数据分析 -- Pandas③

表格合并
纵向合并
在日常工作中,表格合并是个较为常见的需求。还是以之前的销售数据为例,一般是每个团队只统计自己团队的销售数据,然后汇总给负责人进行数据汇总,得到最后的总表。
ABCD 四个团队的销售表分别如下,我们纵向合并表格,也就是将表格内容从上往下进行叠加。
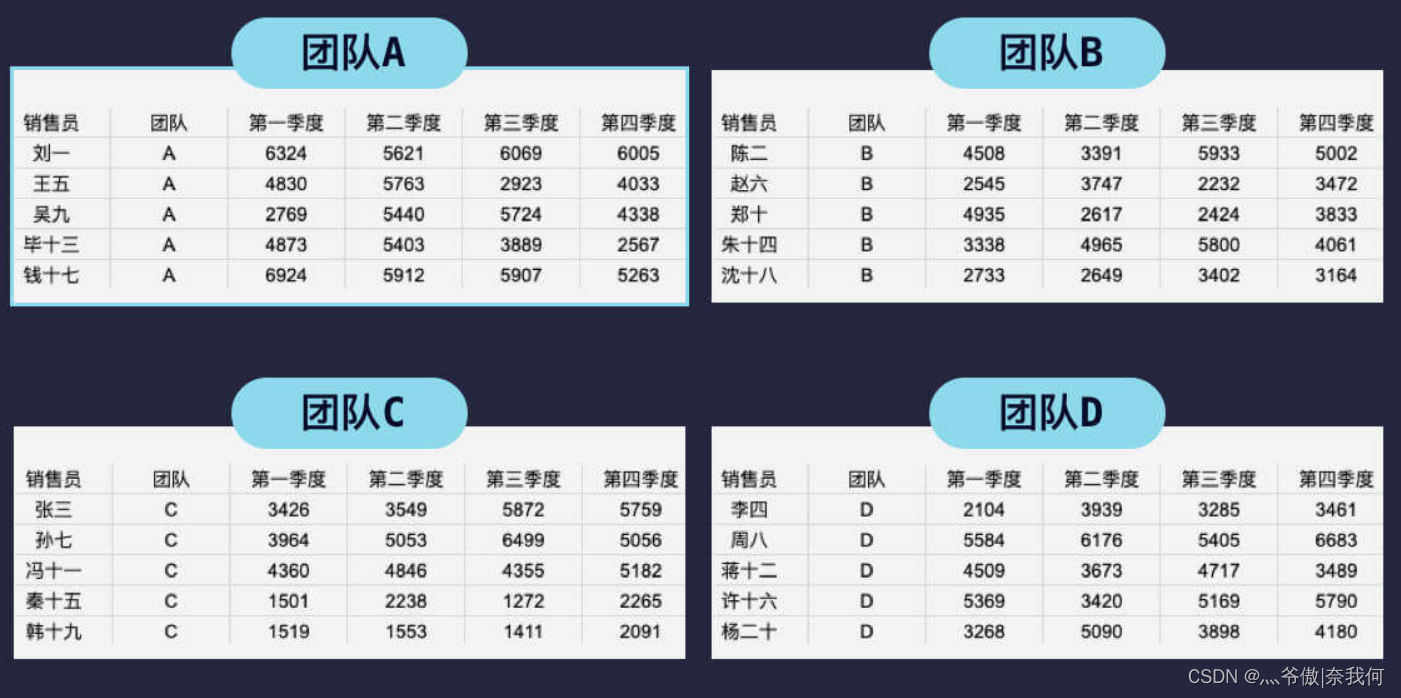
这在 pandas 中使用 concat() 方法,将要合并的表放入列表中作为参数
pd.concat([df1, df2])
- 1
应用到我们的例子中,完整代码如下:
import pandas as pd
df_a = pd.read_csv('2019年团队A销售数据.csv')
df_b = pd.read_csv('2019年团队B销售数据.csv')
df_c = pd.read_csv('2019年团队C销售数据.csv')
df_d = pd.read_csv('2019年团队D销售数据.csv')
df = pd.concat([df_a, df_b, df_c, df_d])
print(type(df))
# 输出:<class 'pandas.core.frame.DataFrame'>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
可以看到,合并后也是一个 DataFrame 类型的表格。

横向合并
除了表格的纵向合并,还有一种情况——表格的横向合并。
假设团队 A 的销售数据分为上半年和下半年的数据,两个表分别如下图所示:
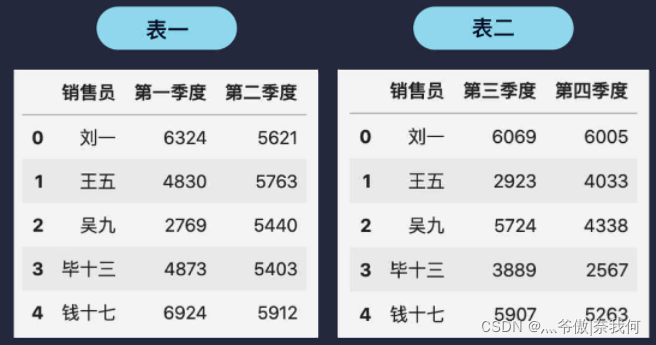
将这两个表格进行横向合并最简单的方法是 pd.merge(表一, 表二),合并后得到如下所示的新表:

上面的例子是 merge() 方法最简单的情况,只传入两个需要横向合并的表格作为参数。merge() 方法还有两个比较重要的参数分别是 on 和 how。
参数 on 表明用于合并的列名,可以使用列表指定多个列名,这些列名必须同时存在于两个表格当中。如果没有指定参数 on,那么 pandas 会自动将两个表格都有的列名作为参数 on 的值。
在上面的列子中参数 on 默认就是销售员,合并时 pandas 会将销售员这列值一样的行进行横向合并,并不是简单地按顺序合并,因此两张表的排列顺序不一样也能正确地进行合并。
上面例子中的两个表格情况比较简单,销售员都是一样的。假设刘一在第三四季度离职了,表格变成了下面这样:
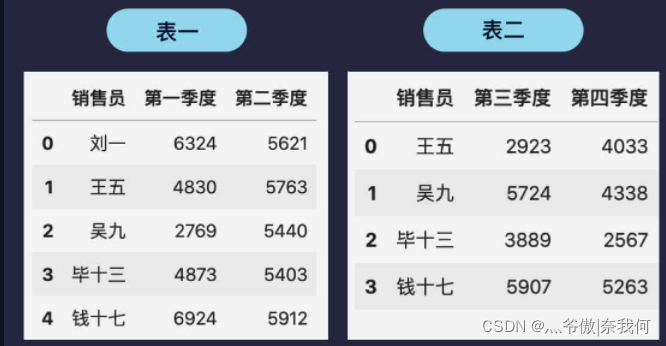
这时候,pd.merge(表一, 表二) 后的结果如下:
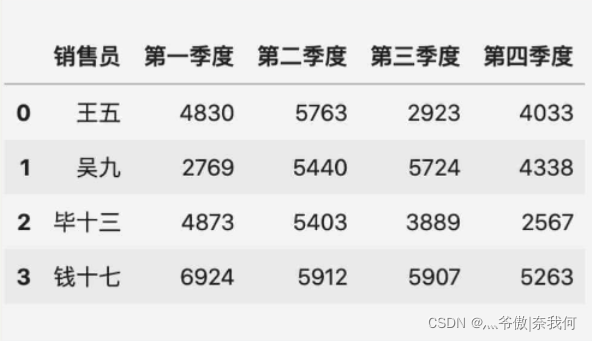
可以看到,合并后刘一的数据被剔除了,这其实是参数 how 导致的。参数 how 指定了合并的方式,总共有四种方式可选,默认为 inner。
- left
- right
- outer
- inner(默认)
inner(内连接)表示只保留参数 on 指定的列(上面的例子中是销售员)中两个表格都出现的部分。因为刘一只在表一中出现,因此合并后就剔除了刘一这行数据。
outer(外连接)和 inner 相反,它会保留两个表格中所有的数据,数据缺失部分以 NaN 填充。即以 NaN 填充上面的例子中刘一在第三四季度的数据。
注意,如果某列中用 NaN 补全了空位,那这一列数据就会变为浮点型数据。

left(左连接)表示将表二合并到表一中,具体指保留表一的全部数据,将表二中两表中共同的销售员数据进行合并,剔除表二中独有的数据。缺失数据同样也是用 NaN 填充。right(右连接)正好相反,表示将表一合并到表二中。

数据清洗
之前我们的数据都是很完整,格式也都是统一的。但有些时候,我们的数据可能存在部分缺失、格式不统一、甚至数据错误等情况。这时候这些数据就成了“脏”数据,我们需要对其进行数据清洗。
数据缺失是最常见的问题之一,导致这个问题的原因可能是:人工填写时遗漏、本身就没有这项数据等等。
我对豆瓣图书 Top250 数据进行了些删除,故意造成数据缺失,以便于我们对它进行数据清洗。
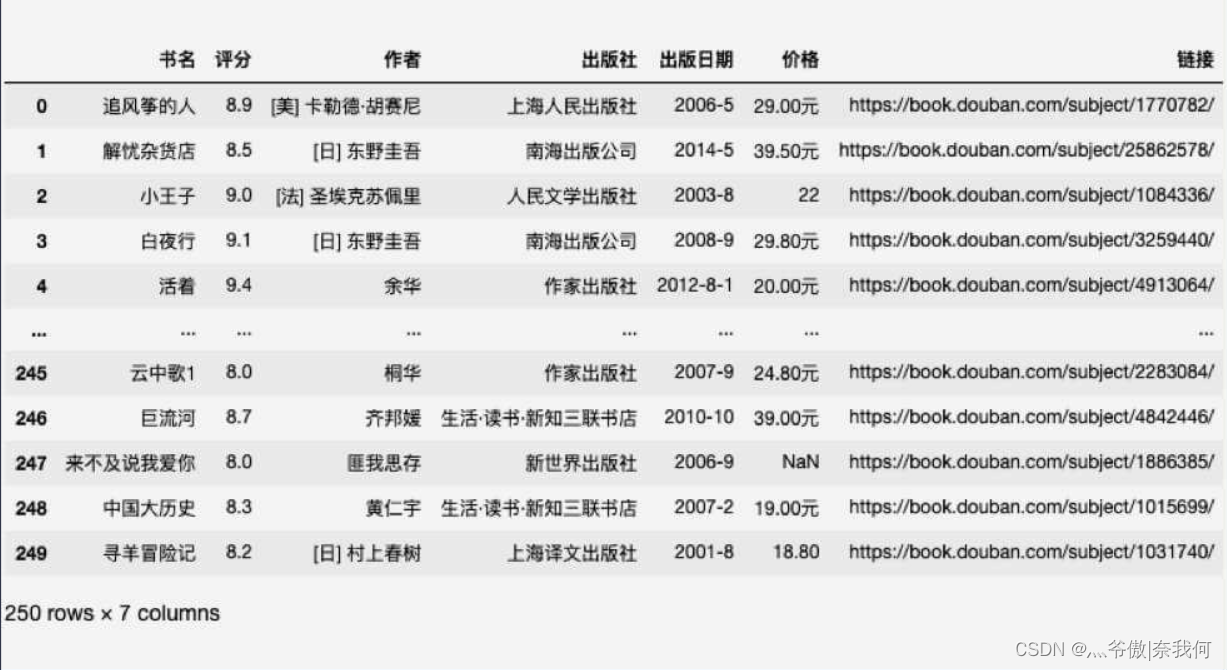
读取表格文件后,调用 info() 方法和 describe() 方法可以看到如下信息:
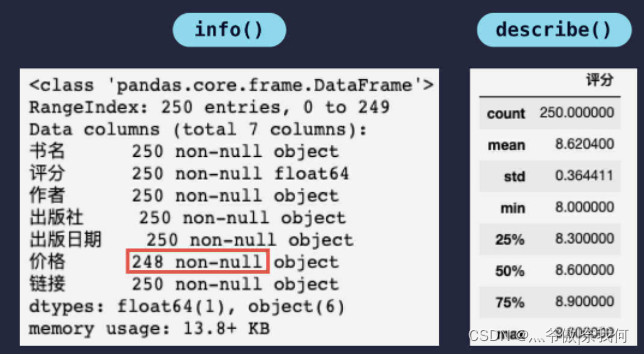
从中可知:总共 250 条数据,价格缺失了 2 条数据。数据缺失会引起后续数据分析的错误,常见的处理数据缺失的方法有 删除缺失数据行 和 为缺失数据赋值。
删除缺失数据行
假设我们认为有缺失数据的那一行数据都不可信,需要将其删除,只需一行代码即可:
df.dropna()
- 1
dropna() 方法的作用是删除所有包含 NaN 的行,执行后上表中数据缺失的那 2 行数据就会被删除。
dropna() 方法同样也是返回删除后的表格,不会对原表格有影响。如需直接在原表格上删除,传入 inplace=True 即可。
但上面的方法过于简单粗暴,可能只是一个不影响分析的数据缺失了,也会被无情地删除。所以我们要有策略地进行删除。
我们可以传入 how='all' 来控制当这一行数据都为 NaN 时才删除这一行。how 默认为 any,表示只要有一个 NaN 就会删除这一行。
df.dropna(how='all')
- 1
我们也可以传入 thresh 参数来控制当一行中非空值数量小于多少时才删除此行,比如当一行数据中,非空值数量小于 5 个时删除这一行,代码就可以这样写:
df.dropna(thresh=5)
- 1
当我们只想分析价格时,其他数据的缺失对我们的分析没有影响。这时可以通过 subset 参数决定哪几列有数据缺失时才进行删除。比如,当书名和价格这两列有数据缺失时可以这样写:
df.dropna(subset=['书名', '价格'])
- 1
综上:

数据填充
除了删除缺失数据行,有些情况下我们还能为缺失数据赋值。比如价格缺失了,我们可以将缺失价格设置为 0,方法如下:
df['价格'].fillna(0)
- 1
首先是选取有数据缺失的列,然后调用 fillna() 方法,该方法会将传入的参数填充到该列所有缺失的数据中。
我们同样可以传入 inplace=True 来直接更改原表格,pandas 中大部分方法都是返回修改后的表格,而不会修改原表格。我们都可以传入 inplace=True 来直接修改原表格,如果不想修改原表格,只需将修改后的表格保存到新的变量中即可。
但将缺失价格直接设成 0 并不是最优解,它会拉低整体的价格。我们可以将其设置成比较接近的值,比如价格的平均值:
df['价格'].fillna(df['价格'].mean())
- 1
像这样处理后,数据的偏差会小一些。上面的代码是理想情况,实际上会报错。为什么呢?我们再来看一下我们的数据表格。

可以看到,除了数据缺失知道,价格这一列的数据格式还不统一。有的是整数,有的是小数,还有的后面加上了元。这样的数据我们也没有办法进行分析,需要将其格式统一。我们需要去除“元”字,再统一保留一位小数。
统一数据格式
首先是去除“元”字,这其实就是字符串处理。在 Python 中,可以使用 replace() 方法进行字符串替换。我们可以像下面这样去除“元”字:
'29.00元'.replace('元', '')
- 1
而在 pandas 中也有这些字符串方法,它藏在了 str 属性下面。所以在 pandas 中我们可以这么写:
df['价格'].str.replace('元', '')
- 1
先访问 str 属性,再调用里面的字符串方法。Python 里的字符串方法,比如 replace()、upper()、lower()、split() 等等在其中。
需要注意的是,因为字符串不可变,这些方法都只是返回新的数据,不会更改原字符串。因此,我们还需要像下面这样才能将原表格中价格这一列的数据替换成修改后的数据:
df['价格'] = df['价格'].str.replace('元', '')
- 1
这样处理完之后看上去是数字,但实际上类型还是字符串,我们需要使用 astype() 方法进行类型转换。价格是小数,所以我们将其转换成浮点数类型(float)。
df['价格'] = df['价格'].str.replace('元', '').astype('float')
- 1
对价格进行处理后的表格是这样的:
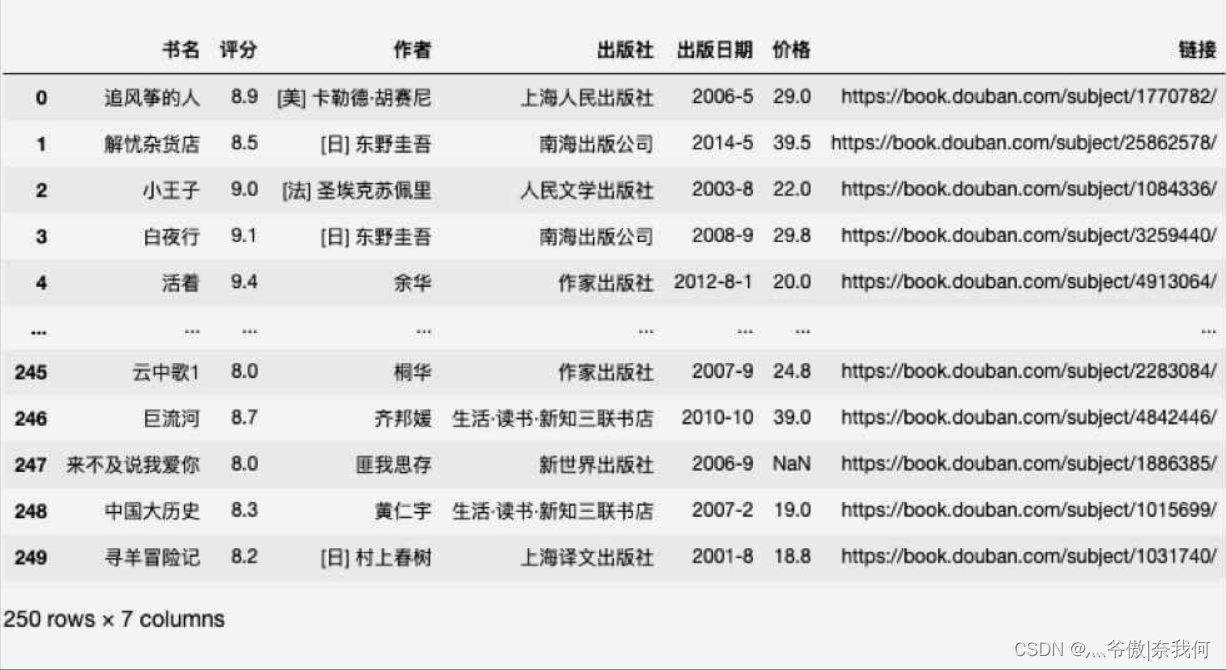
除了缺失数据还是 NaN,其他价格都统一成了保留一位小数的浮点数。这时我们再执行 df.describe() 看一下处理过后的数据:
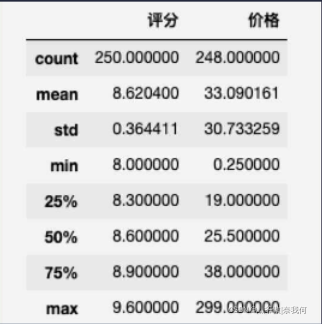
因为价格这一列被我们处理成数字了,所以统计信息中出现了价格相关的信息。并且这时再执行 df[‘价格’].fillna(df[‘价格’].mean()) 也不会报错了。
但算出来的平均价格是 33.090161,然而我们并不需要精确到小数点后这么多位。因此我们可以使用 round() 方法进行四舍五入,参数是要保留的小数位数。所以最后的代码如下:
df['价格'].fillna(df['价格'].mean().round(1), inplace=True) # 保留 1 位小数
- 1
去除重复数据
首先我们故意创建一个含有重复数据的表格进行演示:
import pandas as pd
df = pd.DataFrame({'用户名': ['刘一', '陈二', '刘一', '张三'], '交易金额': [25.8, 15.5, 56.3, 46.2]})
repeat = pd.concat([df, df])
print(repeat)
- 1
- 2
- 3
- 4
- 5
用户名 交易金额
0 刘一 25.8
1 陈二 15.5
2 刘一 56.3
3 张三 46.2
0 刘一 25.8
1 陈二 15.5
2 刘一 56.3
3 张三 46.2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
我将同一份表格进行了合并,得到了一个含有重复数据的表格。我们可以调用 drop_duplicates() 方法删除完全重复的行,即每一列的数据都完全相同的行。
print(repeat.drop_duplicates())
- 1
结果:
用户名 交易金额
0 刘一 25.8
1 陈二 15.5
2 刘一 56.3
3 张三 46.2
- 1
- 2
- 3
- 4
- 5
我们还可以通过 subset 参数指定按列去重,即只要这一列的数据重复就会删除重复的内容。
print(repeat.drop_duplicates(subset=['用户名']))
- 1
用户名 交易金额
0 刘一 25.8
1 陈二 15.5
3 张三 46.2
- 1
- 2
- 3
- 4
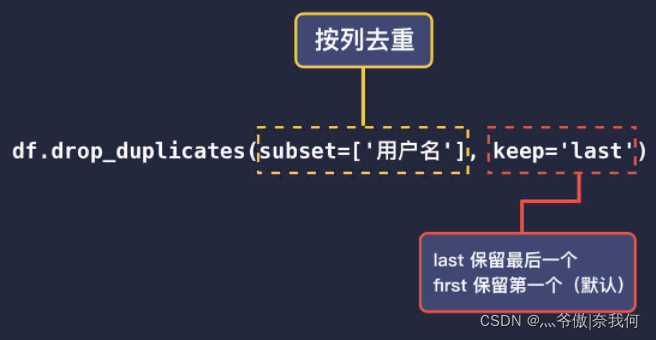
可以看到,按照用户名进行去重刘一的两条记录只剩一条了。去重默认是保留第一条不重复的数据,如果你想保留最后一条不重复的数据,可以传入 keep='last'。
print(repeat.drop_duplicates(subset=['用户名'], keep='last'))
- 1
用户名 交易金额
1 陈二 15.5
2 刘一 56.3
3 张三 46.2
- 1
- 2
- 3
- 4
假设数据的顺序是按交易时间排的,上面的代码就能得到每个用户最近一次的交易记录。
前面说的是如何去重,那么我们想要知道不重复的数据有哪些该怎么办呢?其实也很简单,只要在对应的列上调用 unique() 方法即可。
print(repeat['用户名'].unique())
# 输出:['刘一' '陈二' '张三']
print(len(repeat['用户名'].unique()))
# 输出:3
- 1
- 2
- 3
- 4
- 5
可以看到,总共 8 条数据交易记录,实际上只是 3 名用户产生的交易。除了使用 len(repeat[‘用户名’].unique()) 统计不重复的个数之外,我们也可以直接使用 nunique() 方法得到它。
print(repeat['用户名'].nunique())
# 输出:3
- 1
- 2
综上:

pandas 中很实用的方法——apply() 方法
apply() 方法的第一个参数是一个函数,当我们传入函数后,apply() 方法会将该函数应用到表格列里的每一个数据中,并将表格数据作为参数传给函数。(有点映射的味道)
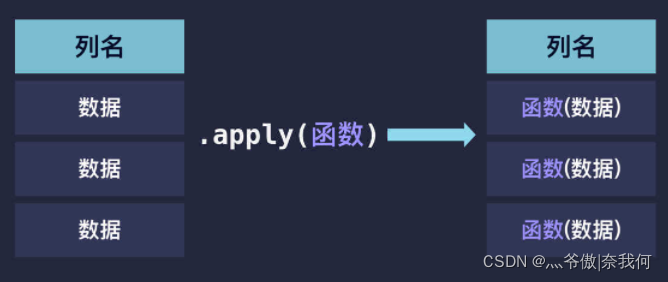
比如:
# 没使用apply() 方法
df['价格'] = df['价格'].str.replace('元', '').astype('float')
# 使用了apply() 方法
def format_price(x):
return float(x.replace('元', ''))
df['价格'] = df['价格'].apply(format_price)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
看上去代码更多了,但只是定义函数比较长。我们使用匿名函数的话也可以一行搞定:
f['价格'] = df['价格'].apply(lambda x: float(x.replace('元', '')))
- 1
之前我们使用的是 pandas 中的方法进行数据处理的,前提是你得先知道有 str 属性、astype() 方法等。而使用 apply() 方法则很灵活,我们可以直接获取到数据,使用 Python 的方式进行处理。同时处理的规则可以非常灵活,只要按需求定义一个函数即可。
附:匿名函数
Python 中的匿名函数:

下面这张是匿名函数和普通函数的对比图:

使用匿名函数并不能提高代码的运行效率,只是让代码看上去更加的简洁而已。有些只会用一次的函数,不知道如何给它命名时,直接用匿名函数会很方便。
我们还可以将匿名函数赋值给变量,这样匿名函数也拥有了姓名。
文章来源: blog.csdn.net,作者:十八岁讨厌编程,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/zyb18507175502/article/details/122730014

- 点赞
- 收藏
- 关注作者
评论(0)