一零一九、岗位数据分析(Spark)

【摘要】
目录
建表语句
原始数据
数据分析
完整代码
分析岗位数据如下要求:
分析不同学历的平均薪资(每个学历的平均估值(最高薪资平均值、最低薪资平均值求平均)
分析不同岗位的平均薪资(求每个学历的平均估值(最高薪资平均值、最低薪资平均值求平均)
分析各公司提供的岗位
建表语句
DROP TABLE I...
目录
分析岗位数据如下要求:
分析不同学历的平均薪资(每个学历的平均估值(最高薪资平均值、最低薪资平均值求平均)
分析不同岗位的平均薪资(求每个学历的平均估值(最高薪资平均值、最低薪资平均值求平均)
分析各公司提供的岗位
建表语句
-
DROP TABLE IF EXISTS `job`;
-
CREATE TABLE `job` (
-
`address` varchar(255) DEFAULT NULL,
-
`company` varchar(255) DEFAULT NULL,
-
`edu` varchar(255) DEFAULT NULL,
-
`jobName` varchar(255) DEFAULT NULL,
-
`salary` varchar(255) DEFAULT NULL,
-
`size` varchar(255) DEFAULT NULL
-
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
原始数据

数据分析
1、获取原始数据
-
val source: RDD[Row] = sprak.read
-
.format("jdbc")
-
.option("url", "jdbc:mysql://localhost:3306/crawler")
-
.option("dbtable", "job")
-
.option("user", "root")
-
.option("password", "123456")
-
.load()
-
.rdd
-
source.foreach(println)

可见,题目要求为最低工资平均值 与 最高工资平均值,先对数据格式进行处理一下
2、格式化数据
-
val data: RDD[(String, String, String, String, Float, Float, String)] = source.map(item => {
-
val salary: Any = item(4)
-
val min: String = salary.toString.split("-")(0)
-
val minsalary: String =
-
if (min.contains("面议")) min.substring(4)
-
else min
-
val max: Int = salary.toString.split("-")(1).length - 1
-
val maxsalary: String = salary.toString.split("-")(1).substring(0, max)
-
(item(0).toString, item(1).toString, item(2).toString, item(3).toString, minsalary.toFloat, maxsalary.toFloat, item(5).toString)
-
})
-
-
data.foreach(println)
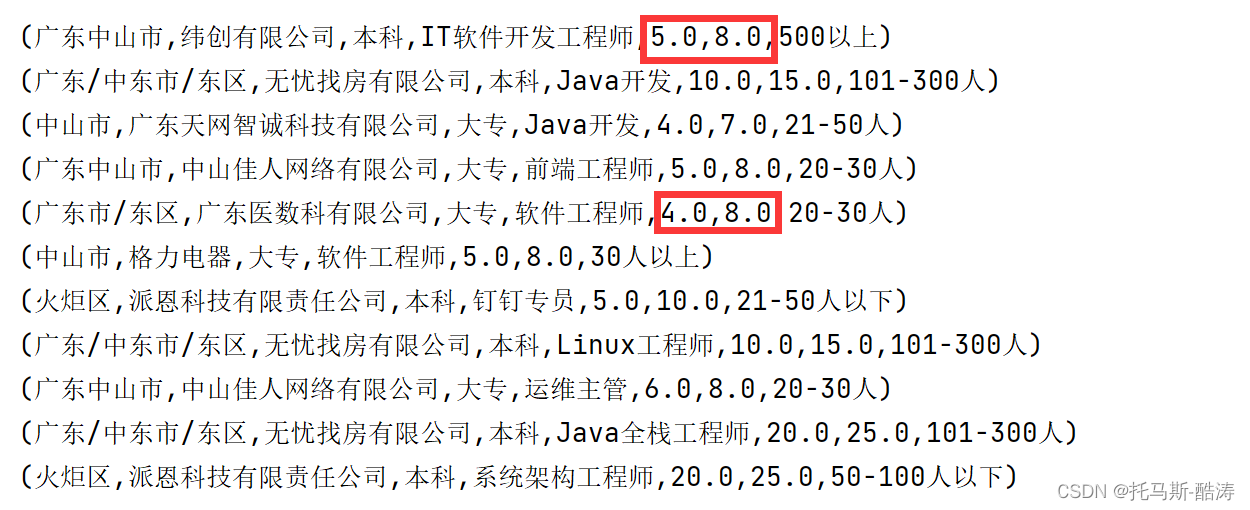
处理完数据后如图,并将其转为小数,方便后续运算
3、转为DF,创建表
-
import sprak.implicits._
-
val dataDF: DataFrame = data.toDF("address", "company", "edu", "jobName", "minsalary", "maxsalary", "size")
-
-
dataDF.createOrReplaceTempView("salary")
4、分析不同学历的平均薪资(每个学历的平均估值(最高薪资平均值、最低薪资平均值求平均))
-
val sql1 =
-
"""
-
|select s.edu,(s.avg_minsalary + s.avg_maxsalary)/2 as avgSalary from
-
|(select edu,avg(minsalary) as avg_minsalary,avg(maxsalary) as avg_maxsalary from salary group by edu) s
-
|""".stripMargin
-
-
sprak.sql(sql1).show()

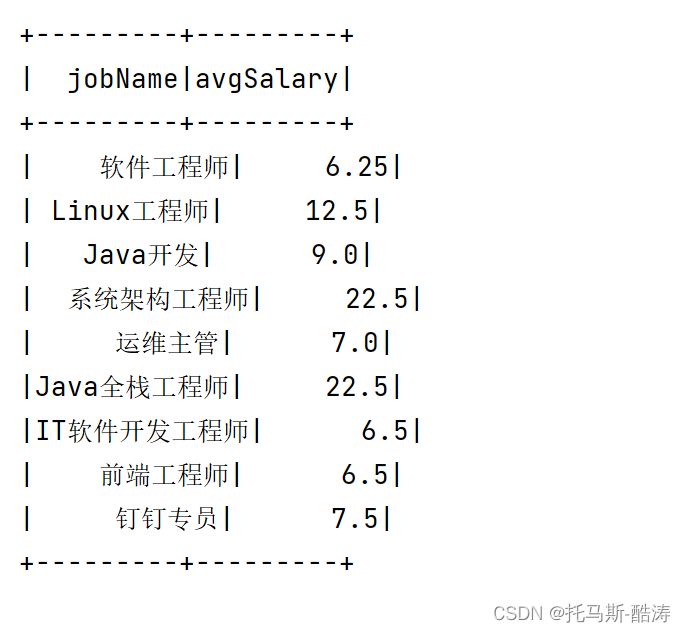
5、分析不同岗位的平均薪资(求每个学历的平均估值(最高薪资平均值、最低薪资平均值求平均))
-
val sql2 =
-
"""
-
|select s.jobName,(s.avg_minsalary+s.avg_maxsalary)/2 as avgSalary from
-
|(select jobName,avg(minsalary) as avg_minsalary,avg(maxsalary) as avg_maxsalary from salary group by jobName) s
-
|""".stripMargin
-
-
sprak.sql(sql2).show()
6、分析各公司提供的岗位
-
val sql3 =
-
"""
-
|select company,count(jobName) as jobNum from salary group by company
-
|""".stripMargin //分析不同岗位的平均薪资
-
-
sprak.sql(sql3).show()

完整代码
-
package example.spark.test
-
-
import org.apache.spark.rdd.RDD
-
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
-
-
-
object WordCount {
-
def main(args: Array[String]): Unit = {
-
val sprak: SparkSession = SparkSession.builder().master("local[6]").appName("job")
-
.config("spark.sql.warehouse.dir", "E:/")
-
.getOrCreate()
-
-
sprak.sparkContext.setLogLevel("ERROR")
-
-
val source: RDD[Row] = sprak.read
-
.format("jdbc")
-
.option("url", "jdbc:mysql://localhost:3306/crawler")
-
.option("dbtable", "job")
-
.option("user", "root")
-
.option("password", "123456")
-
.load()
-
.rdd
-
source.foreach(println)
-
println("------------------------------------------------------------------------------------")
-
// val data: RDD[(String, String, String, String, Float, Float, String)] = source.map(item => {
-
// var salary = item(4)
-
// val minsalary: String = if (salary.toString.split("-")(0).contains("面议"))
-
// salary.toString.split("-")(0).substring(4)
-
// else salary.toString.split("-")(0)
-
// val maxsalary: String = salary.toString.split("-")(1).substring(0, salary.toString.split("-")(1).length - 1)
-
// (item(0).toString, item(1).toString, item(2).toString, item(3).toString, minsalary.toFloat, maxsalary.toFloat, item(5).toString)
-
// })
-
val data: RDD[(String, String, String, String, Float, Float, String)] = source.map(item => {
-
val salary: Any = item(4)
-
val min: String = salary.toString.split("-")(0)
-
val minsalary: String =
-
if (min.contains("面议")) min.substring(4)
-
else min
-
val max: Int = salary.toString.split("-")(1).length - 1
-
val maxsalary: String = salary.toString.split("-")(1).substring(0, max)
-
(item(0).toString, item(1).toString, item(2).toString, item(3).toString, minsalary.toFloat, maxsalary.toFloat, item(5).toString)
-
})
-
-
data.foreach(println)
-
println("------------------------------------------------------------------------------------")
-
-
import sprak.implicits._
-
val dataDF: DataFrame = data.toDF("address", "company", "edu", "jobName", "minsalary", "maxsalary", "size")
-
-
dataDF.createOrReplaceTempView("salary")
-
-
val sql1 =
-
"""
-
|select s.edu,(s.avg_minsalary + s.avg_maxsalary)/2 as avgSalary from
-
|(select edu,avg(minsalary) as avg_minsalary,avg(maxsalary) as avg_maxsalary from salary group by edu) s
-
|""".stripMargin
-
-
sprak.sql(sql1).show()
-
println("------------------------------------------------------------------------------------")
-
val sql2 =
-
"""
-
|select s.jobName,(s.avg_minsalary+s.avg_maxsalary)/2 as avgSalary from
-
|(select jobName,avg(minsalary) as avg_minsalary,avg(maxsalary) as avg_maxsalary from salary group by jobName) s
-
|""".stripMargin
-
-
sprak.sql(sql2).show()
-
println("------------------------------------------------------------------------------------")
-
val sql3 =
-
"""
-
|select company,count(jobName) as jobNum from salary group by company
-
|""".stripMargin //分析不同岗位的平均薪资
-
-
sprak.sql(sql3).show()
-
-
-
}
-
}

文章来源: tuomasi.blog.csdn.net,作者:托马斯-酷涛,版权归原作者所有,如需转载,请联系作者。
原文链接:tuomasi.blog.csdn.net/article/details/126039041

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)