Python可视化数据分析05、Pandas数据分析


![]()
Python可视化数据分析05、Pandas数据分析
📋前言📋
💝博客:【】💝
✍本文由在下【红目香薰】原创,首发于CSDN✍
🤗2022年最大愿望:【服务百万技术人次】🤗
💝Python初始环境地址:【】💝
环境需求
环境:win10
开发工具:PyCharm Community Edition 2021.2
数据库:MySQL5.6
目录
DataFrame对象的sum()函数,返回一个含有列小计的Series对象
pip3 config set global.index-url https://repo.huaweicloud.com/repository/pypi/simple
pip3 config list
pip3 install --upgrade pip
pip3 install requests
pip3 install pandas
Pandas介绍
Pandas是Python的一个数据分析包,是基于NumPy的一种工具。
Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
使用Pandas,需要先熟悉它的两个主要数据结构:Series和DataFrame,它们为大多数应用提供了一种可靠、易于使用的基础。
Series
Series是一种类似于一维数组的对象,它由一组数据以及一组与之相关的数据标签(索引)组成,创建Series对象的语法如下:
#导入Pandas模块中的Series类
from Pandas import Series
#最简单的Series
Series对象名 = Series(列表)
#带有标记的索引
Series对象名 = Series(列表, index=索引的列表)
Demo1:
from pandas import Series
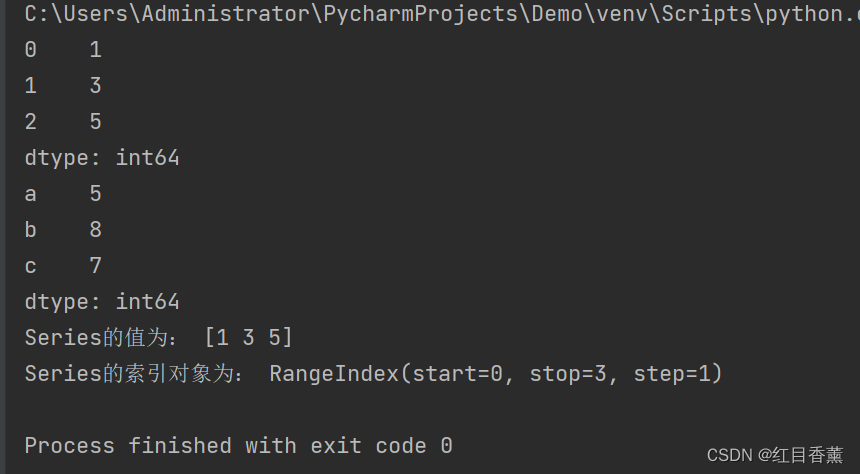
obj1 = Series([1, 3, 5]) # 最简单的Series对象
obj2 = Series([5, 8, 7], index=["a", "b", "c"]) # 带有对各个数据标记的索引
print(obj1)
print(obj2)
print("Series的值为:", obj1.values)
print("Series的索引对象为:", obj1.index)
![]()
Series对象的特性:
- 可以通过索引的方式选取Series中的单个或一组值。
- 对Series对象进行NumPy数组运算,都会保留索引和值之间的连接。
- 将Series看成是一个定长的有序字典,因为它是一个索引值到数据值的一个映射。
- 如果Series的值中出现NaN,可以利用Pandas模块中提供的isnull()和notnull()函数进行判断。
- 在算数运算中会自动对齐不同索引的数据。
- Series对象本身及其索引都有一个name属性,该属性跟Pandas其他的关键功能的关系非常密切。
- Series的索引可以通过赋值的方式修改。如果对象中有4个数据,索引赋值时也必须保证索引中有4个元素。
from pandas import Series
obj = Series([8, 6, -5, 2], index=["a", "b", "c", "d"])
print(obj["a"]) # 输出8
print(obj["d"]) # 输出2
print(obj[["a", "c", "d"]]) # 选取索引为"a","c","d"对应的值。
print(obj[obj > 0]) # 获取值大于0的数据。
print(obj * 2) # 输出Series对象中每个数据乘2之后的结果。
print("a" in obj) # 判断obj对象中是否存在索引值为"a"的数据。
dict = {"a": 23, "b": 12, "c": 8} # 定义字典对象
print(Series(dict)) # 将dict对象转化为Series对象
print(obj.isnull()) # 检测缺失数据
obj2 = Series([8, 6, -5], index=["a", "b", "e"]) # 再定义一个Series对象
print(obj + obj2) # 输出两个Series对象的和
obj.name = "population" # 给obj对象本身的name属性赋值
obj.index.name = "state" # obj对象的索引的name属性赋值
print(obj)
obj.index = ["f", "g", "k", "m"]
print(obj)
8
2
a 8
c -5
d 2
dtype: int64
a 8
b 6
d 2
dtype: int64
a 16
b 12
c -10
d 4
dtype: int64
True
a 23
b 12
c 8
dtype: int64
a False
b False
c False
d False
dtype: bool
a 16.0
b 12.0
c NaN
d NaN
e NaN
dtype: float64
state
a 8
b 6
c -5
d 2
Name: population, dtype: int64
f 8
g 6
k -5
m 2
Name: population, dtype: int64
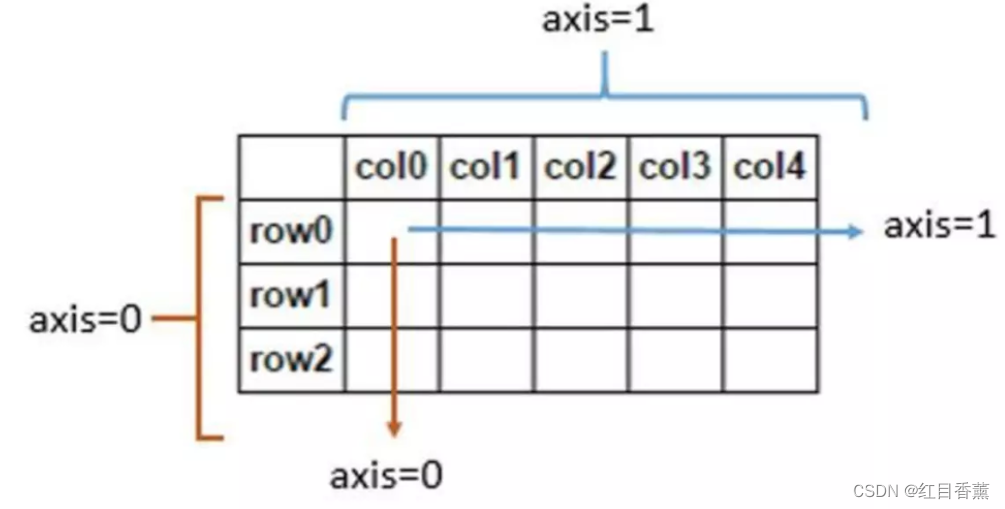
DataFrame
DataFrame是一种类似电子表格的数据结构。它包含一个经过排序的列表集,列表集中的每个数据都可以有不同的类型值(数字、字符串、布尔等)。
Datarame有行和列的索引;它可以被看作是一个Series的字典(每个Series共享一个索引)。
![]()
创建DataFrame对象
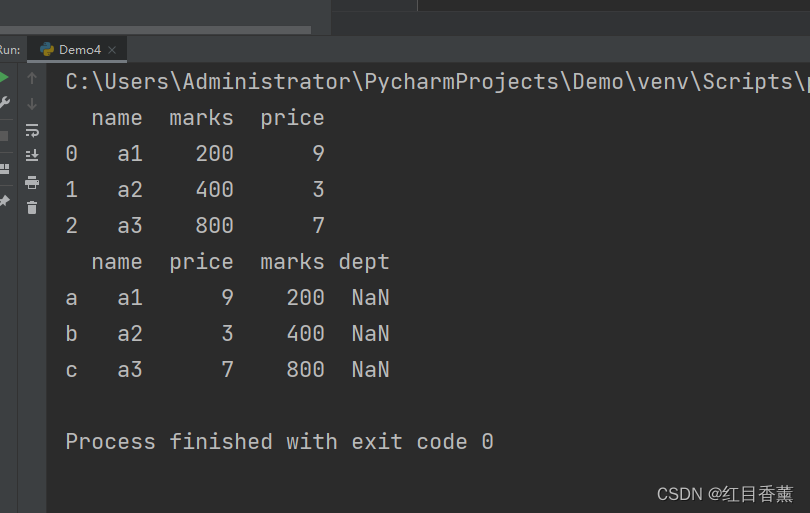
from pandas import Series, DataFrame
data = {"name": ["a1", "a2", "a3"], "marks": [200, 400, 800], "price": [9, 3, 7]}
frame = DataFrame(data)
# 将相等长度列表的字典对象转化为DataFrame对象
print(frame)
# 跟Series类似,DataFrame也能自定义索引
frame2 = DataFrame(data, columns=["name", "price", "marks", "dept"], index=["a", "b", "c"])
print(frame2)
![]()
操作DataFrame对象中列
在DataFrame对象中使用columns属性获取所有的列,并显示所有列的名称
DataFrame对象的每竖列都是一个Series对象
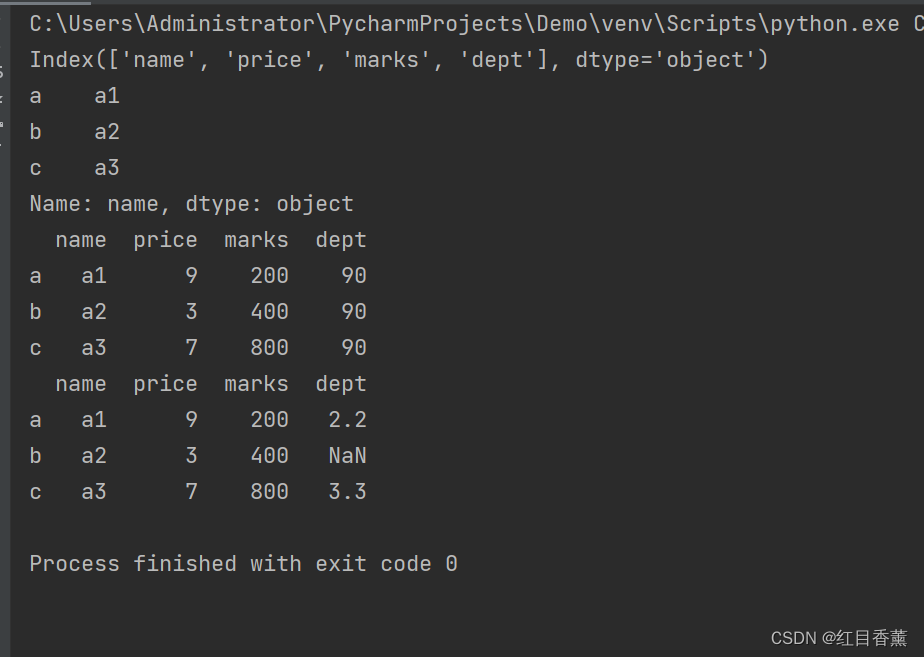
from pandas import Series, DataFrame
data = {"name": ["a1", "a2", "a3"], "marks": [200, 400, 800], "price": [9, 3, 7]}
frame3 = DataFrame(data, columns=["name", "price", "marks", "dept"], index=["a", "b", "c"])
print(frame3.columns)
print(frame3["name"])
frame3["dept"] = 90 # 统一给frame3对象的dept列赋值
print(frame3)
dept = Series([2.2, 3.3], index=["a", "c"])
frame3["dept"] = dept
print(frame3)
![]()
DataFrame对象中values属性
values属性会以二维Ndarray的形式返回DataFrame中的数据
如果DataFrame各列的数据类型不同,则值数组的数据类型就会选用能兼容所有列的数据
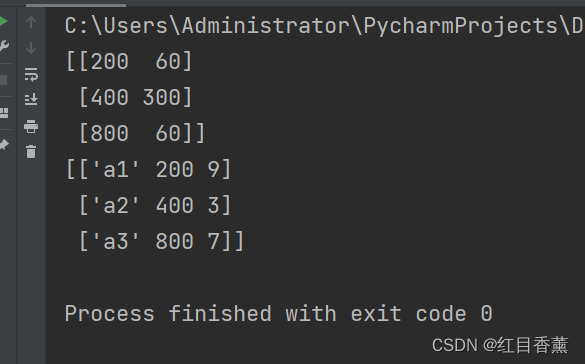
from pandas import Series, DataFrame
data1 = {"num1": [200, 400, 800], "num2": [60, 300, 60]}
data2 = {"name": ["a1", "a2", "a3"], "marks": [200, 400, 800], "price": [9, 3, 7]}
frame1 = DataFrame(data1)
frame2 = DataFrame(data2)
print(frame1.values)
print(frame2.values)
Pandas索引对象
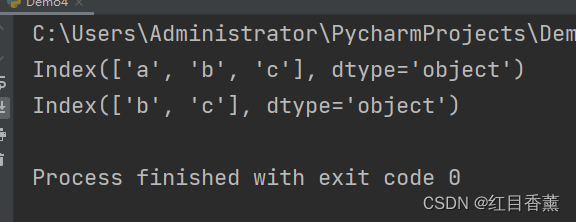
from pandas import Series
obj = Series(range(3), index=["a", "b", "c"])
# 获取Series的索引对象
index = obj.index
print(index)
# 获取第二位及之后的元素
print(index[1:])
Index类的函数列表见下表:
| 函数 |
属性 |
| append |
链接另一个Index对象,产生一个新的Index |
| diff |
计算差集,并得到一个Index对象 |
| intersection |
计算交集 |
| union |
计算并集 |
| isin |
计算一个指示各值是否都包含在参数集合中的布尔型数组 |
| delete |
删除索引指定位置的元素,并得到新的Index |
| drop |
删除传入的值,并得到新的Index |
| insert |
将元素插入到索引指定位置处,并得到新的Index |
| is_monotonic |
当各元素均大于等于前一个元素时,返回True |
| is_unique |
将Index没有重复值时,返回True |
| unique |
返回Index中唯一的数组 |
Series对象和DateFrame对象中的索引值不只是整数,还可以是字符串。
from pandas import Series, DataFrame;
import numpy as np
obj = Series(np.arange(4), index=["a", "b", "c", "d"])
print(obj["b"]) # 获取索引值为b的元素
print(obj[1]) # 获取第二个元素
print(obj[2:4]) # 获取第3个元素和第4个元素
print(obj[["a", "d"]]) # 获取索引值为a和d的元素
obj["b":"c"] = 5 # 设置索引值b到c的值为5
print(obj)
frame = DataFrame(np.arange(9).reshape(3, 3), index=["a", "c", "d"],
columns=["Ohio", "Texas", "California"]) # DataFrame进行索引
print(frame)
print(frame["Ohio"]) # 获取索引值Ohio的元素
print(frame[["Texas", "California"]]) # 获取索引值Texas和California的元素
print(frame[:2]) # 获取前2个元素
print(frame[frame["California"] > 3]) # 选取索引为California中值大于3的记录
print(frame < 5) # 通过布尔型DataFrame进行索引
frame[frame < 5] = 0 # 通过布尔型DataFrame进行索引
print(frame)
1
1
c 2
d 3
dtype: int32
a 0
d 3
dtype: int32
a 0
b 5
c 5
d 3
dtype: int32
Ohio Texas California
a 0 1 2
c 3 4 5
d 6 7 8
a 0
c 3
d 6
Name: Ohio, dtype: int32
Texas California
a 1 2
c 4 5
d 7 8
Ohio Texas California
a 0 1 2
c 3 4 5
Ohio Texas California
c 3 4 5
d 6 7 8
Ohio Texas California
a True True True
c True True False
d False False False
Ohio Texas California
a 0 0 0
c 0 0 5
d 6 7 8
索引对象相同的Pandas对象之间的算术运算
Pandas还提供了sub()函数用于减法,div()函数用于除法,mul()函数用于乘法
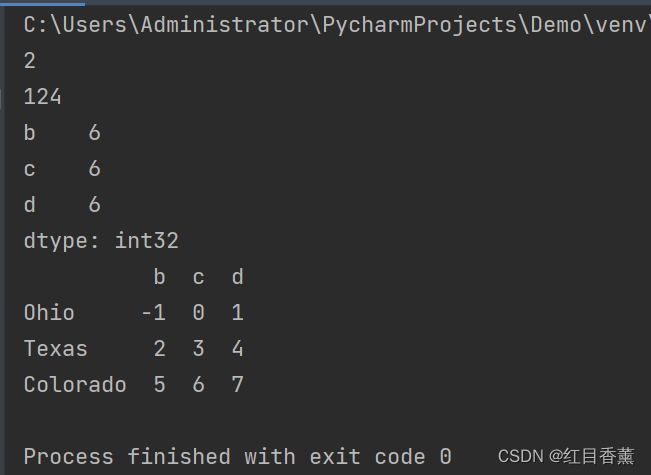
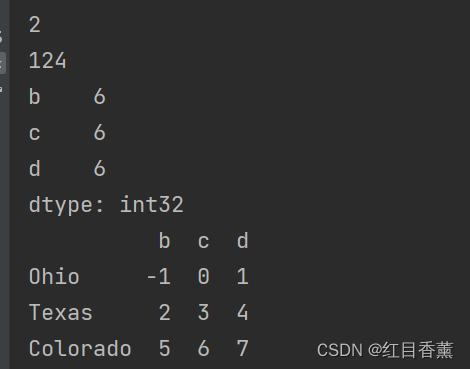
from pandas import Series, DataFrame;
import numpy as np
s1 = Series([7.2, -6.5, -3.5, 1.6], index=["a", "c", "d", "e"])
s2 = Series([-2, 3, 4, 5, 8], index=["a", "c", "e", "f", "f"])
print(s1 + s2) # +算术运算
df1 = DataFrame(np.arange(9).reshape(3, 3), columns=list("bcd"), index=["Ohio", "Texas", "Colorado"])
df2 = DataFrame(np.arange(12).reshape(4, 3), columns=list("bde"), index=["Oregon", "Ohio", "Texas", "Colorado"])
print(df1, df2)
print(df1 + df2) # +算术运算
print(df1.add(df2, fill_value=0)) # add函数
a 5.2
c -3.5
d NaN
e 5.6
f NaN
f NaN
dtype: float64
b c d
Ohio 0 1 2
Texas 3 4 5
Colorado 6 7 8 b d e
Oregon 0 1 2
Ohio 3 4 5
Texas 6 7 8
Colorado 9 10 11
b c d e
Colorado 15.0 NaN 18.0 NaN
Ohio 3.0 NaN 6.0 NaN
Oregon NaN NaN NaN NaN
Texas 9.0 NaN 12.0 NaN
b c d e
Colorado 15.0 7.0 18.0 11.0
Ohio 3.0 1.0 6.0 5.0
Oregon 0.0 NaN 1.0 2.0
Texas 9.0 4.0 12.0 8.0
在Pandas中应用lambda表达式
from pandas import Series
import numpy as np
from pandas import DataFrame
# 定义普通函数
def func(arg):
return arg + 1
print(func(1))
mylambda = lambda arg: arg + 1 # 定义函数(lambda表达式)
print(mylambda(123))
frame = DataFrame(np.arange(9).reshape(3, 3), columns=list("bcd"), index=["Ohio", "Texas", "Colorado"])
f = lambda x: x.max() - x.min() # 定义函数(lambda表达式)
print(frame.apply(f))
# 定义函数(lambda表达式)
sub = lambda x: x - 1
print(frame.applymap(sub))
Pandas排序
from pandas import Series
import numpy as np
from pandas import DataFrame
# 定义普通函数
def func(arg):
return arg + 1
print(func(1))
mylambda = lambda arg: arg + 1 # 定义函数(lambda表达式)
print(mylambda(123))
frame = DataFrame(np.arange(9).reshape(3, 3), columns=list("bcd"), index=["Ohio", "Texas", "Colorado"])
f = lambda x: x.max() - x.min() # 定义函数(lambda表达式)
print(frame.apply(f))
# 定义函数(lambda表达式)
sub = lambda x: x - 1
print(frame.applymap(sub))
from pandas import Series
import numpy as np
from pandas import DataFrame
obj = Series(range(4), index=["d", "a", "b", "c"])
print(obj.sort_index()) # sort_index函数
frame = DataFrame(np.arange(9).reshape(3, 3), columns=[4, 6, 5], index=["c", "a", "d"])
print(frame.sort_index()) # sort_index函数
print(frame.sort_index(axis=1))
print(frame.sort_index(axis=1, ascending=False))
frame = DataFrame({"b": [4, -3, 7, 2], "a": [1, 6, 5, 3]})
print(frame.sort_values(by="b")) # 对"b"这一列进行升序排列
print(frame.sort_values(by=["a", "b"])) # 同时对两列进行升序排列
obj = Series([7, -2, 4, 3, 12])
print(obj.rank()) # rank()函数
# 根据值在原始数据中出现的顺序给出排名
print(obj.rank(method="first"))
a 1
b 2
c 3
d 0
dtype: int64
4 6 5
a 3 4 5
c 0 1 2
d 6 7 8
4 5 6
c 0 2 1
a 3 5 4
d 6 8 7
6 5 4
c 1 2 0
a 4 5 3
d 7 8 6
b a
1 -3 6
3 2 3
0 4 1
2 7 5
b a
0 4 1
3 2 3
2 7 5
1 -3 6
0 4.0
1 1.0
2 3.0
3 2.0
4 5.0
dtype: float64
0 4.0
1 1.0
2 3.0
3 2.0
4 5.0
dtype: float64
Pandas统计
| 统计函数 |
功能说明 |
| count |
非NaN值的数量 |
| describe |
针对Series或DataFrame的列计算汇总统计 |
| min,max |
最小值和最大值 |
| argmin,argmax |
最小值和最大值的索引位置(整数) |
| idxmin,idxmax |
最小值和最大值的索引值 |
| quantile |
样本分位数(0到1) |
| sum |
求和 |
| mean |
均值 |
| median |
中位数 |
| mad |
根据均值计算平均绝对离差 |
| var |
方差 |
| std |
标准差 |
| skew |
样本值的偏度(三阶矩) |
| kurt |
样本值的峰度(四阶矩) |
| cumsum |
样本值的累计和 |
| cummin,cummax |
样本值的累计最大值和累计最小值 |
| cumprod |
样本值的累计积 |
| diff |
计算一阶差分(对时间序列很有用) |
| pct_change |
计算百分数变化 |
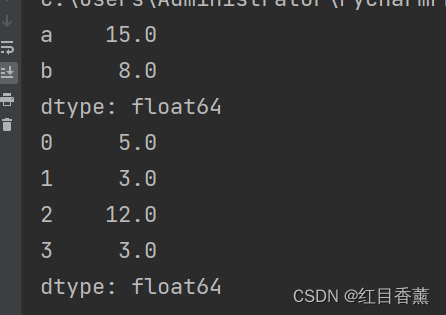
DataFrame对象的sum()函数,返回一个含有列小计的Series对象
from pandas import Series, DataFrame
import numpy as np
frame = DataFrame({"a": [1, 6, 5, 3], "b": [4, -3, 7, np.nan]})
# 按列进行求和
print(frame.sum())
# 按行进行求和
print(frame.sum(axis=1))
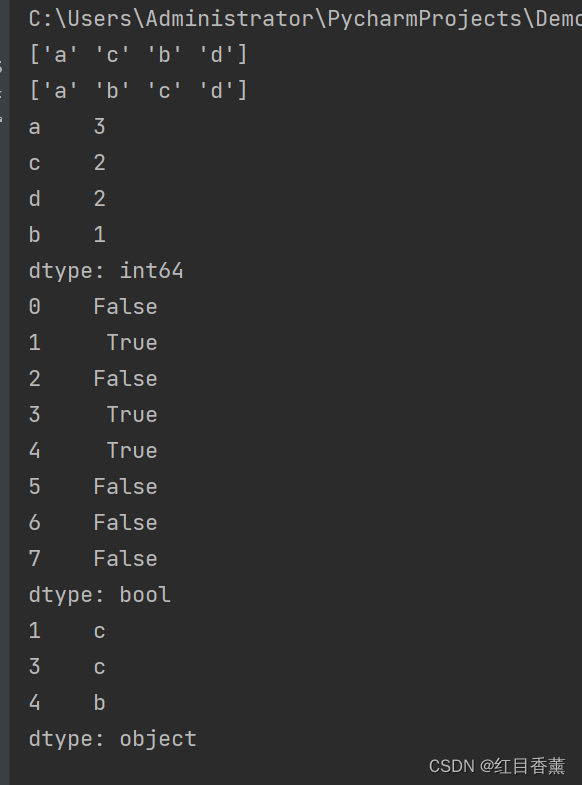
数据消重、频率统计和数据包含判断
from pandas import Series, DataFrame
obj = Series(["a", "c", "a", "c", "b", "a", "d", "d"])
uniques = obj.unique() # 获取Series中的唯一值数组
print(uniques)
uniques.sort() # 对Series数组进行排序
print(uniques)
# 计算Series数组各值出现的频率
print(obj.value_counts())
# obj各值是否包含于["b","c"]中
mask = obj.isin(["b", "c"])
print(mask)
print(obj[mask]) # 选取Series中数据的子集
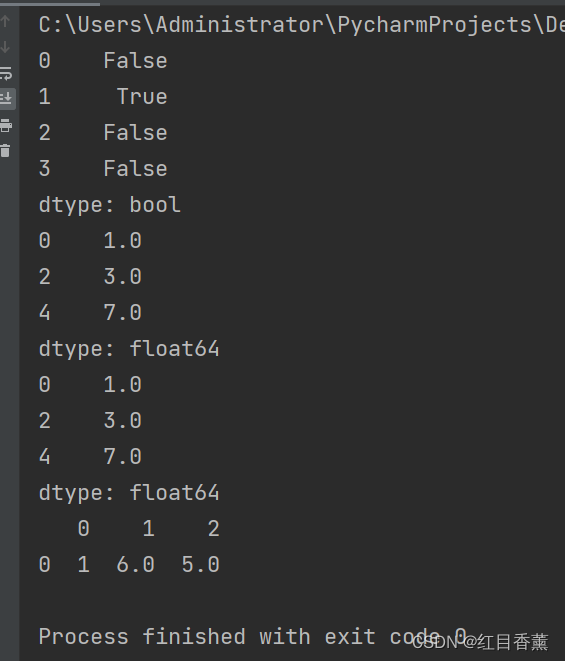
缺失数据处理
缺失数据在大部分数据分析应用中都很常见,Pandas的设计目标之一就是让缺失数据的处理任务尽量轻松
Pandas使用浮点值NaN(Not a umber)表示浮点和非浮点数组中的缺失数据
Pandas提供了专门的处理缺失数据的函数:
| 函数 |
说明 |
| dropna |
根据各标签的值中是否存在缺失数据对轴标签进行过滤 |
| fillna |
用指定值或插值函数填充缺失数据 |
| isnull |
返回一个含有布尔值的对象,这些布尔值表示哪些值是缺失值 |
| notnull |
返回一个含有布尔值的对象,这些布尔值表示哪些值不是缺失值 |
from pandas import Series, DataFrame
import numpy as np
data = Series(["a", np.nan, "c", "d"])
print(data.isnull()) # 判断是否为空对象
data = Series([1, np.nan, 3, np.nan, 7])
print(data.dropna()) # 滤掉缺失数据
# 通过布尔值索引滤除数据
print(data[data.notnull()])
data = DataFrame([[1, 6, 5], [2, np.nan, np.nan]])
# 滤除DataFrame中的缺失数据
print(data.dropna())

- 点赞
- 收藏
- 关注作者
评论(0)