Python可视化数据分析03、jieba【分词】

【摘要】 编辑Python可视化数据分析03、jieba【分词】📋前言📋💝博客:【红目香薰的博客_CSDN博客-计算机理论,2022年蓝桥杯,MySQL领域博主】💝✍本文由在下【红目香薰】原创,首发于CSDN✍🤗2022年最大愿望:【服务百万技术人次】🤗💝Python初始环境地址:【Python可视化数据分析01、python环境搭建】💝 环境需求环境:win10开发工具:PyC...

![]()
Python可视化数据分析03、jieba【分词】
📋前言📋
💝博客:【】💝
✍本文由在下【红目香薰】原创,首发于CSDN✍
🤗2022年最大愿望:【服务百万技术人次】🤗
💝Python初始环境地址:【】💝
环境需求
环境:win10
开发工具:PyCharm Community Edition 2021.2
数据库:MySQL5.6
目录
demo3:搜索引擎模式【lcut_for_search()】
前言
由于中科院分词总是过期需要证书,学校的网还不允许访问git,所以我这里用jieba来讲解分词。
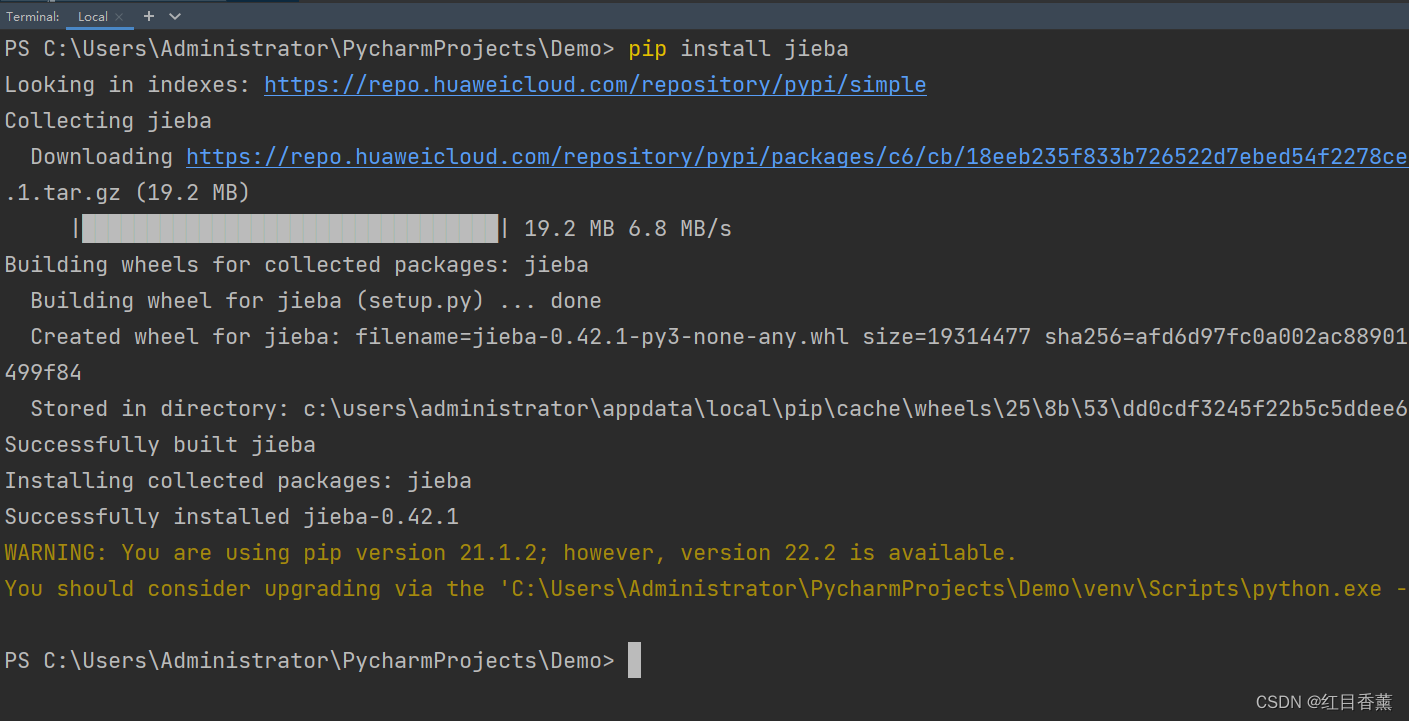
通过pip3下载jieba
pip3 install jieba
![]()
新建测试类:Demo3.py
demo1:jieba精确模式分词
jieba精确模式分词使用lcut()函数,类似cut()函数,其参数和cut()函数是一致的,只不过返回结果是列表而不是生成器,默认使用精确模式。
【lcut】默认模式。句子精确地切开,每个字符只会出席在一个词中,适合文本分析;
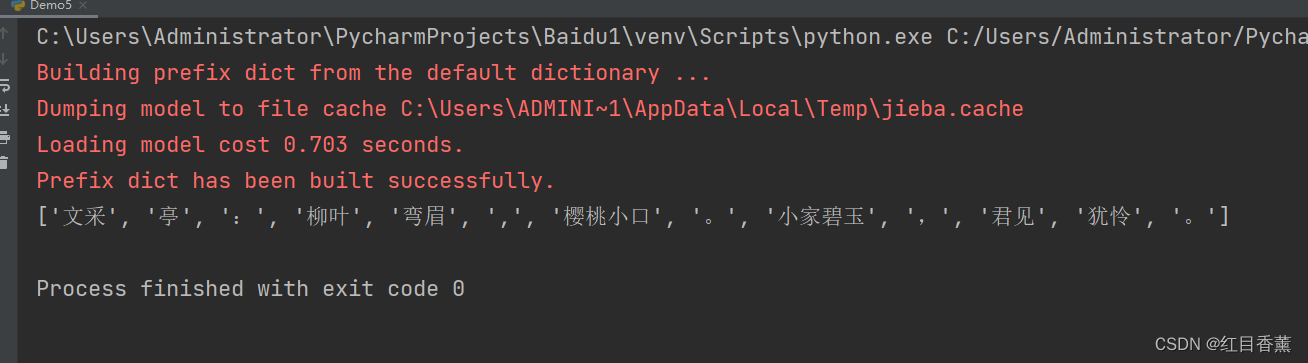
import jieba
strInfo = "文采亭:柳叶弯眉,樱桃小口。小家碧玉,君见犹怜。"
# 精准拆分
result = jieba.lcut(strInfo)
print(result)
![]()
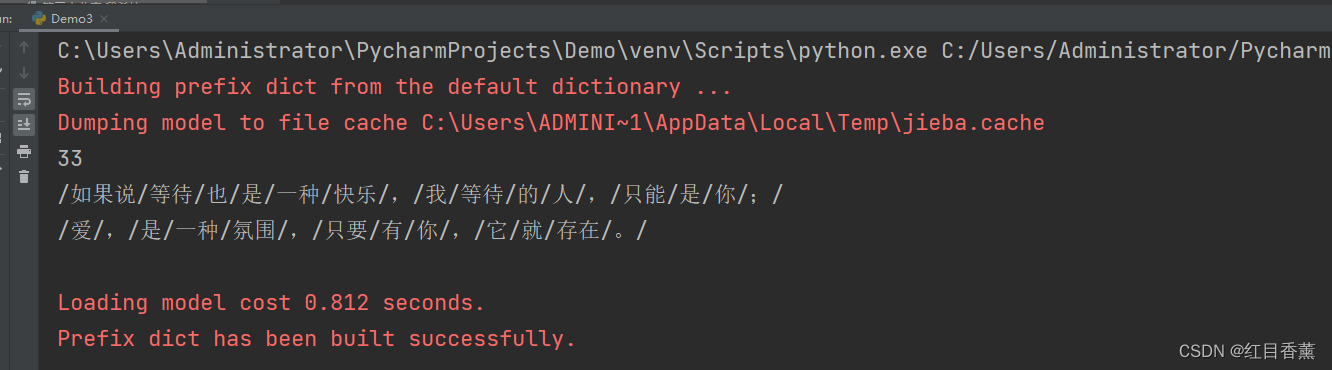
import jieba
content = """
如果说等待也是一种快乐,我等待的人,只能是你;
爱,是一种氛围,只要有你,它就存在。
"""
result = jieba.lcut(content)
print(len(result), '/'.join(result))
![]()
可以从以上看出,自动分开词句。
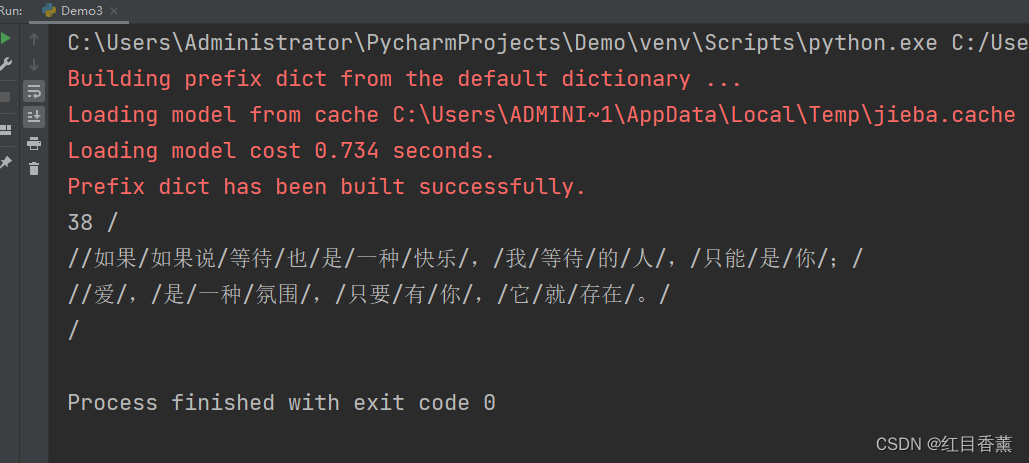
demo2:全模式【cut_all=True】
会将所有的可能都拆分开
import jieba
content = """
如果说等待也是一种快乐,我等待的人,只能是你;
爱,是一种氛围,只要有你,它就存在。
"""
result = jieba.lcut(content,cut_all=True)
print(len(result), '/'.join(result))
![]()
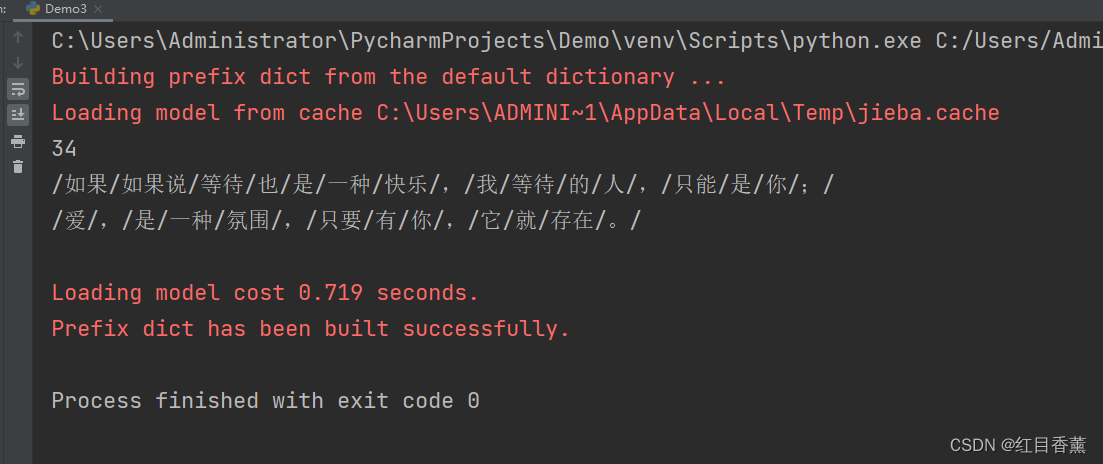
demo3:搜索引擎模式【lcut_for_search()】
import jieba
content = """
如果说等待也是一种快乐,我等待的人,只能是你;
爱,是一种氛围,只要有你,它就存在。
"""
result = jieba.lcut_for_search(content)
print(len(result), '/'.join(result))
![]()
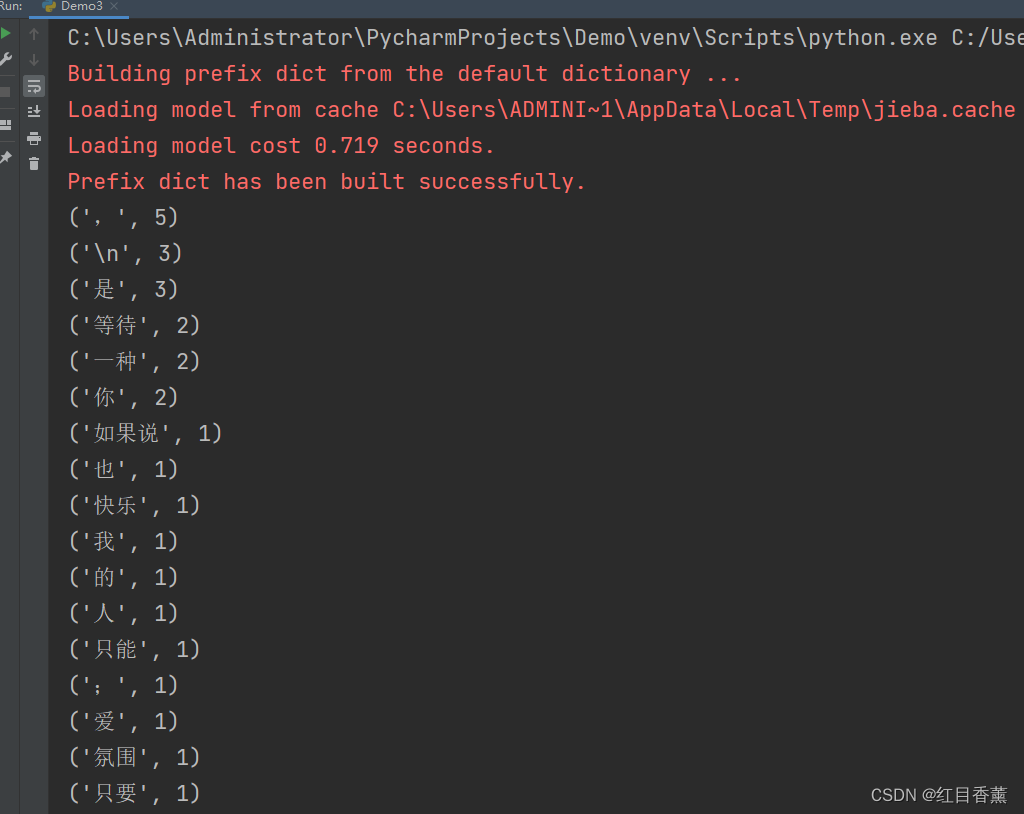
demo4:通过collections进行词频分析
import jieba
from collections import Counter
content = """
如果说等待也是一种快乐,我等待的人,只能是你;
爱,是一种氛围,只要有你,它就存在。
"""
result = jieba.lcut(content)
counter = Counter(result)
dictionary = dict(counter)
k = 100
res = counter.most_common(k)
for item in res:
print(item)
![]()
import jieba
from collections import Counter
content = """
雨巷
撑着油纸伞,独自
彷徨在悠长,悠长
又寂寥的雨巷,
我希望逢着
一个丁香一样地
结着愁怨的姑娘。
她是有
丁香一样的颜色,
丁香一样的芬芳,
丁香一样的忧愁,
在雨中哀怨,
哀怨又彷徨;
她彷徨在这寂寥的雨巷,
撑着油纸伞
像我一样,
像我一样地
默默彳亍着,
冷漠,凄清,又惆怅。
她静默地走近
走近,又投出
太息一般的眼光,
她飘过
像梦一般的,
像梦一般的凄婉迷茫。
像梦中飘过
一枝丁香的,
我身旁飘过这女郎;
她静默地远了,远了,
到了颓圮的篱墙,
走尽这雨巷。
在雨的哀曲里,
消了她的颜色,
散了她的芬芳
消散了,甚至她的
太息般的眼光,
丁香般的惆怅。
撑着油纸伞,独自
彷徨在悠长,悠长
又寂寥的雨巷,
我希望飘过
一个丁香一样地
结着愁怨的姑娘。
"""
result = jieba.lcut(content)
counter = Counter(result)
dictionary = dict(counter)
k = 100
res = counter.most_common(k)
for item in res:
print(item)
jieba的内容很好理解,就不多说了。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)