【高并发实战】千万级购物车系统缓存架构方案


前言:📫 作者简介:小明java问道之路,专注于研究计算机底层,就职于金融公司后端高级工程师,擅长交易领域的高安全/可用/并发/性能的设计和架构📫
🏆 Java领域优质创作者、阿里云专家博主、华为云专家🏆
🔥 如果此文还不错的话,还请👍关注、点赞、收藏三连支持👍一下博主哦
本文导读
本文主要介绍redis在千万级系统中设计架构方案,包括主架构设计、缓存一致性方案、大value处理方案和redis限流和故障恢复降级方案
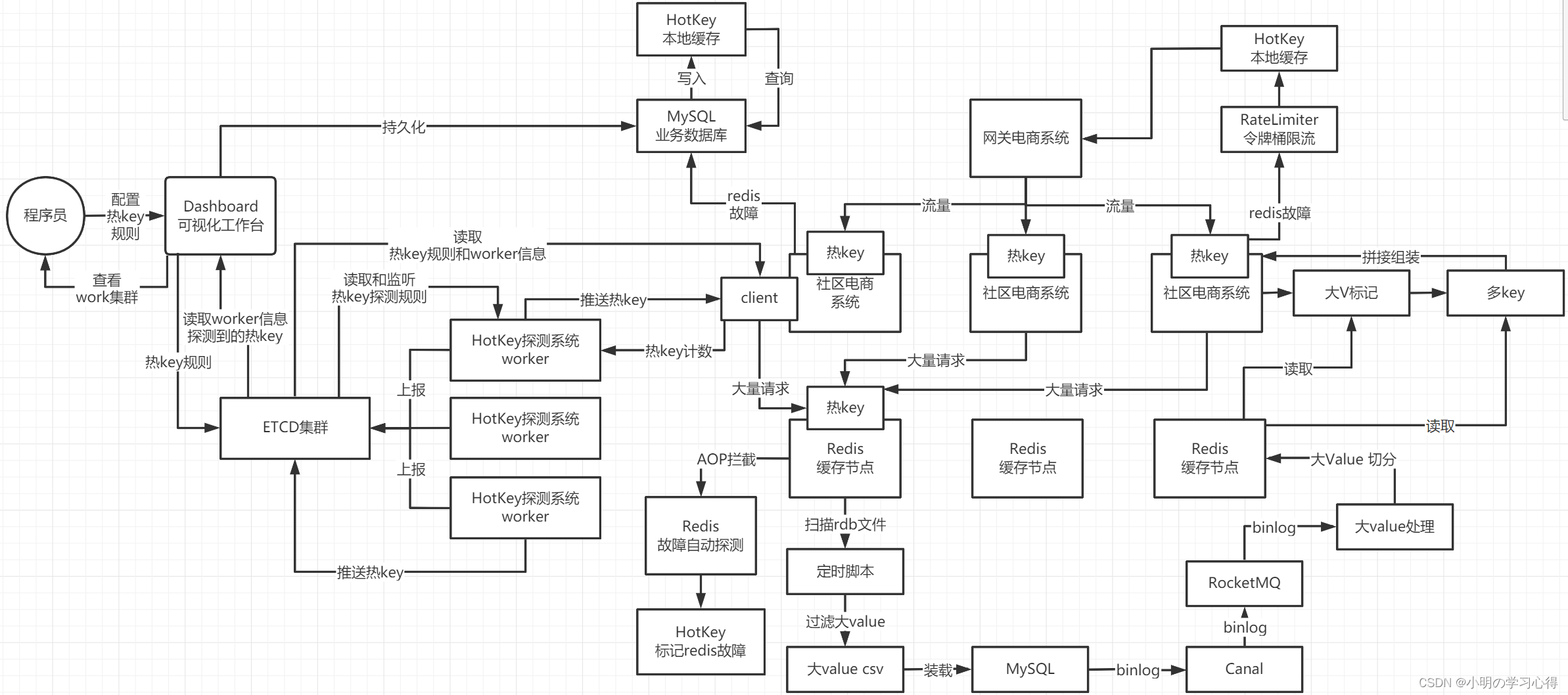
缓存架构主架构图:
主架构中包括缓存集群、缓存限流、缓存大value处理、HotKey探测系统、redis故障恢复降级和redis-mysql数据同步
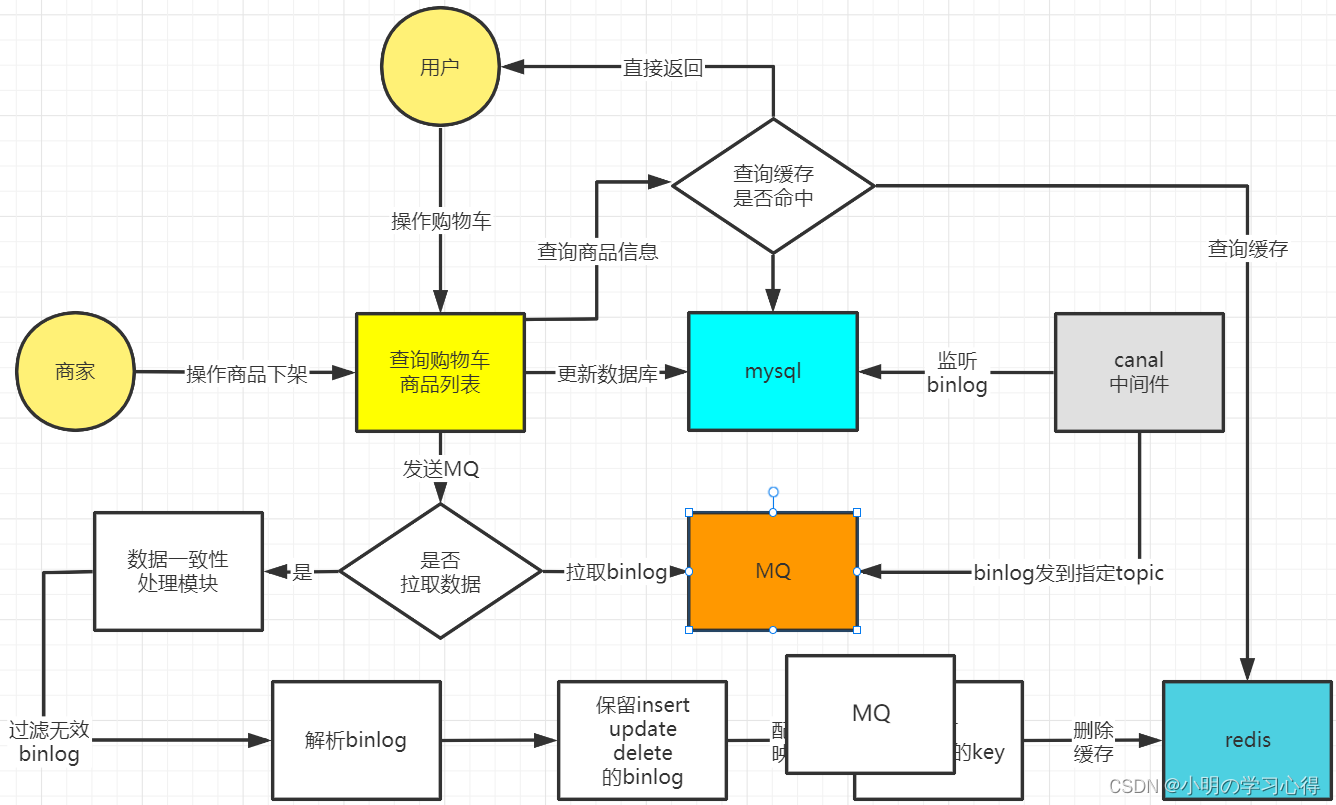
缓存一致性解决方案:
一、对于所有的DB操作都不去添加具体的删除缓存的操作,而是通过canal监听binlog的方式
二、待数据确认已提交到数据库后,通过监听的变化,解析出对应的数据后,过滤掉非增删改的
binlog
三、然后通过常量类配置的需要处理数据一致性的相关表以及关键字段和缓存前缀key,进行组装出需要进行删除的缓存key。并且通过mq的ack机制来保证缓存一定会被删除掉。
缓存限流解决方案:
防止redis崩溃之后,系统无法正常运转,所以我们需要做一个降级处理。
系统操作redis的所有方法一般都是通过RedisCache和Redislock两个类来处理的,所以我们通过AOP切面的方式,对这两个类中的所有方法做一个切面,如果在这里执行redis操作的时候,redis挂掉了,连接失败了,那么方法会抛异常,我们在切面处理方法上,捕捉异常,然后记录一下是redis挂掉还是网络暂时的波动
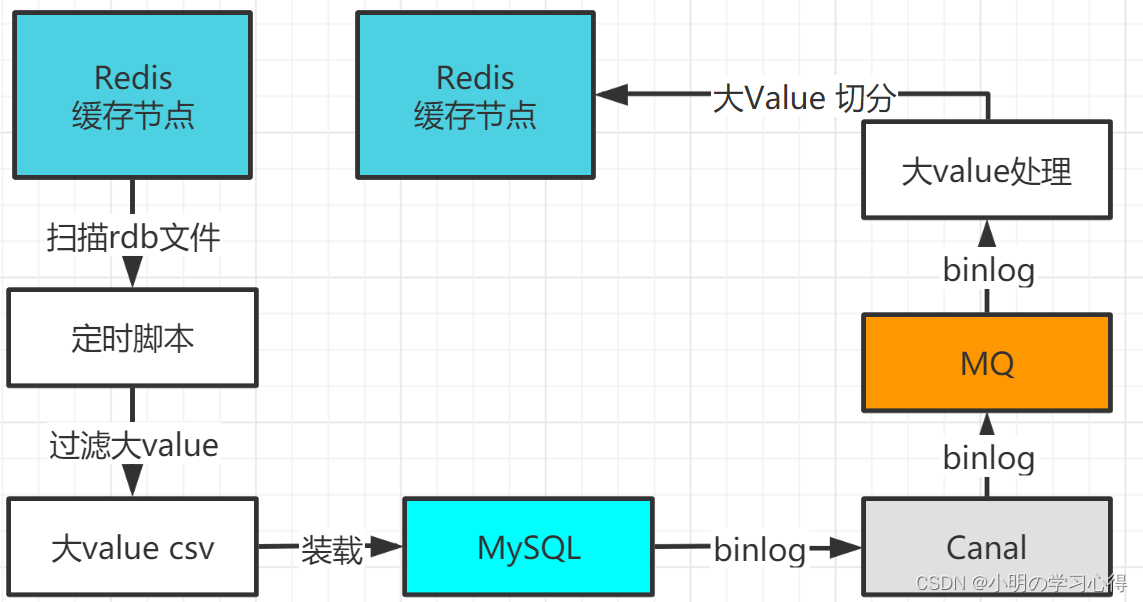
大Value处理方案:
一、搭建的redis集群
二、在canal中已经创建好了监听,存储到mysql中redis_large_key_log表的canal instance
三、在每天凌晨3点,会将Redis中的大key(value)数据,通过canal instance发送到 MQ
四、消费redis_large_key_log表的binlog数据,该数据包含Redis的大key(value)信息
五、将大value切分成多个key,返回时拼接组装

- 点赞
- 收藏
- 关注作者
评论(0)