一文搞定C语言函数和函数递归(和bug郭一起学C系列)

写在前面
本章主要带大家掌握函数的基本使用和递归!
本文带你搞定C语言函数和递归,函数和递归并不难,让我们一起加油!
@TOC
函数的概念
什么是函数呢?
是和数学里学的函数一样吗?
数学里的函数,具有对应关系和某种功能!
你了解C语言函数吗?维基百科中,C语言函数又叫做:子程序!
- 在计算机科学中,子程序(英语:Subroutine, procedure, function, routine, method,
subprogram, callable unit),是一个大型程序中的某部分代码, 由一个或多个语句块组
成。它负责完成某项特定任务,而且相较于其他代 码,具备相对的独立性。- 一般会有输入参数并有返回值,提供对过程的封装和细节的隐藏。这些代码通常被集成为软
件库。- 函数在面向过程的语言中已经出现。是结构(Struct)和类(Class)的前身。本身就是对具有相关性语句的归类和对某过程的抽象。
让我们来看看我们最熟悉的主函数!
int main()
{
//里面多条语句块组成!
//具有独立性!
}
还有函数的其他特性,我们学完这一章节再来总结一下!
C语言函数的分类
- 库函数
库函数就是我们直接可以使用的函数,像printf,scanf,strlen....等等,C语言函数库里已经实现好了,且具有某些功能的函数!我们直接拿来用就好了,但是前提我们得引该函数所在函数库的头文件,也就是我们之前比喻的:用别人的东西,我们要打招呼!我们包含一下这个头文件就可以使用该函数了!
#include<stdio.h>
int main()
{
printf("hhh");
//该函数的使用要引头文件<stdio.h>
}
- 自定义函数
自定义函数,顾名思义就是自己定义函数!
当我们要实现某种功能时,函数库中没有相应函数能够具有这种功能,那我们只能自己写一个具有该功能的函数了。
int Add(int a,int b)
{
return a+b;
}
int main()
{
int a=1,b=3;
int c=Add(); //自定义加法功能的函数!
}
该函数的细节,我们稍后学习,我们只要知道,这就是自定义函数就OK!
库函数
为什么会有库函数?
- 我们知道在我们学习C语言编程的时候,总是在一个代码编写完成之后迫不及待的想知道结果,想把这个结果打印到我们的屏幕上看看。这个时候我们会频繁的使用一个功能:将信息按照一定的格式打印到屏幕(
printf)。
#include<stdio.h>
int main()
{
printf("搞定C语言函数和函数递归");
return 0;
}
- 在编程的过程中我们会频繁的做一些字符串的拷贝工作(
strcpy)。
#include<string.h>
int main()
{
char arr1[]="abcdefg";
char arr2[]="xxx";
strcpy(arr1,arr2);
//将arr2拷贝到arr1中!
}
- 在编程是我们也计算,总是会计算n的k次方这样的运算(
pow)。
#include<math.h>
int main()
{
int n=2;
int k=3;
int x=pow(n,k);
//计算n的k次方!
return 0;
}
像上面我们描述的基础功能,它们不是业务性的代码。我们在开发的过程中每个程序员都可能用的到,为了支持可移植性和提高程序的效率,所以C语言的基础库中提供了一系列类似的库函数,方便程序员进行软件开发。
不同函数可能写在不同的函数库中,我们需要引用不同的函数库!
那我们该怎么学习库函数呢?
这里我给大家推荐一个学习和查阅函数库的网站:www.cplusplus.com建议收藏!
让我们一起来看看吧!

C library就是C语言函数库!

注:C语言函数库,如果要在C++代码中引用,就将函数库名加个C
这就是函数库的目录!点击就可以打开该函数库进行该函数库中函数学习和查阅!
 也可以点击搜索,输入函数名,查阅学习!
也可以点击搜索,输入函数名,查阅学习!
简单的总结,C语言常用的库函数都有:
- IO函数
- 字符串操作函数
- 字符操作函数
- 内存操作函数
- 时间/日期函数
- 数学函数
- 其他库函数
我们参照网站文档,学习几个库函数


我们学习一个函数,首先我们应该知道,该函数的作用
Fill block of memory
Sets the first num bytes of the block of memory pointed by ptr to the specified value (interpreted as an unsigned char).
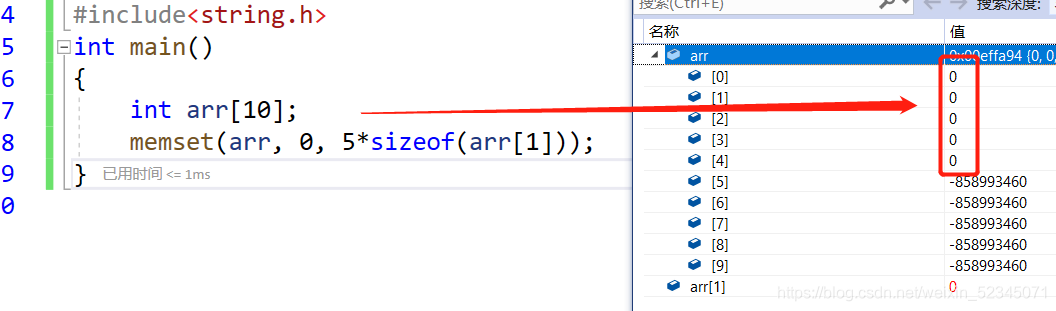
这就是memseth函数的作用,将ptr指针地址的空间,num个字节,初始化为value值!
然后我们在看看f返回值,每个参数的细节,还有所在库函数!
void * memset ( void * ptr, int value, size_t num ); <string.h>
可以知道该函数的返回值是void(空)。
ptr是一个void类型的指针。
value是int类型的值,
num是字节个数。
还有一些相关细节描述,就可以参考文档学了。
我们就可以使用该函数了!
库函数的学习就介绍到这里,可以利用网站文档自行学习!http://www.cplusplus.com/
自定义函数
如果库函数能干所有的事情,那还要程序员干什么?
所有更加重要的是自定义函数。
自定义函数和库函数一样,有函数名,返回值类型和函数参数。 但是不一样的是这些都是我们自己来设计。这给程序员一个很大的发挥空间。
函数的组成:
ret_type fun_name(para1, * )
{
statement;//语句项
}
ret_type //返回类型
fun_name// 函数名
para1 //函数参数
我们举个例子,大家就懂了怎么自定义函数了!
写一个函数求两个数中的较小值!
int Min(int x,int y) //函数的定义
{
if(x<y)
return x;
else
return y;
}
int main()
{
int x=2;
int y=5;
int c = Min(x,y); //函数的调用
return 0;
}
在Min调用函数中,函数的参数是x,y叫做实际参数,我们将x,y传给函数,然后,函数就会接收,创建了int x,int y来接收实际参数,(int x,int y)是形式参数!是x,y的临时拷贝!而int c= Min(x,y);就是将函数返回值,我们要求的最小值接收。而且类型要一致!
我们再来写个函数!
交换两数
void Exchange1(int a,int b) //函数的定义
{
int c=0;
c=a;
a=b;
b=c;
}
int main()
{
int a=2;
int b=3;
printf("a=%d b=%d\n",a,b);
Exchange1(a,b);//函数的调用
printf("a=%d b=%d",a,b);
}

我们看运行结果,并没有实现两数的交换为啥会这样呢?你可以调试一下!
我们再用另一种方式写这个代码!
void Exchange2(int* a,int* b) //函数的定义
{
int c = 0;
c = *a;
*a = *b;
*b = c;
}
int main()
{
int a=2;
int b=3;
printf("a=%d b=%d\n",a,b);
Exchange2(&a,&b);//函数的调用
printf("a=%d b=%d",a,b);
}

为啥将实际参数a,b改成&a,&b指针就能实现两数的交换!
我们学习函数的参数就知道了!
函数的参数
实际参数(实参):
真实传给函数的参数,叫实参。实参可以是:常量、变量、表达式、函数等。无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。
形式参数(形参):
形式参数是指函数名后括号中的变量,因为形式参数只有在函数被调用的过程中才实例化(分配内存单元),所以叫形式参数。形式参数当函数调用完成之后就自动销毁了。因此形式参数只在函数中有效。
上面Exchange1和Exchange2函数中的参数a,b,a,b都是形式参数。在main函数中传给Exchange1的a,b和传给Exchange2函数的&a,&b是实际参数。
Exchange1调试过程!
 我们已经看到,在函数内
我们已经看到,在函数内a和b已经交换了,但是为什么,出了函数却没有达到交换的效果呢?

出函数后,a和b还是原来的值!
Exchange2调试过程


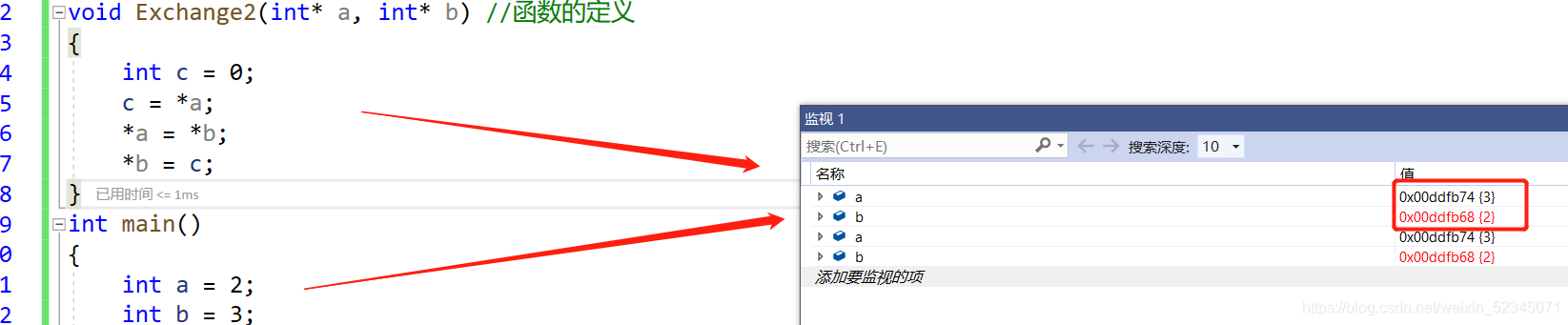
这里可以看到Exchange函数在调用的时候,a,b拥有自己的空间,同时拥有了和实参一模一样的内容。所以我们可以简单的认为:形参实例化之后其实相当于实参的一份临时拷贝!
函数的调用
传值调用
函数的形参和实参分别占有不同内存块,对形参的修改不会影响实参。
Exchange1就是传值调用!
传址调用
传址调用是把函数外部创建变量的内存地址传递给函数参数的一种调用函数的方式。
这种传参方式可以让函数和函数外边的变量建立起正真的联系,也就是函数内部可以直接操作函数外部的变量。
Exchange2就是传址调用!
总结
如果我们要改变实参的值,我们就应该传递实参的地址,也就是传址调用!而传值调用,不会改变实参的值,因为形参只是实参的一份临时拷贝!
学到这,我们就可以尝试自己写几个函数了!
- 写一个函数可以判断一个数是不是素数。
- 写一个函数判断一年是不是闰年。
- 写一个函数,实现一个整形有序数组的二分查找。
写完了吗?来看看我写的吧!
//1.判断闰年
int is_leapyear(int x)
{
if (x % 4 == 0 && x % 100 != 0||x % 400 == 0)
return 1;
else
return 0;
}
//二分查找
int binary_search(int* arr, int sz,int x)
{
int left = 0,right = sz - 1;
while (left < right)
{
int mid = (left + right) / 2;
if (arr[mid] > x)
{
right = mid - 1;
}
else if(arr[mid]<x)
{
left = mid + 1;
}
else
{
return mid;
}
}
return -1;
}
//判断素数
int is_prime_number(int x)
{
if (x < 2)
return 0;
int i = 0;
for (i = 2; i <=sqrt(x); i++)
{
if (x % i == 0)
return 0;
}
return 1;
}
函数的嵌套调用和链式访问
函数和函数之间可以有机组合。
嵌套调用
void len_2()
{
printf("搞定C语言函数和递归!\n");
}
void len_1()
{
int i=0;
for(i=0;i<3;i++)
len_2();
}
int main()
{
len_1();
return 0;
}
这便是函数嵌套,len_1函数里面嵌套了len_2函数!
链式访问
把一个函数的返回值作为另外一个函数的参数。
#include<stdio.h>
#include<string.h>
int main()
{
char arr[10]="abcd";
char*arr1=strlen(strcat(arr,"efgh"));
printf("%s",arr1);
return 0;
}
注:strcat函数是将字符串"efgh"复制到arr1中,将arr的地址返回,strlen计算字符个数,细节请查阅文档!
所以strcat的返回值给了strlen函数,strlen函数的返回值,又给了printf函数,作为printf函数的参数!
我们再看个代码!
int main()
{
printf("%d",printf("%d",printf("%d",43)));
}
注:printf函数的返回值是打印的字符个数,所以运行结果是:
4321
函数的声明和定义
函数的声明
- 告诉编译器有一个函数叫什么,参数是什么,返回类型是什么。但是具体是不是存在,无关紧要。
- 函数的声明一般出现在函数的使用之前。要满足先声明后使用。
- 函数的声明一般要放在头文件中的。
函数定义:
函数的定义是指函数的具体实现,交待函数的功能实现。
#include<stdio.h>
//函数声明,告诉编译器存在这样一个函数
int Add(int x,int y);
int main()
{
return 0;
}
//函数定义,函数的具体实现
int Add(int x,int y)
{
return x+y;
}
上面是在一个文件中,并且我们知道函数先声明后使用!
其实我们也可以分文件进去函数的声明和定义!



头文件
.h文件,放函数的声明!
源文件.c文件,放函数的定义!
有人就会问了,搞这么多文件干嘛!自己一个文件不好吗?这多麻烦啊!
我们再想一个问题,如果我们以后工作,小组要一起写一个程序。如果只有一个源文件,我们如何分配工作?
一个人写完,再给下一个人?
显然这样是不合理的,所以,这时多文件的优势就来了!
我们可以分工合作,一个人写一个函数文件,然后在.h文件声明一下就可以了!
分文件书写形式还有一个优势!
利于函数的封装和隐藏!
当我们给别人写了个程序时,我们将这程序的功能卖给别人,而有些重要的代码,商业机密,不能给他们看到。这就可以利用分文件的优势了!我们只卖功能不卖代码!
我们团队要给客户写一个计算机功能的程序
操作如下:

写add函数功能的函数库!
创建一个文件add
 写一个
写一个add.h的头文件和add.c的源文件
再将文件属性,配置类型,改成静态库(.lib)

编译一下就生成一个.lib的文件!找到.lib文件和add.h文件打包卖给客户!

test_7_24.5就是客户,买到了add.lib文件和add.h文件!

我们将静态库Add.lib引用声明一下,便可以使用了!
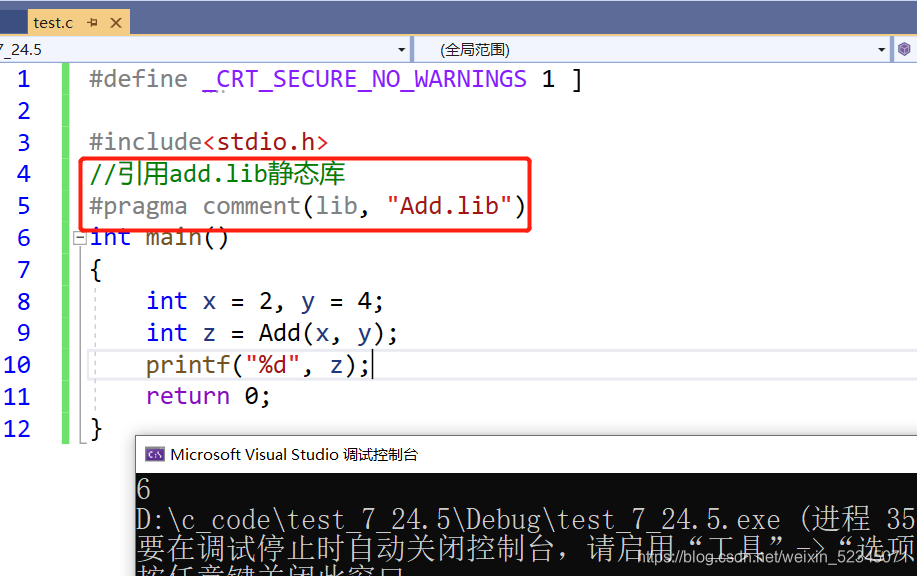
学会了吗!快去试试吧!

函数的递归
什么是递归?
程序调用自身的编程技巧称为递归(recursion)。 递归做为一种算法在程序设计语言中广泛应用。 一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的程序就可描述出解题过程所需要的多次重复计算,大大地减少了程序的代码量。 递归的主要思考方式在于:把****大事化小!
递归的两个必要条件
- 存在限制条件,当满足这个限制条件的时候,递归便不再继续。
- 每次递归调用之后越来越接近这个限制条件!
接受一个整型值,按照顺序打印它的每一位!例如:输入:1234 输出:1 2 3 4
#include <stdio.h>
void print(int n)
{
if(n>9) //限制条件
{
print(n/10); //接近限制条件
}
printf("%d ", n%10);
}
int main()
{
int num = 1234;
print(num);
return 0;
}
这就是使用函数递归解决该问题!

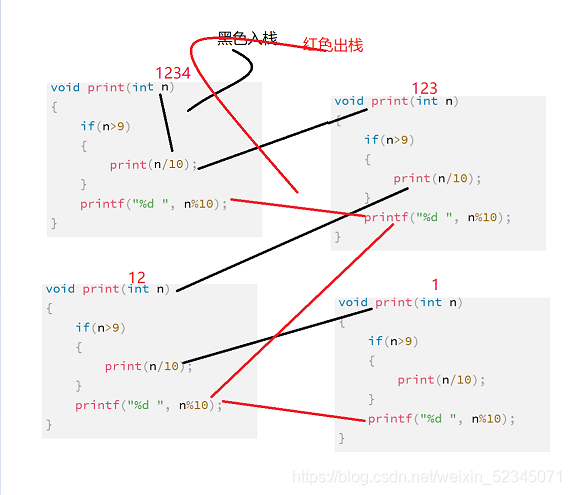
什么是入栈,出栈呢?

你是否想过,如果我们无限递归下去,一直开辟栈区的空间,是否会发生栈区内存空间不足!


所以递归的两个条件是很重要的!缺一不可,不然就会无限递归下去!
编写函数不允许创建临时变量,求字符串的长度。
这个题目怎么用递归实现呢?
我们要知道递归的思想就是大事化小!
让我我们多画图,便于学习递归思想!

int my_strlen(char* arr)
{
if(*arr!='\0') //限制条件
{
return 1+my_strlen(arr+1);
//调用接近限制条件
}
else
{
return 0;
}
}
#include<stdio.h>
int main()
{
char arr[]="abcdefg";
int len= my_strlen(arr);
return 0;
}

学会了吗!
你们可以尝试自己写几个递归的代码!
求n的阶乘。(不考虑溢出)
求第n个斐波那契数(不考虑溢出)
int factorial(int n)
{
if(n <= 1)
return 1;
else
return n* factorial(n-1);
}
int fib(int n)
{
if (n <= 2)
return 1;
else
return fib(n - 1) + fib(n - 2);
}
但是我们发现有问题;
在使用fib 这个函数的时候如果我们要计算第50个斐波那契数字的时候特别耗费时间。
使用factorial 函数求10000的阶乘(不考虑结果的正确性),程序会崩溃。
为什么呢?
我们发现fib 函数在调用的过程中很多计算其实在一直重复。 如果我们把代码修改一下!
int count = 0;//全局变量
int fib(int n)
{
if(n == 3)
count++;
if (n <= 2)
return 1;
else
return fib(n - 1) + fib(n - 2);
}
最后我们输出看看count,是一个很大很大的值。
那我们如何改进呢?
在调试factorial 函数的时候,如果你的参数比较大,那就会报错:stack overflow(栈溢出)这样的信息。 系统分配给程序的栈空间是有限的,但是如果出现了死循环,或者(死递归),这样有可能导致一直开辟栈空间,最终产生栈空间耗尽的情况,这样的现象我们称为栈溢出。
那如何解决上述的问题:
- 将递归改写成非递归。
- 使用static对象替代
nonstatic局部对象。在递归函数设计中,可以使用static对象替代nonstatic局部对象(即栈对 象),这不仅可以减少每次递归调用和返回时产生和释放nonstatic对象的开销,
而且static对象还可以保存递归调用的中间状态,并且可为各个调用层所访问。
你们可以试试!
int fib(int n)
{
if(n<3)
{
return 1;
}
else
{
int a=1;
int b=1;
int c=0;
while(n>2)
{
a=b;
b=c;
c=a+b;
n--;
}
return c;
}
}
提示:
3. 许多问题是以递归的形式进行解释的,这只是因为它比非递归的形式更为清晰。
4. 但是这些问题的迭代实现往往比递归实现效率更高,虽然代码的可读性稍微差些。
5. 当一个问题相当复杂,难以用迭代实现时,此时递归实现的简洁性便可以补偿它所带来的运行时开销。
所以要根据需要选择递归!
大佬多多指导,有赞必回,未完待续!

- 点赞
- 收藏
- 关注作者
评论(0)