什么是数据密集型应用的可扩展性

0 前言
硬件生产出来就不会再进行改变,而是会一直使用到它损坏或者性能跟不上。比如:芯片设计出来也不会再返厂增加新功能。这一点有点像建筑的整体架构,比如金字塔完工至今,仍然保留当初时的结构。
相比之下,软件系统则完全相反,原因如下:
-
如果一个软件系统没有更新和调整、迭代,说明系统没有发展。比如 Windows 系统从命令行工具发展到 95、XP、Win7、Win8、Win 10 到现在的 Win11。
-
即使软件系统现在的工作可靠,但不意味着将来能够保持正常运行。比如当负载增加,用户数从十万到千万,流量从百万到亿级流量。
软件系统天生和内在的可扩展的特性,即使魅力,也是难点。
魅力体现在通过修改、更新、扩展,不断增加新功能和特性,满足新需求,顺应新技术。难点体现在如果系统以某种方式增加,如何应对这种增长;如果添加计算资源来处理额外的负载;如果一处修改,是否会影响别处,重构的风险不言而喻。如何避免扩展时改动的范围太大,是可扩展性设计的主要思考点。
1 可扩展性
描述负载
负载可以用称为负载参数的若干数字来描述,参数的最佳选择取决于系统的体系结构,它可能是:
-
Web 服务器的每秒请求处理次数
-
数据库中写入的比例
-
聊天室的同时活动用户数量
-
缓存命中率
推特的案例研究
文章中举出了推特在可扩展性上的案例,比如推特主要有两个操作:
-
发布推特:用户可以快速推送新消息给所有的关注者,平均大约 4.6 k requests/sec,峰值约 12k requests/sec
-
主页时间线:查看关注对象的最新消息(平均 300k requests/sec )
具体可以看看这篇视频:Timelines at Scale
推特的可扩展挑战主要归咎于 fan-out,扇出 。在电子工程中,扇出指的输出是一个门连接到另一个输入门的数量。对于推特而言,每个用户都关注许多人(Watch),每个用户都会受到许多人的关注(Follower)。
加载某个用户关注者的所有推文的最佳方法是什么?可能会发生两个操作:
-
将发布的一条新推文插入全球推文集合中。该集合可能是一个关系数据库,然后可能会有数十亿行, 这种想法当然不理想。当用户查看时间线时,首先查找所有的关注对象,列出这些人所有的推文,最后以时间线来排序合并,类似可以参考如下的 SQL 查询语句:
SELECT tweets.*, users.* FROM tweets
JOIN users ON tweets.sender_id = users.id
JOIN follwers ON follows.followee_id = users.id
WHERE follows.follwer_id = current_user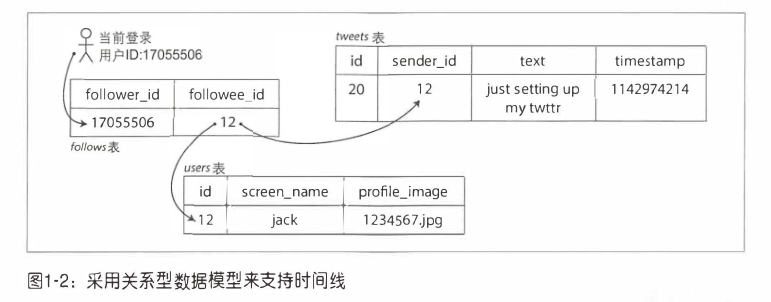
-
维护每个用户的时间线的缓存,类似设置一个用户推特邮箱,当用户推送新推特时,查询其关注者,将该推特插入到每个关注者的时间线缓存中,因为已经预先将该结果取出,而访问时间线的性能非常看。
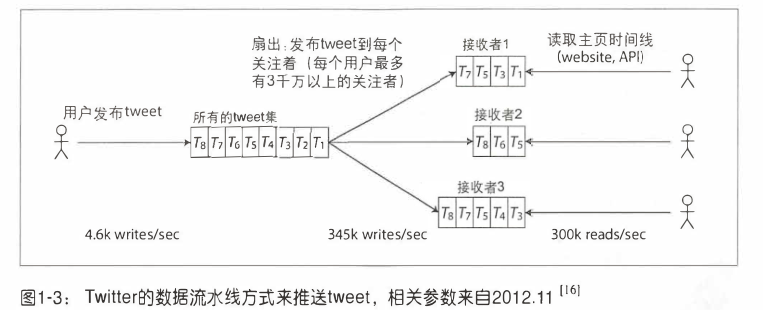
推特最初使用的是第一种方法,随着系统的增长,开始转向方法二。
总结
对千特定应用来说,扩展能力好的架构通常会做出某些假设,然后有针对性地优化设计,如哪些操作是最频繁的,哪些负载是少数情况。 如果这些假设最终发现是错误的,那么可扩展性的努力就白费了,甚至会出现与设计预期完全相反的情况。
而对于早期的初创公司或者尚未定型的产品,快速迭代推出产品功能往往比投入精力来应对不可知的扩展性更为重要。

- 点赞
- 收藏
- 关注作者
评论(0)