力扣刷题之数组序号计算(每日一题7/28)

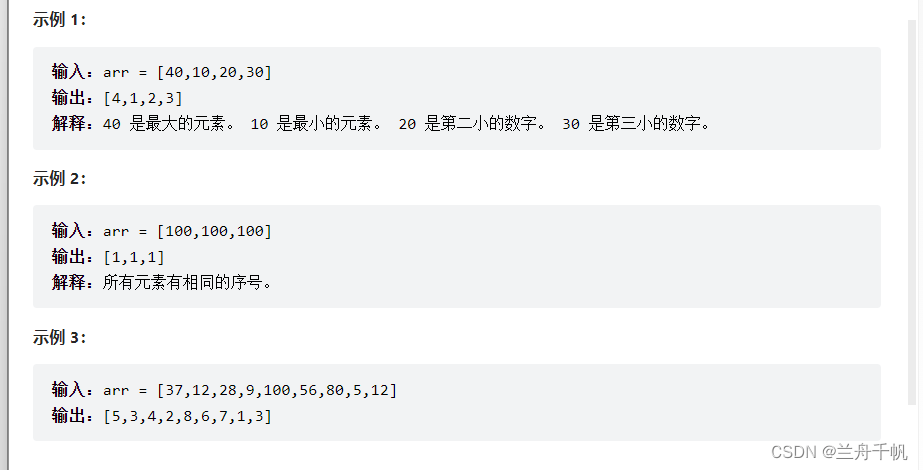
给你一个整数数组 arr ,请你将数组中的每个元素替换为它们排序后的序号。
序号代表了一个元素有多大。序号编号的规则如下:
序号从 1 开始编号。
一个元素越大,那么序号越大。如果两个元素相等,那么它们的序号相同。
每个数字的序号都应该尽可能地小。
力扣
链接
最后它给了一点提示

这个数据量是绝对会测试你的程序的算法执行效率的。单纯的用for循环做的话,不太行。下面给出自己之前一些愚蠢的尝试。下面这个也是可以去计算出来的,但是在大量数据面前就执行效率很慢,原因是for循环的过多使用。
class Solution {
public int[] arrayRankTransform(int[] arr) {
int i, j, k;
int arr_a[] = arr;
HashSet set = new HashSet<>();
// for (int i1 : arr_a) {
// System.out.println(i1);
//
// }
for (int x = 0; x < arr.length; x++) {
set.add(arr_a[x]);
}
Integer arr_b[] = (Integer[]) set.toArray(set.toArray(new Integer[]{}));
for (i = 0; i < arr_b.length - 1; i++) {
for (j = 0; j < arr_b.length - i - 1; j++) {
if (arr_b[j] > arr_b[j + 1]) {
k = arr_b[j];
arr_b[j] = arr_b[j + 1];
arr_b[j + 1] = k;
}
}
}
for (int i1 = 0; i1 < arr.length; i1++) {
for (int i2 = 0; i2 < arr_b.length; i2++) {
if (arr[i1] == arr_b[i2]) {
arr[i1] = i2 + 1;
break;
}
}
}
return arr;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
可笑的是,我明明都已经开始用集合了,后来又去用for循环了。
下面给出优化后的解题方法。我用了一个HashMap的数据结构。这个数据结构是双列数据结构。并且不会允许键重复,并且是散列的具有无序的特点。不过这个无所谓,我用这个数据结构的目的就是为了存储排序后的数组的值。来看具体怎么体现。
自己定义了数组进行的测试,在力扣提交的时候只需要将自己定义的重复的数组删掉,最后要返回一个最终的数组。
如下,首先对当前数组进行了排序,这个默认是从何小到大排序的,题目实际的要求也是这样,所以不用修改默认。
排序后的数组中的元素一定是按照顺序排列的,是从小到大排序的。
思路:用HashMap数据结构存储数组排序后的值,作为集合的键,集合的值可以自然增长。因为我们数组排序后是按从小到大排序,那么我们这样把它的从小到大的值对应到从小到大的索引值+1。其实可以让键对应的值从1开始变大就可以。因为我们最后排序的时候也是要1开始计算的。
class Solution {
public int[] arrayRankTransform(int[] arr) {
int[] arr_new = Arrays.copyOf(arr, arr.length);
Arrays.sort(arr);
HashMap<Integer, Integer> map = new HashMap<>();
// for (int i = 0; i < array.length; i++) {
// if(!map.containsKey(array[i]))
// {
// map.put(array[i],i+1);
// }
// }
//
for (int i : arr) {
//要保证不要存储重复的键,当然map本身也不允许重复,
//只是你如果进行存储重复的键的话,值得话会被覆盖。
//这样的话后面的排序就乱套了。题目要求的,如果两个数字一样的话,
//他们的最终替代的值也是一样的。所以我们只保留可能
//出现同样数字的一个值
if (!map.containsKey(i))
{
map.put(i,map.size()+1);
}
}
//下面我们进行一个重新的赋值,将排序替换掉原来的数字。
for (int i = 0; i < arr.length; i++) {
arr_new[i]= map.get(arr_new[i]);
}
return arr_new;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33

想想其中一段你会这样去写吗?这样写是不对的。如果出现相同的数,它其实是不要存储的,但是你的按照这个索引i还是会变大,这样是不对的。
for (int i = 0; i < array.length; i++) {
if(!map.containsKey(array[i]))
{
map.put(array[i],i+1);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
要用普通的for的话还是得这样写
for (int i = 0; i < arr.length; i++) {
if(!map.containsKey(arr[i]))
{
map.put(arr[i],map.size()+1);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
需要注意的是数组的拷贝,你会不会这样写?
这样写的话也可以获取到和原来数组一样的元素存储,但是如果你将来对摸一个数组排序的话,拎一个数组也会跟着变。因为这样的其实是一个指针的指向,指向原来数组的地址,当然一个数组变,另一个也会变。
这样你重新赋值的话就赋给位置不是原来的数了。
int[] arr_new = arr;
- 1
这是需要注意的地方。用hash集合操作的话其实还是效率比较高的。
基本上这个体无论怎么操作道理都是一样的。
文章来源: daodaozi.blog.csdn.net,作者:兰舟千帆,版权归原作者所有,如需转载,请联系作者。
原文链接:daodaozi.blog.csdn.net/article/details/126041477

- 点赞
- 收藏
- 关注作者
评论(0)