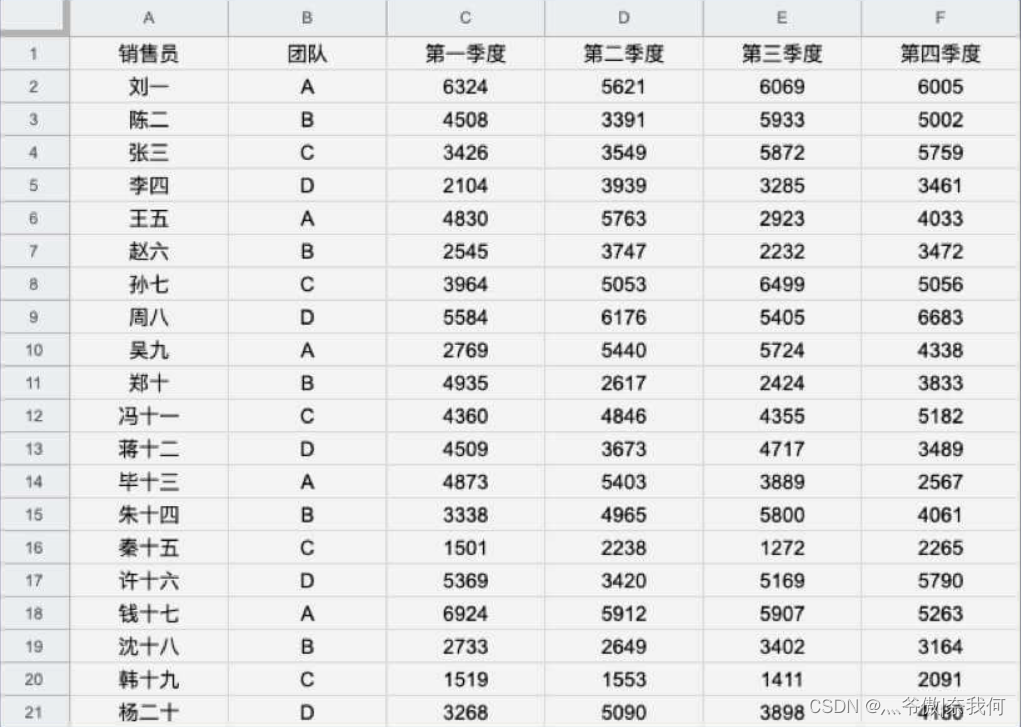
将每一行四个季度进行求和
df['总和'] = df['第一季度'] + df['第二季度'] + df['第三季度'] + df['第四季度']
- 1
若此时我们想要筛选出那些总销售额低于平均值的销售员:
df[df['总和'] < df['总和'].mean()]
- 1
这和 NumPy 中数组的布尔索引是一样的,中括号里是筛选条件,返回值是所有符合条件的数据。df[‘总和’] < df[‘总和’].mean() 的结果如下:
0 False
1 False
2 False
3 True
4 False
5 True
6 False
7 False
8 False
9 True
10 False
11 True
12 True
13 False
14 True
15 False
16 False
17 True
18 True
19 True
Name: 总和, dtype: bool
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
符合条件的为 True,不符合条件的为 False。最终 df[df[‘总和’] < df[‘总和’].mean()] 会去除所有结果为 False 的行,只保留下结果为 True 的。最终的返回结果如下:
销售员 团队 第一季度 第二季度 第三季度 第四季度 总和
3 李四 D 2104 3939 3285 3461 12789
5 赵六 B 2545 3747 2232 3472 11996
9 郑十 B 4935 2617 2424 3833 13809
11 蒋十二 D 4509 3673 4717 3489 16388
12 毕十三 A 4873 5403 3889 2567 16732
14 秦十五 C 1501 2238 1272 2265 7276
17 沈十八 B 2733 2649 3402 3164 11948
18 韩十九 C 1519 1553 1411 2091 6574
19 杨二十 D 3268 5090 3898 4180 16436
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
我们也可以写多个条件进行判断,在 pandas 中要表示同时满足,各条件之间要用 & 符号连接。如果要表示只要满足之一,各条件之间要用 | 符号来连接。并且每个条件要用括号括起来,举个例子:
# 筛选出总和大于 10000 且小于 12000 的
df[(df['总和'] > 10000) & (df['总和'] < 12000)]
# 筛选出总和小于 5000 或大于 12000 的
df[(df['总和'] < 5000) | (df['总和'] > 12000)]
- 1
- 2
- 3
- 4
- 5

给数据打标签
pandas 的 cut() 方法常用于数据的分类和打标签。
比如:
pd.cut(df['总和'], bins=[0, 1000, 2000, 3000], labels=['不合格', '良好', '优秀'])
- 1
上面这段代码的意思是,按照 (0, 1000]、(1000, 2000] 和 (2000, 3000] 的数值区间,把数据分为不合格、良好和优秀三组。
参数详解:
- 第一个参数是要分类的列;
- 第二个参数
bins是分类的方式,即分类区间,默认是左开右闭,设置 bins=[0, 1000, 2000, 3000],那对应的分类区间就是 (0, 1000]、(1000, 2000] 和 (2000, 3000]。如果你想要左闭右开的方式,可以再添加一个参数 right=False。 - 参数
labels分别对应了这三组的标签名。即 (0, 1000] 表示不合格,(1000, 2000] 表示良好,(2000, 3000] 表示优秀。
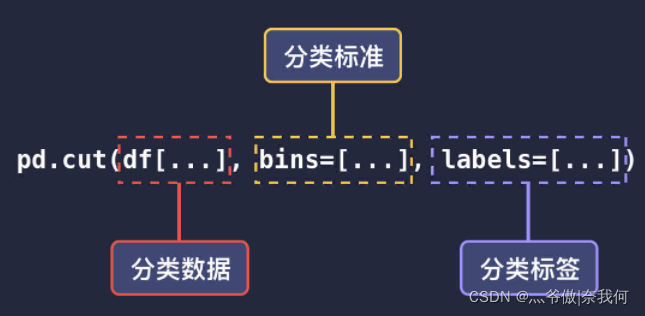
记得打完标签后一定要新增一个列放进去,要不是显示不出来的。
例如:
df['绩效'] = pd.cut(df['总和'], bins=[0, 1000, 2000, 3000], labels=['不合格', '良好', '优秀'])
- 1
行的查改增删
首先,我们用 DataFrame 构建一个简单的表格:
import pandas as pd
df = pd.DataFrame({'辣条': [14, 20], '面包': [7, 3], '可乐': [8, 13], '烤肠': [10, 6]})
- 1
- 2
- 3
然后我们能得到下面这样的表格:
辣条 面包 可乐 烤肠
0 14 7 8 10
1 20 3 13 6
- 1
- 2
- 3
列是通过列名来获取的,同理,行是通过最左边的索引来获取。在不指定的情况下,索引值默认从 0 开始依次递增。我们可以使用 loc 基于索引进行表格行的查改增删。
查看行
索引
以查看上面表格中第一行的数据为例,代码如下:
print(df.loc[0])
- 1
注意,loc 并不是一个方法,而是类似于字典。所以我们使用的是 [] 而不是 ()
运行结果:
辣条 14
面包 7
可乐 8
烤肠 10
Name: 0, dtype: int64
- 1
- 2
- 3
- 4
- 5

如果你在构建表格时像下面这样单独设置了索引,同样也可以用对应的索引值来获取表格行的数据:
import pandas as pd
data = {
'辣条': [14, 20],
'面包': [7, 3],
'可乐': [8, 13],
'烤肠': [10, 6]
}
df = pd.DataFrame(data, index=['2020-01-01', '2020-01-02'])
print(df.loc['2020-01-01'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
上面的代码中,表格的索引是日期。我们查看对应日期的数据时就需要将对应的日期作为索引,运行结果如下:
辣条 14
面包 7
可乐 8
烤肠 10
Name: 2020-01-01, dtype: int64
- 1
- 2
- 3
- 4
- 5
除了第一个参数索引外,还支持第二个参数列名。即同时基于行和列获取指定的数据,比如:
print(df.loc[0, '辣条'])
- 1

分片
例如:
# 行分片
print(df.loc[0:1, '辣条'])
# 列分片
print(df.loc[0, '辣条':'可乐'])
# 同时分片
print(df.loc[0:1, '辣条':'可乐'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
需要注意的是,这里的分片和 Python 中列表的分片不太一样,这里的分片结果是前后都包含的,而列表分片只包含前面不包含后面。
运行结果:
0 14
1 20
Name: 辣条, dtype: int64
辣条 14
面包 7
可乐 8
Name: 0, dtype: int64
辣条 面包 可乐
0 14 7 8
1 20 3 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
你也可以通过省略冒号前后的内容来实现全选,例如:df.loc[:, ‘辣条’:‘可乐’],这一点和列表的分片是一样的。
loc 同时也支持布尔索引来进行数据的筛选,比如获取辣条销量大于 15 的数据:
df.loc[df['辣条'] > 15]
- 1
上面的写法等价于 df[df[‘辣条’] > 15],不同之处在于 loc 还能通过第二个参数筛选出只想查看的列,比如:
print(df.loc[df['辣条'] > 15, ['辣条', '面包']])
- 1
结果:
辣条 面包
1 20 3
- 1
- 2

多条件筛选的写法与前面一样
iloc
除了比较常用的 loc 之外,我们还能使用 iloc。用法和 loc 一样,区别在于 loc 使用的参数是索引,而 iloc 的参数是位置,即第几行。因此,在不指定索引的情况下,loc 和 iloc 的效果是一样的。但当单独指定了索引,我们想获取前 3 行数据时可以像下面这样写:
import pandas as pd
data = {
'辣条': [14, 20, 12, 15, 17],
'面包': [7, 3, 8, 3, 9],
'可乐': [8, 13, 23, 12, 19],
'烤肠': [10, 6, 21, 24, 18]
}
df = pd.DataFrame(data, index=['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04', '2020-01-05'])
print(df.iloc[:3]) # :3 表示 0、1、2 前三行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
结果:
辣条 面包 可乐 烤肠
2020-01-01 14 7 8 10
2020-01-02 20 3 13 6
2020-01-03 12 8 23 21
- 1
- 2
- 3
- 4
注意:索引变成了日期,想要按位置获取数据的话只能使用 iloc,这时如果使用 df.loc[:3] 将会报错。
注意,iloc 的分片和 Python 的列表分片一样,要和 loc 的分片规则区分开来。
修改行
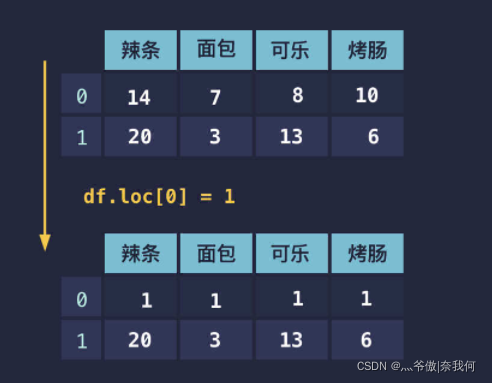
假设某行的数据有问题,我们需要进行修正。修改起来同样也很简单,直接赋值即可。这里分为两种情况:
- 赋值为一个数字;
- 赋值为长度和列数相等列表。
情况一
对于第一种情况,这一行所有的数据都会被修改成同样的数字:
df.loc[0] = 1 # 第一行都改成 1
print(df)
- 1
- 2
结果:
辣条 面包 可乐 烤肠
0 1 1 1 1
1 20 3 13 6
- 1
- 2
- 3
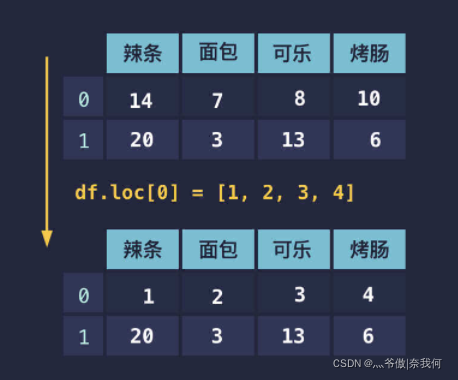
情况二
而第二种情况则是按列表顺序修改对应的列:
# 按顺序修改成 1 2 3 4
df.loc[0] = [1, 2, 3, 4]
print(df)
- 1
- 2
- 3
辣条 面包 可乐 烤肠
0 1 2 3 4
1 20 3 13 6
- 1
- 2
- 3
当然你也可以使用例如 df.loc[0, ‘辣条’] = 23 定位到行和列来修改特定的数据。
新增行
行和列的基本操作都是类似的,只是具体的方式不同。新增行也是如此,只需传入表格中不存在的索引即可。
例如:
# 添加第三行,全为 1
df.loc[2] = 1
# 添加第四行,分别为 1 2 3 4
df.loc[3] = [1, 2, 3, 4]
print(df)
- 1
- 2
- 3
- 4
- 5
结果:
辣条 面包 可乐 烤肠
0 14 7 8 10
1 20 3 13 6
2 1 1 1 1
3 1 2 3 4
- 1
- 2
- 3
- 4
- 5
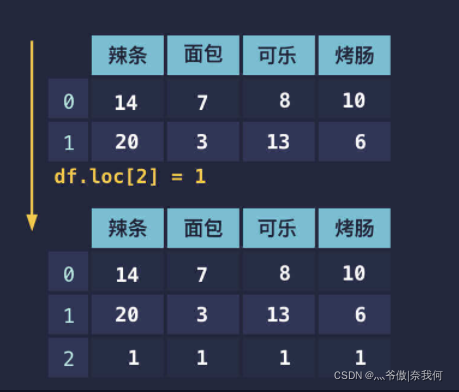
注意:在新增行时,是不能使用 iloc 传入索引的.(所以在新增行的时候就不要使用iloc了)
删除行
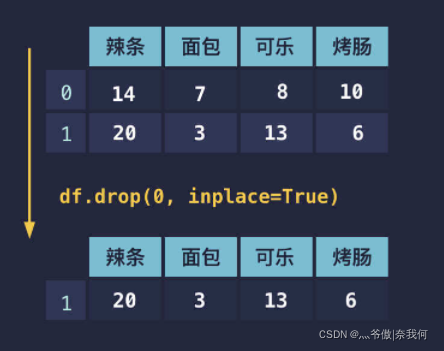
删除行和删除列一样,都是使用 drop() 方法。删除列的使用传入了 axis=1 表示对列进行删除,axis 默认为 0,因此删除行时省略 axis 参数即可。
df.drop(0, inplace=True) # 删除第一行
print(df)
# 或者 print(df.drop(0))
- 1
- 2
- 3
数据的分组
pandas 提供了 groupby() 方法用于数据的分组,第一个参数用于指定按哪一列进行分组。
例如现在我们有数据:
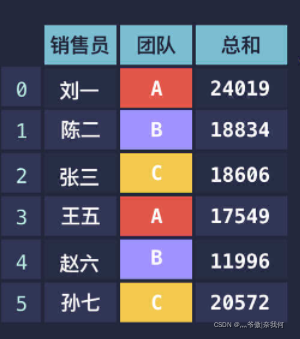
我们要按团队分组就可以像下面这样写:
df.groupby('团队')
- 1
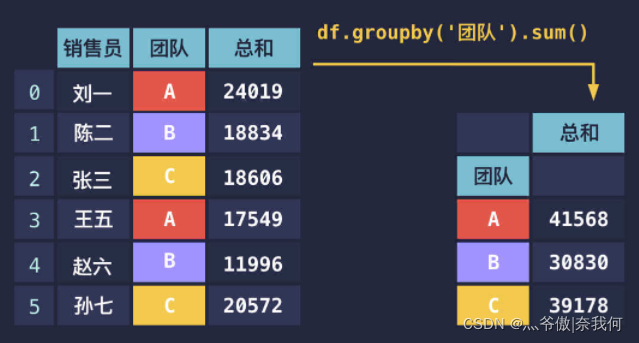
但仅仅进行分组是没有结果的(实际上它返回的是一个分组后的对象,你不能直接打印出来看),还需要调用 max()、min()、mean()、sum() 等方法进行分组后的计算。
就像:
print(df.groupby('团队').sum())
- 1
分组统计后的结果如下:
第一季度 第二季度 第三季度 第四季度 总和
团队
A 25720 28139 24512 22206 100577
B 18059 17369 19791 19532 74751
C 14770 17239 19409 20353 71771
D 20834 22298 22474 23603 89209
- 1
- 2
- 3
- 4
- 5
- 6
文章来源: blog.csdn.net,作者:十八岁讨厌编程,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/zyb18507175502/article/details/122729188

- 点赞
- 收藏
- 关注作者
评论(0)