初识爬虫③ -网页基础

重识网页
网页的本质是 HTML,当我们用浏览器打开某个网页的时候,浏览器用适合人类阅读的方式呈现出来了。
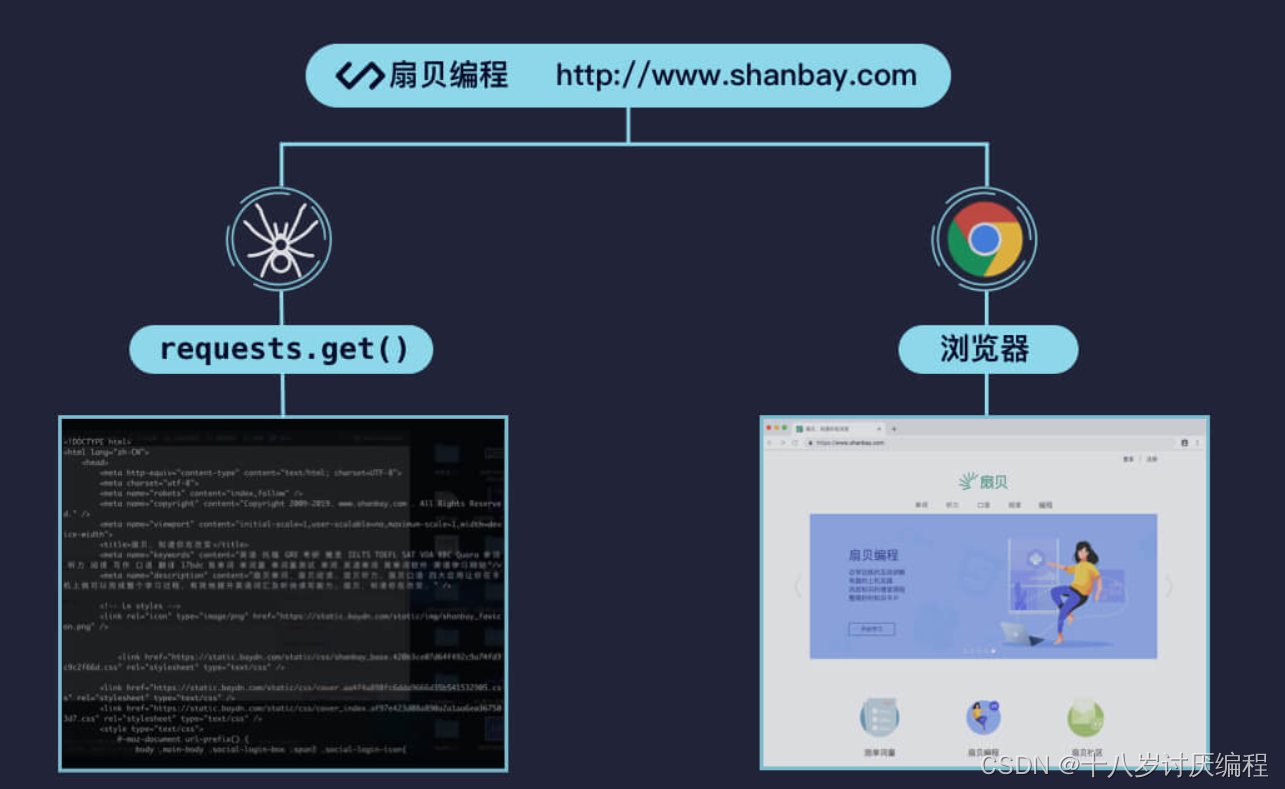
爬虫要解析的就是 HTML,熟悉 HTML 语法后你就可以在解析 HTML 上游刃有余。
前面我们讲过,向浏览器中输入某个网址后,浏览器会向服务器发出请求,然后服务器就会作出响应。其实,服务器返回给浏览器的这个结果就是 HTML 代码了。
而紧接着,浏览器会根据这个 HTML 代码,解析成我们所能看见的漂亮网页。
通过右键点击 显示网页源代码 可以看到:网页的本质就是一个 HTML 文档。
整个网页的源代码都完整地呈现在你面前。但是这个 HTML 文档经过压缩,导致结构不清晰,阅读起来非常吃力。
你可能会好奇,这个 HTML 压缩成这个样子,一行代码几百个字母,这是给人看的吗?
的确,它一般都不是给人看的,是给浏览器看的。
大部分程序员在写完代码后发布代码前会对代码进行压缩,去除一些些没用的换行符、空格等。虽然格式不好看,但浏览器能读懂就行。压缩后的优点就是文件体积小,这样在你从互联网上访问(下载)这个网页时,耗费的流量更少,加载时间更短!
现在你应该理解 HTML 和我们在网上冲浪时看到的网页二者在本质上是一样的。
网页开发
爬虫看到的网页是 HTML,我们在浏览器里看到的网页其实是经过浏览器对 HTML 处理过后的样子。
在学习 HTML 前,我们先了解一些网页开发的知识。网页开发,也叫 Web 开发,是近几年比较热门的开发岗位。你可能听过 Web 开发或者身边有从事 Web 开发的朋友,Web 开发也称为前端开发,他们需要同时掌握三把利器——HTML、CSS、JavaScript。
一下接触三个新知识,你可能会有点吃力。不过不要担心,对于爬虫来说,我们暂时只需要掌握 HTML 的知识即可,其他知识稍作了解。
接下来我们会把网页开发和熟悉的 PPT 制作来对比理解,我想你对 PPT 的制作应该不陌生吧?
PPT的制作过程:
- 新建 PPT 文件
- 插入标题、文本框、图片等元素
- 调整字体大小、颜色等,进行排版
- 添加动画,比如为页面元素设置进入和退出的动画
进行一个网页的开发过程和上面类似:
- 新建 HTML 文件
- 添加 HTML 元素
- 通过 CSS 来调整元素样式
- 通过 JavaScript 来配置页面的交互动作等
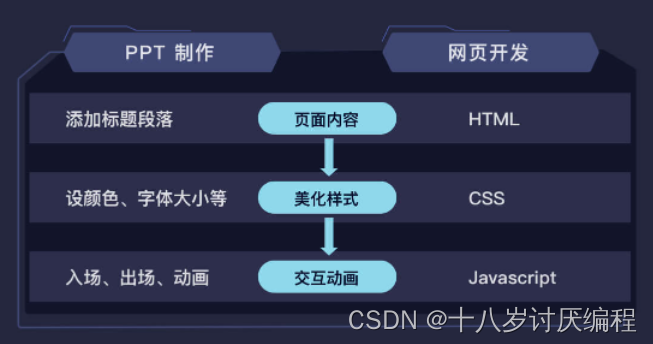
简单来说就是:HTML 负责为网页添加内容,CSS 负责美化网页,JavaScript 负责让网页动起来。JavaScript 是最复杂的部分,对于高级的前端开发,这是必须要掌握的。

HTML 元素
HTML(Hyper Text Markup Language)是一种超文本标记语言,它是由一堆标记(或者称为标签)组成的,语法特别简单。
<html>
<head>
<title>我的第一个网页</title>
</head>
<body>
Hello,World
</body>
</html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
上面的代码展示了一个最简单的 HTML 代码,可以看到很多夹在尖括号 <> 中间的字母,它们叫做 标签。
一般来说标签都是成对出现的,所以标签又分为 开始标签(比如 <title>)和 结束标签(比如 </title>)。开始标签、结束标签加上标签中间的内容就构成了 元素。
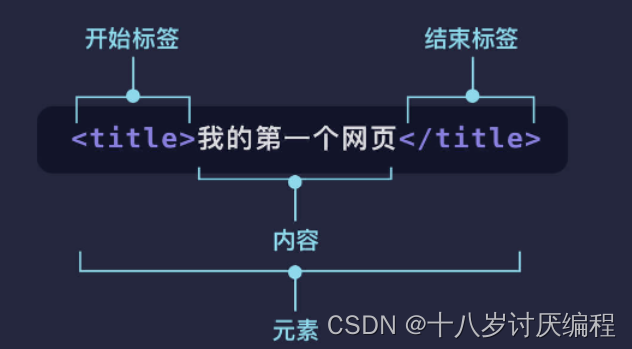
结束标签与开始标签十分相似,只是结束标签在元素名之前包含了一个斜杠 /,表示着元素的结束。初学者常常会忘记结束标签,这可能会产生一些奇怪的结果。
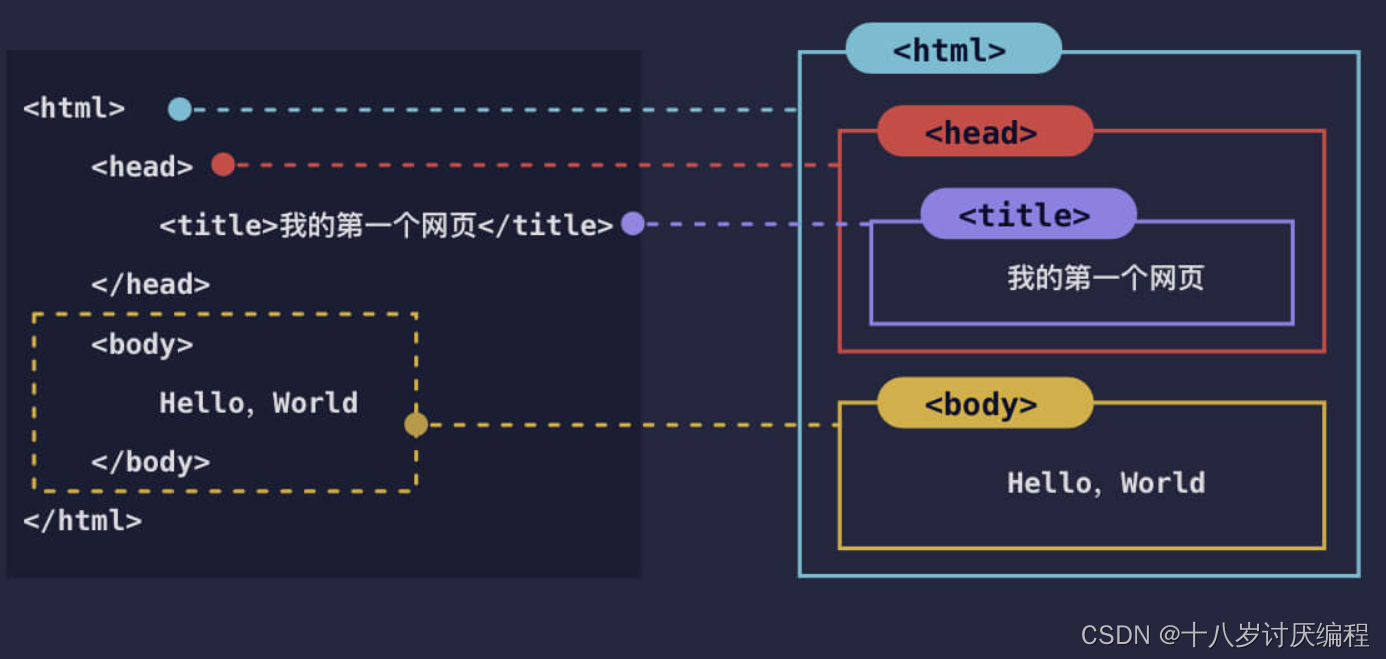
我们重新看一下最开始的 HTML 代码,它是由 html、head、title、body 这四个元素组成的。一般情况下,这四个是每个 HTML 文档都会有的元素。
我们还能看到 HTML 标签是可以嵌套的,一般情况下,一份符合标准的 HTML 文档最外层都是 <html> 标签,所有的内容都包含在 <html> 元素里。因此 <html> 元素也叫根元素。
一般来说,<head> 和 <body> 标签也是必须的,直接嵌套在 <html> 元素里。<head> 元素里的内容是 网页头,网页头中一般存放网页相关信息、加载样式和脚本等。<body> 元素里的内容是 网页体,也就是存放网页内容的地方。
我们一定要注意层级关系,不能错乱,像下面这样 <head> 和 <body> 交叉在一起是有问题的:
<html>
<head>
<title>我的第一个网页</title>
<body>
</head>
Hello,World
</body>
</html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
接下来我们来详细说说 网页头 和 网页体。
前面说过网页头中一般存放网页相关信息、加载样式和脚本等,我们来看一个例子:
<head>
<meta charset="utf-8" />
<title>我的第一个网页</title>
<link rel="stylesheet" href="style.css" />
<script src="script.js"></script>
</head>
- 1
- 2
- 3
- 4
- 5
- 6
<meta charset=“utf-8” /> 定义了网页的编码方式,是 utf-8。当爬虫获取的数据乱码时,我们可以根据它来更正编码;<title>我的第一个网页</title> 指定了网页的标题,也就是浏览器标签栏中看到的标题;
剩下来的一个是加载样式文件的代码,一个是加载脚本文件的代码。对爬虫来说不必深入,了解一下即可。
或许你已经发现了,<meta charset=“utf-8” /> 和前面说的需要有开始标签和结束标签不太一样,只有一个标签。别急,这个我们后面会说。
接下来是 网页体,这个是爬虫要重点关注的,我们需要的数据都存放在里面。上面的示例代码中,为了简洁,直接在网页体内写了内容。但一般网页的网页体内会有很多其他的元素共同组成。
HTML 常见元素
一篇结构清晰的文章都有标题和段落,HTML 网页也是如此。
HTML 提供了 6 个等级的标题,即 <h1>、<h2>、<h3>、<h4>、<h5>、<h6>,重要性依次递减,也就是说 <h1> 是最大的标题,<h6> 是最小的标题。
同时,在HTML 里段落使用的是 <p> 标签,超链接使用的是 <a> 标签,图片使用的是 <img> 标签。

前面说过,标签分为开始标签和结束标签。这是 HTML 的元素的一个重要特性——闭合性。根据闭合性分为自闭合标签和非自闭合标签。顾名思义,二者的区别就是闭合方式的不同。
前面讲过的 <meta charset=“utf-8” /> 就属于自闭合标签。下图对比了非自闭合标签(h1)和自闭合标签(meta)的区别:
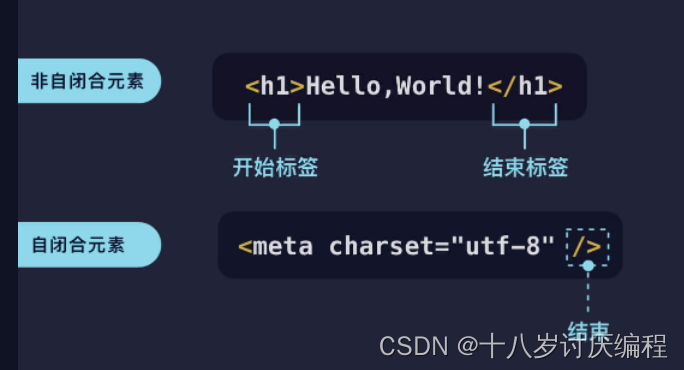
非自闭合元素必须有开始和结束标签,而自闭合元素没有结束标签,/> 意味着这个元素的结束。非自闭合元素有被开始标签和结束标签包裹住的内容,而自闭合标签则没有元素内容,只有元素属性。
对于自闭合元素和非自闭合元素,你只需要知道有这两种写法即可。当你在别的网页源代码里看到这两种写法时,不要觉得陌生。
下图列出了常见的自闭合元素和非自闭合元素,了解一下即可:

属性
HTML 元素可以通过设置属性来为元素提供更多信息。在爬虫中,我们经常通过这些属性去筛选、提取数据。
<a> 元素是我们常见的超链接,是 HTML 里非常重要的元素。它将一个个网页全都链接在一起,形成了互联网。<a> 元素的 href 属性中存储的是跳转网页的地址,被标签包裹的内容是网页中展示给我们看的实际内容。
HTML 元素属性的语法是 属性名=“属性值”,且必须在开始标签中。HTML 元素可以拥有多个属性,用空格分隔开即可。
有时候会看见class=“one two”,不是说class这个属性的值为one two,而是说他有两个值one和two。
自闭合元素没有元素内容,因此元素属性对它们来说就是全部。继续拿前面说过的 <meta charset=“utf-8” /> 为例,通过 charset=“utf-8” 定义了网页编码为 utf-8。
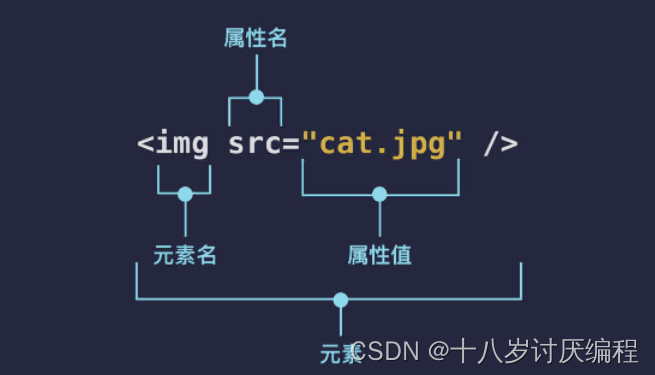
<img> 元素也是自闭合元素,它是图片元素,网页上面呈现的各种图片就是使用了 <img> 元素。<img> 元素有个 src 属性,里面储存图片的地址,这样浏览器就能将图片展示在网页上。
我们可以像下面这样在网页中展示一张图片:
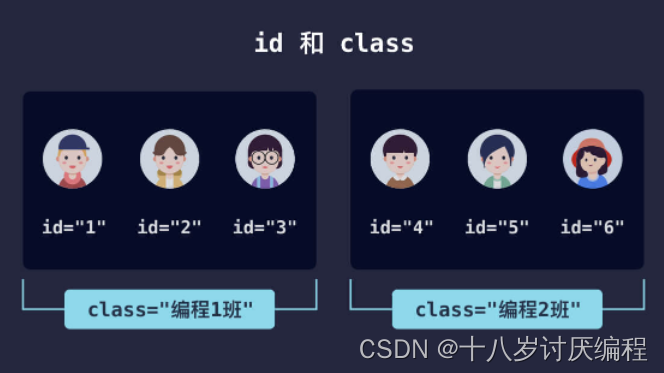
HTML 中还有两个很常用的属性——id 和 class!
id 和 class 都用于标识元素,是给 JavaScript 和 CSS 用的。因为爬虫中经常用到它们,因此这里简单的介绍一下。
id 是唯一标识,其值在整个网页里是唯一的。而 class 是一类标识,其值可以用在同一类所有的元素中。
你可以简单的理解为:id 是学号,class 是班级。学号是全学校唯一的,而班级里有很多的人。
再举个实际点的例子:比如网页上有一个唯一的登录按钮(<button> 元素),那么我们可以给它加上 id=“login-btn” 来标识。
网页上还有很多电影名称,格式都一样,我们可以给它们加上 class=“movie-name” 来标识。
为什么要做标识呢?是为了给 JavaScript 找到对应的元素做出交互,为了给 CSS 找到对应的元素设置样式。而我们的爬虫正可以利用这一点找到我们需要的数据,比如我们想要找到所有的电影名称,只需要找到所有 class 为 movie-name 的元素,并提取出元素的内容即可。
除了这些之外,还有更多的 HTML 元素和属性,语法都比较简单,大家遇到不认识的元素或属性时,利用搜索引擎、翻阅文档就可以轻松解决!
文章来源: blog.csdn.net,作者:十八岁讨厌编程,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/zyb18507175502/article/details/124635049

- 点赞
- 收藏
- 关注作者
评论(0)